
 Datenbank
SQL
Warum erfordern Codespezifikationen, dass SQL-Anweisungen nicht zu viele Joins haben?
Datenbank
SQL
Warum erfordern Codespezifikationen, dass SQL-Anweisungen nicht zu viele Joins haben?
Warum erfordern Codespezifikationen, dass SQL-Anweisungen nicht zu viele Joins haben?
Unterfrage senden
Interviewer: Haben Sie jemals Linux bedient?
Ich: Ja
Interviewer:Welchen Befehl soll ich verwenden, um die Speichernutzung zu überprüfen
Ich:kostenlos oder oben
Interviewer:Können Sie mir sagen, welche Informationen Sie mit dem kostenlosen Befehl sehen können?
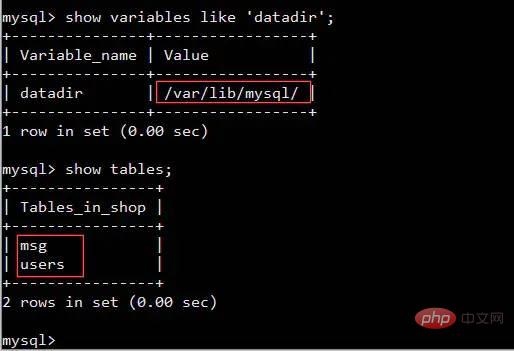
Ich:Nun, wie in der Abbildung unten gezeigt, können Sie die Speicher- und Cachenutzung sehen.
Gesamtsumme Speicher
gebrauchter verwendeter Speicher
freier freier Speicher
buff/cache verwendeter Cache
verfügbarer verfügbarer Speicher

Interviewer: Wissen Sie dann, wie man den verwendeten Cache (Buff/Cache) löscht
?Ich: em... Ich weiß nicht
Interviewer: sync; echo 3 > /proc/sys/vm/drop_caches Können Sie mir dann sagen, ob ich diesen Befehl online ausführen kann?

em…., gehen Sie zurück und warten Sie auf Benachrichtigung
Lassen Sie uns noch einmal über SQL Join sprechenInterviewer:
Wechseln Sie das Thema und sprechen Sie über Ihr Verständnis von Join
Ich:Okay (wenn Sie es noch einmal falsch beantworten, ist es vorbei) Ergreifen Sie die Gelegenheit.)
innerer Beitritt, innerer Beitritt
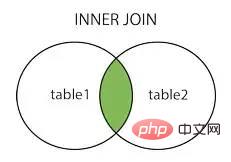
Linker Beitritt, Linker Beitritt
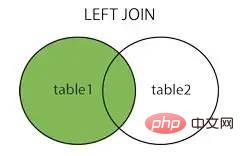
Rechter Beitritt, Rechter Beitritt
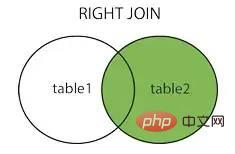
vollständige Teilnahme

Bildquelle: https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
Interviewer: Wenn Sie während der Projektentwicklung Join-Anweisungen verwenden müssen, wie können Sie die Leistung optimieren und verbessern?
Ich:Es gibt zwei Situationen, eine mit kleiner Datengröße und eine mit großer Datengröße.
Interviewer:Dann?
Ich:Für 1. Wenn die Datengröße klein ist, legen Sie einfach alles in den Speicher und das war's
2. Wenn die Datengröße groß ist
- , Sie können den Index erhöhen. Optimieren Sie die Ausführungsgeschwindigkeit von Join-Anweisungen.
- Sie können die Anzahl der Joins durch redundante Informationen reduzieren.
- Versuchen Sie, die Anzahl der Tabellenverbindungen zu reduzieren für eine SQL-Anweisung sollte das 5-fache nicht überschritten werden
Zusammenfassend lässt sich sagen, dass die Join-Anweisung relativ leistungsintensiv ist, oder?
