
 Betrieb und Instandhaltung
Betrieb und Wartung von Linux
Ich weiß nicht, wie man die Linux-Firewall-Software IPtables verwendet! Was für ein Betriebs- und Wartungstyp sind Sie?
Betrieb und Instandhaltung
Betrieb und Wartung von Linux
Ich weiß nicht, wie man die Linux-Firewall-Software IPtables verwendet! Was für ein Betriebs- und Wartungstyp sind Sie?
Ich weiß nicht, wie man die Linux-Firewall-Software IPtables verwendet! Was für ein Betriebs- und Wartungstyp sind Sie?

Verbindungsverfolgung (conntrack)
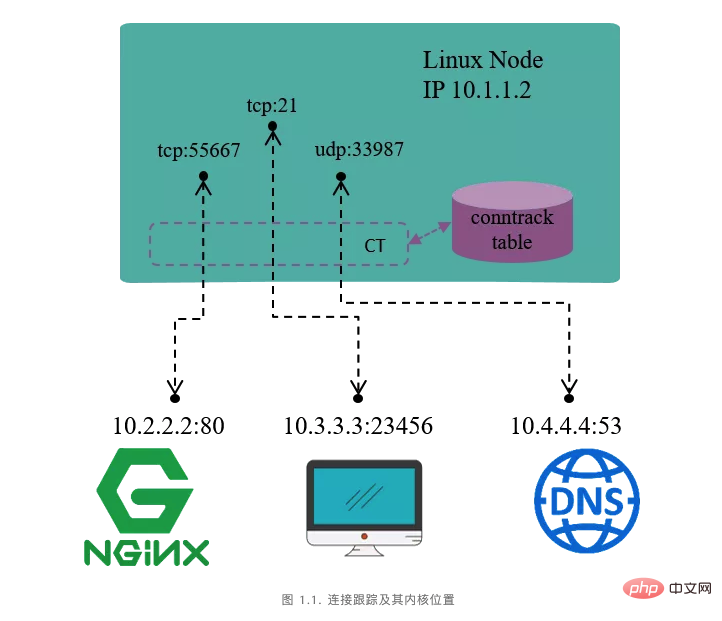
-
Die Verbindung für die Maschine, um auf den externen HTTP-Dienst (Ziel) zuzugreifen Port 80) Die Verbindung von der externen Zugriffsmaschine zum FTP-Dienst (Zielport 21) Die Verbindung von der Maschine zum externen DNS-Dienst (Zielport 53)
Tupelinformationen aus dem Datenpaket extrahieren, den Datenfluss (Flow) und die entsprechende Verbindung (Verbindung) identifizieren. Pflegen Sie eine Statusdatenbank (Conntrack-Tabelle) für alle Verbindungen, z. B. die Erstellungszeit der Verbindung, die Anzahl der gesendeten Pakete, die Anzahl der gesendeten Bytes usw. Abgelaufene Verbindungen (GC) wiederverwenden. Bereitstellung von Diensten für übergeordnete Funktionen (z. B. NAT).
In Beim TCP/IP-Protokoll handelt es sich bei der Verbindung um ein Layer-4-Konzept. TCP ist verbindungsorientiert und alle gesendeten Pakete erfordern eine Antwort (ACK) vom Peer, und es gibt einen Neuübertragungsmechanismus. UDP ist verbindungslos und die gesendeten Pakete erfordern keine Antwort vom Peer, und es gibt keinen Neuübertragungsmechanismus. In conntrack(CT) stellt ein durch ein Tupel (Tupel) definierter Datenfluss (Flow) eine Verbindung (Verbindung) dar. Wir werden später sehen, dass dreischichtige Protokolle wie UDP und sogar ICMP auch Verbindungsdatensätze in CT haben, aber nicht alle Protokolle werden verbunden.
