
Als ich anfing, diesen Artikel zu schreiben, war ich ziemlich verwirrt, denn viele Informationen kann man online finden, indem man nach „Was passiert von der Eingabe der URL bis zur Seitenanzeige“ sucht? Darüber hinaus handelt es sich bei dieser Interviewfrage im Grunde um eine Pflichtfrage. Während des Interviews im Februar wusste ich zwar, was dabei passierte, aber als der Interviewer Schritt für Schritt Fragen stellte, waren viele Details nicht klar.
Der Zweck dieses Artikels besteht darin, das Wissen darüber zusammenzufassen und zu erweitern, was nach der Eingabe der URL passiert. Daher kann der Artikel kompliziert sein.
Der Gesamtvorgang ist wie folgt:
Wenn wir mit der Eingabe der URL in den Browser beginnen, gleicht der Browser tatsächlich bereits intelligent die mögliche URL ab und beginnt mit Suchen Sie in Verlaufseinträgen, Lesezeichen usw. nach der URL, die möglicherweise der eingegebenen Zeichenfolge entspricht, und geben Sie dann intelligente Eingabeaufforderungen ein, damit Sie die URL-Adresse vervollständigen können. Beim Chrome-Browser von Google wird die Webseite sogar direkt aus dem Cache angezeigt. Das heißt, die Seite wird angezeigt, bevor Sie die Eingabetaste drücken.
1. Sobald die Anfrage initiiert wird, löst der Browser zunächst den Domänennamen auf Datei der lokalen Festplatte anzeigen Gibt es Regeln, die diesem Domänennamen entsprechen? Wenn ja, verwenden Sie die IP-Adresse direkt in der Hosts-Datei.
2. Wenn die entsprechende IP-Adresse nicht in der lokalen Hosts-Datei gefunden werden kann, sendet der Browser eine DNS-Anfrage an den lokalen DNS-Server. Lokale DNS-Server werden im Allgemeinen von Ihrem Netzwerkzugangsserveranbieter bereitgestellt, z. B. China Telecom und China Mobile.
3. Nachdem die DNS-Anfrage für die von Ihnen eingegebene URL den lokalen DNS-Server erreicht hat, fragt der lokale DNS-Server zunächst seinen Cache-Eintrag ab. Wenn sich dieser Eintrag im Cache befindet, kann das Ergebnis direkt zurückgegeben werden ist eine rekursive Art der Abfrage. Wenn nicht, fragt der lokale DNS-Server auch den DNS-Root-Server ab.
4. Der Root-DNS-Server zeichnet nicht die spezifische Korrespondenz zwischen Domänennamen und IP-Adressen auf, sondern teilt dem lokalen DNS-Server mit, dass Sie zum Domänenserver gehen können, um mit der Abfrage fortzufahren und die Domänenserveradresse anzugeben. Dieser Prozess ist ein iterativer.
5. Der lokale DNS-Server stellt weiterhin Anfragen an den Domänenserver. In diesem Beispiel ist das Anforderungsobjekt der .com-Domänenserver. Nachdem der .com-Domänenserver die Anfrage erhalten hat, sendet er die Korrespondenz zwischen dem Domänennamen und der IP-Adresse nicht direkt zurück, sondern teilt dem lokalen DNS-Server die Adresse des Auflösungsservers für Ihren Domänennamen mit.
6. Schließlich sendet der lokale DNS-Server eine Anfrage an den Domänennamenauflösungsserver und empfängt dann eine Korrespondenz zwischen dem Domänennamen und der IP-Adresse. Der lokale DNS-Server gibt nicht nur die IP-Adresse an den Computer des Benutzers zurück Gibt diese Korrespondenz auch im Cache zurück, damit die Ergebnisse bei der nächsten Abfrage eines anderen Benutzers direkt zurückgegeben werden können, um den Netzwerkzugriff zu beschleunigen.
Das Bild unten erklärt diesen Prozess perfekt:

DNS (Domain Name System, Domain Name System) als verteilte Datenbank im Internet, die Domänennamen und IP-Adressen einander zuordnet, ermöglicht Benutzern einen bequemeren Zugriff auf das Internet, ohne sich etwas merken zu müssen Was kann verwendet werden? Die IP-Nummernzeichenfolge, die direkt vom Gerät gelesen wird. Der Prozess des endgültigen Erhaltens der dem Hostnamen entsprechenden IP-Adresse über den Hostnamen wird als Domänennamenauflösung (oder Hostnamenauflösung) bezeichnet.
