
 Datenbank
MySQL-Tutorial
Wie implementiert man server- und datenbankübergreifende Datenoperationen in MySQL?
Datenbank
MySQL-Tutorial
Wie implementiert man server- und datenbankübergreifende Datenoperationen in MySQL?
Wie implementiert man server- und datenbankübergreifende Datenoperationen in MySQL?

MySQL ist ein relationales Open-Source-Datenbankverwaltungssystem, das häufig zur Datenspeicherung und Verwaltung von Webanwendungen verwendet wird. In tatsächlichen Anwendungsszenarien müssen wir häufig server- und datenbankübergreifende Vorgänge für Daten implementieren, z. B. Datensynchronisierung, Datenmigration oder verteilte Datenverwaltung zwischen mehreren Datenbanken.
Im Folgenden werden die Methoden und Beispielcodes zur Implementierung server- und datenbankübergreifender Datenoperationen in MySQL vorgestellt.
- Verwendung der Federated Storage Engine
Die Federated Storage Engine ist eine von MySQL bereitgestellte Speicher-Engine. Mit dieser Speicher-Engine können wir eine Tabelle in einer MySQL-Instanz erstellen, die mit anderen MySQL-Servern verbunden ist, um serverübergreifende Datenoperationen durchzuführen.
Zuerst müssen wir die Federated Storage Engine auf dem MySQL-Server aktivieren. Fügen Sie die folgende Konfiguration in der my.cnf-Konfigurationsdatei hinzu:
[mysqld] federated = ON
Erstellen Sie dann eine Federated-Tabelle in der Datenbank und geben Sie die Informationen des Remote-MySQL-Servers an, mit dem eine Verbindung hergestellt werden soll:
CREATE TABLE federated_table (
id INT(11) AUTO_INCREMENT,
data VARCHAR(100),
PRIMARY KEY (id)
) ENGINE=FEDERATED
DEFAULT CHARSET=utf8
CONNECTION='mysql://[用户名]:[密码]@[远程MySQL服务器IP地址]:[端口号]/[数据库名]/[远程表名]';Im obigen Code [Benutzername], [Passwort] , [IP-Adresse des Remote-MySQL-Servers], [Portnummer], [Datenbankname], [Remote-Tabellenname] sollten entsprechend der tatsächlichen Situation ersetzt werden. Nach erfolgreicher Erstellung können wir serverübergreifende Datenoperationen durchführen, indem wir diese föderierte Tabelle bedienen.
- Verwenden Sie die Replikationsfunktion
Die Replikationsfunktion von MySQL kann Daten auf einem MySQL-Server auf andere MySQL-Server kopieren, um serverübergreifende Datenoperationen zu erreichen.
Konfigurieren Sie zunächst die Hauptdatenbank. Fügen Sie die folgende Konfiguration in der my.cnf-Konfigurationsdatei hinzu:
[mysqld] server-id=1 log_bin=mysql-bin binlog_format=row
Starten Sie dann den MySQL-Dienst neu.
Konfigurieren Sie in der Slave-Datenbank. Fügen Sie die folgende Konfiguration in der my.cnf-Konfigurationsdatei hinzu:
[mysqld] server-id=2
Starten Sie dann den MySQL-Dienst neu.
Erstellen Sie ein Replikationskonto in der Master-Datenbank und erteilen Sie Replikationsberechtigungen:
CREATE USER 'repl_user'@'从数据库IP地址' IDENTIFIED BY 'repl_password'; GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'从数据库IP地址';
Unter anderem muss die IP-Adresse der Slave-Datenbank durch die tatsächliche IP-Adresse der Slave-Datenbank ersetzt werden.
Überprüfen Sie dann den Dateinamen und den Speicherort des Binärprotokolls in der Hauptdatenbank:
SHOW MASTER STATUS;
Notieren Sie die Werte von Datei und Position.
