
 Java
JavaInterview Fragen
Interviewer: Wie viel wissen Sie über hohe Parallelität? Ich: emmm...
Java
JavaInterview Fragen
Interviewer: Wie viel wissen Sie über hohe Parallelität? Ich: emmm...
Interviewer: Wie viel wissen Sie über hohe Parallelität? Ich: emmm...

Hohe Parallelität ist eine Erfahrung, die fast jeder Programmierer haben möchte. Der Grund ist einfach: Mit zunehmendem Datenverkehr treten verschiedene technische Probleme auf, z. B. Zeitüberschreitungen bei der Schnittstellenantwort, erhöhte CPU-Last, häufiger GC, Deadlock, großer Datenspeicher usw. Diese Probleme können uns dazu veranlassen, uns kontinuierlich zu verbessern unsere technische Tiefe.
Wenn der Kandidat in früheren Vorstellungsgesprächen an einem Projekt mit hoher Parallelität gearbeitet hat, habe ich den Kandidaten normalerweise gebeten, über sein Verständnis von hoher Parallelität zu sprechen, aber nicht viele Leute können diese Frage systematisch beantworten, wahrscheinlich geteilt in die Folgende Kategorien:
1. Kein Konzept für datenbasierte Indikatoren: Sie sind sich nicht sicher, welche Art von Indikatoren Sie zur Messung von Systemen mit hoher Parallelität wählen sollen? Ich kann den Unterschied zwischen Parallelität und QPS nicht erkennen und kenne nicht einmal die Gesamtzahl der Benutzer meines Systems, die Anzahl der aktiven Benutzer, QPS und TPS während Flach- und Spitzenzeiten und andere wichtige Daten.
2. Einige Pläne wurden entworfen, aber die Details sind noch nicht vollständig erfasst: Ich kann die technischen Punkte und möglichen Nebenwirkungen des Plans nicht erklären. Wenn es beispielsweise einen Engpass bei der Leseleistung gibt, wird Caching eingeführt, aber Probleme wie Cache-Trefferrate, Hotkeys und Datenkonsistenz werden ignoriert.
3. Einseitiges Verständnis, das Design mit hoher Parallelität mit Leistungsoptimierung gleichsetzt: spricht von gleichzeitiger Programmierung, mehrstufigem Caching, Asynchronisierung und horizontaler Erweiterung, ignoriert jedoch Design mit hoher Verfügbarkeit, Service-Governance und Betrieb Wartungsgarantien.
4. Beherrschen Sie den großen Plan, aber ignorieren Sie die grundlegendsten Dinge: Kann große Ideen wie vertikale Schichtung, horizontale Partitionierung, Caching klar erklären, hat aber kein Bewusstsein für die Analyse der Datenstruktur ist vernünftig und der Algorithmus Ob er effizient ist oder nicht, ich habe nie darüber nachgedacht, Details aus den beiden grundlegendsten Dimensionen von IO und Computing zu optimieren.
In diesem Artikel möchte ich meine Erfahrung in Projekten mit hoher Parallelität zusammenfassen, um das Wissen und die praktischen Ideen, die in High-Parallelität gemeistert werden müssen, systematisch zusammenzufassen. Ich hoffe, dass es für Sie hilfreich ist. Der Inhalt gliedert sich in folgende 3 Teile:
Wie versteht man hohe Parallelität? Was ist das Ziel des Systemdesigns mit hoher Parallelität? -
Was sind die praktischen Lösungen für hohe Parallelität?
Hohe Parallelität bedeutet großen Datenverkehr, und es müssen technische Mittel eingesetzt werden, um den Auswirkungen des Datenverkehrs zu widerstehen. Diese Mittel ähneln dem operativen Datenverkehr, sodass der Datenverkehr vom System reibungsloser verarbeitet werden kann und den Benutzern ein besseres Erlebnis geboten wird.