Laienhaft ausgedrückt sind wir eher daran gewöhnt, uns den Namen einer Website zu merken, wie zum Beispiel www.baidu.com, als uns an ihre IP-Adresse zu erinnern, wie zum Beispiel: 167.23.10.2. Und Computer können sich die IP-Adresse einer Website besser merken als Links wie www.baidu.com. Da DNS einem Telefonbuch entspricht, wenn Sie beispielsweise nach dem Domainnamen www.baidu.com suchen, schaue ich in meinem Telefonbuch nach und erfahre, dass die Telefonnummer (IP) 167.23.10.2 ist .
1. Rekursive Analyse
Wenn der lokale DNS-Server selbst die DNS-Anfrage des Clients nicht beantworten kann, müssen Sie dies tun andere DNS-Server abfragen. Derzeit gibt es zwei Methoden. Die in der Abbildung gezeigte ist die rekursive Methode. Der lokale DNS-Server ist für die Abfrage anderer DNS-Server verantwortlich. Im Allgemeinen fragt er zuerst den Stammdomänenserver des Domänennamens ab und dann fragt der Stammdomänennamenserver eine Ebene nach der anderen ab. Das endgültige Abfrageergebnis wird an den lokalen DNS-Server zurückgegeben, und der lokale DNS-Server gibt es dann an den Client zurück.

2 Wenn der lokale DNS-Server selbst die DNS-Anfrage des Clients nicht beantworten kann, kann dies auch durch eine iterative Abfrage gelöst werden, wie in der Abbildung dargestellt. Der lokale DNS-Server fragt nicht selbst andere DNS-Server ab, sondern gibt die IP-Adressen anderer DNS-Server, die den Domänennamen auflösen können, an das Client-DNS-Programm zurück. Das Client-DNS-Programm fragt dann weiterhin diese DNS-Server ab, bis die Abfrageergebnisse vorliegen erhalten bis. Mit anderen Worten: Die iterative Analyse hilft Ihnen nur dabei, relevante Server zu finden, hilft Ihnen jedoch nicht dabei, diese zu überprüfen. Beispiel: Die Server-IP-Adresse von baidu.com lautet hier 192.168.4.5. Sie können es selbst überprüfen. Ich bin sehr beschäftigt, daher kann ich Ihnen hier nur helfen. Wir haben den Root-DNS-Server und den Domänen-DNS-Server bereits erwähnt. So ist der DNS-Domänennamenraum organisiert. In der folgenden Tabelle werden die fünf Kategorien vorgestellt, die zur Beschreibung von DNS-Domänennamen im Namespace entsprechend ihrer Funktionen verwendet werden, sowie Beispiele für jeden Namenstyp Wenn eine Website genügend Benutzer hat und sich die jedes Mal angeforderten Ressourcen auf demselben Computer befinden, kann der Computer jederzeit abstürzen. Die Lösung besteht darin, die DNS-Lastausgleichstechnologie zu verwenden. Ihr Prinzip besteht darin, mehrere IP-Adressen für denselben Hostnamen im DNS-Server zu konfigurieren. Bei der Beantwortung von DNS-Anfragen antwortet der DNS-Server auf jede Anfrage mit der vom Host aufgezeichneten IP-Adresse Geben Sie in der DNS-Datei unterschiedliche Analyseergebnisse der Reihe nach zurück, leiten Sie den Client-Zugriff auf verschiedene Computer, sodass verschiedene Clients auf unterschiedliche