Ich:Ja
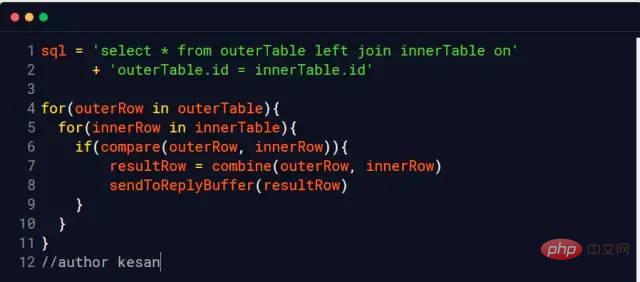
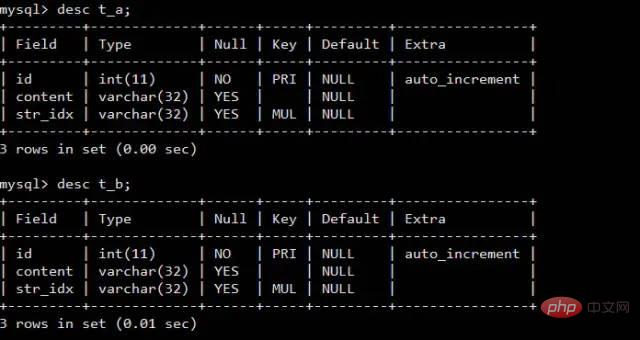
Interviewer:Warum? Ich: Beim Ausführen der Join-Anweisung muss ein Vergleichsprozess stattfinden Interviewer: Ja Ich:Es ist relativ langsam, zwei Tabellen einzeln zu vergleichen, also können wir Lesen Sie die Daten in den beiden Tabellen nacheinander in einen Speicherblock. Am Beispiel der InnoDB-Engine von MySQL können wir den relevanten Speicherbereich mithilfe der folgenden Anweisung definitiv finden join_buffer_size Die Größe wird beeinflusst Die Ausführungsleistung unserer Join-Anweisung. Interviewer: Interviewer: Nehmen Sie als Beispiel die InnoDB-Engine von MySQL InnoDB verwendet eine Seite als grundlegende E/A-Einheit und die Größe jeder Seite beträgt 16 KB. InnoDB erstellt einen Speicher für jede Tabellendaten-.ibd-Datei Ich:Das bedeutet, dass wir so viele Dateien lesen müssen, wie es Tabellen zum Verbinden gibt, häufige Bewegungen sind jedoch immer noch unvermeidlich die Festplatte Interviewer:Das heißt, häufige Bewegungen des Magnetkopfes wirken sich auf die Leistung aus, oder? Ich:Ja, sagen aktuelle Open-Source-Frameworks nicht gerne, dass sie die Leistung erheblich verbessern durch sequentielles Lesen und Schreiben? , wie hbase, kafka Interviewer: Stimmt, glauben Sie, dass Linux dies optimiert hat? Tipp, Sie können den kostenlosen Befehl erneut ausführen, um einen Blick darauf zu werfen Ich: Seltsam wie Der Cache ist mit mehr als 1,2 GB belegt Bildquelle: https://www.linuxatemyram.com/ Interviewer: Haben Sie jemals darüber nachgedacht buff/ im Cache gespeichert Was Ist? Warum belegt Buff/Cache so viel Speicher und der verfügbare Speicher ist verfügbar und es sind immer noch 1,1 GB vorhanden? Warum kann man den von Buff/Cache belegten Speicher mit zwei Befehlen bereinigen, den belegten Speicher aber nur durch Beenden des Vorgangs freigeben? Interviewer: Ich: Könnte es sein? Ich denke an einen Satz in „CSAPP“ (Deep Understanding of Computer Systems) Das Wesen der Speicherhierarchie besteht darin, dass jede Schicht des Speichergeräts der Cache des Geräts der unteren Schicht ist Für Laien Begrifflich, Das heißt, Linux behandelt den Speicher als Cache der Festplatte Zugehörige Informationen: http://tldp.org/LDP/sag/html/buffer-cache.html Interviewer: Jetzt weiß ich: Wie soll ich die Punktefrage beantworten? Ich: Ich... Interviewer: Gib dir noch eine Chance, was würdest du tun, wenn du gefragt würdest? den Join-Algorithmus implementieren? Ich: Wenn kein Index vorhanden ist, wird die verschachtelte Schleife beendet. Wenn ein Index vorhanden ist, können Sie den Index verwenden, um die Leistung zu verbessern. Interviewer: Zurück zu join_buffer, was ist Ihrer Meinung nach in join_buffer gespeichert? Ich: Während des Scanvorgangs wählt die Datenbank eine Tabelle aus und fügt die Daten ein, die sie zurückgeben und mit anderen Tabellen vergleichen muss .join_buffer Interviewer: Wie gehe ich damit um, wenn ein Index vorhanden ist? Ich: Das ist relativ einfach. Lesen Sie einfach die Indexbäume der beiden Tabellen und vergleichen Sie sie. Lassen Sie mich die indexfreie Verarbeitungsmethode vorstellen Lesen Sie jeweils eine Datenzeile in der Tabelle. Das heißt, wenn die äußere Tabelle 100.000 Datenzeilen und die innere Tabelle 100 Datenzeilen enthält, muss sie 10.000.000 Mal gelesen werden (vorausgesetzt, die Dateien dieser beiden Tabellen). wurden nicht ausgeführt) Das System speichert es im Speicher, wir nennen es eine kalte Datentabelle) Natürlich verwendet jetzt keine Datenbank-Engine diesen Algorithmus (zu langsam) Blockieren Block, das heißt, es heißt, dass jedes Mal ein Datenelement in den Speicher abgerufen wird, um den E/A-Overhead zu reduzieren MySQL InnoDB verwendet diesen Algorithmus, wenn kein Index verwendet werden kann. Berücksichtigen Sie die folgenden beiden Tabellen t_a und t_b ZusammenfassungPuffer
show variables like '%buffer%'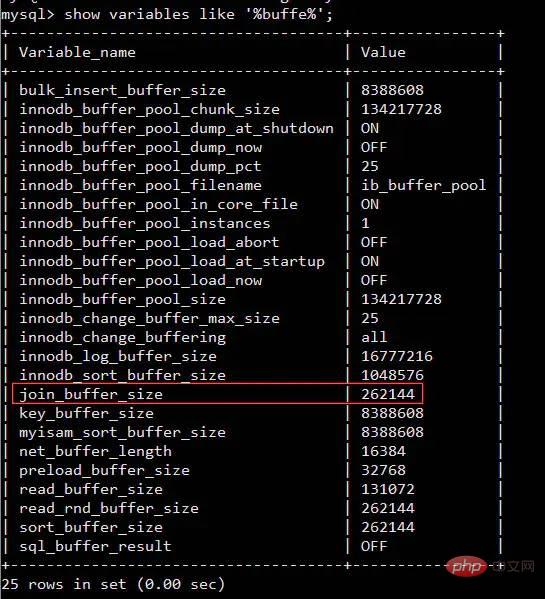
Ich:
Die meisten Daten in der Datenbank werden irgendwann auf der Festplatte gespeichert und in Form von Dateien gespeichert.
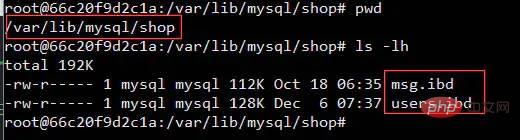


Den von Buff/Cache belegten Speicher so beiläufig freizugeben bedeutet, dass er nicht wichtig ist und das Löschen keinen Einfluss auf den Betrieb des Systems hat

Join-Algorithmus
 Als ich in der Schule war, machte der Datenbanklehrer am liebsten den Datenbankparadigmentest. Erst bei der Arbeit lernte ich, dass alles auf Leistung basieren sollte, wenn es überflüssig sein kann , verwenden Sie es. Wenn es nicht redundant sein kann, schließen Sie es an, wenn es sich wirklich auf die Leistung auswirkt. Versuchen Sie, die Größe Ihres „join_buffer_size“ zu erhöhen, oder wechseln Sie zu einem Solid-State-Laufwerk.
