
 Backend-Entwicklung
Python-Tutorial
Pandas+Pyecharts |. Visualisierung elektronischer Produktverkaufsdaten + Benutzer-RFM-Porträt
Backend-Entwicklung
Python-Tutorial
Pandas+Pyecharts |. Visualisierung elektronischer Produktverkaufsdaten + Benutzer-RFM-Porträt
Pandas+Pyecharts |. Visualisierung elektronischer Produktverkaufsdaten + Benutzer-RFM-Porträt

??
??
-
Ich hoffe, es hilft An alle, wenn Sie Fragen haben. Wenn es Bereiche gibt, die verbessert werden müssen, wenden Sie sich bitte an den Herausgeber.
Beteiligte Bibliotheken: Pandas – DatenverarbeitungPyecharts
– Datenvisualisierung-
P andas Datenverarbeitung
2.1 Daten lesen import pandas as pd from pyecharts.charts import Line from pyecharts.charts import Bar from pyecharts.charts import Pie from pyecharts.charts import Grid from pyecharts.charts import PictorialBar from pyecharts import options as opts from pyecharts.commons.utils import JsCode import warnings warnings.filterwarnings('ignore')
Nach dem Login kopieren2.2 Dateninformationen df = pd.read_csv("电子产品销售分析.csv")Nach dem Login kopieren一共有564169条数据,其中category_code、brand两列有部分数据缺失。
2.3 去掉部分用不到的列
df1 = df[['event_time', 'order_id', 'category_code', 'brand', 'price', 'user_id', 'age', 'sex', 'local']] df1.shape
Nach dem Login kopieren(564169, 9)
2.4 去除重复数据
df1 = df1.drop_duplicates() df1.shape
Nach dem Login kopieren(556456, 9)
Nach dem Login kopieren2.5 增加部分时间列
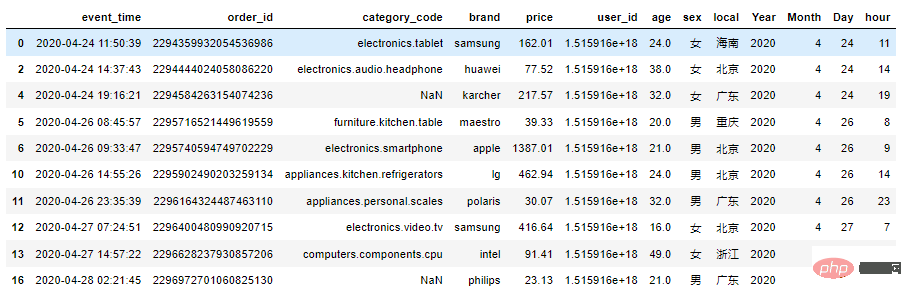
df1['event_time'] = pd.to_datetime(df1['event_time'].str[:19],format="%Y-%m-%d %H:%M:%S") df1['Year'] = df1['event_time'].dt.year df1['Month'] = df1['event_time'].dt.month df1['Day'] = df1['event_time'].dt.day df1['hour'] = df1['event_time'].dt.hour df1.head(10)
Nach dem Login kopieren
2.6 过滤数据,也可以选择均值填充
df1 = df1.dropna(subset=['category_code']) df1 = df1[(df1["Year"] == 2020)&(df1["price"] > 0)] df1.shape
Nach dem Login kopieren(429261, 13)
Nach dem Login kopieren2.7 对年龄分组
Nach dem Login kopierendf1['age_group'] = pd.cut(df1['age'],[10,20,30,40,50],labels=['10-20','20-30','30-40','40-50'])
Nach dem Login kopieren2.8 增加商品一、二级分类