Server zugreifen und so einen Lastausgleich erreichen können Benutzer kann geografische Entfernung usw. sein. Nachdem der Browser die dem Domänennamen entsprechende IP-Adresse erhalten hat, verwendet er einen zufälligen Port (1024 TCP-Verbindung wie im Bild gezeigt: Initiieren Sie nach dem Herstellen der TCP-Verbindung eine http-Anfrage. Ein typischer HTTP-Anforderungsheader muss im Allgemeinen die Anforderungsmethode enthalten, z. B. GET oder POST. Weniger häufig verwendet werden die Methoden PUT und DELETE, HEAD, OPTION und TRACE. Allgemeine Browser können nur GET- oder POST-Anforderungen initiieren. Wenn der Client eine HTTP-Anfrage an den Server initiiert, gibt es einige Anforderungsinformationen: |. Anforderungsmethode-URI-Protokoll/-Version | |. Anforderungstext: Das Folgende ist ein vollständiges HTTP-Anforderungsbeispiel: (1) Die erste Zeile der Anfrage lautet „Vorschlag/Version der Methoden-URL“: GET/sample.jsp HTTP/1.1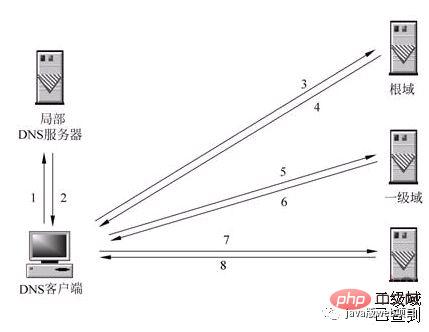
3) Wie der DNS-Domänennamenraum organisiert ist
 (Gestohlenes Bild)
(Gestohlenes Bild) 4) DNS-Lastausgleich
3. Der Browser sendet eine HTTP-Anfrage an den Webserver
<code><span style="font-size: 16px;">。</span>. Nachdem diese Verbindungsanforderung den Server erreicht hat (über verschiedene Routing-Geräte, außer im LAN), gelangt sie in die Netzwerkkarte und dann in den TCP/IP-Protokollstapel des Kernels (wird zur Identifizierung der Verbindungsanforderung verwendet). , Entkapseln Sie das Paket, ziehen Sie es Schicht für Schicht ab) und werden Sie möglicherweise auch von der Netfilter-Firewall (einem zum Kernel gehörenden Modul) gefiltert und erreichen Sie schließlich das WEB-Programm und stellen Sie schließlich eine TCP/IP-Verbindung her. 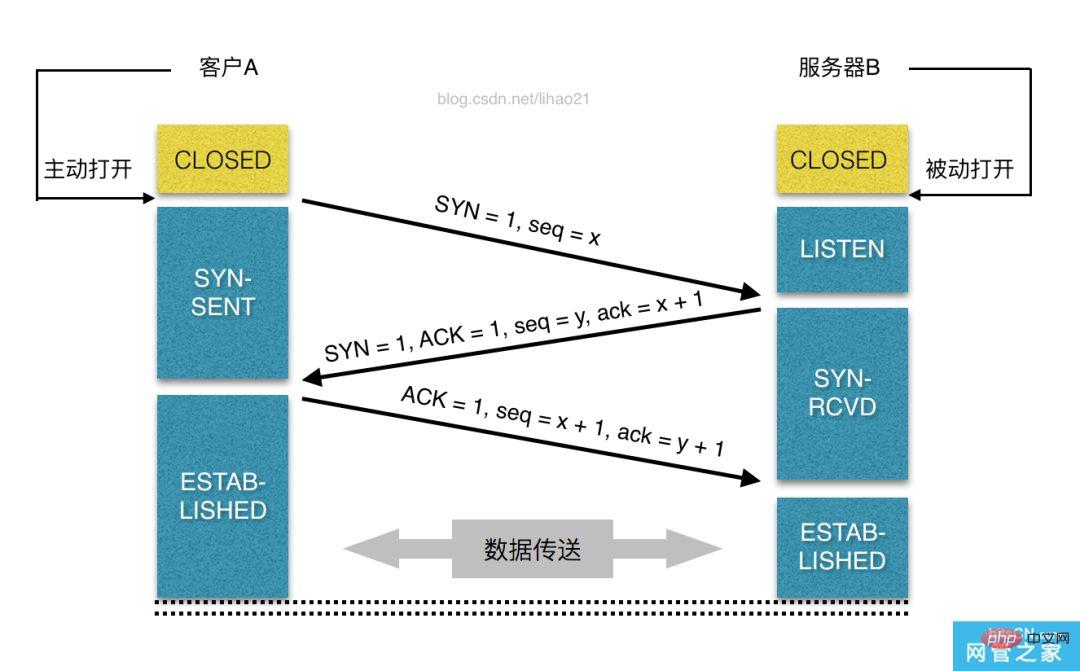
GET/sample.jspHTTP/1.1Accept:image/gif.image/jpeg,*/*Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234
(2) Anforderungsheader (Anforderungsheader)Accept:image/gif.image/jpeg.*/*
Accept-Language:zh-cn
Connection:Keep-Alive
Host:localhost
User-Agent:Mozila/4.0(compatible:MSIE5.01:Windows NT5.0)
Accept-Encoding:gzip,deflate.
username=jinqiao&password=1234
Warum muss der Server den Webseiteninhalt, den der Benutzer sehen möchte, umleiten, anstatt ihn direkt zu senden? Einer der Gründe hat mit Suchmaschinenrankings zu tun. Wenn eine Seite zwei Adressen hat, z. B. http://www.yy.com/ und http://yy.com/, denken Suchmaschinen, dass es sich um zwei Websites handelt. Infolgedessen wird jeder Suchlink reduziert Das Suchergebnis wird im Ranking reduziert. Die Suchmaschine weiß, was eine permanente 301-Weiterleitung bedeutet, und ordnet daher die URLs mit und ohne www im gleichen Website-Ranking ein. Außerdem verschlechtert die Verwendung unterschiedlicher Adressen die Cache-Freundlichkeit. Wenn eine Seite mehrere Namen hat, erscheint sie möglicherweise mehrmals im Cache.