Netfilter
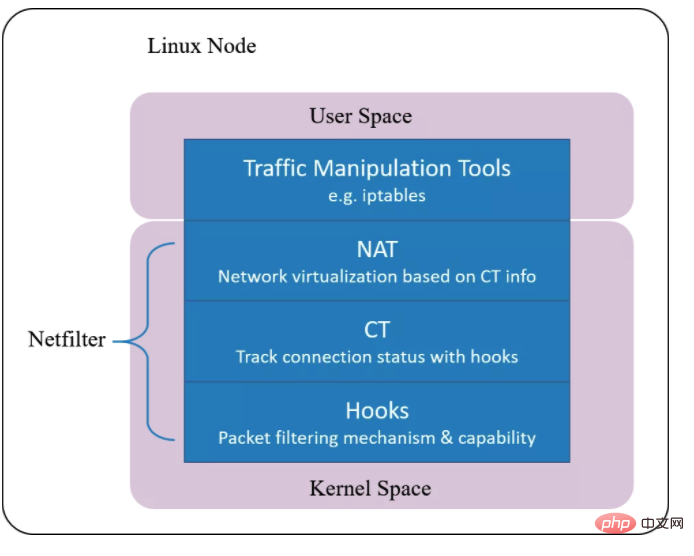
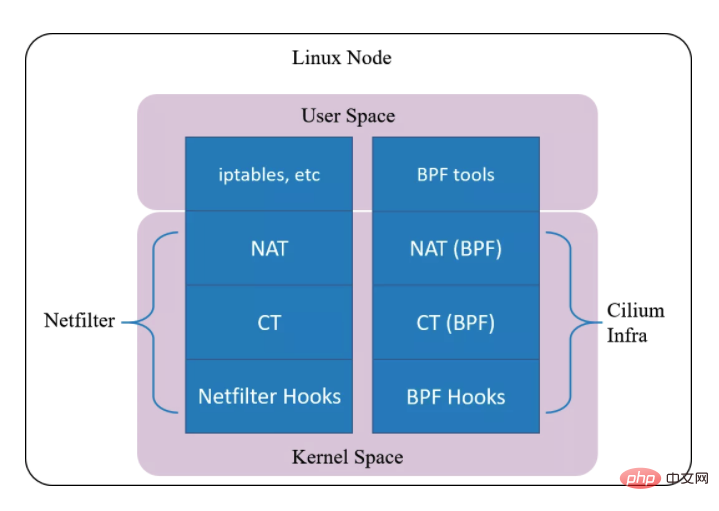
Implementieren Sie die Paketabfangfunktion basierend auf dem BPF-Hook (entspricht dem Hook-Mechanismus im Netfilter). Implementieren Sie basierend auf dem BPF-Hook einen neuen Satz von Conntrack und NAT. Daher sogar Wenn Netfilter deinstalliert wird, hat dies keine Auswirkungen auf die Unterstützung von Cilium für Funktionen wie Kubernetes ClusterIP, NodePort, ExternalIPs und LoadBalancer. Da dieser Verbindungsverfolgungsmechanismus unabhängig von Netfilter ist, werden seine Conntrack- und NAT-Informationen nicht in der Conntrack-Tabelle und der NAT-Tabelle des Kernels (d. h. Netfilters) gespeichert.Daher sind reguläre conntrack/netstats/ss/lsof und andere Tools nicht sichtbar. Sie müssen Cilium-Befehle verwenden, wie zum Beispiel:
$ cilium bpf nat list$ cilium bpf ct list global
Iptables
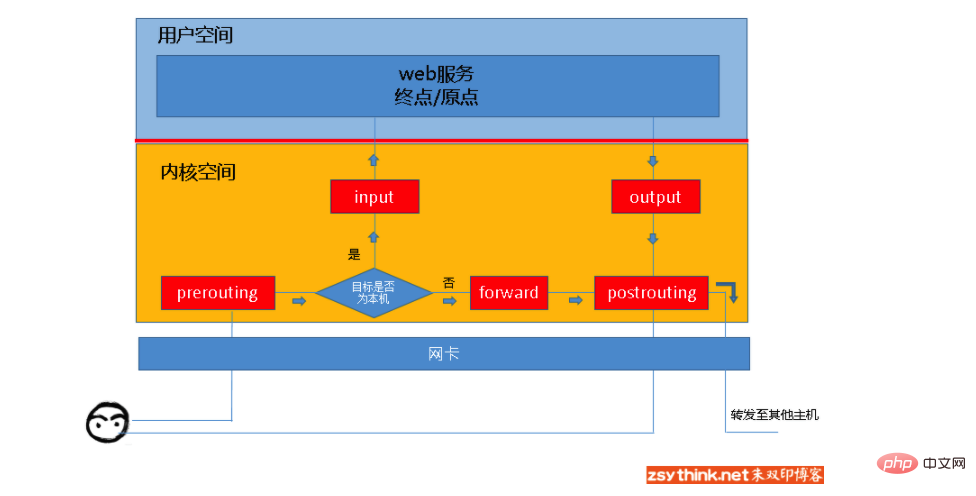
Filtertabelle: Wird zum Filtern von Datenpaketen verwendet. Spezifische Regelanforderungen bestimmen, wie ein Datenpaket verarbeitet wird. nat-Tabelle: Wird hauptsächlich zum Ändern der IP-Adresse und Portnummerninformationen von Datenpaketen verwendet. Mangle-Tabelle: Wird hauptsächlich zum Ändern des Diensttyps und Lebenszyklus von Datenpaketen, zum Festlegen von Tags für Datenpakete, zum Implementieren von Traffic Shaping, Policy Routing usw. verwendet. Rohtabelle: Wird hauptsächlich verwendet, um zu entscheiden, ob eine Statusverfolgung für Datenpakete durchgeführt werden soll.
