
 Betrieb und Instandhaltung
Betrieb und Wartung von Linux
Ultra-umfassende Sammlung – Zusammenfassende Sammlung von Linux-Leistungsanalysetools
Betrieb und Instandhaltung
Betrieb und Wartung von Linux
Ultra-umfassende Sammlung – Zusammenfassende Sammlung von Linux-Leistungsanalysetools
Ultra-umfassende Sammlung – Zusammenfassende Sammlung von Linux-Leistungsanalysetools
Aus Interesse am Linux-Betriebssystem und einem starken Wunsch nach grundlegendem Wissen habe ich diesen Artikel zusammengestellt. Dieser Artikel kann auch als Indikator zum Testen von Grundkenntnissen verwendet werden. Darüber hinaus deckt der Artikel alle Aspekte eines Systems ab. Ohne umfassende Computersystemkenntnisse, Netzwerkkenntnisse und Betriebssystemkenntnisse ist es unmöglich, die im Dokument enthaltenen Tools vollständig zu beherrschen. Darüber hinaus ist die Analyse und Optimierung der Systemleistung eine langfristige Serie.
Dieses Dokument ist hauptsächlich ein umfassender Artikel, der auf dem Blogbeitrag von Netflix Senior Performance Architect Brendan Gregg basiert, der die Linux-Leistungsoptimierungstools aktualisiert und Artikel zur Optimierung der Linux-Systemleistung sammelt Die beteiligten Leistungstest-Tools werden erläutert.
Hintergrundwissen: Hintergrundwissen ist das, was Sie bei der Analyse von Leistungsproblemen wissen müssen. Zum Beispiel Hardware-Cache; ein weiteres Beispiel ist der Betriebssystemkernel. Die Verhaltensdetails der Anwendung hängen oft mit diesen Dingen zusammen. Diese Dinge auf niedriger Ebene können sich auf unerwartete Weise auf die Leistung der Anwendung auswirken. Beispielsweise können einige Programme den Cache nicht vollständig nutzen, was zu Leistungseinbußen führt. Beispielsweise werden unnötig viele Systemaufrufe aufgerufen, was zu häufigen Kernel-/Benutzerwechseln usw. führt. Dies dient nur dazu, den Weg für den weiteren Inhalt dieses Artikels zu ebnen. Ich weiß noch nicht viel mehr, als ich weiß, und hoffe, dass alle gemeinsam lernen und Fortschritte machen können.