Als ich in der Schule war, machte der Datenbanklehrer am liebsten den Datenbankparadigmentest. Erst bei der Arbeit lernte ich, dass alles auf Leistung basieren sollte, wenn es überflüssig sein kann , verwenden Sie es. Wenn es nicht redundant sein kann, schließen Sie es an, wenn es sich wirklich auf die Leistung auswirkt. Versuchen Sie, die Größe Ihres „join_buffer_size“ zu erhöhen, oder wechseln Sie zu einem Solid-State-Laufwerk. Referenzen
„Vertiefendes Verständnis von Computersystemen“ – Kapitel 6 Speicherhierarchie „Experimente und Spaß mit dem Linux-Festplatten-Cache“ Der Autor veranschaulicht anhand mehrerer Beispiele den Einfluss des Festplatten-Caches auf die Programmausführungsleistung "Linux hat meinen RAM gefressen》Erklärung der freien ParameterSo leeren Sie den Puffer/Pagecache (Festplatten-Cache) unter Linux.Erklärung des Unterfragebefehls am Anfang des Artikels
Wie MySQL ausgeführt wird: MySQL von der Wurzel aus verstehenBlock bested-Loop von MariaDB Das offizielle Dokument erklärt die Implementierung des Block-Nested-Loop-Algorithmus
Das obige ist der detaillierte Inhalt vonWarum erfordern Codespezifikationen, dass SQL-Anweisungen nicht zu viele Joins haben?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Was ist der Unterschied zwischen HQL und SQL im Hibernate-Framework?
Apr 17, 2024 pm 02:57 PM
Was ist der Unterschied zwischen HQL und SQL im Hibernate-Framework?
Apr 17, 2024 pm 02:57 PM
HQL und SQL werden im Hibernate-Framework verglichen: HQL (1. Objektorientierte Syntax, 2. Datenbankunabhängige Abfragen, 3. Typsicherheit), während SQL die Datenbank direkt betreibt (1. Datenbankunabhängige Standards, 2. Komplexe ausführbare Datei). Abfragen und Datenmanipulation).
 Verwendung der Divisionsoperation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Verwendung der Divisionsoperation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
„Verwendung der Divisionsoperation in OracleSQL“ In OracleSQL ist die Divisionsoperation eine der häufigsten mathematischen Operationen. Während der Datenabfrage und -verarbeitung können uns Divisionsoperationen dabei helfen, das Verhältnis zwischen Feldern zu berechnen oder die logische Beziehung zwischen bestimmten Werten abzuleiten. In diesem Artikel wird die Verwendung der Divisionsoperation in OracleSQL vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Zwei Arten von Divisionsoperationen in OracleSQL In OracleSQL können Divisionsoperationen auf zwei verschiedene Arten durchgeführt werden.
 Vergleich und Unterschiede der SQL-Syntax zwischen Oracle und DB2
Mar 11, 2024 pm 12:09 PM
Vergleich und Unterschiede der SQL-Syntax zwischen Oracle und DB2
Mar 11, 2024 pm 12:09 PM
Oracle und DB2 sind zwei häufig verwendete relationale Datenbankverwaltungssysteme, die jeweils über ihre eigene, einzigartige SQL-Syntax und -Eigenschaften verfügen. In diesem Artikel werden die SQL-Syntax von Oracle und DB2 verglichen und unterschieden und spezifische Codebeispiele bereitgestellt. Datenbankverbindung Verwenden Sie in Oracle die folgende Anweisung, um eine Verbindung zur Datenbank herzustellen: CONNECTusername/password@database. In DB2 lautet die Anweisung zum Herstellen einer Verbindung zur Datenbank wie folgt: CONNECTTOdataba
 Ausführliche Erläuterung der Funktion „Tag festlegen' in den dynamischen SQL-Tags von MyBatis
Feb 26, 2024 pm 07:48 PM
Ausführliche Erläuterung der Funktion „Tag festlegen' in den dynamischen SQL-Tags von MyBatis
Feb 26, 2024 pm 07:48 PM
Interpretation der dynamischen SQL-Tags von MyBatis: Detaillierte Erläuterung der Verwendung von Set-Tags. MyBatis ist ein hervorragendes Persistenzschicht-Framework. Es bietet eine Fülle dynamischer SQL-Tags und kann Datenbankoperationsanweisungen flexibel erstellen. Unter anderem wird das Set-Tag zum Generieren der SET-Klausel in der UPDATE-Anweisung verwendet, die sehr häufig bei Aktualisierungsvorgängen verwendet wird. In diesem Artikel wird die Verwendung des Set-Tags in MyBatis ausführlich erläutert und seine Funktionalität anhand spezifischer Codebeispiele demonstriert. Was ist Set-Tag? Set-Tag wird in MyBati verwendet
 Was bedeutet das Identitätsattribut in SQL?
