

学习channel设计:从入门到放弃
前言
今天给大家带来的是
Go语言中的channel。Go语言从出世以来就以高并发著称,得益于其Goroutine的设计,Goroutine也就是一个可执行的轻量级协程,有了Goroutine我们可以轻松的运行协程,但这并不能满足我们的需求,我们往往还希望多个线程/协程是能够通信的,Go语言为了支持多个Goroutine通信,设计了channel,本文我们就一起从GO1.15的源码出发,看看channel到底是如何设计的。
什么是channel
通过开头的介绍我们可以知道channel是用于goroutine的数据通信,在Go中通过goroutine+channel的方式,可以简单、高效地解决并发问题。我们先来看一下简单的示例:
func GoroutineOne(ch chan <-string) {
fmt.Println("GoroutineOne running")
ch <- "asong真帅"
fmt.Println("GoroutineOne end of the run")
}
func GoroutineTwo(ch <- chan string) {
fmt.Println("GoroutineTwo running")
fmt.Printf("女朋友说:%s\n",<-ch)
fmt.Println("GoroutineTwo end of the run")
}
func main() {
ch := make(chan string)
go GoroutineOne(ch)
go GoroutineTwo(ch)
time.Sleep(3 * time.Second)
}
// 运行结果
// GoroutineOne running
// GoroutineTwo running
// 女朋友说:asong真帅
// GoroutineTwo end of the run
// GoroutineOne end of the run这里我们运行了两个Goroutine,在GoroutineOne中我们向channel中写入数据,在GoroutineTwo中我们监听channel,直到读取到"asong真帅"。我们可以画一个简单的图来表明一下这个顺序:
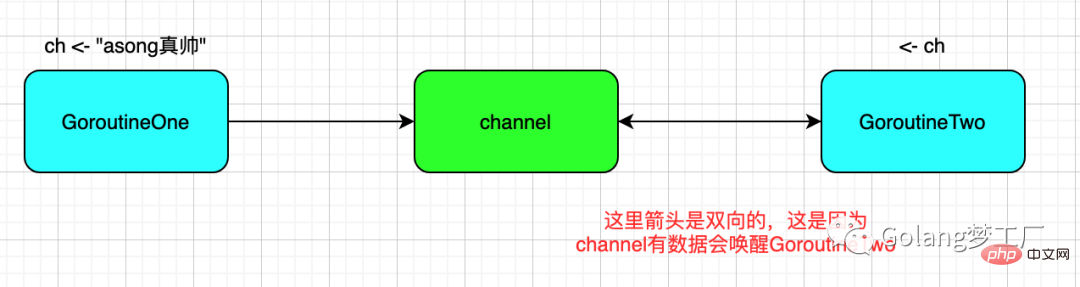
上面的例子是对无缓冲channel的一个简单应用,其实channel的使用语法还是挺多的,下面且听我慢慢道来,毕竟是从入门到放弃嘛,那就先从入门开始。
入门channel
channel类型
channel有三种类型的定义,分别是:chan、chan <-、<- chan,可选的<-代表channel的方向,如果我们没有指定方向,那么channel就是双向的,既可以接收数据,也可以发送数据。
chan T // 接收和发送类型为T的数据 chan<- T // 只可以用来发送 T 类型的数据 <- chan T // 只可以用来接收 T 类型的数据
创建channel
我们可以使用make初始化channel,可以创建两种两种类型的channel:无缓冲的channel和有缓冲的channel。
示例:
ch_no_buffer := make(chan int) ch_no_buffer := make(chan int, 0) ch_buffer := make(chan int, 100)
没有设置容量或者容量设置为0,则说明channel没有缓存,此时只有发送方和接收方都准备好后他们才可以进行通讯,否则就是一直阻塞。如果容量设置大于0,那就是一个带缓冲的channel,发送方只有buffer满了之后才会阻塞,接收方只有缓存空了才会阻塞。
注意:未初始化(为nil)的channel是不可以通信的
func main() {
var ch chan string
ch <- "asong真帅"
fmt.Println(<- ch)
}
// 运行报错
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send (nil chan)]:channel入队
channel的入队定义如下:
"channel" <- "要入队的值(可以是表达式)"
在无缓冲的channel中,只有在出队方准备好后,channel才会入队,否则一直阻塞着,所以说无缓冲channel是同步的。
在有缓冲的channel中,缓存未满时,就会执行入队操作。
向nil的channel中入队会一直阻塞,导致死锁。
channel单个出队
channel的单个出队定义如下:
<- "channel"
无论是有无缓冲的channel在接收不到数据时都会阻塞,直到有数据可以接收。
从nil的channel中接收数据会一直阻塞。