【Leistungsanalyse-Tool】
Schauen wir uns zunächst ein Bild an:
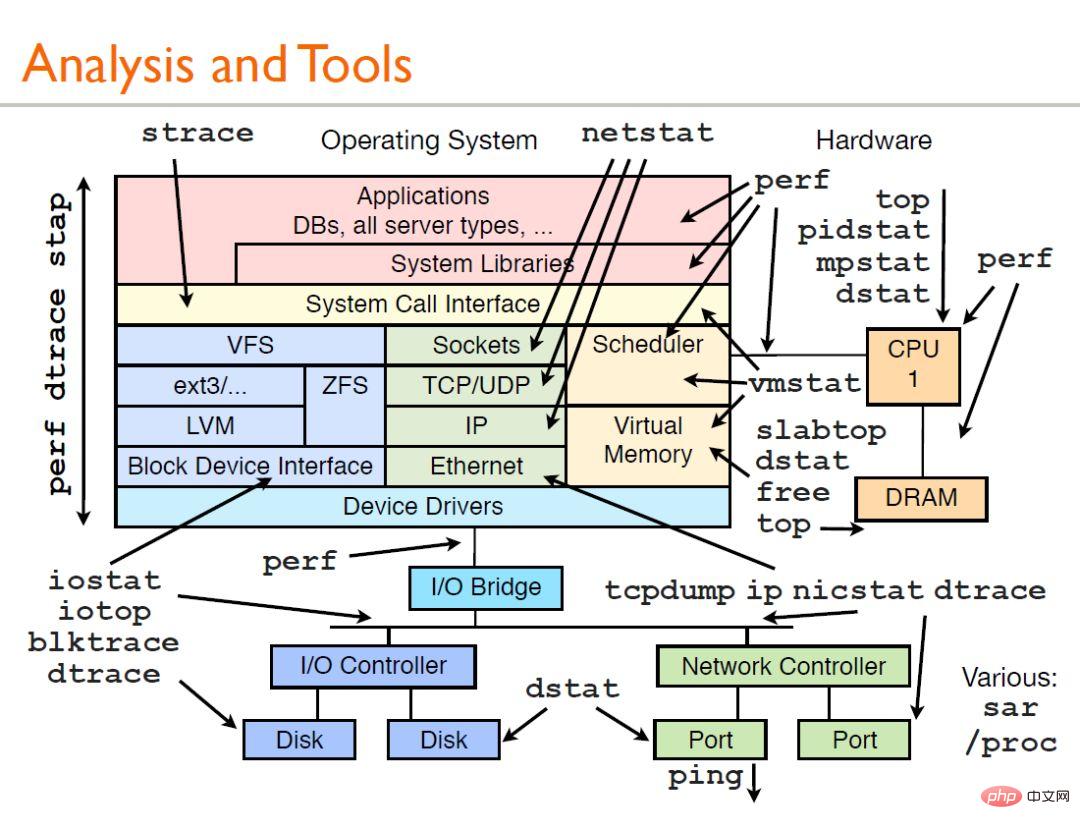
Das Bild oben ist eine von Brendan Gregg geteilte Leistungsanalyse. Hier können wir eine kurze Einführung in die herkömmliche Verwendung geben:
▲ vmstat – Statistiken zum virtuellen Speicher
vmstat (VirtualMeomoryStatistics, Statistiken zum virtuellen Speicher) ist ein gängiges Tool zur Speicherüberwachung unter Linux. Es kann den virtuellen Speicher, den Prozess und die CPU des Betriebssystems überwachen. Beobachten Sie die Gesamtsituation.
Allgemeine Verwendung von vmstat: vmstat-Intervallzeiten bedeuten eine Abtastung einmal pro Intervall in Sekunden, die Gesamtabtastzeit mal. Wenn die Zeitspanne weggelassen wird, werden Daten erfasst, bis der Benutzer sie manuell stoppt.
Ein einfaches Beispiel:

Sie können Strg+C verwenden, um die Datenerfassung durch vmstat zu stoppen.
Die erste Zeile zeigt den Durchschnitt seit dem Systemstart, die zweite Zeile zeigt an, was jetzt passiert, die folgenden Zeilen zeigen, was in jedem 5-Sekunden-Intervall passiert, die Bedeutung jeder Spalte steht in der Kopfzeile wie folgt Anzeige:
▪ Die procs:-Spalte r zeigt an, wie viele Prozesse auf die CPU warten, und die b-Spalte zeigt, wie viele Prozesse ununterbrochen schlafen (auf IO warten).
▪ Speicher: Die swapd-Spalte zeigt, wie viele Blöcke von der Festplatte ausgelagert wurden (Seitenaustausch), die restlichen Spalten zeigen, wie viele Blöcke frei (nicht verwendet) sind und wie viele Blöcke als Puffer verwendet werden und wie viel davon als Cache des Betriebssystems verwendet wird.
▪ Swap: Zeigt die Swap-Aktivität an: wie viele Blöcke pro Sekunde ein- (von der Festplatte) und ausgelagert (auf die Festplatte) werden.
▪ io: Zeigt an, wie viele Blöcke vom Blockgerät gelesen (bi) und geschrieben (bo) wurden, was normalerweise auf Festplatten-E/A zurückzuführen ist.
