

Redis-Studiennotizen-Listen-Prinzip
Grundlegende Funktionen
| Befehl | Beschreibung | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B LPOP-Taste 1, Taste 2,... Timeout | Entfernen und Holen Sie sich das erste Element der Liste. Wenn kein Element in der Liste vorhanden ist, wird die Liste blockiert, bis die Wartezeit abgelaufen ist oder das Element gelöscht wird. | |||||||||||||||||||
| BRPOP key1 [key2 ] timeout | Bewegen Sie sich und holen Sie sich das letzte Element der Liste. Wenn kein Element in der Liste vorhanden ist, wird das blockiert list, bis die Wartezeit abgelaufen ist oder ein Popable-Element gefunden wird. | |||||||||||||||||||
| BRPOPLPUSH Quell-Ziel-Timeout | Wählen Sie einen Wert aus der Liste, fügen Sie das entnommene Element in eine andere Liste ein und geben Sie es zurück Wartezeitüberschreitung oder Bis Popup-Elemente gefunden werden. | |||||||||||||||||||
| LIndex key index | 通过索引获取列表中的元素 | |||||||||||||||||||
| Linsert key before/after pivot value | 在列表的元素前或者后插入元素 | |||||||||||||||||||
| LLEN key | 获取列表长度 | |||||||||||||||||||
| LPOP key | 移出并获取列表的第一个元素 | |||||||||||||||||||
| LPUSH-Schlüsselwert1,Wert2,… | Fügen Sie einen oder mehrere Werte in den Kopf der Liste ein | |||||||||||||||||||
| LPUSHX-Schlüsselwert | fügt einen Wert in den Kopf einer vorhandenen Liste ein | |||||||||||||||||||
| LRANGE-Taste Srart Stop | Ruft die Elemente im angegebenen Bereich der Liste ab | |||||||||||||||||||
| LREM-Taste Zählwert | Listenelement entfernen | |||||||||||||||||||
| LSET-Schlüsselindexwert | Legen Sie den Wert des Listenelements fest durch. index | |||||||||||||||||||
| LTRIM-Taste Start Stop | Das Bereinigen einer Liste bedeutet, dass die Liste nur Elemente innerhalb des angegebenen Bereichs behält und alle Elemente, die nicht innerhalb des angegebenen Bereichs liegen, gelöscht werden. Der Index beginnt bei 0 und der Bereich ist inklusive. | |||||||||||||||||||
| RPOP-Taste | entfernt das letzte Element aus der Liste, und der Rückgabewert ist das entfernte Element | |||||||||||||||||||
| RPOPPUSH Quellziel | Entfernen Sie das letzte Element der Liste, fügen Sie dieses Element einer anderen Liste hinzu und geben Sie | |||||||||||||||||||
| RPUSH-Schlüsselwert1 Wert2 …… | zurück Eins hinzufügen oder Weitere Werte bis zum Ende der Liste
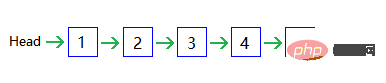
Einfach verknüpfte ListeBevor wir die Listenimplementierung von Redis lernen, werfen wir einen Blick darauf Zunächst einmal So implementieren Sie eine einfach verknüpfte Liste: Jeder Knoten hat einen Rückwärtszeiger (Referenz), der auf den nächsten Knoten zeigt, der letzte Knoten zeigt auf NULL, um das Ende anzuzeigen, und es gibt einen Kopfzeiger, der auf den zeigt erster Knoten, der den Start anzeigt.