channel的出队还有一种非阻塞写法,定义如下:
val, ok := <-ch
这么写可以判断当前channel是否关闭,如果这个channel被关闭了,ok会被设置为false,val就是零值。
channel循环出队
我们可以使用for-range循环处理channel。
func main() {
ch := make(chan int,10)
go func() {
for i:=0;i<10;i++{
ch <- i
}
close(ch)
}()
for val := range ch{
fmt.Println(val)
}
fmt.Println("over")
}range ch会一直迭代到channel被关闭。在使用有缓冲channel时,配合for-range是一个不错的选择。
配合select使用
Go语言中的select能够让Goroutine同时等待多个channel读或者写,在channel状态未改变之前,select会一直阻塞当前线程或Goroutine。先看一个例子:
func fibonacci(ch chan int, done chan struct{}) {
x, y := 0, 1
for {
select {
case ch <- x:
x, y = y, x+y
case <-done:
fmt.Println("over")
return
}
}
}
func main() {
ch := make(chan int)
done := make(chan struct{})
go func() {
for i := 0; i < 10; i++ {
fmt.Println(<-ch)
}
done <- struct{}{}
}()
fibonacci(ch, done)
}select与switch具有相似的控制结构,与switch不同的是,select中的case中的表达式必须是channel的收发操作,当select中的两个case同时被触发时,会随机执行其中的一个。为什么是随机执行的呢?随机的引入就是为了避免饥饿问题的发生,如果我们每次都是按照顺序依次执行的,若两个case一直都是满足条件的,那么后面的case永远都不会执行。
上面例子中的select用法是阻塞式的收发操作,直到有一个channel发生状态改变。我们也可以在select中使用default语句,那么select语句在执行时会遇到这两种情况:
当存在可以收发的 Channel时,直接处理该Channel对应的case;当不存在可以收发的 Channel时,执行default中的语句;
注意:nil channel上的操作会一直被阻塞,如果没有default case,只有nil channel的select会一直被阻塞。
关闭channel
内建的close方法可以用来关闭channel。如果channel已经关闭,不可以继续发送数据了,否则会发生panic,但是从这个关闭的channel中不但可以读取出已发送的数据,还可以不断的读取零值。
func main() {
ch := make(chan int, 10)
ch <- 10
ch <- 20
close(ch)
fmt.Println(<-ch) //1
fmt.Println(<-ch) //2
fmt.Println(<-ch) //0
fmt.Println(<-ch) //0
}channel基本设计思想
channel设计的基本思想是:不要通过共享内存来通信,而是通过通信来实现共享内存(Do not communicate by sharing memory; instead, share memory by communicating)。
这个思想大家是否理解呢?我在这里分享一下我的理解(查找资料+个人理解),有什么不对的,留言区指正或开喷!
什么是使用共享内存来通信?其实就是多个线程/协程使用同一块内存,通过加锁的方式来宣布使用某块内存,通过解锁来宣布不再使用某块内存。
什么是通过通信来实现共享内存?其实就是把一份内存的开销变成两份内存开销而已,再说的通俗一点就是,我们使用发送消息的方式来同步信息。
为什么鼓励使用通过通信来实现共享内存?使用发送消息来同步信息相比于直接使用共享内存和互斥锁是一种更高级的抽象,使用更高级的抽象能够为我们在程序设计上提供更好的封装,让程序的逻辑更加清晰;其次,消息发送在解耦方面与共享内存相比也有一定优势,我们可以将线程的职责分成生产者和消费者,并通过消息传递的方式将它们解耦,不需要再依赖共享内存。
对于这个理解更深的文章,建议读一下这篇文章:为什么使用通信来共享内存
channel在设计上本质就是一个有锁的环形队列,包括发送方队列、接收方队列、互斥锁等结构,下面我就一起从源码出发,剖析这个有锁的环形队列是怎么设计的!