▪ System: Zeigt die Anzahl der Interrupts (in) und Kontextwechsel (cs) pro Sekunde an.
▪ CPU: Zeigt den Prozentsatz der gesamten CPU-Zeit an, die für verschiedene Vorgänge aufgewendet wird, einschließlich der Ausführung von Benutzercode (Nicht-Kernel), der Ausführung von Systemcode (Kernel), im Leerlauf und beim Warten auf E/A.
Symptome von unzureichendem Speicher: Der freie Speicher nimmt stark ab, das Recycling von Puffern und Caches hilft nicht, umfangreiche Nutzung von Swap-Partitionen (swpd), häufiger Seitenaustausch (swap), Erhöhung der Anzahl der Lese- und Schreibplatten (io) , und Seitenfehler (in ) nehmen zu, die Anzahl der Kontextwechsel (cs) nimmt zu, die Anzahl der Prozesse, die auf IO (b) warten, nimmt zu und es wird viel CPU-Zeit damit verbracht, auf IO (wa) zu warten
▲iostat – für die Meldung von Statistiken der Zentraleinheit (CPU)
iostat für die Meldung von Statistiken der Zentraleinheit (CPU) und Ein-/Ausgabestatistiken für das gesamte System, Adapter, TTY-Geräte, Festplatten und CD-ROMs, die dasselbe anzeigen CPU-Nutzungsinformationen standardmäßig als vmstat verwenden. Verwenden Sie den folgenden Befehl, um erweiterte Gerätestatistiken anzuzeigen:

Die erste Zeile zeigt den Durchschnitt seit dem Systemstart, dann den inkrementellen Durchschnitt, eine Zeile pro Gerät.
Übliche Abkürzungsgewohnheiten für Linux-Festplatten-IO-Indikatoren: rq ist eine Anforderung, r ist ein Lesevorgang, w ist ein Schreibvorgang, qu ist eine Warteschlange, sz ist eine Größe, a ist ein Durchschnitt, tm ist eine Zeit und svc ist ein Dienst.
▪rrqm/s und wrqm/s: Kombinierte Lese- und Schreibanforderungen pro Sekunde. „Zusammengeführt“ bedeutet, dass das Betriebssystem mehrere logische Anforderungen aus der Warteschlange entnimmt und sie zu einer Anforderung an die eigentliche Festplatte zusammenführt.
▪r/s und w/s: Anzahl der Lese- und Schreibanfragen, die pro Sekunde an das Gerät gesendet werden.
▪rsec/s und wsec/s: Anzahl der pro Sekunde gelesenen und geschriebenen Sektoren.
▪avgrq –sz: Angeforderte Anzahl von Sektoren.
▪avgqu –sz: Anzahl der Anfragen, die in der Gerätewarteschlange warten.