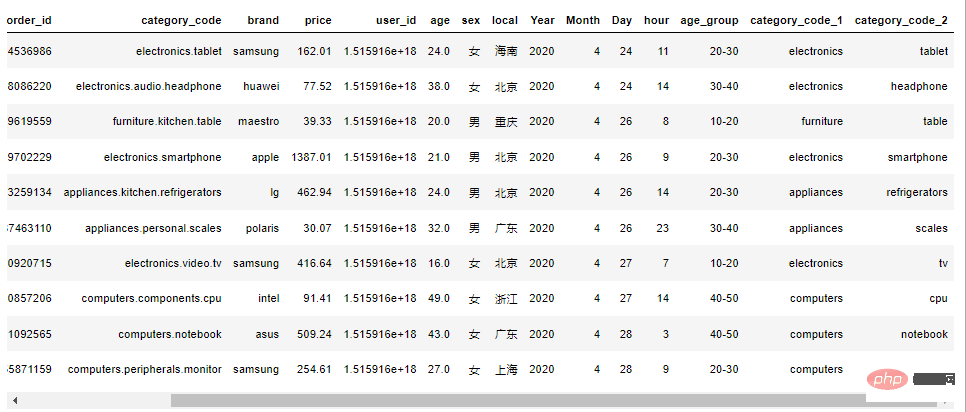
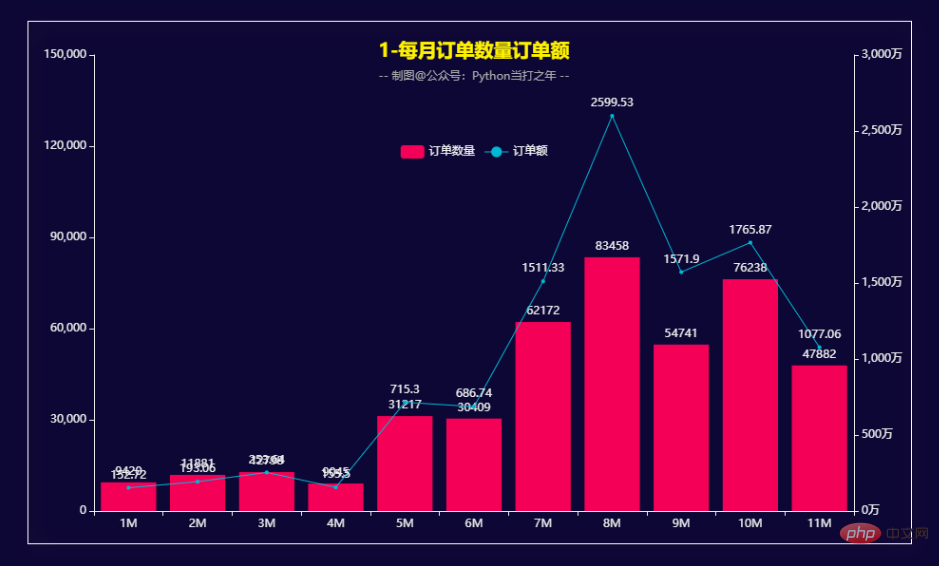
Nach dem Login kopierendf1["category_code_1"] = df1["category_code"].apply(lambda x: x.split(".")[0] if "." in x else x) df1["category_code_2"] = df1["category_code"].apply(lambda x: x.split(".")[-1] if "." in x else x) df1.head(10)Nach dem Login kopieren数据处理后还有87678个用户429261条数据。 3. Pyecharts数据可视化 3.1 每月订单数量订单额 def get_bar1(): bar1 = ( Bar() .add_xaxis(x_data) .add_yaxis("订单数量", y_data1) .extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value}万"))) .set_global_opts( legend_opts=opts.LegendOpts(pos_top='25%', pos_left='center'), title_opts=opts.TitleOpts( title='1-每月订单数量订单额', subtitle='-- 制图@公众号:Python当打之年 --', pos_top='7%', pos_left="center" ) ) ) line = ( Line() .add_xaxis(x_data) .add_yaxis("订单额", y_data2, yaxis_index=1) ) bar1.overlap(line)Nach dem Login kopieren下半年的订单量和订单额相对于上半年明显增多。 8月份的订单量和订单额达到峰值。
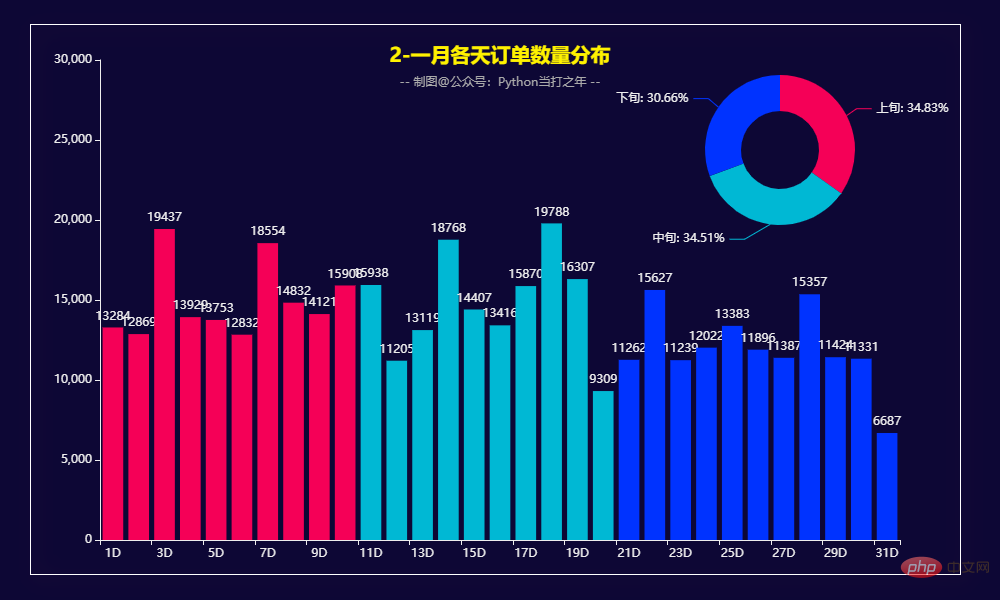