Eingabekette: Wenn ein Paket empfangen wird, das auf die lokale Adresse zugreift, werden die Regeln in dieser Kette angewendet. Ausgabekette: Wenn die Maschine ein Paket sendet, werden die Regeln in dieser Kette angewendet. Weiterleitungskette: Beim Empfang eines Datenpakets, das an andere Adressen weitergeleitet werden muss, werden die Regeln in dieser Kette angewendet. Beachten Sie, dass Sie die Funktion ip_forward aktivieren müssen, wenn Sie die Weiterleitung implementieren müssen der Linux-Kernel. Prerouting-Kette: Die Regeln in dieser Kette werden vor dem Routing des Pakets angewendet. Postrouting-Kette: Nach dem Routing des Pakets werden die Regeln in dieser Kette angewendet.
Nachrichten an einen bestimmten Prozess weiter die lokale Maschine: PREROUTING –> Von dieser Maschine weitergeleitete Nachrichten: PREROUTING –> Eine Nachricht (normalerweise eine Antwortnachricht), die von einem Prozess auf dem lokalen Computer gesendet wird: OUTPUT –>Wir können den Prozess der Datenpakete zusammenfassen, die durch die Firewall gehen wie folgt:
-T: Tabellenname
-n: Nicht lösen IP-Adresse -v: Zeigt die Zählerinformationen, die Anzahl und Größe der Pakete an -x: Die Option gibt an, den genauen Wert des Zählers anzuzeigen --line-numbers: Die Seriennummer der Anzeigeregel (abgekürzt als --line) Außerdem sollten Sie bei der Suche nach dem öffentlichen Konto Linux auf diese Weise lernen, mit „Monkey“ im zu antworten Hintergrund und erhalte ein Überraschungsgeschenkpaket. -L:链名
#iptables -t filter -nvxL DOCKER --lineChain DOCKER (1 references)num pkts bytes target prot opt in out source destination1 5076 321478 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.2 tcp dpt:84432 37233 54082508 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.2 tcp dpt:223 1712 255195 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.3 tcp dpt:90004 0 0 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.3 tcp dpt:80005 40224 6343104 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.4 tcp dpt:34436 21034 2227009 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.5 tcp dpt:33067 58 5459 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.6 tcp dpt:808 826 70081 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.6 tcp dpt:4439 10306905 1063612492 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.9 tcp dpt:330610 159775 12297727 ACCEPT tcp -- !docker0 docker0 0.0.0.0/0 172.17.0.7 tcp dpt:11111
增加规则
命令语法:iptables -t 表名 -A 链名 匹配条件 -j 动作示例:iptables -t filter -A INPUT -s 192.168.1.146 -j DROP
命令语法:iptables -t 表名 -I 链名 匹配条件 -j 动作示例:iptables -t filter -I INPUT -s 192.168.1.146 -j ACCEPT
命令语法:iptables -t 表名 -I 链名 规则序号 匹配条件 -j 动作示例:iptables -t filter -I INPUT 5 -s 192.168.1.146 -j REJECT
删除规则
命令语法:iptables -t 表名 -D 链名 规则序号示例:iptables -t filter -D INPUT 3
命令语法:iptables -t 表名 -D 链名 匹配条件 -j 动作示例:iptables -t filter -D INPUT -s 192.168.1.146 -j DROP
命令语法:iptables -t 表名 -F 链名示例:iptables -t filter -F INPUT
修改规则
命令语法:iptables -t 表名 -R 链名 规则序号 规则原本的匹配条件 -j 动作示例:iptables -t filter -R INPUT 3 -s 192.168.1.146 -j ACCEPT