▪await:每个IO请求花费的时间。
▪svctm:实际请求(服务)时间。
▪%util:至少有一个活跃请求所占时间的百分比。
▲dstat--系统监控工具
dstat显示了cpu使用情况,磁盘io情况,网络发包情况和换页情况,输出是彩色的,可读性较强,相对于vmstat和iostat的输入更加详细且较为直观。在使用时,直接输入命令即可,当然也可以使用特定参数。
如下:dstat –cdlmnpsy
▲iotop--LINUX进程实时监控工具
iotop命令是专门显示硬盘IO的命令,界面风格类似top命令,可以显示IO负载具体是由哪个进程产生的。是一个用来监视磁盘I/O使用状况的top类工具,具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。
可以以非交互的方式使用:iotop –bod interval,查看每个进程的I/O,可以使用pidstat,pidstat –d instat。
搜索公众号Linux中文社区后台回复“私房菜”,获取一份惊喜礼包。
▲pidstat--监控系统资源情况
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
使用方法:pidstat –d interval;pidstat还可以用以统计CPU使用信息:pidstat –u interval;统计内存信息:Pidstat –r interval。
▲top
top命令的汇总区域显示了五个方面的系统性能信息:
1.负载:时间,登陆用户数,系统平均负载;
2.进程:运行,睡眠,停止,僵尸;
3.cpu:用户态,核心态,NICE,空闲,等待IO,中断等;
4.内存:总量,已用,空闲(系统角度),缓冲,缓存;
5.交换分区:总量,已用,空闲
任务区域默认显示:进程ID,有效用户,进程优先级,NICE值,进程使用的虚拟内存,物理内存和共享内存,进程状态,CPU占用率,内存占用率,累计CPU时间,进程命令行信息。
▲htop
htop 是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要ncurses。
Htop可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
与top相比,htop有以下优点:
▪ 可以横向或者纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
▪ 在启动上,比top更快。
▪ 杀进程时不需要输入进程号。
▪ htop支持鼠标操作。
▲mpstat
mpstat 是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。常见用法:mpstat –P ALL interval times。
▲netstat
Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
▲常见用法:
netstat –npl 可以查看你要打开的端口是否已经打开。
netstat –rn 打印路由表信息。
netstat –in 提供系统上的接口信息,打印每个接口的MTU,输入分组数,输入错误,输出分组数,输出错误,冲突以及当前的输出队列的长度。
▲ps--显示当前进程的状态
ps参数太多,具体使用方法可以参考man ps,常用的方法:ps aux #hsserver;ps –ef |grep #hundsun
▪ 杀掉某一程序的方法:ps aux | grep mysqld | grep –v grep | awk ‘{print $2 }’ xargs kill -9
▪ 杀掉僵尸进程:ps –eal | awk ‘{if ($2 == “Z”){print $4}}’ | xargs kill -9
▲strace
跟踪程序执行过程中产生的系统调用及接收到的信号,帮助分析程序或命令执行中遇到的异常情况。
举例:查看mysqld在linux上加载哪种配置文件,可以通过运行下面的命令:strace –e stat64 mysqld –print –defaults > /dev/null
▲uptime
能够打印系统总共运行了多长时间和系统的平均负载,uptime命令最后输出的三个数字的含义分别是1分钟,5分钟,15分钟内系统的平均负荷。
▲lsof
lsof(list open files)是一个列出当前系统打开文件的工具。通过lsof工具能够查看这个列表对系统检测及排错,常见的用法:
查看文件系统阻塞 lsof /boot
查看端口号被哪个进程占用 lsof -i : 3306
查看用户打开哪些文件 lsof –u username
查看进程打开哪些文件 lsof –p 4838
查看远程已打开的网络链接 lsof –i @192.168.34.128