3.2 一月各天订单数量分布 def get_bar2(): pie1 = ( Pie() .add( "", datas, radius=["13%", "25%"], label_opts=opts.LabelOpts(formatter="{b}: {d}%"), ) ) bar1 = ( Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='600px', bg_color='#0d0735')) .add_xaxis(x_data) .add_yaxis("", y_data, itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_function))) .set_global_opts( legend_opts=opts.LegendOpts(is_show=False), title_opts=opts.TitleOpts( title='2-一月各天订单数量分布', subtitle='-- 制图@公众号:Python当打之年 --', pos_top='7%', pos_left="center" ) ) ) bar1.overlap(pie1)Nach dem Login kopieren从每天的订单量上看,上中下旬订单量基本持平,占比都在30%以上,上旬和中旬要稍微高一点。
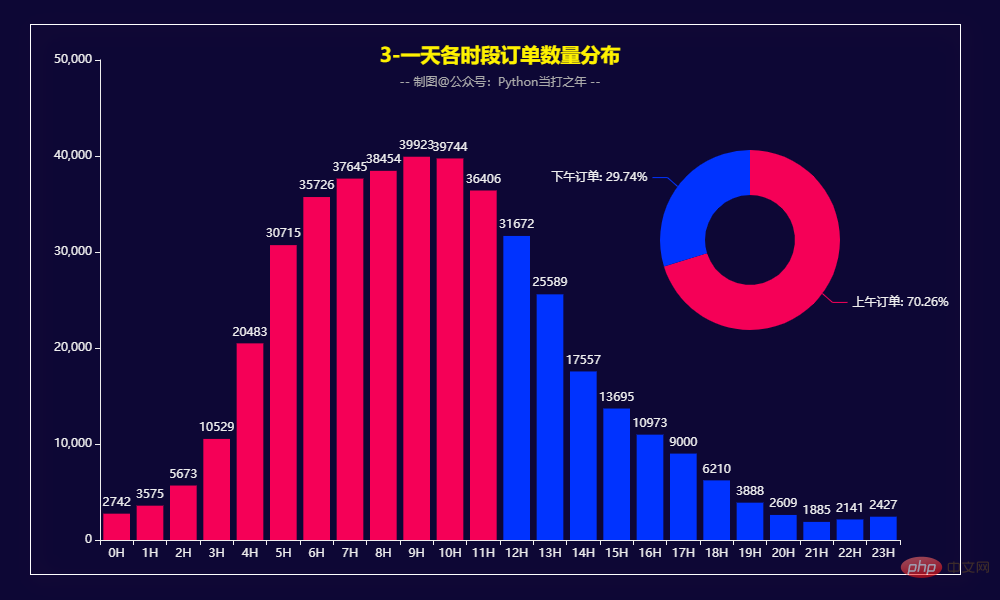
3.3 一天各时段订单数量分布 从订单时段上看,上午的订单要明显高于下午,占比达到了70.26%,尤其是在早上7:00-11:00之间。
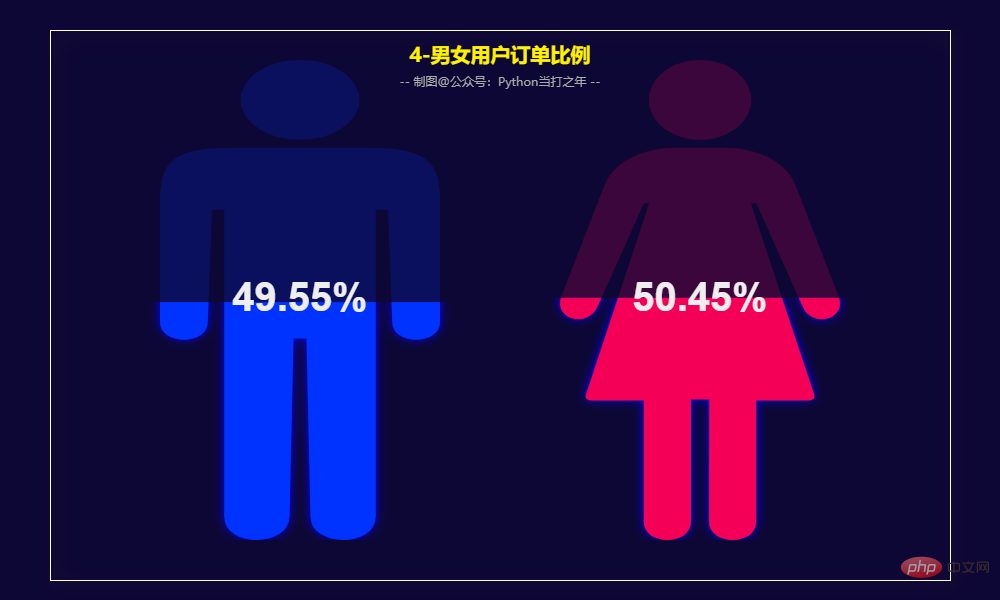
3.4 男女用户订单比例 男性订单数量占比49.55%,女性订单数量占比50.45%,基本持平。
3.5 女性/男性购买商品TOP20
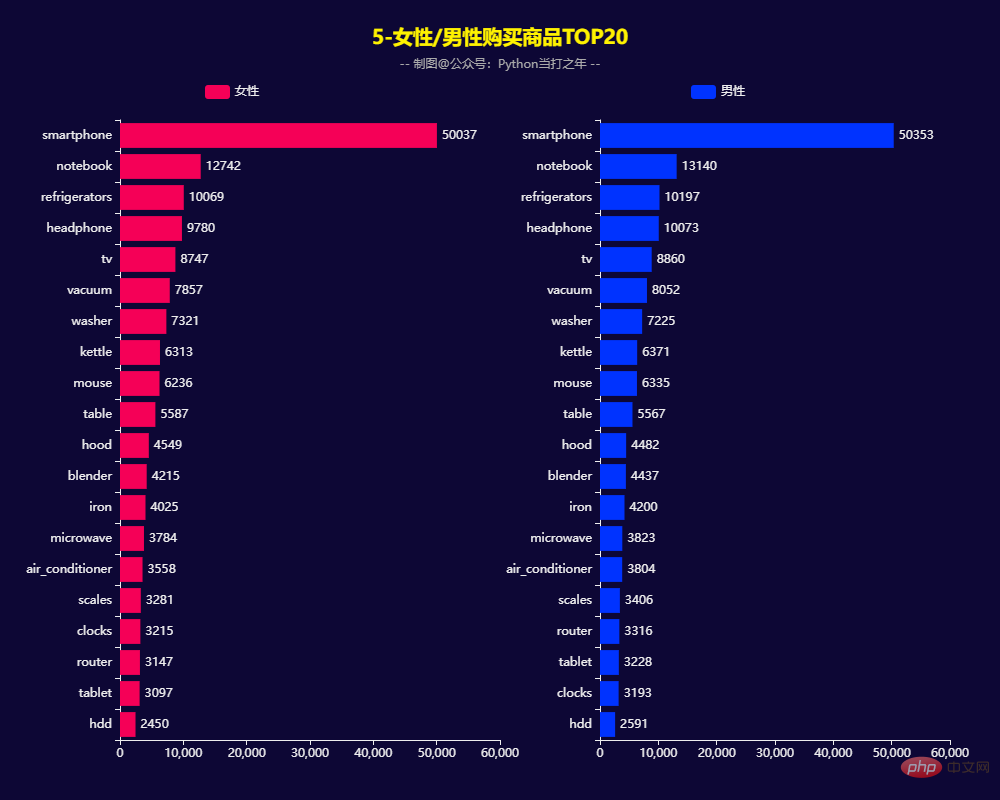
def get_bar3(): bar1 = ( Bar() .add_xaxis(x_data1) .add_yaxis('女性', y_data1, label_opts=opts.LabelOpts(position='right') ) .set_global_opts( title_opts=opts.TitleOpts( title='5-女性/男性购买商品TOP20', subtitle='-- 制图@公众号:Python当打之年 --', pos_top='3%', pos_left="center"), legend_opts=opts.LegendOpts(pos_left='20%', pos_top='10%') ) .reversal_axis() ) bar2 = ( Bar() .add_xaxis(x_data2) .add_yaxis('男性', y_data2, label_opts=opts.LabelOpts(position='right') ) .set_global_opts( legend_opts=opts.LegendOpts(pos_right='25%', pos_top='10%') ) .reversal_axis() ) grid1 = ( Grid() .add(bar1, grid_opts=opts.GridOpts(pos_left='12%', pos_right='50%', pos_top='15%')) .add(bar2, grid_opts=opts.GridOpts(pos_left='60%', pos_right='5%', pos_top='15%')) )Nach dem Login kopieren男性女性购买商品TOP20基本一致:smartphone、notebook、refrigerators、headphone等四类商品购买量比较大。
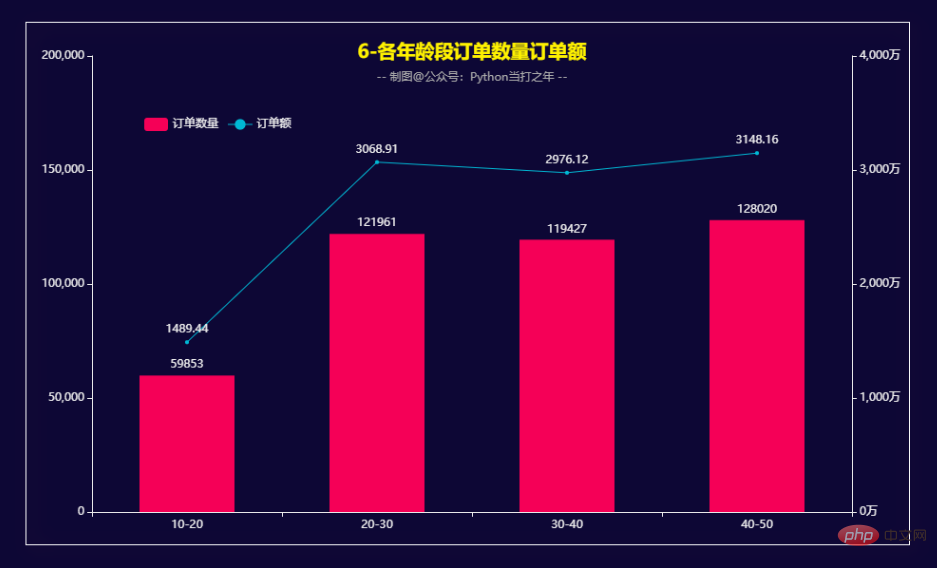
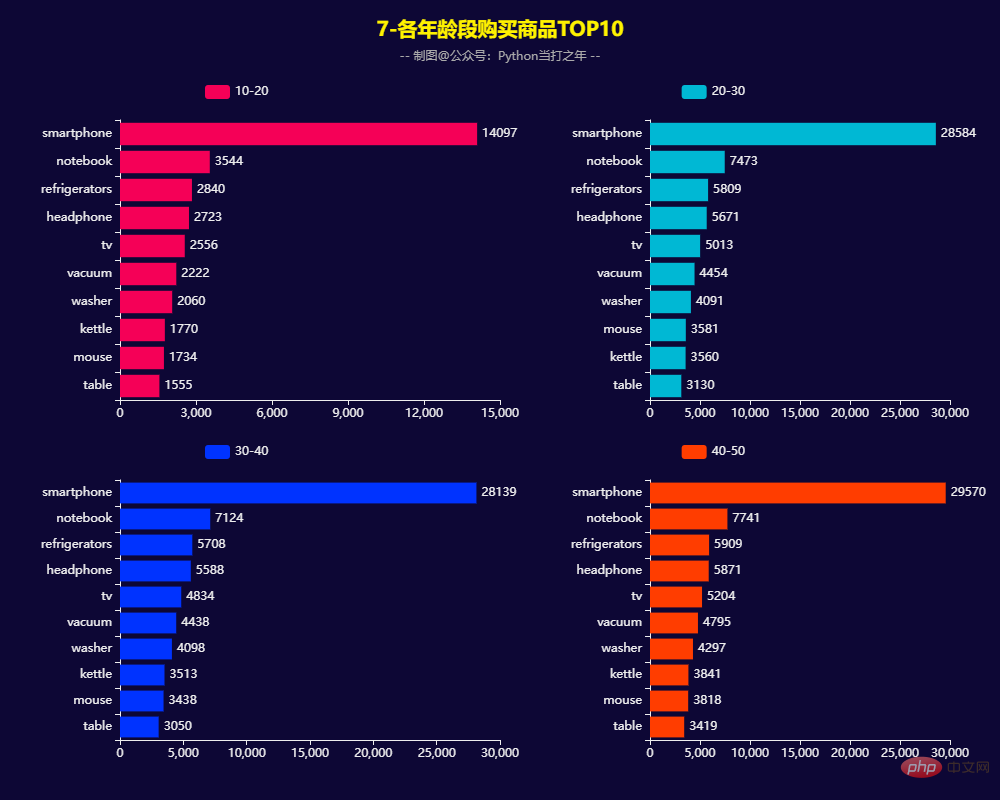
3.6 各年龄段订单数量订单额 在10-50年龄段内,随着年龄段的增加,订单量和订单金额也在逐步增大。 细分的话,20-30和40-50这两个年龄段稍高一些。
3.7 各年龄段购买商品TOP10
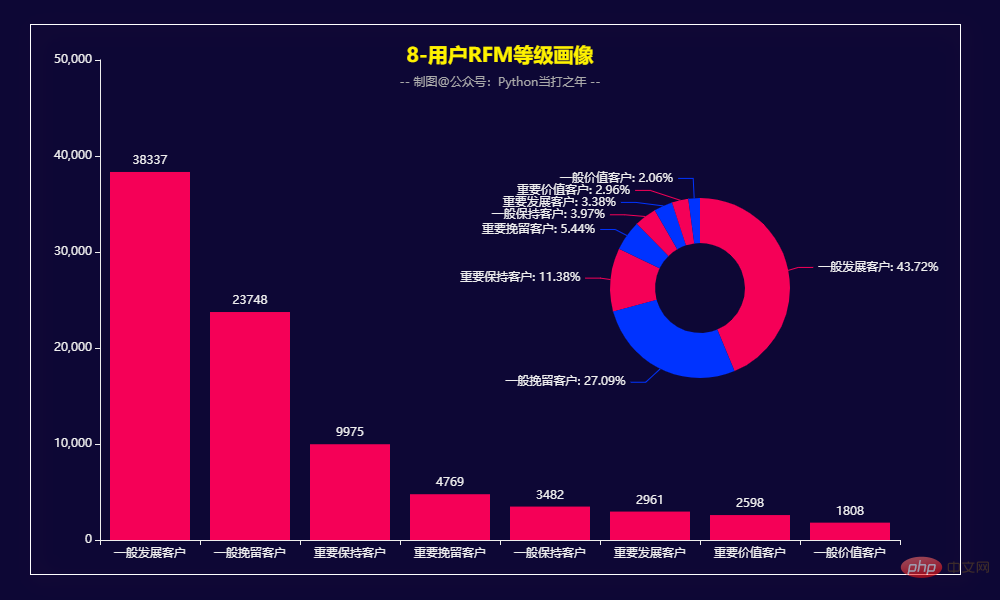
3.8 用户RFM等级画像
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为(R)、购买的总体频率(F)以及花了多少钱(M)三项指标来描述该客户的价值状况,从而能够更加准确地将成本和精力更精确的花在用户层次身上,实现针对性的营销。
用户分类:
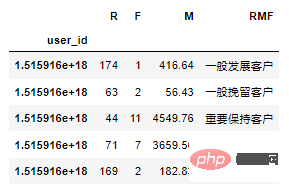