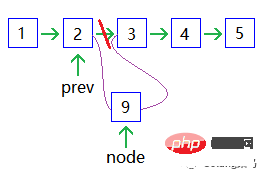
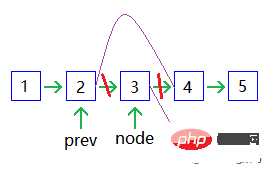
Ähnlich wie hier, aber neu und gelöscht benötigen nur Zeit; Rückwärtssuche ist nicht möglich und Sie müssen beginnen von Anfang an, falls Sie es verpassen. 🎜Knoten hinzufügen: 🎜🎜
Einen Knoten löschen:
Eine doppelt verknüpfte Liste wird auch als doppelt verknüpfte Liste bezeichnet. Es handelt sich um eine Art verknüpfte Liste hat zwei Zeiger, die auf den unmittelbaren Nachfolger bzw. den unmittelbaren Vorgänger zeigen. Daher können Sie ausgehend von jedem Knoten in der doppelt verknüpften Liste problemlos auf dessen Vorgänger- und Nachfolgerknoten zugreifen.
|


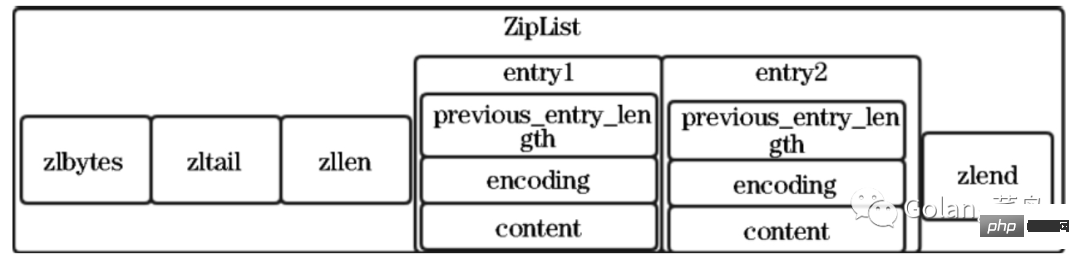
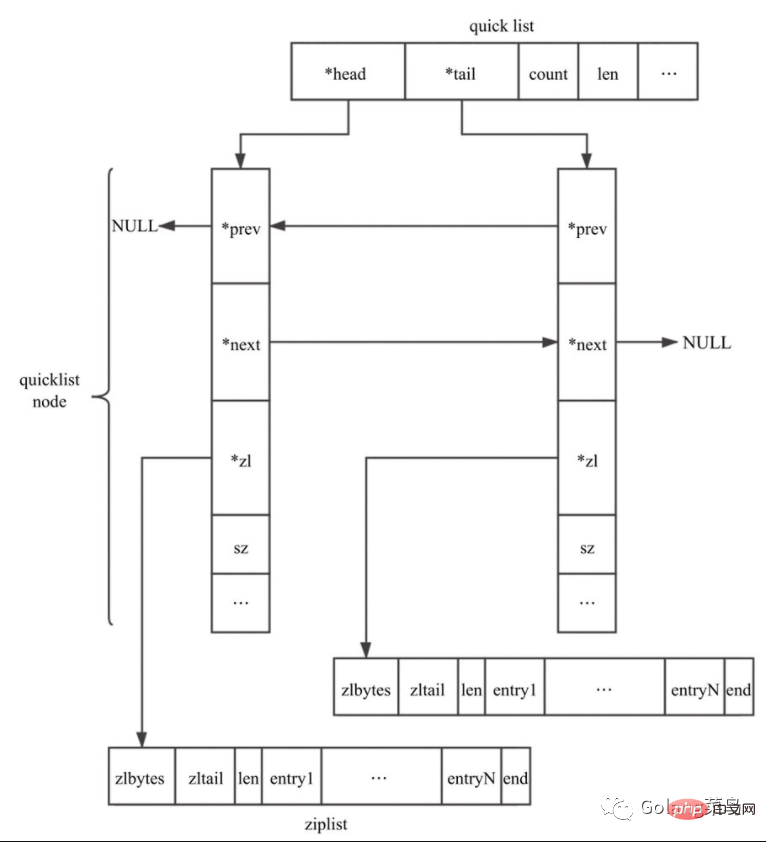
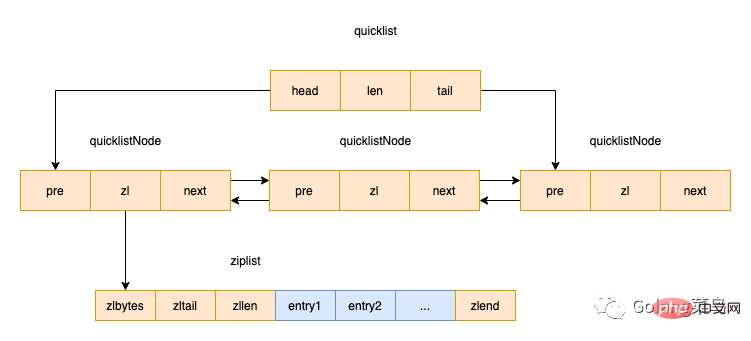
| Wert | Bedeutung |
|---|---|
| 0 | Besonderer Wert bedeutet keine Komprimierung |
| 1 | An jedem Ende der Quicklist befindet sich 1 Knoten, der nicht komprimiert ist, und der mittlere Knoten ist komprimiert sind nicht komprimiert und der mittlere Knoten ist komprimiert |
| n | An beiden Enden der Quicklist gibt es n Knoten, die nicht komprimiert sind, und die Knoten in der Mitte sind komprimiert |
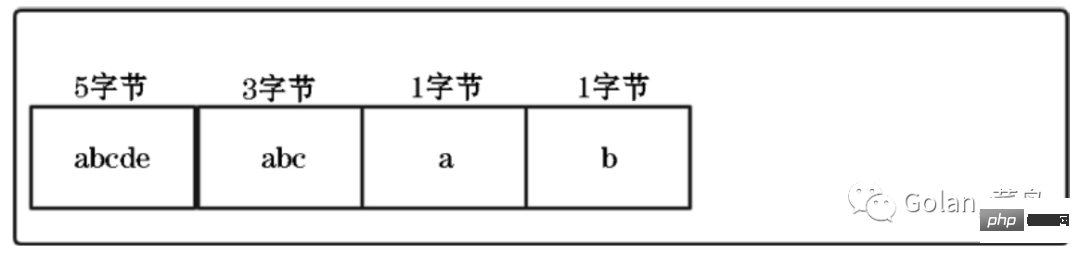
Es gibt auch ein Füllfeld, was bedeutet, dass die maximale Kapazität jedes Quicknode-Knotens unterschiedliche Bedeutungen hat kann auch auf andere Werte konfiguriert werden. ;list-max-ziplist-size -2