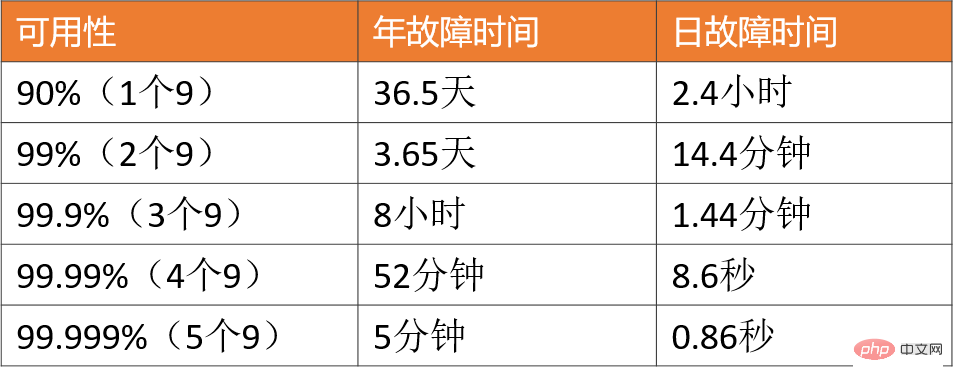
Zu unseren gängigen Szenarien mit hoher Parallelität gehören: Taobaos Double 11, Ticketraub während des Frühlingsfestes, heiße Neuigkeiten von Weibo Vs usw. Zusätzlich zu diesen typischen Dingen können Flash-Sale-Systeme mit Hunderttausenden Anfragen pro Sekunde, Bestellsysteme mit Dutzenden Millionen Bestellungen pro Tag, Informationsflusssysteme mit Hunderten Millionen täglichen Aktiven pro Tag usw. klassifiziert werden als hohe Parallelität. Natürlich variiert der Grad der Parallelität bei den oben genannten Szenarien mit hoher Parallelität. Wie viel Parallelität gilt also als hohe Parallelität? 1. Man kann nicht nur auf Zahlen schauen, man muss sich konkrete Geschäftsszenarien ansehen. Es kann nicht gesagt werden, dass der Flash-Verkauf von 10-W-QPS eine hohe Parallelität aufweist, aber der Informationsfluss von 1-W-QPS weist keine hohe Parallelität auf. Das Informationsflussszenario umfasst komplexe Empfehlungsmodelle und verschiedene manuelle Strategien, und seine Geschäftslogik kann mehr als zehnmal komplexer sein als das Flash-Sale-Szenario. Daher befinden sie sich nicht in derselben Dimension und haben keine vergleichende Bedeutung. 2. Das Geschäft wird von 0 auf 1 aufgebaut. Parallelität und QPS sind nur Referenzindikatoren. Das Wichtigste ist: Wenn das Geschäftsvolumen allmählich das Zehnfache oder das Hundertfache erreicht, verwenden Sie es Wenn es um hohe Parallelität geht Verarbeitungsmethoden: Wie können Sie Ihr System weiterentwickeln und Probleme verhindern und lösen, die durch hohe Parallelität in den Dimensionen Architekturdesign, Codierungsimplementierung und sogar Produktlösungen verursacht werden? Anstatt blind die Hardware aufzurüsten und Maschinen für die horizontale Erweiterung hinzuzufügen. Darüber hinaus sind die Geschäftsmerkmale jedes Szenarios mit hoher Parallelität völlig unterschiedlich: Es gibt Informationsflussszenarien mit mehr Lesen und weniger Schreiben und es gibt Transaktionsszenarien mit mehr Lesen und Schreiben Ist da? eine universelle technische Lösung zur Lösung verschiedener Szenarien? Was ist mit dem Problem der hohen Parallelität? Ich denke, wir können aus den großen Ideen und den Plänen anderer lernen, aber im eigentlichen Umsetzungsprozess wird es unzählige Fallstricke im Detail geben. Da die Software- und Hardwareumgebung, der Technologie-Stack und die Produktlogik nicht vollständig konsistent sein können, führen diese außerdem zu demselben Geschäftsszenario. Selbst wenn dieselbe technische Lösung verwendet