def rfm_func(x): level = x.apply(lambda x:"1" if x > 0 else '0') RMF = level.R + level.F + level.M dic_rfm ={ '111':'重要价值客户', '011':'重要保持客户', '101':'重要发展客户', '001':'重要挽留客户', '110':'一般价值客户', '100':'一般发展客户', '010':'一般保持客户', '000':'一般挽留客户' } result = dic_rfm[RMF] return resultNach dem Login kopieren计算等级:
df_rfm = df1.copy() df_rfm = df_rfm[['user_id','event_time','price']] # 时间以当年年底为准 df_rfm['days'] = (pd.to_datetime("2020-12-31")-df_rfm["event_time"]).dt.days # 计算等级 df_rfm = pd.pivot_table(df_rfm,index="user_id", values=["user_id","days","price"], aggfunc={"user_id":"count","days":"min","price":"sum"}) df_rfm = df_rfm[["days","user_id","price"]] df_rfm.columns = ["R","F","M"] df_rfm['RMF'] = df_rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1) df_rfm.head()Nach dem Login kopieren用户画像:
根据RFM模型可将用户分为以下8类:
重要价值客户:最近消费时间近、消费频次和消费金额都很高。 重要保持客户:最近消费时间较远,消费金额和频次都很高。
Wichtige Entwicklungskunden: Benutzer mit aktueller Konsumzeit und hoher Konsummenge, aber geringer Häufigkeit und geringer Loyalität, die ein hohes Potenzial haben, müssen sich auf die Entwicklung konzentrieren.