源码剖析
数据结构
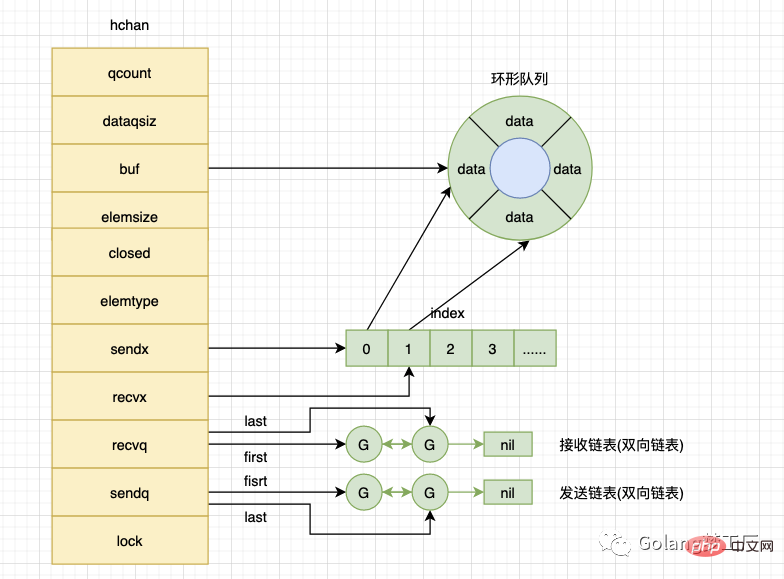
在src/runtime/chan.go中我们可以看到hchan的结构如下:
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
lock mutex
}我们来解释一下hchan中每个字段都是什么意思:
qcount:循环数组中的元素数量dataqsiz:循环数组的长度buf:只针对有缓冲的channel,指向底层循环数组的指针elemsize:能够接收和发送的元素大小closed:channel是否关闭标志elemtype:记录channel中元素的类型sendx:已发送元素在循环数组中的索引recvx:已接收元素在循环数组中的索引recvq:等待接收的goroutine队列senq:等待发送的goroutine队列lock:互斥锁,保护hchan中的字段,保证读写channel的操作都是原子的。
这个结构结合上面那个图理解就更清晰了:
buf是指向底层的循环数组,dataqsiz就是这个循环数组的长度,qcount就是当前循环数组中的元素数量,缓冲的channel才有效。elemsize和elemtype就是我们创建channel时设置的容量大小和元素类型。sendq、recvq是一个双向链表结构,分别表示被阻塞的goroutine链表,这些 goroutine 由于尝试读取channel或向channel发送数据而被阻塞。
对于上面的描述,我们可以画出来这样的一个理解图:
channel的创建
前面介绍channel入门的时候我们就说到了,我们使用make进行创建,make在经过编译器编译后对应的runtime.makechan或runtime.makechan64。为什么会有这个区别呢?先看一下代码:
// go 1.15.7
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}runtime.makechan64本质也是调用的makechan方法,只不过多了一个数值溢出的校验。runtime.makechan64是用于处理缓冲区大于2的32方,所以这两个方法会根据传入的参数类型和缓冲区大小进行选择。大多数情况都是使用makechan。我们只需要分析makechan函数就可以了。
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 对发送元素进行限制 1<<16 = 65536
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 检查是否对齐
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 判断是否会发生内存溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// 构造hchan对象
var c *hchan
switch {
// 说明是无缓冲的channel
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
// 元素类型不包含指针,只进行一次内存分配
// 如果hchan结构体中不含指针,gc就不会扫描chan中的元素,所以我们只需要分配
// "hchan 结构体大小 + 元素大小*个数" 的内存
case elem.ptrdata == 0:
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
// 元素包含指针,进行两次内存分配操作
default:
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 初始化hchan中的对象
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}注释我都添加上了,应该很容易懂吧,这里在特殊说一下分配内存这块的内容,其实归一下类,就只有两块:
分配一次内存:若创建的 channel是无缓冲的,或者创建的有缓冲的channel中存储的类型不存在指针引用,就会调用一次mallocgc分配一段连续的内存空间。分配两次内存:若创建的有缓冲 channel存储的类型存在指针引用,就会连同hchan和底层数组同时分配一段连续的内存空间。
因为都是调用mallocgc方法进行内存分配,所以channel都是在堆上创建的,会进行垃圾回收,不关闭close方法也是没有问题的(但是想写出漂亮的代码就不建议你这么做了)。
channel入队
channel发送数据部分的代码经过编译器编译后对应的是runtime.chansend1,其调用的也是runtime.chansend方法:
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}我们主要分析一下chansend方法,代码有点长,我们分几个步骤来看这段代码:
前置检查 加锁/异常检查 channel直接发送数据channel发送数据缓冲区有可用空间channel发送数据缓冲区无可用空间
前置检查
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, funcPC(chansend))
}
if !block && c.closed == 0 && full(c) {
return false
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}这里最主要的检查就是判断当前channel是否为nil,往一个nil的channel中发送数据时,会调用gopark函数将当前执行的goroutine从running状态转入waiting状态,这让就会导致进程出现死锁,表象出panic事件。
紧接着会对非阻塞的channel进行一个上限判断,看看是否快速失败,这里相对于之前的版本做了改进,使用full方法来对hchan结构进行校验。
func full(c *hchan) bool {
if c.dataqsiz == 0 {
return c.recvq.first == nil
}
return c.qcount == c.dataqsiz
}这里快速失败校验逻辑如下:
若是 qcount与dataqsiz大小相同(缓冲区已满)时,则会返回失败。非阻塞且未关闭,同时底层数据 dataqsiz大小为0(无缓冲channel),如果接收方没准备好则直接返回失败。
加锁/异常检查
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}前置校验通过后,在发送数据的逻辑执行之前会先为当前的channel加锁,防止多个协程并发修改数据。如果Channel 已经关闭,那么向该 Channel发送数据时会报“send on closed channel”错误并中止程序。
channel直接发送数据
直接发送数据是指 如果已经有阻塞的接收goroutines(即recvq中指向非空),那么数据将被直接发送给接收goroutine。
if sg := c.recvq.dequeue(); sg != nil {
//找到一个等待的接收器。我们将想要发送的值直接传递给接收者,绕过通道缓冲区(如果有的话)。
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}这里主要是调用Send方法,我们来看一下这个函数:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 静态竞争省略掉
// elem是指接收到的值存放的位置
if sg.elem != nil {
// 调用sendDirect方法直接进行内存拷贝
// 从发送者拷贝到接收者
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
// 绑定goroutine
gp := sg.g
// 解锁
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 唤醒接收的 goroutine
goready(gp, skip+1)
}我们再来看一下SendDirect方法:
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
dst := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}这里调用了memove方法进行内存拷贝,这里是从一个 goroutine 直接写另一个 goroutine 栈的操作,这样做的好处是减少了一次内存 copy:不用先拷贝到 channel 的buf,直接由发送者到接收者,没有中间商赚差价,效率得以提高,完美。
channel发送数据缓冲区有可用空间
接着往下看代码,判断channel缓冲区是否还有可用空间:
// 判断通道缓冲区是否还有可用空间
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)
// 指向下一个待发送元素在循环数组中的位置
c.sendx++
// 因为存储数据元素的结构是循环队列,所以当当前索引号已经到队末时,将索引号调整到队头
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 当前循环队列中存储元素数+1
c.qcount++
// 释放锁,发送数据完毕
unlock(&c.lock)
return true
}这里的几个步骤还是挺好理解的,注释已经添加到代码中了,我们再来详细解析一下:
如果当前缓冲区还有可用空间,则调用 chanbuf方法获取底层缓冲数组中sendx索引的元素指针值调用 typedmemmove方法将发送的值拷贝到缓冲区中数据拷贝成功, sendx进行+1操作,指向下一个待发送元素在循环数组中的位置。如果下一个索引位置正好是循环队列的长度,那么就需要把所谓位置归0,因为这是一个循环环形队列。发送数据成功后,队列元素长度自增,至此发送数据完毕,释放锁,返回结果即可。
channel发送数据缓冲区无可用空间
缓冲区空间也会有满了的时候,这是有两种方式可以选择,一种是直接返回,另外一种是阻塞等待。
直接返回的代码就很简单了,做一个简单的是否阻塞判断,不阻塞的话,直接释放锁,返回即可。
if !block {
unlock(&c.lock)
return false
}阻塞的话代码稍微长一点,我们来分析一下:
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
KeepAlive(ep)首先通过调用gettg获取当前执行的goroutine,然后调用acquireSudog方法构造sudog结构体,然后设置待发送信息和goroutine等信息(sudog 通过 g 字段绑定 goroutine,而goroutine 通过waiting绑定 sudog,sudog 还通过 elem 字段绑定待发送元素的地址);构造完毕后调用c.sendq.enqueue将其放入待发送的等待队列,最后调用gopark方法挂起当前的goroutine进入wait状态。
这里在最后调用了KeepAlive方法,很多人对这个比较懵逼,我来解释一下。这个方法就是为了保证待发送的数据处于活跃状态,也就是分配在堆上避免被GC。这里我在画一个图解释一下上面的绑定过程,更加深理解。
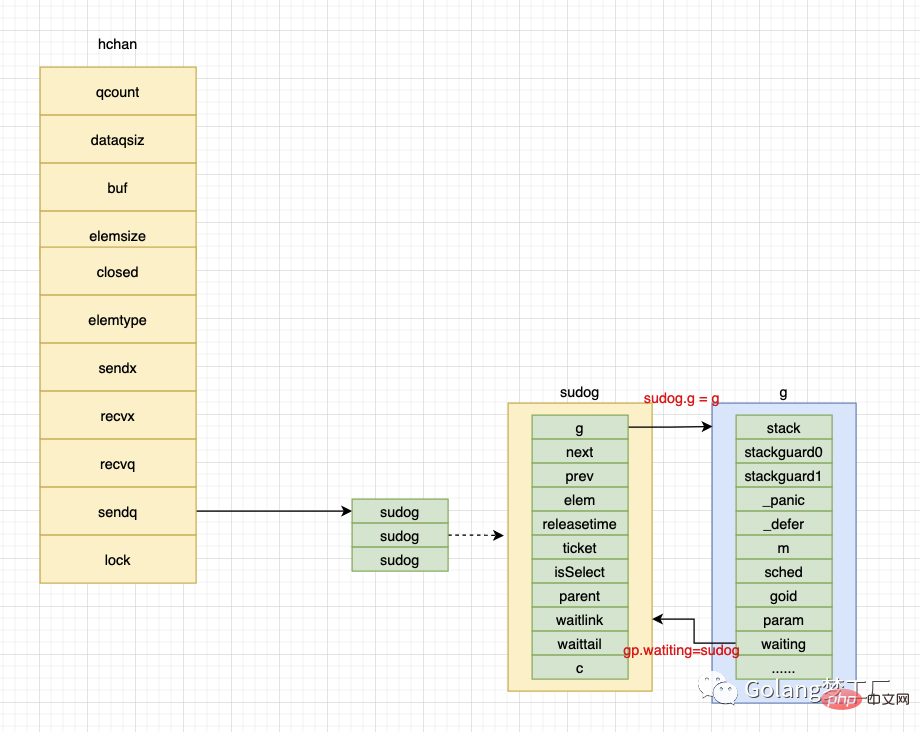
现在goroutine处于wait状态了,等待被唤醒,唤醒代码如下:
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if gp.param == nil {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
// 唤醒后channel被关闭了,直接panic
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
// 去掉mysg上绑定的channel
mysg.c = nil
// 释放sudog
releaseSudog(mysg)
return true唤醒的逻辑比较简单,首先判断goroutine是否还存在,不存在则抛出异常。唤醒后还有一个检查是判断当前channel是否被关闭了,关闭了则触发panic。最后我们开始取消mysg上的channel绑定和sudog的释放。
这里大家肯定好奇,怎么没有看到唤醒后执行发送数据动作?之所以有这个想法,就是我们理解错了。在上面我们已经使goroutine进入了wait状态,那么调度器在停止g 时会记录运行线程和方法内执行的位置,也就是这个ch <- "asong"位置,唤醒后会在这个位置开始执行,代码又开始重新执行了,但是我们之前进入wait状态的绑定是要解绑与释放的,否则下次进来就会出现问题喽。
接收数据
之前我们介绍过channel接收数据有两种方式,如下:
val := <- ch val, ok := <- ch
它们在经过编译器编译后分别对应的是runtime.chanrecv1 和 runtime.chanrecv2:
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}其实都是调用chanrecv方法,所以我们只需要解析这个方法就可以了。接收部分的代码和接收部分的代码是相对应的,所以我们也可以分几个步骤来看这部分代码:
前置检查 加锁和提前返回 channel直接接收数据channel缓冲区有数据channel缓冲区无数据
前置检查
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if atomic.Load(&c.closed) == 0 {
return
}
if empty(c) {
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}首先也会判断当前channel是否为nil channel,如果是nil channel且为非阻塞接收,则直接返回即可。如果是nil channel且为阻塞接收,则直接调用gopark方法挂起当前goroutine。
然后也会进行快速失败检查,这里只会对非阻塞接收的channel进行快速失败检查,检查规则如下:
func empty(c *hchan) bool {
// c.dataqsiz is immutable.