命令语法:iptables -t 表名 -P 链名 动作示例:iptables -t filter -P FORWARD ACCEPT
保存规则
方式一
service iptables save
#配置好yum源以后安装iptables-serviceyum install -y iptables-services#停止firewalldsystemctl stop firewalld#禁止firewalld自动启动systemctl disable firewalld#启动iptablessystemctl start iptables#将iptables设置为开机自动启动,以后即可通过iptables-service控制iptables服务systemctl enable iptables
方式二
iptables-save > /etc/sysconfig/iptables
加载规则
iptables-restore < /etc/sysconfig/iptables
匹配条件
#示例如下iptables -t filter -I INPUT -s 192.168.1.111,192.168.1.118 -j DROPiptables -t filter -I INPUT -s 192.168.1.0/24 -j ACCEPTiptables -t filter -I INPUT ! -s 192.168.1.0/24 -j ACCEPT
#示例如下iptables -t filter -I OUTPUT -d 192.168.1.111,192.168.1.118 -j DROPiptables -t filter -I INPUT -d 192.168.1.0/24 -j ACCEPTiptables -t filter -I INPUT ! -d 192.168.1.0/24 -j ACCEPT
#示例如下iptables -t filter -I INPUT -p tcp -s 192.168.1.146 -j ACCEPTiptables -t filter -I INPUT ! -p udp -s 192.168.1.146 -j ACCEPT
#示例如下iptables -t filter -I INPUT -p icmp -i eth4 -j DROPiptables -t filter -I INPUT -p icmp ! -i eth4 -j DROP
#示例如下iptables -t filter -I OUTPUT -p icmp -o eth4 -j DROPiptables -t filter -I OUTPUT -p icmp ! -o eth4 -j DROP
扩展匹配条件
tcp扩展模块
–sport:用于匹配 tcp 协议报文的源端口,可以使用冒号指定一个连续的端口范围。 –dport:用于匹配 tcp 协议报文的目标端口,可以使用冒号指定一个连续的端口范围。 –tcp-flags:用于匹配报文的tcp头的标志位。 –syn:用于匹配 tcp 新建连接的请求报文,相当于使用 <span style="outline: 0px;font-size: 17px;">–tcp-flags SYN,RST,ACK,FIN SYN</span>。
#示例如下iptables -t filter -I OUTPUT -d 192.168.1.146 -p tcp -m tcp --sport 22 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m tcp --dport 22:25 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m tcp --dport :22 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m tcp --dport 80: -j REJECTiptables -t filter -I OUTPUT -d 192.168.1.146 -p tcp -m tcp ! --sport 22 -j ACCEPTiptables -t filter -I INPUT -p tcp -m tcp --dport 22 --tcp-flags SYN,ACK,FIN,RST,URG,PSH SYN -j REJECTiptables -t filter -I OUTPUT -p tcp -m tcp --sport 22 --tcp-flags SYN,ACK,FIN,RST,URG,PSH SYN,ACK -j REJECTiptables -t filter -I INPUT -p tcp -m tcp --dport 22 --tcp-flags ALL SYN -j REJECTiptables -t filter -I OUTPUT -p tcp -m tcp --sport 22 --tcp-flags ALL SYN,ACK -j REJECTiptables -t filter -I INPUT -p tcp -m tcp --dport 22 --syn -j REJECT
udp 扩展模块
–sport:匹配udp报文的源地址。 –dport:匹配udp报文的目标地址。
#示例iptables -t filter -I INPUT -p udp -m udp --dport 137 -j ACCEPTiptables -t filter -I INPUT -p udp -m udp --dport 137:157 -j ACCEPT
icmp 扩展模块
–icmp-type:匹配icmp报文的具体类型。
#示例iptables -t filter -I INPUT -p icmp -m icmp --icmp-type 8/0 -j REJECTiptables -t filter -I INPUT -p icmp --icmp-type 8 -j REJECTiptables -t filter -I OUTPUT -p icmp -m icmp --icmp-type 0/0 -j REJECTiptables -t filter -I OUTPUT -p icmp --icmp-type 0 -j REJECTiptables -t filter -I INPUT -p icmp --icmp-type "echo-request" -j REJECT
multiport 扩展模块
-p tcp -m multiport –sports 用于匹配报文的源端口,可以指定离散的多个端口号,端口之间用”逗号”隔开。 -p udp -m multiport –dports 用于匹配报文的目标端口,可以指定离散的多个端口号,端口之间用”逗号”隔开。