Legen Sie die replizierten Informationen in der Slave-Datenbank fest:
CHANGE MASTER TO MASTER_HOST='主数据库IP地址', MASTER_USER='repl_user', MASTER_PASSWORD='repl_password', MASTER_LOG_FILE='二进制日志的文件名', MASTER_LOG_POS=二进制日志的位置;
Darunter muss die IP-Adresse der Master-Datenbank durch die tatsächliche IP-Adresse der Master-Datenbank ersetzt werden, und der Dateiname und der Speicherort des Binärprotokolls sollten die Werte verwenden im vorherigen Schritt aufgezeichnet.
Dann starten Sie den Replikationsprozess auf der Slave-Datenbank:
START SLAVE;
Sie können den Status des Replikationsprozesses über den Befehl SHOW SLAVE STATUSG anzeigen.
Auf diese Weise werden die Datenänderungsvorgänge in der Master-Datenbank mit der Slave-Datenbank synchronisiert, wodurch serverübergreifende Datenvorgänge realisiert werden.
Zusammenfassend kann MySQL über die Federated Storage Engine und die Replikationsreplikationsfunktion server- und datenbankübergreifende Datenoperationen realisieren. Entwickler können geeignete Methoden auswählen, um server- und datenbankübergreifende Datenoperationen basierend auf den tatsächlichen Anforderungen durchzuführen.
Die oben genannten Methoden und Beispielcodes für die Implementierung server- und datenbankübergreifender Datenoperationen in MySQL werden Ihnen hoffentlich weiterhelfen.
Das obige ist der detaillierte Inhalt vonWie implementiert man server- und datenbankübergreifende Datenoperationen in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Tutorial zur PyCharm-Nutzung: Führt Sie ausführlich durch die Ausführung des Vorgangs
Feb 26, 2024 pm 05:51 PM
Tutorial zur PyCharm-Nutzung: Führt Sie ausführlich durch die Ausführung des Vorgangs
Feb 26, 2024 pm 05:51 PM
PyCharm ist eine sehr beliebte integrierte Entwicklungsumgebung (IDE) für Python. Sie bietet eine Fülle von Funktionen und Tools, um die Python-Entwicklung effizienter und komfortabler zu gestalten. Dieser Artikel führt Sie in die grundlegenden Betriebsmethoden von PyCharm ein und stellt spezifische Codebeispiele bereit, um den Lesern einen schnellen Einstieg zu erleichtern und sich mit der Bedienung des Tools vertraut zu machen. 1. Laden Sie PyCharm herunter und installieren Sie es. Zuerst müssen wir zur offiziellen Website von PyCharm gehen (https://www.jetbrains.com/pyc).
 Was ist Sudo und warum ist es wichtig?
Feb 21, 2024 pm 07:01 PM
Was ist Sudo und warum ist es wichtig?
Feb 21, 2024 pm 07:01 PM
sudo (Superuser-Ausführung) ist ein Schlüsselbefehl in Linux- und Unix-Systemen, der es normalen Benutzern ermöglicht, bestimmte Befehle mit Root-Rechten auszuführen. Die Funktion von sudo spiegelt sich hauptsächlich in den folgenden Aspekten wider: Bereitstellung von Berechtigungskontrolle: sudo erreicht eine strikte Kontrolle über Systemressourcen und sensible Vorgänge, indem es Benutzern erlaubt, vorübergehend Superuser-Berechtigungen zu erhalten. Normale Benutzer können über sudo bei Bedarf nur vorübergehende Berechtigungen erhalten und müssen sich nicht ständig als Superuser anmelden. Verbesserte Sicherheit: Durch die Verwendung von sudo können Sie die Verwendung des Root-Kontos bei Routinevorgängen vermeiden. Die Verwendung des Root-Kontos für alle Vorgänge kann zu unerwarteten Systemschäden führen, da für jeden fehlerhaften oder nachlässigen Vorgang die vollen Berechtigungen gewährt werden. Und