wird, treten unterschiedliche Probleme auf, und diese Fallstricke müssen auftreten nach und nach überwunden werden. Daher werde ich mich in diesem Artikel auf Grundkenntnisse, allgemeine Ideen und effektive Erfahrungen konzentrieren, die ich geübt habe, in der Hoffnung, Ihnen ein tieferes Verständnis der hohen Parallelität zu vermitteln. Klaren Sie zunächst die Ziele des High-Parallel-Systemdesigns und besprechen Sie dann den Designplan und die praktischen Erfahrungen, um sinnvoll und zielgerichtet zu sein. Hohe Parallelität bedeutet nicht nur das Streben nach hoher Leistung, was für viele Menschen ein einseitiges Verständnis ist. Aus makroökonomischer Sicht gibt es drei Ziele für das Design von Systemen mit hoher Parallelität: hohe Leistung, hohe Verfügbarkeit und hohe Skalierbarkeit. Die Leistung spiegelt die Parallelverarbeitungsfähigkeit des Systems wider. Bei begrenzten Hardwareinvestitionen bedeutet Verbesserung Kosten. Gleichzeitig spiegelt die Leistung auch das Benutzererlebnis wider. Die Reaktionszeiten betragen 100 Millisekunden bzw. 1 Sekunde, was den Benutzern völlig unterschiedliche Gefühle vermittelt. : gibt den Zeitpunkt an, zu dem das System normal funktionieren kann. Beim einen gibt es das ganze Jahr über keine Ausfallzeiten und keine Störungen; beim anderen kommt es hin und wieder zu Online-Unfällen und Ausfallzeiten. Benutzer werden sich definitiv für Ersteres entscheiden. Wenn das System außerdem nur eine Verfügbarkeit von 90 % erreichen kann, wird dies auch das Geschäft stark behindern. 3. Hohe Erweiterung : Zeigt die Skalierbarkeit des -Systems an, ob die Erweiterung in Spitzenverkehrszeiten in kurzer Zeit abgeschlossen werden kann und Spitzenverkehr, wie z. B. Double 11-Ereignisse, reibungsloser bewältigen kann , Scheidungen von Prominenten und andere heiße Ereignisse . Diese drei Ziele müssen umfassend betrachtet werden, da sie miteinander verbunden sind und sich sogar gegenseitig beeinflussen. als wie : Berücksichtigen Sie die Skalierbarkeit des Systems , Sie werden den Dienst zustandslos gestalten , Diese Art von Cluster Die designdesign gewährleistet eine hohe Skalierbarkeit und verbessert tatsächlich auch die Leistung und Benutzerfreundlichkeit des Systems. Ein weiteres Beispiel: Um die Verfügbarkeit sicherzustellen, werden für Serviceschnittstellen normalerweise Timeout-Einstellungen festgelegt, um zu verhindern, dass eine große Anzahl von Threads langsame Anforderungen blockiert und eine Systemlawine verursacht. Im Allgemeinen nehmen wir Einstellungen basierend