#示例如下iptables -t filter -I OUTPUT -d 192.168.1.146 -p udp -m multiport --sports 137,138 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport --dports 22,80 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport ! --dports 22,80 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport --dports 80:88 -j REJECTiptables -t filter -I INPUT -s 192.168.1.146 -p tcp -m multiport --dports 22,80:88 -j REJECT
iprange 模块
–src-range:指定连续的源地址范围。 –dst-range:指定连续的目标地址范围。
#示例iptables -t filter -I INPUT -m iprange --src-range 192.168.1.127-192.168.1.146 -j DROPiptables -t filter -I OUTPUT -m iprange --dst-range 192.168.1.127-192.168.1.146 -j DROPiptables -t filter -I INPUT -m iprange ! --src-range 192.168.1.127-192.168.1.146 -j DROP
牛逼啊!接私活必备的 N 个开源项目!赶快收藏
string 模块
–algo:指定对应的匹配算法,可用算法为bm、kmp,此选项为必需选项。 –string:指定需要匹配的字符串
#示例 iptables -t filter -I INPUT -m string --algo bm --string "OOXX" -j REJECT
time 模块
–timestart:用于指定时间范围的开始时间,不可取反。 –timestop:用于指定时间范围的结束时间,不可取反。 –weekdays:用于指定”星期几”,可取反。 –monthdays:用于指定”几号”,可取反。 –datestart:用于指定日期范围的开始日期,不可取反。 –datestop:用于指定日期范围的结束时间,不可取反。
#示例 iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop 19:00:00 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 443 -m time --timestart 09:00:00 --timestop 19:00:00 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 6,7 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --monthdays 22,23 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time ! --monthdays 22,23 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop 18:00:00 --weekdays 6,7 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 5 --monthdays 22,23,24,25,26,27,28 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --datestart 2017-12-24 --datestop 2017-12-27 -j REJECT
connlimit 模块
–connlimit-above:单独使用此选项时,表示限制每个IP的链接数量。 –connlimit-mask:此选项不能单独使用,在使用–connlimit-above选项时,配合此选项,则可以针对”某类IP段内的一定数量的IP”进行连接数量的限制,如果不明白可以参考上文的详细解释。
#示例 iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 2 -j REJECT iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 20 --connlimit-mask 24 -j REJECT iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 10 --connlimit-mask 27 -j REJECT
limit 模块
–limit-burst:类比”令牌桶”算法,此选项用于指定令牌桶中令牌的最大数量。 –limit:类比”令牌桶”算法,此选项用于指定令牌桶中生成新令牌的频率,可用时间单位有second、minute 、hour、day。
#示例,注意,如下两条规则需配合使用 #令牌桶中最多能存放3个令牌,每分钟生成10个令牌(即6秒钟生成一个令牌)。 iptables -t filter -I INPUT -p icmp -m limit --limit-burst 3 --limit 10/minute -j ACCEPT #默认将icmp包丢弃 iptables -t filter -A INPUT -p icmp -j REJECT
state 扩展模块
NEU: Das erste Paket in der Verbindung, der Zustand ist NEU, wir Es versteht sich, dass der Status des ersten Pakets der neuen Verbindung NEU ist. ESTABLISHED: Wir können den Status des Pakets nach dem NEUEN Statuspaket als ESTABLISHED verstehen, was darauf hinweist, dass die Verbindung hergestellt wurde. RELATED wird wörtlich als Beziehung übersetzt, ist aber dennoch nicht leicht zu verstehen. Im FTP-Dienst erstellt der FTP-Server beispielsweise zwei Prozesse, einen Befehlsprozess und einen Datenprozess. Der Befehlsprozess ist für die