Sowohl der 301- als auch der 302-Statuscode weisen auf eine Umleitung hin, was bedeutet, dass der Browser automatisch zu einer neuen URL-Adresse springt, nachdem er den vom Server zurückgegebenen Statuscode erhalten hat. Diese Adresse kann aus dem Location-Header der Antwort abgerufen werden Der Effekt, den der Benutzer sieht, besteht darin, dass sich die von ihm eingegebene Adresse A sofort in eine andere Adresse B) ändert – das ist ihre Gemeinsamkeit.
Ihr Unterschied ist. 301 bedeutet, dass die Ressource an der alten Adresse A dauerhaft entfernt wurde (auf diese Ressource kann nicht mehr zugegriffen werden). Die Suchmaschine tauscht beim Crawlen des neuen Inhalts auch die alte URL gegen die umgeleitete URL aus. 302 bedeutet dass die Ressource an der alten Adresse A noch vorhanden ist (immer noch erreichbar). Diese Weiterleitung springt nur vorübergehend von der alten Adresse A zur Adresse B. Die Suchmaschine crawlt den neuen Inhalt und speichert die alte URL. SEO302 ist besser als 301
2) Gründe für die Umleitung:
(1) Website-Anpassung (z. B. Änderung der Webverzeichnisstruktur); (2) Die Webseite wurde an eine neue Adresse verschoben ; (3) Änderung der Webseitenerweiterung (wenn die Anwendung .php in .Html oder .shtml ändern muss).
Wenn in diesem Fall keine Umleitung erfolgt, führt die alte Adresse in den Favoriten oder in der Suchmaschinendatenbank nur dazu, dass der besuchende Kunde eine 404-Seitenfehlermeldung erhält und der Zugriffsverkehr außerdem vergeblich verloren geht. Einige registrierte Websites mit mehreren Domainnamen müssen Benutzer, die diese Domainnamen besuchen, auch umleiten, um automatisch zur Hauptseite zu gelangen.
3) Wann sollte eine 301- oder 302-Weiterleitung durchgeführt werden?Wenn eine Website oder Webseite innerhalb von 24 bis 48 Stunden vorübergehend an einen neuen Ort verschoben wird, wird zu diesem Zeitpunkt ein 302-Sprung durchgeführt. Das Szenario bei der Verwendung von 301-Sprung besteht darin, dass die vorherige Website aus irgendeinem Grund entfernt werden muss. Dann ist der Zugriff auf die neue Adresse dauerhaft.
2. Der Domainname ohne www erscheint in den Suchergebnissen der Suchmaschine, aber der Domainname mit www ist nicht enthalten. Zu diesem Zeitpunkt können Sie der Suchmaschine mitteilen, welcher Domainname unser Ziel ist.
3. Der Space-Server ist beim Space-Wechsel instabil.
5. Browser-Tracking-Weiterleitungsadresse
Jetzt weiß der Browser, dass „http://www.google.com/“ die richtige Adresse für den Zugriff ist, und sendet daher eine weitere http-Anfrage. Hier gibt es nichts zu sagen
Nach den vorherigen Schritten haben wir unsere http-Anfrage tatsächlich bereits an den Server gesendet Wie sieht es mit der Bearbeitung unserer Anfragen aus?