auf der Leistung abhängiger Dienste vor. Was sind aus Mikroperspektive die spezifischen Indikatoren zur Messung von hoher Leistung, hoher Verfügbarkeit und hoher Skalierbarkeit? Warum wurden diese Indikatoren ausgewählt? Leistungsindikatoren können zur Messung aktueller Leistungsprobleme eingesetzt werden und dienen als Bewertungsgrundlage für die Leistungsoptimierung. Im Allgemeinen wird die Reaktionszeit der Schnittstelle innerhalb eines Zeitraums als Indikator verwendet. 1. Durchschnittliche Antwortzeit: Wird am häufigsten verwendet, weist jedoch offensichtliche Mängel auf und reagiert nicht empfindlich auf langsame Anfragen. Beispielsweise gibt es 10.000 Anfragen, davon sind 9.900 1 ms und 100 100 ms. Die durchschnittliche Antwortzeit hat sich zwar nur um 0,99 ms erhöht, die Antwortzeit hat sich jedoch um 100 erhöht mal. 2, TP90, TP99 und andere Quantilwerte: Sortieren Sie die Reaktionszeit von klein nach groß. Je größer der Quantilwert, desto empfindlicher ist er langsame Anfragen. 3. Durchsatz: Es ist umgekehrt proportional zur Antwortzeit. Wenn die Antwortzeit beispielsweise 1 ms beträgt, beträgt der Durchsatz 1000 Mal pro Sekunde. Normalerweise werden bei der Festlegung von Leistungszielen sowohl der Durchsatz als auch die Antwortzeit berücksichtigt. Unter 10.000 Anfragen pro Sekunde wird beispielsweise AVG auf unter 50 ms und TP99 auf unter 100 ms gesteuert. Bei Systemen mit hoher Parallelität müssen die AVG- und TP-Quantilwerte gleichzeitig berücksichtigt werden. Aus Sicht der Benutzererfahrung gelten 200 Millisekunden als erster Teilungspunkt, und Benutzer werden die Verzögerung nicht spüren. 1 Sekunde ist der zweite Teilungspunkt, und Benutzer werden die Verzögerung spüren, aber sie ist akzeptabel . Daher sollte TP99 für ein gesundes System mit hoher Parallelität innerhalb von 200 Millisekunden und TP999 oder TP9999 innerhalb von 1 Sekunde gesteuert werden. Hohe Verfügbarkeit bedeutet, dass das System eine hohe Verfügbarkeit hat = Betriebszeit/Gesamtsystemlaufzeit, um das System zu beschreiben . Verfügbarkeit. Für ein System mit hoher Parallelität lautet die grundlegendste Anforderung: 3 9s oder 4 9s garantieren. Der Grund ist einfach: Wenn Sie nur zwei Neunen erreichen können, bedeutet dies, dass es eine Ausfallzeit von 1 % gibt. Einige große Unternehmen haben beispielsweise oft einen Umsatz von mehr als 100 Milliarden Milliardenniveau. Angesichts plötzlichen Datenverkehrs ist es unmöglich, die Architektur vorübergehend zu ändern, indem Maschinen hinzugefügt werden, um die