Befehlsübertragung zwischen dem Server und dem Client verantwortlich (wir können diesen Übertragungsprozess als eine sogenannte „Verbindung“ im Status verstehen, die vorübergehend als „Befehlsverbindung“ bezeichnet wird). Der Datenprozess ist für die Datenübertragung zwischen dem Server und dem Client verantwortlich (wir nennen diesen Prozess vorübergehend „Datenverbindung“). Die zu übertragenden spezifischen Daten werden jedoch durch den Befehl gesteuert. Daher sind die Nachrichten in der „Datenverbindung“ mit der „Befehlsverbindung“ „bezogen“. Dann können sich die Pakete in der „Datenverbindung“ im RELATED-Zustand befinden, da diese Pakete mit den Paketen in der „Befehlsverbindung“ in Beziehung stehen. (Hinweis: Wenn Sie eine Verbindungsverfolgung für FTP durchführen möchten, müssen Sie das entsprechende Kernelmodul nf_conntrack_ftp separat laden. Wenn Sie es automatisch laden möchten, können Sie die Datei /etc/sysconfig/iptables-config konfigurieren) -
UNGÜLTIG: Wenn es für ein Paket keine Möglichkeit gibt, es zu identifizieren, oder das Paket keinen Status hat, dann ist der Status dieses Pakets UNGÜLTIG. Wir können die Pakete mit dem Status UNGÜLTIG blockieren. UNTRACKED: Wenn der Status des Pakets „Untracked“ lautet, bedeutet dies, dass das Paket nicht verfolgt wurde. Wenn der Status des Pakets „Untracked“ lautet, bedeutet dies normalerweise, dass die entsprechende Verbindung nicht gefunden werden kann.
iptables -t filter -I INPUT -m state --state ESTABLISHED -j ACCEPT
mangle 表
TOS:用来设置或改变数据包的服务类型域。这常用来设置网络上的数据包如何被路由等策略。注意这个操作并不完善,有时得不所愿。它在Internet 上还不能使用,而且很多路由器不会注意到这个域值。换句话说,不要设置发往 Internet 的包,除非你打算依靠 TOS 来路由,比如用 iproute2。 TTL:用来改变数据包的生存时间域,我们可以让所有数据包只有一个特殊的 TTL。它的存在有 一个很好的理由,那就是我们可以欺骗一些ISP。为什么要欺骗他们呢?因为他们不愿意让我们共享一个连接。那些 ISP 会查找一台单独的计算机是否使用不同的 TTL,并且以此作为判断连接是否被共享的标志。 MARK 用来给包设置特殊的标记。iproute 2能识别这些标记,并根据不同的标记(或没有标记) 决定不同的路由。用这些标记我们可以做带宽限制和基于请求的分类。
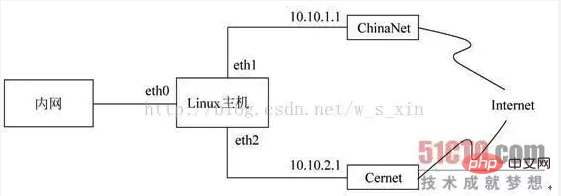
iptables -t mangle -A PREROUTING -i eth0 -p tcp --dport 80 -j MARK --set-mark 1; iptables -t mangle -A PREROUTING -i eth0 -p udp --dprot 53 -j MARK --set-mark 2;
ip rule add from all fwmark 1 table 10 ip rule add from all fwmark 2 table 20
ip route add default via 10.10.1.1 dev eth1 table 10 ip route add default via 10.10.2.1 dev eth2 table 20
Benutzerdefinierte Kette
创建自定义链
#在filter表中创建IN_WEB自定义链 iptables -t filter -N IN_WEB
引用自定义链
#在INPUT链中引用刚才创建的自定义链 iptables -t filter -I INPUT -p tcp --dport 80 -j IN_WEB
重命名自定义链
#将IN_WEB自定义链重命名为WEB iptables -E IN_WEB WEB
删除自定义链
1、自定义链没有被引用。 2、自定义链中没有任何规则。
#第一步:清除自定义链中的规则 iptables -t filter -F WEB #第二步:删除自定义链 iptables -t filter -X WEB
LOG 动作
kern.warning /var/log/iptables.log
service rsyslog restart
–log-level 选项可以指定记录日志的日志级别,可用级别有 emerg,alert,crit,error,warning,notice,info,debug。 –log-prefix 选项可以给记录到的相关信息添加”标签”之类的信息,以便区分各种记录到的报文信息,方便在分析时进行过滤。–log-prefix 对应的值不能超过 29 个字符。
iptables -I INPUT -p tcp --dport 22 -m state --state NEW -j LOG --log-prefix "want-in-from-port-22"

参考链接