Wenn der Wert eine positive Zahl ist, stellt er die Länge der Ziplist auf dem QuicklistNode-Knoten dar. Wenn der Wert beispielsweise 5 ist, enthält die Ziplist jedes QuicklistNode-Knotens höchstens 5 Datenelemente Begrenzt entsprechend der Anzahl der Bytes. Mögliche Werte sind -1 bis -5.
| Wert | Bedeutung |
|---|---|
| -1 | Die maximale Größe des Ziplist-Knotens beträgt 4 KB |
| - 2 | Der maximale Ziplist-Knoten beträgt 8 KB. |
| -3 | -4 |
| -5 | Die maximale Größe des Ziplist-Knotens beträgt 64 KB. |
Das obige ist der detaillierte Inhalt vonRedis-Studiennotizen-Listen-Prinzip. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
Der Redis-Zähler ist ein Mechanismus, der die Speicherung von Redis-Schlüsselwertpaaren verwendet, um Zählvorgänge zu implementieren, einschließlich der folgenden Schritte: Erstellen von Zählerschlüssel, Erhöhung der Zählungen, Verringerung der Anzahl, Zurücksetzen der Zählungen und Erhalt von Zählungen. Die Vorteile von Redis -Zählern umfassen schnelle Geschwindigkeit, hohe Parallelität, Haltbarkeit und Einfachheit und Benutzerfreundlichkeit. Es kann in Szenarien wie Benutzerzugriffszählungen, Echtzeit-Metrikverfolgung, Spielergebnissen und Ranglisten sowie Auftragsverarbeitungszählung verwendet werden.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