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}当循环队列为 0且等待队列 sendq内没有 goroutine 正在等待或者缓冲区数组为空时,如果channel还未关闭,这说明没有要接收的数据,直接返回即可。如果channel已经关闭了且缓存区没有数据了,则会清理ep指针中的数据并返回。这里为什么清理ep指针呢?ep指针是什么?这个ep就是我们要接收的值存放的地址(val := <-ch val就是ep ),即使channel关闭了,我们也可以接收零值。
加锁和提前返回
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}前置校验通过后,在执行接收数据的逻辑之前会先为当前的channel加锁,防止多个协程并发接收数据。同样也会判断当前channel是否被关闭,如果channel被关闭了,并且缓存区没有数据了,则直接释放锁和清理ep中的指针数据,不需要再走接下来的流程。
channel直接接收数据
这一步与channel直接发送数据是对应的,当发现channel上有正在阻塞等待的发送方时,则直接进行接收。
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}等待发送队列里有goroutine存在,有两种可能:
非缓冲的 channel缓冲的 channel,但是缓冲区满了
针对这两种情况,在recv方法中的执行逻辑是不同的:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 非缓冲channel
if c.dataqsiz == 0 {
// 未忽略接收值
if ep != nil {
// 直接从发送方拷贝数据到接收方
recvDirect(c.elemtype, sg, ep)
}
} else { // 有缓冲channel,但是缓冲区满了
// 缓冲区满时,接收方和发送方游标重合了
// 因为是循环队列,都是游标0的位置
// 获取当前接收方游标位置下的值
qp := chanbuf(c, c.recvx)
// 未忽略值的情况下直接从发送方拷贝数据到接收方
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 将发送者数据拷贝到缓冲区中
typedmemmove(c.elemtype, qp, sg.elem)
// 自增到下一个待接收位置
c.recvx++
// 如果下一个待接收位置等于队列长度了,则下一个待接收位置为队头,因为是循环队列
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 上面已经将发送者数据拷贝到缓冲区中了,所以缓冲区还是满的,所以发送方位置仍然等于接收方位置。
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
// 绑定发送方goroutine
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 唤醒发送方的goroutine
goready(gp, skip+1)
}代码中的注释已经很清楚了,但还是想在解释一遍,这里主要就是分为两种情况:
非缓冲区 channel:未忽略接收值时直接调用recvDirect方法直接从发送方的goroutine调用栈中将数据拷贝到接收方的goroutine。带缓冲区的 channel:首先调用chanbuf方法根据recv索引的位置读取缓冲区元素,并将其拷贝到接收方的内存地址;拷贝完毕后调整sendx和recvx索引位置。
最后别忘了还有一个操作就是调用goready方法唤醒发送方的goroutine可以继续发送数据了。
channel缓冲区有数据
我们接着往下看代码,若当前channel的缓冲区有数据时,代码逻辑如下:
// 缓冲channel,buf里有可用元素,发送方也可以正常发送
if c.qcount > 0 {
// 直接从循环队列中找到要接收的元素
qp := chanbuf(c, c.recvx)
// 未忽略接收值,直接把缓冲区的值拷贝到接收方中
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 清理掉循环数组里相应位置的值
typedmemclr(c.elemtype, qp)
// 接收游标向前移动
c.recvx++
// 超过循环队列的长度时,接收游标归0(循环队列)
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 循环队列中的数据数量减1
c.qcount--
// 接收数据完毕,释放锁
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}这段代码没什么难度,就不再解释一遍了。
channel缓冲区无数据
经过上面的步骤,现在可以确定目前这个channel既没有待发送的goroutine,并且缓冲区也没有数据。接下来就看我们是否阻塞等待接收数据了,也就有了如下判断:
if !block {
unlock(&c.lock)
return false, false
}非阻塞接收数据的话,直接返回即可;否则则进入阻塞接收模式:
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)这一部分的逻辑基本与发送阻塞部分一模一样,大概逻辑就是获取当前的goroutine,然后构建sudog结构保存待接收数据的地址信息和goroutine信息,并将sudog加入等待接收队列,最后挂起当前goroutine,等待唤醒。
接下来的环境逻辑也没有特别要说的,与发送方唤醒部分一模一样,不懂的可以看前面。唤醒后的主要工作就是恢复现场,释放绑定信息。
关闭channel
使用close可以关闭channel,其经过编译器编译后对应的是runtime.closechan方法,详细逻辑我们通过注释到代码中:
func closechan(c *hchan) {
// 对一个nil的channel进行关闭会引发panic
if c == nil {
panic(plainError("close of nil channel"))
}
// 加锁
lock(&c.lock)
// 关闭一个已经关闭的channel也会引发channel
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
// 关闭channnel标志
c.closed = 1
// Goroutine集合
var glist gList
// 接受者的 sudog 等待队列(recvq)加入到待清除队列 glist 中