https://www.zsythink.net/archives/category/%e8%bf%90%e7%bb%b4%e7%9b%b8%e5%85%b3 /iptables/ https://my.oschina.net/mojiewhy/blog/3039897 https://www.frozentux.net/iptables-tutorial/cn/iptables-tutorial- cn-1.1.19.html#MARKTARGET https://mp.weixin.qq.com/s/NOxY4ZC7Cay4LCWlMkVx8A
Das obige ist der detaillierte Inhalt vonIch weiß nicht, wie man die Linux-Firewall-Software IPtables verwendet! Was für ein Betriebs- und Wartungstyp sind Sie?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
Wie setze ich nach dem Neustart des Systems automatisch Berechtigungen von Unixsocket fest?
Mar 31, 2025 pm 11:54 PM
So setzen Sie die Berechtigungen von Unixsocket automatisch nach dem Neustart des Systems. Jedes Mal, wenn das System neu startet, müssen wir den folgenden Befehl ausführen, um die Berechtigungen von Unixsocket: sudo ...
 Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Warum tritt bei der Installation einer Erweiterung mit PECL in einer Docker -Umgebung ein Fehler auf? Wie löst ich es?
Apr 01, 2025 pm 03:06 PM
Ursachen und Lösungen für Fehler Bei der Verwendung von PECL zur Installation von Erweiterungen in der Docker -Umgebung, wenn die Docker -Umgebung verwendet wird, begegnen wir häufig auf einige Kopfschmerzen ...
 Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Viele Website -Entwickler stehen vor dem Problem der Integration von Node.js oder Python Services unter der Lampenarchitektur: Die vorhandene Lampe (Linux Apache MySQL PHP) Architekturwebsite benötigt ...
 Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Wie löste ich Berechtigungsprobleme bei der Verwendung von Python -Verssionsbefehl im Linux Terminal?
Apr 02, 2025 am 06:36 AM
Verwenden Sie Python im Linux -Terminal ...
 Was sollte ich tun, wenn Beyond Compare bei der Synchronisierung von Windows- und Linux -Dateien nicht die Sensibilität des Falls nicht in die Fall ist?
Apr 01, 2025 am 08:06 AM
Was sollte ich tun, wenn Beyond Compare bei der Synchronisierung von Windows- und Linux -Dateien nicht die Sensibilität des Falls nicht in die Fall ist?
Apr 01, 2025 am 08:06 AM
Das Problem des Vergleichs und Synchronisierens von Dateien überkompeten: Fallempfindlichkeitsfehler bei der Verwendung von Beyond ...
 Wie konfigurieren Sie die Timing -Timing -Aufgabe von ApScheduler als Dienst auf macOS?
Apr 01, 2025 pm 06:09 PM
Wie konfigurieren Sie die Timing -Timing -Aufgabe von ApScheduler als Dienst auf macOS?
Apr 01, 2025 pm 06:09 PM
Konfigurieren Sie die Timing -Timing -Timing -Timing -Timing auf der MacOS -Plattform, wenn Sie die Timing -Timing -Timing -Timing von APScheduler als Service konfigurieren möchten, ähnlich wie bei NGIN ...
 Kann der Python -Dolmetscher im Linux -System gelöscht werden?
Apr 02, 2025 am 07:00 AM
Kann der Python -Dolmetscher im Linux -System gelöscht werden?
Apr 02, 2025 am 07:00 AM
In Bezug auf das Problem der Entfernung des Python -Dolmetschers, das mit Linux -Systemen ausgestattet ist, werden viele Linux -Verteilungen den Python -Dolmetscher bei der Installation vorinstallieren, und verwendet den Paketmanager nicht ...
