
 Backend-Entwicklung
Python-Tutorial
Python implementiert die Filterung und Filterung von XML-Daten
Backend-Entwicklung
Python-Tutorial
Python implementiert die Filterung und Filterung von XML-Daten
Python implementiert die Filterung und Filterung von XML-Daten


Python implementiert die XML-Datenfilterung und -Filterung.
XML (eXtensible Markup Language) ist eine Auszeichnungssprache zum Speichern und Übertragen von Daten. Sie ist flexibel und skalierbar und wird häufig zwischen verschiedenen Systemen verwendet. Bei der Verarbeitung von XML-Daten müssen wir diese häufig filtern und filtern, um die benötigten Informationen zu extrahieren. In diesem Artikel wird erläutert, wie Sie mit Python XML-Daten filtern und filtern.
- Importieren Sie die erforderlichen Module
Bevor wir beginnen, müssen wir die erforderlichen Module importieren. In Python können wir das Modul xml.etree.ElementTree verwenden, um XML-Daten zu verarbeiten.
import xml.etree.ElementTree as ET
- XML-Dateien analysieren
Um XML-Daten zu verarbeiten, müssen Sie zunächst die XML-Datei in eine Baumstruktur analysieren. Um dies zu erreichen, können wir die Parse-Funktion von ElementTree verwenden.
tree = ET.parse('data.xml') # 解析XML文件
root = tree.getroot() # 获取根节点Hier gehen wir davon aus, dass wir eine XML-Datei mit dem Namen „data.xml“ haben, verwenden die Parse-Funktion, um sie in eine Baumstruktur zu analysieren, und erhalten den Wurzelknoten über die Getroot-Funktion.
- Spezifizierte Tags filtern
Wenn wir uns nur um die Daten einiger bestimmter Tags kümmern, können wir die Tags, an denen wir interessiert sind, herausfiltern, indem wir den XML-Baum durchlaufen. Hier ist ein Beispiel, wir gehen davon aus, dass wir alle Tags mit dem Namen „item“ extrahieren möchten:
items = root.findall('item') # 过滤出所有名为"item"的标签
for item in items:
# 处理item标签的数据
passMit der Funktion „findall“ können Sie alle Tags mit dem Namen „item“ herausfiltern und in einer Liste speichern. Dann können wir die Liste durchlaufen und die Daten jedes Artikel-Tags verarbeiten.
- Spezifizierte Attribute filtern
Zusätzlich zum Filtern von Tags müssen wir manchmal auch bestimmte Daten basierend auf dem Wert des Attributs herausfiltern. Das Folgende ist ein Beispiel. Wir gehen davon aus, dass wir das „item“-Tag mit dem Attribut „type1“ extrahieren möchten:
items = root.findall('item[@type="type1"]') # 筛选出属性为"type1"的item标签
for item in items:
# 处理item标签的数据
passMit XPath-Ausdrücken in der Funktion „findall“ können bestimmte Tags basierend auf dem Wert des Attributs herausgefiltert werden. In diesem Beispiel verwenden wir [@type="type1"], um die Filterkriterien anzugeben.
- Erhalten Sie den Textinhalt des Etiketts
Wenn wir uns nur um den Textinhalt des Etiketts kümmern, können wir das Textattribut von Element verwenden, um ihn abzurufen. Hier ist ein Beispiel, wir gehen davon aus, dass wir den Textinhalt aller „item“-Tags extrahieren möchten:
items = root.findall('item') # 过滤出所有名为"item"的标签
for item in items:
text = item.text # 获取标签的文本内容
# 处理文本内容Durch Zugriff auf die Texteigenschaft von Element können wir den Textinhalt des Tags abrufen und verarbeiten.
Das Obige ist die grundlegende Methode zur Verwendung von Python zum Filtern und Filtern von XML-Daten. Durch das Parsen von XML-Dateien, das Filtern von Tags und Attributen und das Abrufen des Textinhalts von Tags können wir nach Bedarf spezifische Informationen aus XML-Daten extrahieren. Ich hoffe, dass dieser Artikel für Leser hilfreich sein kann, die Python zur Verarbeitung von XML-Daten verwenden.