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// 发送方的sudog也加入到到待清除队列 glist 中
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
// 要关闭的goroutine,发送的值设为nil
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = nil
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// 释放了发送方和接收方后,释放锁就可以了。
unlock(&c.lock)
// 将所有 glist 中的 goroutine 状态从 _Gwaiting 设置为 _Grunnable 状态,等待调度器的调度。
// 我们既然是从sendq和recvq中获取的goroutine,状态都是挂起状态,所以需要唤醒他们,走后面的流程。
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}这里逻辑还是比较简单,归纳总结一下:
一个为 nil的channel不允许进行关闭不可以重复关闭 channel获取当前正在阻塞的发送或者接收的 goroutine,他们都处于挂起状态,然后进行唤醒。这是发送方不允许在向channel发送数据了,但是不影响接收方继续接收元素,如果没有元素,获取到的元素是零值。使用val,ok := <-ch可以判断当前channel是否被关闭。
总结
哇塞,开往幼儿园的车终于停了,小松子唠唠叨叨一路了,你们学会了吗?
我们从入门开始到最后的源码剖析,其实channel的设计一点也不复杂,源码也是很容易看懂的,本质就是维护了一个循环队列嘛,发送数据遵循FIFO(First In First Out)原语,数据传递依赖于内存拷贝。不懂的可以再看一遍,很容易理解的哦~。
Das obige ist der detaillierte Inhalt von学习channel设计:从入门到放弃. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Wie kann ich Dateien mit Golang sicher lesen und schreiben?
Jun 06, 2024 pm 05:14 PM
Wie kann ich Dateien mit Golang sicher lesen und schreiben?
Jun 06, 2024 pm 05:14 PM
Das sichere Lesen und Schreiben von Dateien in Go ist von entscheidender Bedeutung. Zu den Richtlinien gehören: Überprüfen von Dateiberechtigungen, Schließen von Dateien mithilfe von Verzögerungen, Validieren von Dateipfaden, Verwenden von Kontext-Timeouts. Das Befolgen dieser Richtlinien gewährleistet die Sicherheit Ihrer Daten und die Robustheit Ihrer Anwendungen.
 Wie konfiguriere ich den Verbindungspool für die Golang-Datenbankverbindung?
Jun 06, 2024 am 11:21 AM
Wie konfiguriere ich den Verbindungspool für die Golang-Datenbankverbindung?
Jun 06, 2024 am 11:21 AM
Wie konfiguriere ich Verbindungspooling für Go-Datenbankverbindungen? Verwenden Sie den DB-Typ im Datenbank-/SQL-Paket, um eine Datenbankverbindung zu erstellen. Legen Sie MaxOpenConns fest, um die maximale Anzahl gleichzeitiger Verbindungen festzulegen. Legen Sie ConnMaxLifetime fest, um den maximalen Lebenszyklus der Verbindung festzulegen.
 Golang Framework vs. Go Framework: Vergleich der internen Architektur und externen Funktionen
Jun 06, 2024 pm 12:37 PM
Golang Framework vs. Go Framework: Vergleich der internen Architektur und externen Funktionen
Jun 06, 2024 pm 12:37 PM
Der Unterschied zwischen dem GoLang-Framework und dem Go-Framework spiegelt sich in der internen Architektur und den externen Funktionen wider. Das GoLang-Framework basiert auf der Go-Standardbibliothek und erweitert deren Funktionalität, während das Go-Framework aus unabhängigen Bibliotheken besteht, um bestimmte Zwecke zu erreichen. Das GoLang-Framework ist flexibler und das Go-Framework ist einfacher zu verwenden. Das GoLang-Framework hat einen leichten Leistungsvorteil und das Go-Framework ist skalierbarer. Fall: Gin-Gonic (Go-Framework) wird zum Erstellen der REST-API verwendet, während Echo (GoLang-Framework) zum Erstellen von Webanwendungen verwendet wird.