 Schritte und Vorsichtsmaßnahmen für die Linux-Bereitstellung
Mar 14, 2024 pm 03:03 PM
Schritte und Vorsichtsmaßnahmen für die Linux-Bereitstellung
Mar 14, 2024 pm 03:03 PM
Betriebsschritte und Vorsichtsmaßnahmen für LinuxDeploy LinuxDeploy ist ein leistungsstarkes Tool, mit dem Benutzer schnell verschiedene Linux-Distributionen auf Android-Geräten bereitstellen können, sodass Benutzer ein vollständiges Linux-System auf ihren Mobilgeräten erleben können. In diesem Artikel werden die Betriebsschritte und Vorsichtsmaßnahmen von LinuxDeploy ausführlich vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern zu helfen, dieses Tool besser zu nutzen. Arbeitsschritte: LinuxDeploy installieren: Zuerst installieren
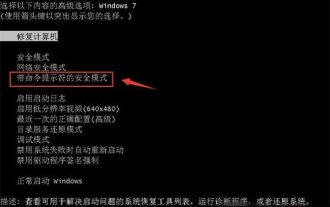 Was tun, wenn Sie vergessen, F2 für das Win10-Startkennwort zu drücken?
Feb 28, 2024 am 08:31 AM
Was tun, wenn Sie vergessen, F2 für das Win10-Startkennwort zu drücken?
Feb 28, 2024 am 08:31 AM
Vermutlich haben viele Benutzer zu Hause mehrere ungenutzte Computer und haben das Einschaltpasswort völlig vergessen, weil sie längere Zeit nicht benutzt wurden. Sie möchten also wissen, was zu tun ist, wenn sie das Passwort vergessen? Dann lasst uns gemeinsam einen Blick darauf werfen. Was tun, wenn Sie vergessen, F2 für das Win10-Startkennwort zu drücken? 1. Drücken Sie den Netzschalter des Computers und drücken Sie dann beim Booten F2 (verschiedene Computermarken haben unterschiedliche Tasten zum Aufrufen des BIOS). 2. Suchen Sie in der BIOS-Schnittstelle nach der Sicherheitsoption (der Speicherort kann je nach Computermarke unterschiedlich sein). Normalerweise im Einstellungsmenü oben. 3. Suchen Sie dann die Option „SupervisorPassword“ und klicken Sie darauf. 4. Zu diesem Zeitpunkt kann der Benutzer sein Passwort sehen und gleichzeitig die Option „Aktiviert“ daneben finden und auf „Dis“ umstellen.
 Huawei Mate60 Pro Screenshot-Bedienschritte teilen
Mar 23, 2024 am 11:15 AM
Huawei Mate60 Pro Screenshot-Bedienschritte teilen
Mar 23, 2024 am 11:15 AM
Mit der Beliebtheit von Smartphones ist die Screenshot-Funktion zu einer der wesentlichen Fähigkeiten für die tägliche Nutzung von Mobiltelefonen geworden. Als eines der Flaggschiff-Handys von Huawei hat die Screenshot-Funktion des Huawei Mate60Pro natürlich große Aufmerksamkeit bei den Nutzern auf sich gezogen. Heute werden wir die Screenshot-Bedienungsschritte des Huawei Mate60Pro-Mobiltelefons teilen, damit jeder bequemer Screenshots machen kann. Erstens bietet das Huawei Mate60Pro-Mobiltelefon eine Vielzahl von Screenshot-Methoden, und Sie können die Methode auswählen, die Ihren persönlichen Gewohnheiten entspricht. Im Folgenden finden Sie eine detaillierte Einführung in mehrere häufig verwendete Abfangfunktionen:
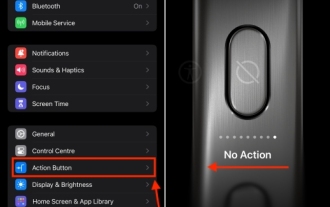 So deaktivieren Sie die Aktionstaste auf dem iPhone 15 Pro und 15 Pro Max