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
如图所示:
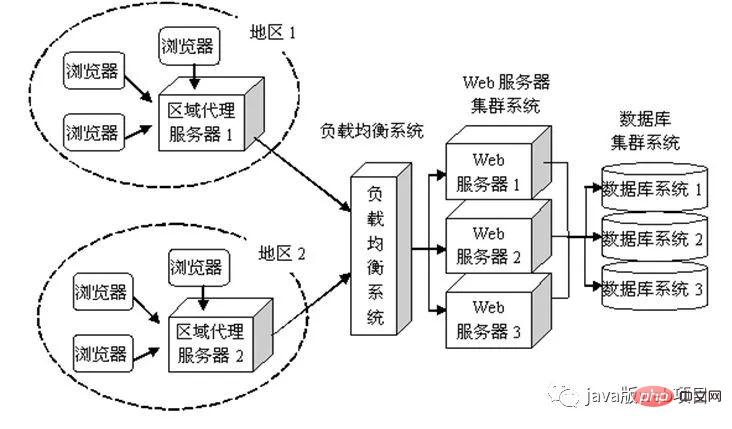
通过Nginx的反向代理,我们到达了web服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等,当然,这个过程涉及很多后端脚本的复杂操作。由于对这一块不熟,所以这一块只能介绍这么多了。
经过前面的6个步骤,服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个HTPP响应。
HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
l 状态行
l 响应头(Response Header)
l 响应正文
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122<html> <head> <title>http</title> </head><body> <!-- body goes here --> </body> </html>
状态行:
状态行由协议版本、数字形式的状态代码、及相应的状态描述,各元素之间以空格分隔。
格式: HTTP-Version Status-Code Reason-Phrase CRLF
例如: HTTP/1.1 200 OK
--Protokollversion: Ob http1.0 oder andere Versionen verwendet werden sollen
-- Statusbeschreibung: Die Statusbeschreibung enthält eine kurze Textbeschreibung des Statuscodes. Wenn der Statuscode beispielsweise 200 ist, ist die Beschreibung ok
-- Statuscode: Der Statuscode besteht aus drei Ziffern und definiert die Kategorie der Antwort und hat fünf mögliche Werte. Wie folgt:
1xx: Informationsstatuscode, der angibt, dass der Server die Client-Anfrage empfangen hat und der Client weiterhin Anfragen senden kann.
100 Weiter
101 Wechselprotokolle
2xx: Erfolgsstatuscode, der angibt, dass der Server die Anfrage erfolgreich empfangen und verarbeitet hat.
200 OK Zeigt an, dass die Client-Anfrage erfolgreich war
204 Kein Inhalt erfolgreich, gibt jedoch nicht den Hauptteil einer Entität zurück
206 Teilinhalt Eine Bereichsanforderung wurde erfolgreich ausgeführt
3xx : Umleitungsstatuscode, der angibt, dass der Server eine Umleitung des Clients erfordert.
301 Permanent verschoben Permanente Umleitung, der Standort-Header der Antwortnachricht sollte die neue URL der Ressource enthalten
302 Gefunden Temporäre Umleitung, die im Standort-Header der Antwortnachricht angegebene URL wird für den temporären Standort verwendet Ressource
303 Siehe Andere Die angeforderte Ressource hat einen anderen URI. Der Client sollte die GET-Methode verwenden, um die angeforderte Ressource abzurufen
304 Nicht geändert Der Serverinhalt wurde nicht aktualisiert und der Browser-Cache kann direkt gelesen werden
307 Temporäre Weiterleitung Temporäre Weiterleitung. Dieselbe Bedeutung wie 302 Gefunden. 302 verbietet die Konvertierung von POST in GET, dies ist jedoch in der tatsächlichen Verwendung nicht unbedingt der Fall. 307 Weitere Browser folgen möglicherweise diesem Standard, hängen jedoch auch von der spezifischen Implementierung des Browsers ab. 4xx: Client-Fehlerstatus Code: Zeigt an, dass die Anfrage des Clients illegale Inhalte enthält.
400 Bad Request bedeutet, dass die Client-Anfrage einen Syntaxfehler aufweist und vom Server nicht verstanden werden kann
401 Unauthorized bedeutet, dass die Anfrage nicht autorisiert ist. Dieser Statuscode muss mit dem WWW-Authenticate-Header-Feld verwendet werden
403 Verboten bedeutet, dass der Server Wenn eine Anfrage eingeht, der Dienst jedoch abgelehnt wird, wird der Grund für die Nichtbereitstellung des Dienstes normalerweise im Antworttext angegeben
404 Nicht gefunden Die angeforderte Ressource existiert nicht, z. B. ein Fehler URL wurde eingegeben
5xx: Serverfehlerstatuscode, der darauf hinweist, dass der Server die Anfrage des Clients nicht normal verarbeiten konnte und ein unerwarteter Fehler aufgetreten ist.
500 Internel-Serverfehler bedeutet, dass ein unerwarteter Fehler im Server aufgetreten ist, der dazu führt, dass die Anfrage des Clients nicht abgeschlossen werden kann.