▲perf
perf是Linux kernel自带的系统性能优化工具。优势在于与Linux Kernel的紧密结合,它可以最先应用到加入Kernel的new feature,用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能。
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
想要更深的了解本工具可以参考:
http://blog.csdn.net/trochiluses/article/details/10261339
汇总:结合以上常用的性能测试命令并联系文初的性能分析工具的图,就可以初步了解到性能分析过程中哪个方面的性能使用哪方面的工具(命令)。
【常用的性能测试工具】
熟练并精通了第二部分的性能分析命令工具,引入几个性能测试的工具,介绍之前先简单了解几个性能测试工具:
▪ perf_events: 一款随 Linux 内核代码一同发布和维护的性能诊断工具,由内核社区维护和发展。Perf 不仅可以用于应用程序的性能统计分析,也可以应用于内核代码的性能统计和分析。
更多参考:http://blog.sina.com.cn/s/blog_98822316010122ex.html。
▪ eBPF tools: 一款使用bcc进行的性能追踪的工具,eBPF map可以使用定制的eBPF程序被广泛应用于内核调优方面,也可以读取用户级的异步代码。重要的是这个外部的数据可以在用户空间管理。这个k-v格式的map数据体是通过在用户空间调用bpf系统调用创建、添加、删除等操作管理的。more: http://blog.csdn.net/ljy1988123/article/details/50444693。
▪ perf-tools: 一款基于 perf_events (perf) 和 ftrace 的Linux性能分析调优工具集。Perf-Tools 依赖库少,使用简单。支持Linux 3.2 及以上内核版本。more: https://github.com/brendangregg/perf-tools。
▪ bcc(BPF Compiler Collection): 一款使用eBPF的perf性能分析工具。一个用于创建高效的内核跟踪和操作程序的工具包,包括几个有用的工具和示例。利用扩展的BPF(伯克利数据包过滤器),正式称为eBPF,一个新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
更多参考:https://github.com/iovisor/bcc#tools。
▪ ktap: 一种新型的linux脚本动态性能跟踪工具。允许用户跟踪Linux内核动态。ktap是设计给具有互操作性,允许用户调整操作的见解,排除故障和延长内核和应用程序。它类似于Linux和Solaris DTrace SystemTap。更多参考:https://github.com/ktap/ktap。
▪ Flame Graphs:是一款使用perf,system tap,ktap可视化的图形软件,允许最频繁的代码路径快速准确地识别,可以是使用github.com/brendangregg/flamegraph中的开发源代码的程序生成。
更多参考:http://www.brendangregg.com/flamegraphs.html。
一、 Linux observability tools | Linux 性能观测工具
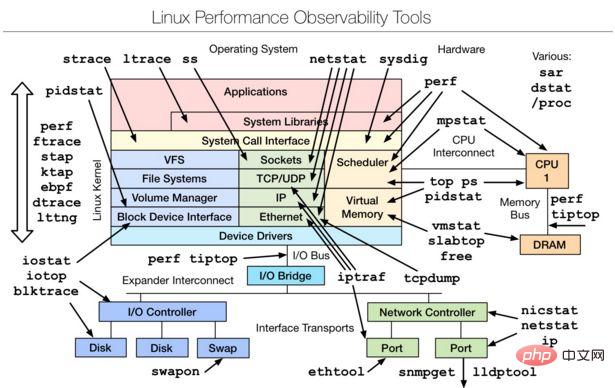
▪ 首先学习的Basic Tool有如下:
uptime、top(htop)、mpstat、isstat、vmstat、free、ping、nicstat、dstat。
▪ 高级的命令如下:
sar、netstat、pidstat、strace、tcpdump、blktrace、iotop、slabtop、sysctl、/proc。
更多参考:http://www.open-open.com/lib/view/open1434589043973.html,详细的命令使用方法可以参考man
二、Linux benchmarking tools | Linux 性能测评工具
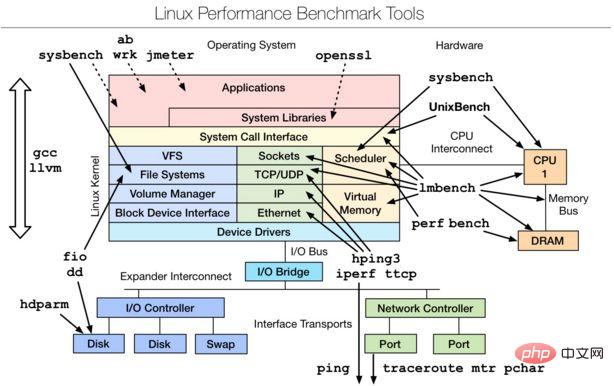
是一款性能测评工具,对于不同模块的性能测试可以使用相应的工具,想要深入了解,可以参考最下文的附件文档。
三、Linux tuning tools | Linux 性能调优工具
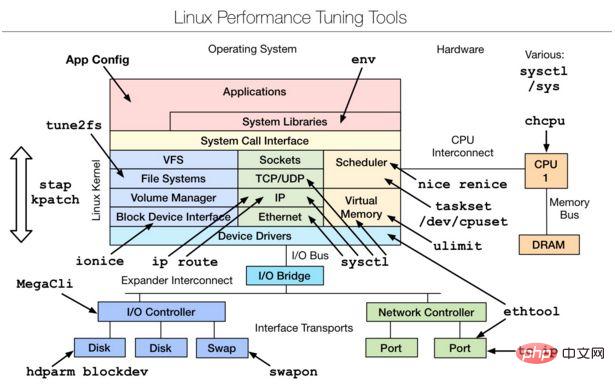
是一款性能调优工具,主要是从linux内核源码层进行的调优,想要深入了解,可以参考下文附件文档。