Verarbeitungsfähigkeiten des Systems linear zu verbessern. Für Geschäftscluster oder Basiskomponenten gilt: Skalierbarkeit = Leistungsverbesserungsverhältnis / Maschinenadditionsverhältnis: Erhöhen Sie die Ressourcen um ein Vielfaches und verbessern Sie die Leistung um ein Vielfaches. Generell sollte die Expansionsfähigkeit über 70 % gehalten werden. Aber aus der Perspektive der Gesamtarchitektur eines Systems mit hoher Parallelität besteht das Ziel der -Erweiterung nicht nur darin, den Dienst zustandslos zu gestalten, denn wenn der Datenverkehr um das Zehnfache ansteigt, steigt der Der Geschäftsdienst kann schnell um das Zehnfache erweitert werden, die Datenbank kann jedoch zu einem neuen Engpass werden. Stateful-Storage-Dienste wie MySQL sind in der Regel technisch schwierig zu erweitern. Wenn die Architektur nicht im Voraus geplant wird (vertikale und horizontale Aufteilung), ist die Migration einer großen Datenmenge erforderlich. Daher muss eine hohe Skalierbarkeit berücksichtigt werden: Service-Cluster, Middleware wie Datenbanken, Caches und Nachrichtenwarteschlangen, Lastausgleich, Bandbreite, abhängige Dritte usw. Wenn die Parallelität ein bestimmtes Niveau erreicht, werden alle oben genannten Faktoren berücksichtigt Könnte zu einem Engpass für die Expansion werden. Ziel ist es, die Rechenleistung einer einzelnen Maschine zu verbessern, Der Plan umfasst außerdem: 1. Entwickeln Sie eine hierarchische Architektur: Dies ist der Fortschritt der horizontalen Erweiterung, da Systeme mit hoher Parallelität oft komplexe Geschäfte haben und die mehrschichtige Verarbeitung komplexe Probleme vereinfachen und die horizontale Erweiterung einfacher machen kann. Das obige Bild ist die häufigste Schichtarchitektur im Internet. Natürlich wird die echte Systemarchitektur mit hoher Parallelität auf dieser Basis weiter verbessert. Beispielsweise wird eine dynamische und statische Trennung vorgenommen und CDN eingeführt. Die Reverse-Proxy-Schicht kann LVS+Nginx sein, die Web-Schicht kann ein einheitliches API-Gateway sein, die Business-Service-Schicht kann je nach vertikalem Geschäft weiter mikroserviced sein , und die Speicherschicht kann aus verschiedenen heterogenen Datenbanken bestehen. 2. Horizontale Erweiterung jeder Ebene: zustandslose horizontale Erweiterung, zustandsbehaftetes Shard-Routing. Geschäftscluster können normalerweise zustandslos gestaltet werden, während Datenbanken und Caches häufig zustandsbehaftet sind. Daher müssen Partitionsschlüssel für Speicher-Sharding konzipiert werden. Natürlich kann die Leseleistung auch durch Master-Slave-Synchronisierung und Lese-Schreib-Trennung verbessert werden. 