Wichtige Kundenbindung: Benutzer, deren jüngste Konsumzeit weit entfernt liegt und deren Konsumhäufigkeit nicht hoch ist, aber deren Konsummenge hoch ist, können Benutzer sein, die verloren gehen oder bereits verloren gegangen sind. und Aufbewahrungsmaßnahmen sollten ergriffen werden.
Allgemeine Wertkunden: Aktuelle Verbrauchszeit, hohe Häufigkeit, aber geringe Verbrauchsmenge. Sie müssen ihren Stückpreis erhöhen.
Allgemeine Entwicklungskunden: Der aktuelle Konsumzeitpunkt ist relativ neu und die Konsummenge und -häufigkeit ist nicht hoch.
Im Allgemeinen Kunden binden : Der aktuelle Konsumzeitpunkt ist weit entfernt, die Konsumhäufigkeit ist hoch und die Konsummenge ist nicht hoch.
Allgemeine Kundenbindung: Alle Indizes sind nicht hoch, sodass man entsprechend aufgeben kann.
Das obige ist der detaillierte Inhalt vonPandas+Pyecharts |. Visualisierung elektronischer Produktverkaufsdaten + Benutzer-RFM-Porträt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Lösung häufiger Pandas-Installationsprobleme: Interpretation und Lösungen für Installationsfehler
Feb 19, 2024 am 09:19 AM
Lösung häufiger Pandas-Installationsprobleme: Interpretation und Lösungen für Installationsfehler
Feb 19, 2024 am 09:19 AM
Pandas-Installations-Tutorial: Analyse häufiger Installationsfehler und ihrer Lösungen. Es sind spezifische Codebeispiele erforderlich. Einführung: Pandas ist ein leistungsstarkes Datenanalysetool, das in der Datenbereinigung, Datenverarbeitung und Datenvisualisierung weit verbreitet ist und daher in der Branche hohes Ansehen genießt der Datenwissenschaft. Aufgrund von Umgebungskonfigurations- und Abhängigkeitsproblemen können jedoch bei der Installation von Pandas einige Schwierigkeiten und Fehler auftreten. In diesem Artikel erhalten Sie ein Pandas-Installations-Tutorial und analysieren einige häufige Installationsfehler und deren Lösungen. 1. Pandas installieren
 So lesen Sie eine TXT-Datei mit Pandas richtig
Jan 19, 2024 am 08:39 AM
So lesen Sie eine TXT-Datei mit Pandas richtig
Jan 19, 2024 am 08:39 AM
Um Pandas zum korrekten Lesen von TXT-Dateien zu verwenden, sind bestimmte Codebeispiele erforderlich. Pandas ist eine weit verbreitete Python-Datenanalysebibliothek. Sie kann zur Verarbeitung einer Vielzahl von Datentypen verwendet werden, einschließlich CSV-Dateien, Excel-Dateien, SQL-Datenbanken usw. Gleichzeitig können damit auch Textdateien, beispielsweise TXT-Dateien, gelesen werden. Beim Lesen von TXT-Dateien treten jedoch manchmal Probleme auf, z. B. Codierungsprobleme, Trennzeichenprobleme usw. In diesem Artikel erfahren Sie, wie Sie TXT mit Pandas richtig lesen
 Lesen Sie CSV-Dateien und führen Sie eine Datenanalyse mit Pandas durch
Jan 09, 2024 am 09:26 AM
Lesen Sie CSV-Dateien und führen Sie eine Datenanalyse mit Pandas durch
Jan 09, 2024 am 09:26 AM
Pandas ist ein leistungsstarkes Datenanalysetool, das verschiedene Arten von Datendateien problemlos lesen und verarbeiten kann. Unter diesen sind CSV-Dateien eines der gebräuchlichsten und am häufigsten verwendeten Datendateiformate. In diesem Artikel wird erläutert, wie Sie mit Pandas CSV-Dateien lesen und Datenanalysen durchführen, und es werden spezifische Codebeispiele bereitgestellt. 1. Importieren Sie die erforderlichen Bibliotheken. Zuerst müssen wir die Pandas-Bibliothek und andere möglicherweise benötigte verwandte Bibliotheken importieren, wie unten gezeigt: importpandasaspd 2. Lesen Sie die CSV-Datei mit Pan
 Python-Pandas-Installationsmethode
Nov 22, 2023 pm 02:33 PM
Python-Pandas-Installationsmethode
Nov 22, 2023 pm 02:33 PM
Python kann Pandas mithilfe von Pip, Conda, aus dem Quellcode und mithilfe des in die IDE integrierten Paketverwaltungstools installieren. Detaillierte Einführung: 1. Verwenden Sie pip und führen Sie den Befehl „pip install pandas“ im Terminal oder in der Eingabeaufforderung aus, um Pandas zu installieren. 2. Verwenden Sie conda und führen Sie den Befehl „conda install pandas“ im Terminal oder in der Eingabeaufforderung aus, um Pandas zu installieren Installation und mehr.