Feb 19, 2024 am 11:24 AM
Was bedeutet das Identitätsattribut in SQL?
Feb 19, 2024 am 11:24 AM
Was ist Identität in SQL? In SQL ist Identität ein spezieller Datentyp, der zum Generieren automatisch inkrementierender Zahlen verwendet wird. Er wird häufig verwendet, um jede Datenzeile in einer Tabelle eindeutig zu identifizieren. Die Spalte „Identität“ wird oft in Verbindung mit der Primärschlüsselspalte verwendet, um sicherzustellen, dass jeder Datensatz eine eindeutige Kennung hat. In diesem Artikel wird die Verwendung von Identity detailliert beschrieben und es werden einige praktische Codebeispiele aufgeführt. Die grundlegende Möglichkeit, Identity zu verwenden, besteht darin, Identit beim Erstellen einer Tabelle zu verwenden.
 So implementieren Sie Springboot+Mybatis-plus, ohne SQL-Anweisungen zum Hinzufügen mehrerer Tabellen zu verwenden
Jun 02, 2023 am 11:07 AM
So implementieren Sie Springboot+Mybatis-plus, ohne SQL-Anweisungen zum Hinzufügen mehrerer Tabellen zu verwenden
Jun 02, 2023 am 11:07 AM
Wenn Springboot + Mybatis-plus keine SQL-Anweisungen zum Hinzufügen mehrerer Tabellen verwendet, werden die Probleme, auf die ich gestoßen bin, durch die Simulation des Denkens in der Testumgebung zerlegt: Erstellen Sie ein BrandDTO-Objekt mit Parametern, um die Übergabe von Parametern an den Hintergrund zu simulieren dass es äußerst schwierig ist, Multi-Table-Operationen in Mybatis-plus durchzuführen. Wenn Sie keine Tools wie Mybatis-plus-join verwenden, können Sie nur die entsprechende Mapper.xml-Datei konfigurieren und die stinkende und lange ResultMap konfigurieren Schreiben Sie die entsprechende SQL-Anweisung. Obwohl diese Methode umständlich erscheint, ist sie äußerst flexibel und ermöglicht es uns
 So beheben Sie den 5120-Fehler in SQL
Mar 06, 2024 pm 04:33 PM
So beheben Sie den 5120-Fehler in SQL
Mar 06, 2024 pm 04:33 PM
Lösung: 1. Überprüfen Sie, ob der angemeldete Benutzer über ausreichende Berechtigungen zum Zugriff auf oder zum Betrieb der Datenbank verfügt, und stellen Sie sicher, dass der Benutzer über die richtigen Berechtigungen verfügt. 2. Überprüfen Sie, ob das Konto des SQL Server-Dienstes über die Berechtigung zum Zugriff auf die angegebene Datei verfügt Ordner und stellen Sie sicher, dass das Konto über ausreichende Berechtigungen zum Lesen und Schreiben der Datei oder des Ordners verfügt. 3. Überprüfen Sie, ob die angegebene Datenbankdatei von anderen Prozessen geöffnet oder gesperrt wurde. Versuchen Sie, die Datei zu schließen oder freizugeben, und führen Sie die Abfrage erneut aus . Versuchen Sie es als Administrator. Führen Sie Management Studio aus als usw.
 Wie verwende ich SQL-Anweisungen zur Datenaggregation und Statistik in MySQL?
Dec 17, 2023 am 08:41 AM
Wie verwende ich SQL-Anweisungen zur Datenaggregation und Statistik in MySQL?
Dec 17, 2023 am 08:41 AM
Wie verwende ich SQL-Anweisungen zur Datenaggregation und Statistik in MySQL? Datenaggregation und Statistiken sind sehr wichtige Schritte bei der Durchführung von Datenanalysen und Statistiken. Als leistungsstarkes relationales Datenbankverwaltungssystem bietet MySQL eine Fülle von Aggregations- und Statistikfunktionen, mit denen Datenaggregation und statistische Operationen problemlos durchgeführt werden können. In diesem Artikel wird die Methode zur Verwendung von SQL-Anweisungen zur Durchführung von Datenaggregation und Statistiken in MySQL vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Verwenden Sie zum Zählen die COUNT-Funktion. Die COUNT-Funktion wird am häufigsten verwendet