四、Linux observability sar | linux性能观测工具
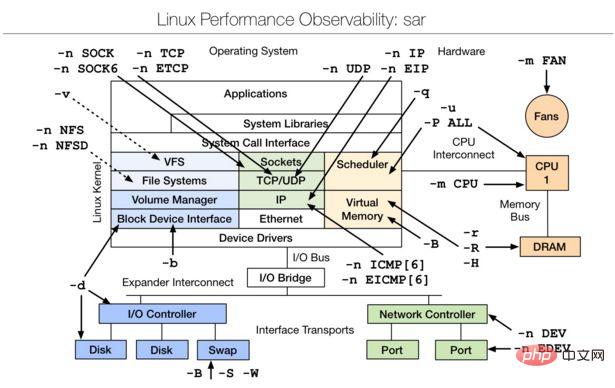
sar(System Activity Reporter系统活动情况报告)是目前LINUX上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等方面。
sar的常归使用方式:sar [options] [-A] [-o file] t [n]
其中:
t为采样间隔,n为采样次数,默认值是1;
-o file表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项
Das obige ist der detaillierte Inhalt vonUltra-umfassende Sammlung – Zusammenfassende Sammlung von Linux-Leistungsanalysetools. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
So starten Sie den Apache -Server neu
Apr 13, 2025 pm 01:12 PM
Befolgen Sie die folgenden Schritte, um den Apache -Server neu zu starten: Linux/MacOS: Führen Sie sudo systemCTL RESTART APache2 aus. Windows: Net Stop Apache2.4 und dann Net Start Apache2.4 ausführen. Führen Sie Netstat -a | Findstr 80, um den Serverstatus zu überprüfen.
 So lösen Sie das Problem, dass Apache nicht gestartet werden kann
Apr 13, 2025 pm 01:21 PM
So lösen Sie das Problem, dass Apache nicht gestartet werden kann
Apr 13, 2025 pm 01:21 PM
Apache kann aus den folgenden Gründen nicht beginnen: Konfigurationsdatei -Syntaxfehler. Konflikt mit anderen Anwendungsports. Berechtigungen Ausgabe. Aus dem Gedächtnis. Prozess -Deadlock. Dämonversagen. Selinux -Berechtigungen Probleme. Firewall -Problem. Software -Konflikt.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 Läuft das Internet unter Linux?
Apr 14, 2025 am 12:03 AM
Läuft das Internet unter Linux?
Apr 14, 2025 am 12:03 AM
Das Internet stützt sich nicht auf ein einzelnes Betriebssystem, aber Linux spielt eine wichtige Rolle dabei. Linux wird häufig auf Servern und Netzwerkgeräten verwendet und ist für seine Stabilität, Sicherheit und Skalierbarkeit beliebt.
 So beheben Sie Apache Schwachstellen
Apr 13, 2025 pm 12:54 PM
So beheben Sie Apache Schwachstellen
Apr 13, 2025 pm 12:54 PM
Schritte zur Behebung der Apache -Sicherheitsanfälligkeit umfassen: 1. Bestimmen Sie die betroffene Version; 2. Anwenden von Sicherheitsaktualisierungen; 3. Starten Sie Apache neu; 4. Überprüfen Sie die Fix; 5. Sicherheitsfunktionen aktivieren.