Referenz:
- Offizielle Python-Dokumentation – xml.etree.ElementTree: https://docs.python.org/3/library/xml.etree.elementtree.html
Das obige ist der detaillierte Inhalt vonPython implementiert die Filterung und Filterung von XML-Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

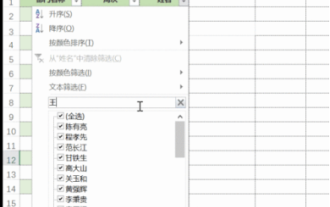 So filtern Sie in Excel mehr als 3 Schlüsselwörter gleichzeitig
Mar 21, 2024 pm 03:16 PM
So filtern Sie in Excel mehr als 3 Schlüsselwörter gleichzeitig
Mar 21, 2024 pm 03:16 PM
Excel wird im Büroalltag häufig zur Verarbeitung von Daten verwendet und es ist oft notwendig, die Funktion „Filter“ zu nutzen. Wenn wir uns für die „Filterung“ in Excel entscheiden, können wir nur bis zu zwei Bedingungen für dieselbe Spalte filtern. Wissen Sie also, wie man in Excel mehr als drei Schlüsselwörter gleichzeitig filtert? Lassen Sie mich es Ihnen als Nächstes demonstrieren. Die erste Methode besteht darin, die Bedingungen schrittweise zum Filter hinzuzufügen. Wenn Sie drei qualifizierende Details gleichzeitig herausfiltern möchten, müssen Sie zunächst eines davon Schritt für Schritt herausfiltern. Zu Beginn können Sie anhand der Konditionen zunächst Mitarbeiter mit dem Namen „Wang“ herausfiltern. Klicken Sie dann auf [OK] und aktivieren Sie dann in den Filterergebnissen die Option [Aktuelle Auswahl zum Filter hinzufügen]. Die Schritte sind wie folgt. Führen Sie die Filterung ebenfalls separat erneut durch
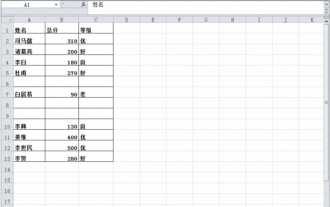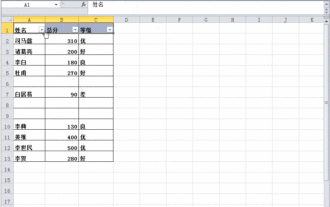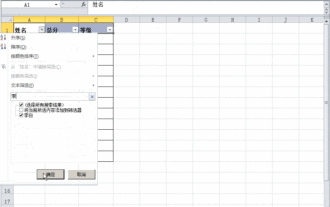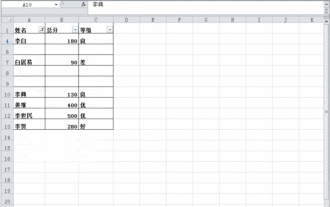 Was soll ich tun, wenn Daten in der Excel-Tabelle vorhanden sind, die Leerzeichen jedoch gefiltert werden?
Mar 13, 2024 pm 06:38 PM
Was soll ich tun, wenn Daten in der Excel-Tabelle vorhanden sind, die Leerzeichen jedoch gefiltert werden?
Mar 13, 2024 pm 06:38 PM
Excel ist eine häufig verwendete Office-Software, aber die Tabelle enthält eindeutig Daten und ist beim Filtern leer. Viele Benutzer wissen nicht, wie sie es lösen sollen. Der Inhalt dieses Software-Tutorials besteht darin, der Mehrheit der Benutzer Antworten zu geben. Benutzer mit Bedarf sind herzlich eingeladen, sich die Lösungen anzusehen. Was soll ich tun, wenn Daten in der Excel-Tabelle vorhanden sind, die Leerzeichen jedoch gefiltert werden? Der erste Grund ist, dass die Tabelle leere Zeilen enthält. Wir möchten jedoch alle Personen mit dem Nachnamen „Li“ filtern. Wir können jedoch feststellen, dass die richtigen Ergebnisse nicht herausgefiltert werden, da die Tabelle leere Zeilen enthält. Lösung: Schritt 1: Alle Inhalte auswählen und dann filtern
 So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
So verwenden Sie die Excel-Filterfunktion mit mehreren Bedingungen
Feb 26, 2024 am 10:19 AM
Wenn Sie wissen müssen, wie Sie die Filterung mit mehreren Kriterien in Excel verwenden, führt Sie das folgende Tutorial durch die Schritte, um sicherzustellen, dass Sie Ihre Daten effektiv filtern und sortieren können. Die Filterfunktion von Excel ist sehr leistungsstark und kann Ihnen dabei helfen, aus großen Datenmengen die benötigten Informationen zu extrahieren. Diese Funktion kann Daten entsprechend den von Ihnen festgelegten Bedingungen filtern und nur die Teile anzeigen, die die Bedingungen erfüllen, wodurch die Datenverwaltung effizienter wird. Mithilfe der Filterfunktion können Sie Zieldaten schnell finden und so Zeit beim Suchen und Organisieren von Daten sparen. Diese Funktion kann nicht nur auf einfache Datenlisten angewendet werden, sondern auch nach mehreren Bedingungen gefiltert werden, um Ihnen dabei zu helfen, die benötigten Informationen genauer zu finden. Insgesamt ist die Filterfunktion von Excel sehr praktisch