1. Cluster-Bereitstellung reduziert den Druck auf eine einzelne Maschine durch Lastausgleich. Die obige Lösung ist nichts anderes als die Berücksichtigung aller möglichen Optimierungspunkte aus den beiden Dimensionen Computing und IO. Sie erfordert ein unterstützendes Überwachungssystem, um die aktuelle Leistung in Echtzeit zu verstehen und Sie bei der Durchführung von Leistungsengpassanalysen zu unterstützen Befolgen Sie dann 28 Prinzipien, erfassen Sie die Hauptwidersprüche und optimieren Sie sie. 1 Sowohl Nginx als auch das Service-Governance-Framework unterstützen den Zugriff auf einen anderen Knoten. Hochverfügbarkeitslösungen werden hauptsächlich aus drei Richtungen betrachtet: Redundanz, Kompromisse sowie Systembetrieb und -wartung. Gleichzeitig müssen sie über unterstützende Pflichtmechanismen und Fehlerbehandlungsprozesse verfügen können rechtzeitig nachverfolgt werden. 1. Angemessene Schichtarchitektur: Zum Beispiel die oben erwähnte häufigste Schichtarchitektur des Internets, außerdem kann sie entsprechend der Datenzugriffsschicht und weiter angepasst werden Geschäftslogikschicht Microservices sind feinkörniger geschichtet (die Leistung muss jedoch bewertet werden, da es möglicherweise einen weiteren Hop im Netzwerk gibt). Hohe Parallelität ist in der Tat ein komplexes und systemisches Problem. Aufgrund des begrenzten Platzes müssen technische Punkte wie verteilte Ablaufverfolgung, vollständige Link-Stresstests und flexible Transaktionen berücksichtigt werden. Wenn die Geschäftsszenarien unterschiedlich sind, unterscheiden sich außerdem auch die Implementierungslösungen für hohe Parallelität, aber die allgemeinen Designideen und die Lösungen, die als Referenz verwendet werden können, sind grundsätzlich ähnlich. Design mit hoher Parallelität muss auch die drei Prinzipien des Architekturdesigns einhalten: Einfachheit, Angemessenheit und Entwicklung. „Vorzeitige Optimierung ist die Wurzel allen Übels“, kann nicht von der tatsächlichen Situation des Unternehmens getrennt werden, und überdesigne nicht , Die passende Lösung ist die perfekteste. Ich hoffe, dass dieser Artikel Ihnen ein umfassenderes Verständnis der hohen Parallelität vermitteln kann. Wenn Sie auch über Erfahrung und fundiertes Denken verfügen, aus dem Sie lernen können, hinterlassen Sie bitte eine Nachricht im Kommentarbereich zur Diskussion. 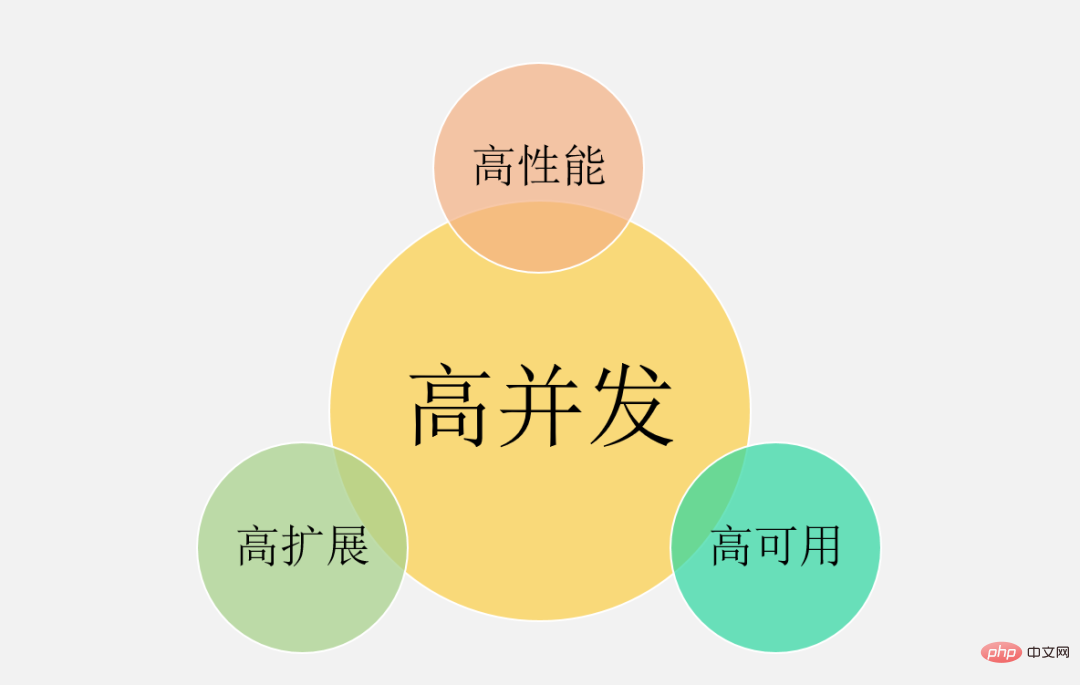
❇ Leistungsindikatoren