 So installieren Sie Pandas in Python
Dec 04, 2023 pm 02:48 PM
So installieren Sie Pandas in Python
Dec 04, 2023 pm 02:48 PM
Schritte zum Installieren von Pandas in Python: 1. Öffnen Sie das Terminal oder die Eingabeaufforderung. 2. Geben Sie den Befehl „pip install pandas“ ein, um die Pandas-Bibliothek zu installieren. 3. Warten Sie, bis die Installation abgeschlossen ist. Anschließend können Sie die Pandas-Bibliothek importieren und verwenden im Python-Skript; 4. Stellen Sie sicher, dass Sie die entsprechende virtuelle Umgebung aktivieren, bevor Sie Pandas installieren. 5. Wenn Sie eine integrierte Entwicklungsumgebung verwenden, können Sie den Code „Pandas als PD importieren“ hinzufügen Importieren Sie die Pandas-Bibliothek.
 Praktische Tipps zum Lesen von TXT-Dateien mit Pandas
Jan 19, 2024 am 09:49 AM
Praktische Tipps zum Lesen von TXT-Dateien mit Pandas
Jan 19, 2024 am 09:49 AM
Praktische Tipps zum Lesen von TXT-Dateien mit Pandas. In der Datenanalyse und Datenverarbeitung sind TXT-Dateien ein gängiges Datenformat. Die Verwendung von Pandas zum Lesen von TXT-Dateien ermöglicht eine schnelle und bequeme Datenverarbeitung. In diesem Artikel werden verschiedene praktische Techniken vorgestellt, die Ihnen dabei helfen, Pandas besser zum Lesen von TXT-Dateien zu verwenden, sowie spezifische Codebeispiele. TXT-Dateien mit Trennzeichen lesen Wenn Sie Pandas zum Lesen von TXT-Dateien mit Trennzeichen verwenden, können Sie read_c verwenden
 Pandas liest problemlos Daten aus der SQL-Datenbank
Jan 09, 2024 pm 10:45 PM
Pandas liest problemlos Daten aus der SQL-Datenbank
Jan 09, 2024 pm 10:45 PM
Datenverarbeitungstool: Pandas liest Daten in SQL-Datenbanken und erfordert spezifische Codebeispiele. Da die Datenmenge weiter wächst und ihre Komplexität zunimmt, ist die Datenverarbeitung zu einem wichtigen Bestandteil der modernen Gesellschaft geworden. Im Datenverarbeitungsprozess ist Pandas für viele Datenanalysten und Wissenschaftler zu einem der bevorzugten Tools geworden. In diesem Artikel wird die Verwendung der Pandas-Bibliothek zum Lesen von Daten aus einer SQL-Datenbank vorgestellt und einige spezifische Codebeispiele bereitgestellt. Pandas ist ein leistungsstarkes Datenverarbeitungs- und Analysetool auf Basis von Python
 Vorstellung der effizienten Datendeduplizierungsmethode in Pandas: Tipps zum schnellen Entfernen doppelter Daten
Jan 24, 2024 am 08:12 AM
Vorstellung der effizienten Datendeduplizierungsmethode in Pandas: Tipps zum schnellen Entfernen doppelter Daten
Jan 24, 2024 am 08:12 AM
Das Geheimnis der Pandas-Deduplizierungsmethode: eine schnelle und effiziente Methode zur Datendeduplizierung, die spezifische Codebeispiele erfordert. Bei der Datenanalyse und -verarbeitung kommt es häufig zu Duplikaten in den Daten. Doppelte Daten können die Analyseergebnisse verfälschen, daher ist die Deduplizierung ein sehr wichtiger Schritt. Pandas, eine leistungsstarke Datenverarbeitungsbibliothek, bietet eine Vielzahl von Methoden zur Datendeduplizierung. In diesem Artikel werden einige häufig verwendete Deduplizierungsmethoden vorgestellt und spezifische Codebeispiele angehängt. Der häufigste Fall der Deduplizierung basierend auf einer einzelnen Spalte basiert darauf, ob der Wert einer bestimmten Spalte dupliziert wird.