Nov 07, 2023 am 11:17 AM
So deaktivieren Sie die Aktionstaste auf dem iPhone 15 Pro und 15 Pro Max
Nov 07, 2023 am 11:17 AM
Apple brachte einige Pro-exklusive Hardwarefunktionen in das iPhone 15 Pro und 15 Pro Max ein, die die Aufmerksamkeit aller auf sich zogen. Wir sprechen von Titanrahmen, schlanken Designs, dem neuen A17 Pro-Chipsatz, einem aufregenden 5-fach-Teleobjektiv und mehr. Von all dem Schnickschnack, der den iPhone 15 Pro-Modellen hinzugefügt wurde, bleibt die Aktionstaste ein herausragendes und hervorstechendes Merkmal. Es versteht sich von selbst, dass es eine nützliche Ergänzung zum Starten von Aktionen auf Ihrem iPhone ist. Allerdings könnten Sie versehentlich die Aktionstaste gedrückt halten und die Funktion unbeabsichtigt auslösen. Ehrlich gesagt ist es ärgerlich. Um dies zu vermeiden, sollten Sie die Aktionstaste auf dem iPhone 15 Pro und 15 Pro Max deaktivieren. lassen
 CSS-Webseiten-Scroll-Überwachung: Überwachen Sie das Scrollen von Webseiten und führen Sie entsprechende Vorgänge aus
Nov 18, 2023 am 10:35 AM
CSS-Webseiten-Scroll-Überwachung: Überwachen Sie das Scrollen von Webseiten und führen Sie entsprechende Vorgänge aus
Nov 18, 2023 am 10:35 AM
CSS-Webseiten-Scroll-Überwachung: Überwachen Sie das Scrollen von Webseiten und führen Sie entsprechende Vorgänge aus. Mit der kontinuierlichen Entwicklung der Front-End-Technologie werden die Effekte und Interaktionen von Webseiten immer vielfältiger. Unter diesen ist die Scroll-Überwachung eine gängige Technologie, mit der einige Spezialeffekte oder Vorgänge basierend auf der Scroll-Position ausgeführt werden können, wenn der Benutzer auf der Webseite scrollt. Im Allgemeinen kann die Scroll-Überwachung über JavaScript implementiert werden. In einigen Fällen können wir den Effekt der Scroll-Überwachung jedoch auch durch reines CSS erzielen. In diesem Artikel wird erläutert, wie das Scrollen von Webseiten über CSS implementiert wird
 Benutzerdefinierte Aktionsschaltflächen: Entdecken Sie die Personalisierung auf dem iPhone 15 Pro
Sep 24, 2023 pm 03:05 PM
Benutzerdefinierte Aktionsschaltflächen: Entdecken Sie die Personalisierung auf dem iPhone 15 Pro
Sep 24, 2023 pm 03:05 PM
Apples iPhone 15 Pro und iPhone 15 Pro Max führen eine neue programmierbare Aktionstaste ein, die den herkömmlichen Klingel-/Stummschalter über den Lautstärketasten ersetzt. Lesen Sie weiter, um zu erfahren, was die Aktionsschaltfläche bewirkt und wie Sie sie anpassen können. Eine neue Aktionstaste bei Apple iPhone 15 Pro-Modellen ersetzt den herkömmlichen iPhone-Schalter, der Klingeln und Lautlos aktiviert. Standardmäßig aktiviert die neue Taste weiterhin beide Funktionen durch langes Drücken, aber Sie können durch langes Drücken auch eine Reihe anderer Funktionen ausführen, darunter Schnellzugriff auf die Kamera oder Taschenlampe, die Aktivierung von Sprachnotizen, den Fokusmodus, die Übersetzung usw Barrierefreiheitsfunktionen wie eine Lupe. Sie können es auch mit einer einzigen Verknüpfung verknüpfen, was eine Menge weiterer Möglichkeiten eröffnet