❇ VerfügbarkeitIndikator
❇ SkalierbarkeitIndikator
❇Vertikale Erweiterung (Scale-up)
Da die Leistung einzelner Maschinen immer Grenzen hat, ist es letztendlich notwendig, eine horizontale Erweiterung einzuführen und die Fähigkeiten zur gleichzeitigen Verarbeitung durch Cluster-Bereitstellung weiter zu verbessern, einschließlich der folgenden zwei Richtungen: 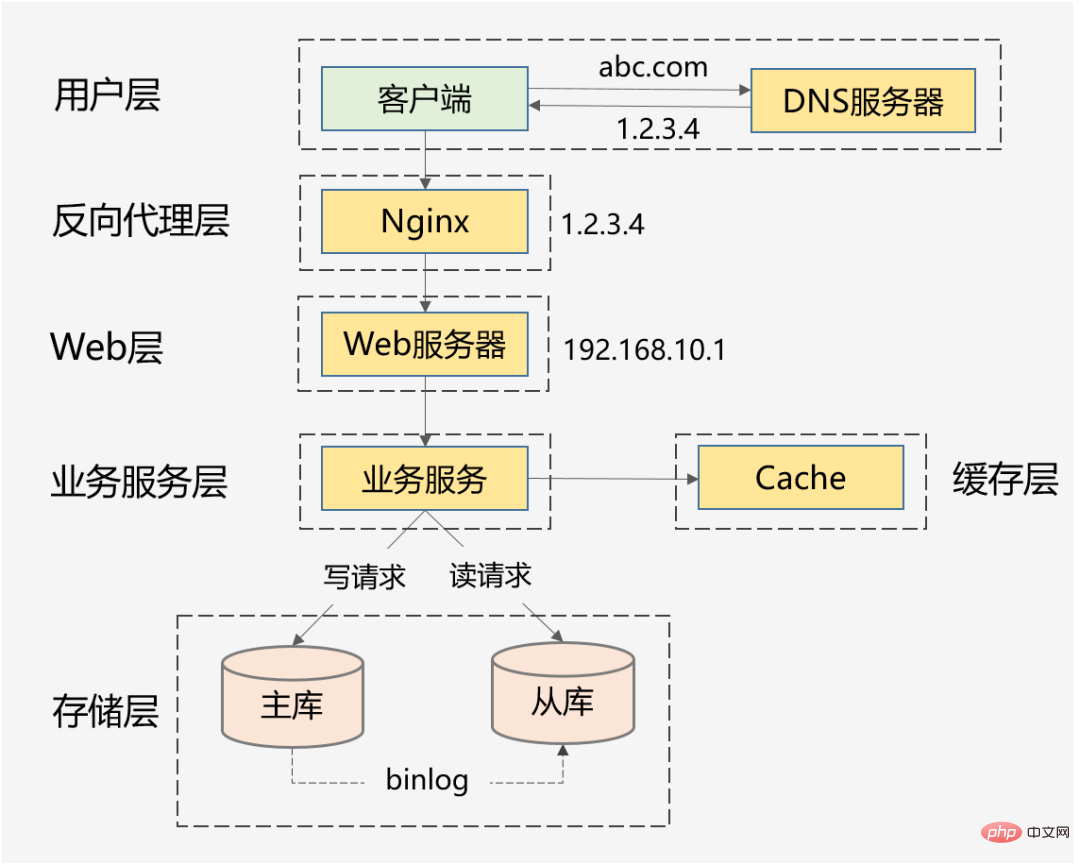
❇ Leistungsstarke, praktische Lösung
❇ Praktische Hochverfügbarkeitslösungen
❇ Hochskalierbare praktische Lösung
Das obige ist der detaillierte Inhalt vonInterviewer: Wie viel wissen Sie über hohe Parallelität? Ich: emmm.... Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Fünf häufig gestellte Fragen und Antworten zu Vorstellungsgesprächen in Go-Sprache
Jun 01, 2023 pm 08:10 PM
Fünf häufig gestellte Fragen und Antworten zu Vorstellungsgesprächen in Go-Sprache
Jun 01, 2023 pm 08:10 PM
Als Programmiersprache, die in den letzten Jahren sehr beliebt geworden ist, ist die Go-Sprache in vielen Unternehmen und Betrieben zu einem Hotspot für Vorstellungsgespräche geworden. Für Anfänger der Go-Sprache ist die Beantwortung relevanter Fragen während des Interviews eine Frage, die es wert ist, untersucht zu werden. Hier sind fünf häufig gestellte Fragen und Antworten zu Go-Interviews als Referenz für Anfänger. Bitte stellen Sie vor, wie der Garbage-Collection-Mechanismus der Go-Sprache funktioniert. Der Garbage-Collection-Mechanismus der Go-Sprache basiert auf dem Mark-Sweep-Algorithmus und dem Dreifarben-Markierungsalgorithmus. Wenn der Speicherplatz im Go-Programm nicht ausreicht, wird der Go-Garbage Collector verwendet
 Zusammenfassung der Front-End-React-Interviewfragen im Jahr 2023 (Sammlung)
Aug 04, 2020 pm 05:33 PM
Zusammenfassung der Front-End-React-Interviewfragen im Jahr 2023 (Sammlung)
Aug 04, 2020 pm 05:33 PM
Als bekannte Website zum Programmierenlernen hat die chinesische PHP-Website einige Fragen zu React-Interviews für Sie zusammengestellt, um Front-End-Entwicklern bei der Vorbereitung und Beseitigung von Hindernissen für React-Interviews zu helfen.
 Eine vollständige Sammlung ausgewählter Fragen und Antworten zu Web-Frontend-Interviews im Jahr 2023 (Sammlung)
Apr 08, 2021 am 10:11 AM
Eine vollständige Sammlung ausgewählter Fragen und Antworten zu Web-Frontend-Interviews im Jahr 2023 (Sammlung)
Apr 08, 2021 am 10:11 AM
Dieser Artikel fasst einige ausgewählte Web-Frontend-Interviewfragen zusammen, die es wert sind, gesammelt zu werden (mit Antworten). Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.