503 Dienst nicht verfügbar bedeutet, dass der Server die Anfrage des Clients derzeit nicht verarbeiten kann Mit der Zeit kehrt der Server möglicherweise zum Normalzustand zurück
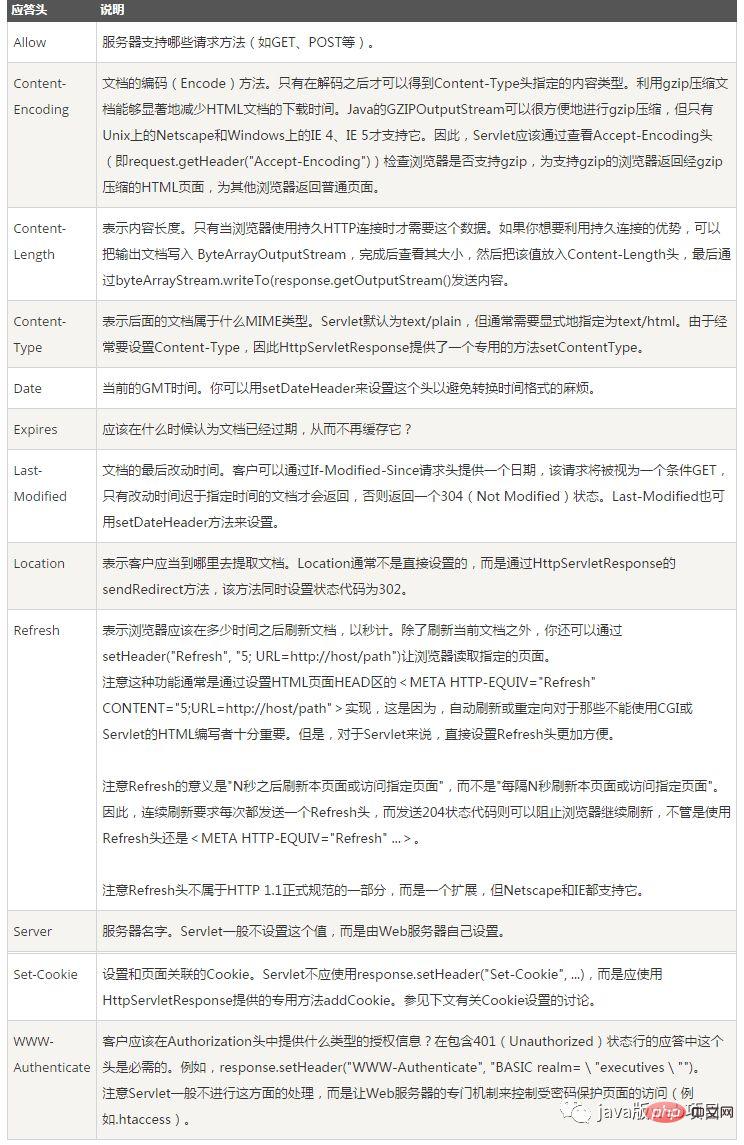
Antwortheader:
Antwortheader: bestehend aus Schlüsselwort-/Wertpaaren, ein Paar pro Zeile, Schlüsselwörter und Werte werden durch einen englischen Doppelpunkt getrennt: Typische Antwortheader sind:
Der Antworttext
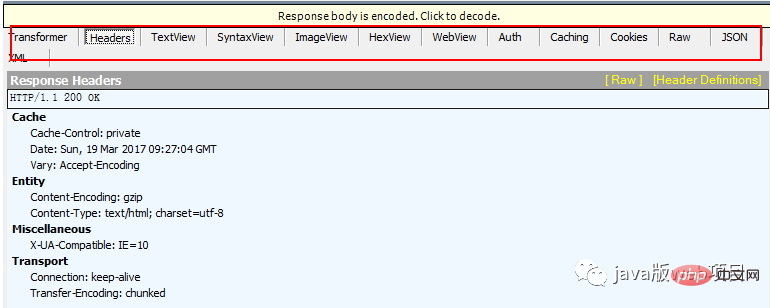
enthält einige spezifische Informationen, die wir benötigen, wie Cookies, HTML, Bilder, vom Backend zurückgegebene Anforderungsdaten usw. Hierbei ist zu beachten, dass zwischen dem Antworttext und dem Antwortheader eine Leerzeile vorhanden ist, was darauf hinweist, dass die Antwortheaderinformationen bis zum Leerzeichen reichen. Das Bild unten zeigt den von Fiddler erfassten Anforderungstext im roten Feld: Antworttext:
Wenn der Browser nicht alle HTML-Dokumente vollständig akzeptiert, hat er bereits mit der Anzeige dieser Seite begonnen Bildschirm? Verschiedene Browser verfügen möglicherweise über unterschiedliche Analyseprozesse. Hier stellen wir nur den Rendering-Prozess von WebKit vor HTML analysieren, um DOM-Baum zu erstellen-> Render-Baum erstellen-> Render-Baum zeichnen-> Wenn der Browser die HTML-Datei analysiert, wird sie „von oben nach unten“ geladen. . Und während des Ladevorgangs Parsing und Rendering durchführen. Wenn während des Parsing-Prozesses eine Anforderung für externe Ressourcen wie Bilder, externes Link-CSS, Iconfont usw. vorliegt, ist der Anforderungsprozess asynchron und hat keinen Einfluss auf das Laden des HTML-Dokuments. Jedes Element im DOM-Knoten liegt in Form eines Boxmodells vor, für das der Browser seine Position und Größe berechnen muss. Dieser Vorgang wird als Relow bezeichnet as Nachdem Farbe, Schriftart usw. festgelegt wurden, beginnt der Browser mit dem Zeichnen des Inhalts. Dieser Vorgang wird als Repaint bezeichnet. Wenn die Seite zum ersten Mal geladen wird, kommt es unweigerlich zu Reflow und Repain. Der Reflow- und Repain-Prozess ist sehr leistungsintensiv, insbesondere auf Mobilgeräten. Er beeinträchtigt das Benutzererlebnis und führt manchmal zum Einfrieren der Seite. Deshalb sollten wir Reflow und Repain so wenig wie möglich reduzieren.