 Wie speichere ich JSON-Daten in einer Datenbank in Golang?
Jun 06, 2024 am 11:24 AM
Wie speichere ich JSON-Daten in einer Datenbank in Golang?
Jun 06, 2024 am 11:24 AM
JSON-Daten können mithilfe der gjson-Bibliothek oder der json.Unmarshal-Funktion in einer MySQL-Datenbank gespeichert werden. Die gjson-Bibliothek bietet praktische Methoden zum Parsen von JSON-Feldern, und die Funktion json.Unmarshal erfordert einen Zieltypzeiger zum Unmarshalieren von JSON-Daten. Bei beiden Methoden müssen SQL-Anweisungen vorbereitet und Einfügevorgänge ausgeführt werden, um die Daten in der Datenbank beizubehalten.
 Was sind die Best Practices für die Fehlerbehandlung im Golang-Framework?
Jun 05, 2024 pm 10:39 PM
Was sind die Best Practices für die Fehlerbehandlung im Golang-Framework?
Jun 05, 2024 pm 10:39 PM
Best Practices: Erstellen Sie benutzerdefinierte Fehler mit klar definierten Fehlertypen (Fehlerpaket). Stellen Sie weitere Details bereit. Protokollieren Sie Fehler ordnungsgemäß. Geben Sie Fehler korrekt weiter und vermeiden Sie das Ausblenden oder Unterdrücken. Wrappen Sie Fehler nach Bedarf, um Kontext hinzuzufügen
 Wie finde ich den ersten Teilstring, der mit einem regulären Golang-Ausdruck übereinstimmt?
Jun 06, 2024 am 10:51 AM
Wie finde ich den ersten Teilstring, der mit einem regulären Golang-Ausdruck übereinstimmt?
Jun 06, 2024 am 10:51 AM
Die FindStringSubmatch-Funktion findet die erste Teilzeichenfolge, die mit einem regulären Ausdruck übereinstimmt: Die Funktion gibt ein Segment zurück, das die passende Teilzeichenfolge enthält, wobei das erste Element die gesamte übereinstimmende Zeichenfolge und die nachfolgenden Elemente einzelne Teilzeichenfolgen sind. Codebeispiel: regexp.FindStringSubmatch(text,pattern) gibt einen Ausschnitt übereinstimmender Teilzeichenfolgen zurück. Praktischer Fall: Es kann verwendet werden, um den Domänennamen in der E-Mail-Adresse abzugleichen, zum Beispiel: email:="user@example.com", pattern:=@([^\s]+)$, um die Übereinstimmung des Domänennamens zu erhalten [1].
 Wie löst man häufige Sicherheitsprobleme im Golang-Framework?
Jun 05, 2024 pm 10:38 PM
Wie löst man häufige Sicherheitsprobleme im Golang-Framework?
Jun 05, 2024 pm 10:38 PM
So beheben Sie häufige Sicherheitsprobleme im Go-Framework Angesichts der weit verbreiteten Einführung des Go-Frameworks in der Webentwicklung ist die Gewährleistung seiner Sicherheit von entscheidender Bedeutung. Im Folgenden finden Sie eine praktische Anleitung zur Lösung häufiger Sicherheitsprobleme mit Beispielcode: 1. SQL-Injection Verwenden Sie vorbereitete Anweisungen oder parametrisierte Abfragen, um SQL-Injection-Angriffe zu verhindern. Beispiel: constquery="SELECT*FROMusersWHEREusername=?"stmt,err:=db.Prepare(query)iferr!=nil{//Handleerror}err=stmt.QueryR
 Ist es vielversprechender, Java oder Golang von Front-End zu Back-End-Entwicklung zu verwandeln?
Apr 02, 2025 am 09:12 AM
Ist es vielversprechender, Java oder Golang von Front-End zu Back-End-Entwicklung zu verwandeln?
Apr 02, 2025 am 09:12 AM
Backend Learning Path: Die Erkundungsreise von Front-End zu Back-End als Back-End-Anfänger, der sich von der Front-End-Entwicklung verwandelt, Sie haben bereits die Grundlage von Nodejs, ...