 50 Angular-Interviewfragen, die Sie beherrschen müssen (Sammlung)
Jul 23, 2021 am 10:12 AM
50 Angular-Interviewfragen, die Sie beherrschen müssen (Sammlung)
Jul 23, 2021 am 10:12 AM
In diesem Artikel werden Ihnen 50 Angular-Interviewfragen vorgestellt, die Sie beherrschen müssen. Diese 50 Interviewfragen werden in drei Teilen analysiert: Anfänger, Mittelstufe und Fortgeschrittene, und Sie werden durch sie geführt!
 Interviewer: Wie viel wissen Sie über hohe Parallelität? Ich: emmm...
Jul 26, 2023 pm 04:07 PM
Interviewer: Wie viel wissen Sie über hohe Parallelität? Ich: emmm...
Jul 26, 2023 pm 04:07 PM
Hohe Parallelität ist eine Erfahrung, die fast jeder Programmierer haben möchte. Der Grund ist einfach: Wenn der Datenverkehr zunimmt, treten verschiedene technische Probleme auf, z. B. Zeitüberschreitungen bei der Schnittstellenantwort, erhöhte CPU-Auslastung, häufiger GC, Deadlock, großer Datenspeicher usw. Diese Probleme können uns bei der kontinuierlichen Verbesserung der technischen Tiefe unterstützen.
 Teilen von hochfrequenten Vue-Interviewfragen im Jahr 2023 (mit Antwortanalyse)
Aug 01, 2022 pm 08:08 PM
Teilen von hochfrequenten Vue-Interviewfragen im Jahr 2023 (mit Antwortanalyse)
Aug 01, 2022 pm 08:08 PM
Dieser Artikel fasst für Sie einige ausgewählte Fragen zu Vue-Hochfrequenzinterviews im Jahr 2023 (mit Antworten) zusammen, die es wert sind, gesammelt zu werden. Es hat einen gewissen Referenzwert. Freunde in Not können sich darauf beziehen. Ich hoffe, es wird für alle hilfreich sein.
 Werfen Sie einen Blick auf diese Front-End-Interviewfragen, die Ihnen helfen, hochfrequente Wissenspunkte zu meistern (4)
Feb 20, 2023 pm 07:19 PM
Werfen Sie einen Blick auf diese Front-End-Interviewfragen, die Ihnen helfen, hochfrequente Wissenspunkte zu meistern (4)
Feb 20, 2023 pm 07:19 PM
10 Fragen pro Tag. Nach 100 Tagen beherrschen Sie alle hochfrequenten Wissenspunkte von Front-End-Interviews. ! ! Ich hoffe, dass Sie beim Lesen des Artikels nicht direkt auf die Antwort schauen, sondern zunächst darüber nachdenken, ob Sie sie wissen, und wenn ja, wie lautet Ihre Antwort? Denken Sie darüber nach und vergleichen Sie sie dann mit der Antwort. Wenn Sie eine bessere Antwort als meine haben, hinterlassen Sie bitte eine Nachricht im Kommentarbereich und diskutieren Sie gemeinsam über die Schönheit der Technologie.
 Fassen Sie einige häufig gestellte Front-End-Interviewfragen (mit Antworten) zusammen, um Ihr Wissen zu festigen!
Jul 29, 2022 am 09:49 AM
Fassen Sie einige häufig gestellte Front-End-Interviewfragen (mit Antworten) zusammen, um Ihr Wissen zu festigen!
Jul 29, 2022 am 09:49 AM
Der Hauptzweck der Veröffentlichung von Artikeln besteht darin, mein Wissen zu festigen und kompetenter zu werden. Alles basiert auf meinem eigenen Verständnis und den Informationen, die ich online gesucht habe. Ich hoffe, Sie können mir einen Rat geben. Im Folgenden habe ich einige häufig gestellte Interviewfragen zusammengefasst. Ich werde sie weiterhin aktualisieren, um mich selbst zu überwachen.