Wenn beim Laden des Dokuments auf eine js-Datei gestoßen wird, unterbricht das HTML-Dokument den Rendering-Thread (Laden, Parsen und Rendering-Synchronisation) und wartet nicht nur darauf, dass die js-Datei im Dokument geladen wird , aber auch darauf warten, dass die Analyse ausgeführt wird. Nach Abschluss kann der Rendering-Thread des HTML-Dokuments fortgesetzt werden. Da JS das DOM, das klassischste Dokument, ändern kann, bedeutet dies, dass der anschließende Download aller Ressourcen möglicherweise nicht erforderlich ist, bevor die JS-Ausführung abgeschlossen ist. Dies ist der Hauptgrund, warum js nachfolgende Ressourcen-Downloads blockiert. Ich verstehe also, dass im üblichen Code js am Ende des HTML-Dokuments platziert wird. Der Ausführungsmechanismus von JS kann als Hauptthread plus Aufgabenwarteschlange betrachtet werden. Synchrone Aufgaben sind Aufgaben, die im Hauptthread ausgeführt werden, und asynchrone Aufgaben sind Aufgaben, die in der Aufgabenwarteschlange platziert werden. Alle synchronen Aufgaben werden im Hauptthread ausgeführt und bilden einen Ausführungsstapel. Wenn das Skript ausgeführt wird, wird ein Ereignis in die Aufgabenwarteschlange gestellt Extrahieren Sie dann das Ereignis aus der Aufgabenwarteschlange und führen Sie es aus. Bei Aufgaben in der Aufgabenwarteschlange wird dieser Vorgang kontinuierlich wiederholt und wird daher auch als Ereignisschleife bezeichnet. Für den konkreten Prozess können Sie meinen Artikel lesen: Klicken Sie hier Tatsächlich kann dieser Schritt mit Schritt 8 parallelisiert werden. Wenn der Browser HTML anzeigt , wird die Notwendigkeit erkannt, Tags für andere Adressinhalte abzurufen. Zu diesem Zeitpunkt sendet der Browser eine Get-Anfrage zum Abrufen der Dateien. Ich möchte beispielsweise externe Bilder, CSS-, JS-Dateien usw. erhalten, ähnlich dem folgenden Link: Bild: http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/ 8q2anwu7.gif CSS-Stylesheet: http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css JavaScript-Datei: http://static.ak.fbcdn. net/rsrc.php/zEMOA/hash/c8yzb6ub.js Diese Adressen müssen einen Prozess durchlaufen, der dem HTML-Lesen ähnelt. Der Browser sucht also im DNS nach diesen Domänennamen, sendet Anfragen, leitet sie weiter usw. Im Gegensatz zu dynamischen Seiten können statische Dateien vom Browser zwischengespeichert werden. Einige Dateien müssen möglicherweise nicht mit dem Server kommunizieren, können aber direkt aus dem Cache gelesen oder in einem CDN abgelegt werden An diesem Punkt ist der Prozess von der Eingabe der URL bis zur Seitenanzeige endgültig abgeschlossen. Natürlich ist der Schreibstil eingeschränkt und es gibt eventuelle Fehler. Sie können gerne darauf hinweisen, dass dieser Artikel auf viele Artikel verweist, ich kann mich jedoch nicht an die Links zu vielen Artikeln erinnern, daher liste ich nur die folgenden drei Referenzlinks auf. 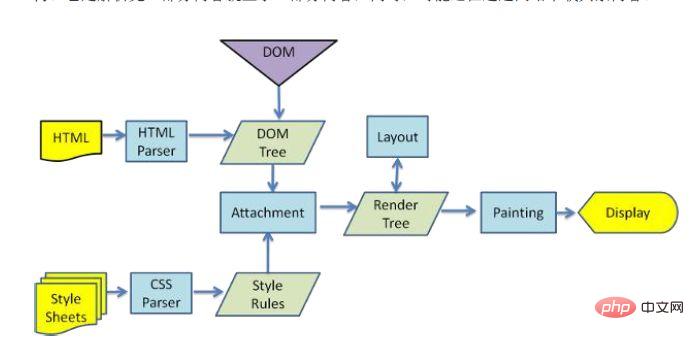 Während des Analysevorgangs analysiert der Browser zunächst die HTML-Datei, um einen DOM-Baum zu erstellen, und analysiert dann die CSS-Datei, um einen Rendering-Baum zu erstellen. Nachdem der Rendering-Baum erstellt wurde, beginnt der Browser mit dem Layout des Renderings Baum und zeichne ihn auf dem Bildschirm. Dieser Prozess ist relativ komplex und umfasst zwei Konzepte: Reflow und Repaint.
Während des Analysevorgangs analysiert der Browser zunächst die HTML-Datei, um einen DOM-Baum zu erstellen, und analysiert dann die CSS-Datei, um einen Rendering-Baum zu erstellen. Nachdem der Rendering-Baum erstellt wurde, beginnt der Browser mit dem Layout des Renderings Baum und zeichne ihn auf dem Bildschirm. Dieser Prozess ist relativ komplex und umfasst zwei Konzepte: Reflow und Repaint. 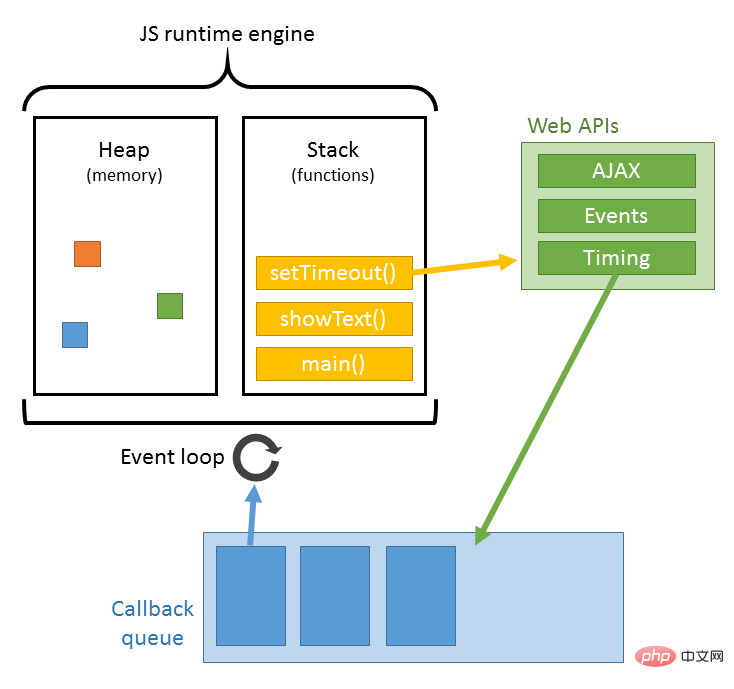
JS-Parsing wird durch die JS-Parsing-Engine im Browser abgeschlossen, z. B. Googles V8. JS läuft in einem einzelnen Thread, das heißt, es kann nur eine Aufgabe gleichzeitig ausführen. Die vorherige Aufgabe muss in die Warteschlange gestellt werden, bevor die nächste gestartet werden kann. Allerdings gibt es einige Aufgaben, die zeitaufwändig sind, wie z. B. das Lesen und Schreiben von E/A usw., daher ist ein Mechanismus erforderlich, um die späteren Aufgaben zuerst auszuführen, nämlich synchrone Aufgaben (synchron) und asynchrone Aufgaben (asynchron). 9. Der Browser sendet eine Anfrage zum Abrufen von in HTML eingebetteten Ressourcen (wie Bilder, Audio, Video, CSS, JS usw.)
Das obige ist der detaillierte Inhalt vonUnverzichtbare Fragen im Vorstellungsgespräch: Was passiert von der Eingabe der URL bis zur Seitenanzeige?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