 XML-Daten mit Python filtern und sortieren
Aug 07, 2023 pm 04:17 PM
XML-Daten mit Python filtern und sortieren
Aug 07, 2023 pm 04:17 PM
Implementieren des Filterns und Sortierens von XML-Daten mit Python Einführung: XML ist ein häufig verwendetes Datenaustauschformat, das Daten in Form von Tags und Attributen speichert. Bei der Verarbeitung von XML-Daten müssen wir die Daten häufig filtern und sortieren. Python bietet viele nützliche Tools und Bibliotheken zum Verarbeiten von XML-Daten. In diesem Artikel wird erläutert, wie Sie mit Python XML-Daten filtern und sortieren. Lesen der XML-Datei Bevor wir beginnen, müssen wir die XML-Datei lesen. Python verfügt über viele XML-Verarbeitungsbibliotheken.
 So öffnen Sie gefilterte doppelte Dateien in Quark
Mar 01, 2024 am 11:25 AM
So öffnen Sie gefilterte doppelte Dateien in Quark
Mar 01, 2024 am 11:25 AM
Bei der Verwendung von Quark Browser gibt es eine Funktion zum Filtern doppelter Dateien. Hier finden Sie eine Einführung, wie Sie diese Funktion aktivieren können. 1. Klicken Sie zunächst auf Ihrem Mobiltelefon auf „Quark Browser“, um die Benutzeroberfläche aufzurufen. Klicken Sie dann zum Öffnen und Aufrufen auf „Quark Network Disk“ in den Optionen in der Mitte der Seite und wählen Sie diese aus. 2. Suchen Sie im unteren Teil der Quark-Netzwerkfestplattenoberfläche nach „Backup-Einstellungen“ und klicken Sie, um sie zu öffnen, wie in der Abbildung unten gezeigt: 3. Als nächstes gibt es auf der Seite, die Sie aufrufen, einen „Filter doppelter Dateien“. Dahinter befindet sich eine Schaltfläche zum Umschalten. Klicken Sie auf den kreisförmigen Schieberegler, um diese Funktion zu aktivieren. Wenn Sie mit dem Sichern von Dateien fortfahren, werden doppelte Dateien übersprungen, um Speicherplatz auf der Netzwerkfestplatte zu sparen.
 Verwendung von JavaScript zur Implementierung der Tabellenfilterfunktion
Aug 10, 2023 pm 09:51 PM
Verwendung von JavaScript zur Implementierung der Tabellenfilterfunktion
Aug 10, 2023 pm 09:51 PM
Verwendung von JavaScript zur Implementierung der Tabellenfilterfunktion Mit der kontinuierlichen Weiterentwicklung der Internettechnologie sind Tabellen zu einer gängigen Methode zur Anzeige von Daten auf Webseiten geworden. Bei großen Datenmengen haben Benutzer jedoch häufig Schwierigkeiten, bestimmte Daten zu finden. Daher ist das Hinzufügen von Filterfunktionen zu Tabellen, damit Benutzer die benötigten Daten schnell finden können, für viele Webdesigns zu einer Anforderung geworden. In diesem Artikel wird erläutert, wie Sie mit JavaScript die Tabellenfilterfunktion implementieren. Zuerst benötigen wir eine Datentabelle. Hier ist ein einfaches Beispiel: <t
 Python implementiert die Filterung und Filterung von XML-Daten
Aug 09, 2023 am 10:13 AM
Python implementiert die Filterung und Filterung von XML-Daten
Aug 09, 2023 am 10:13 AM
Python implementiert die XML-Datenfilterung und -Filterung. XML (eXtensibleMarkupLanguage) ist eine Auszeichnungssprache zum Speichern und Übertragen von Daten. Sie ist flexibel und skalierbar und wird häufig für den Datenaustausch zwischen verschiedenen Systemen verwendet. Bei der Verarbeitung von XML-Daten müssen wir diese häufig filtern und filtern, um die benötigten Informationen zu extrahieren. In diesem Artikel wird erläutert, wie Sie mit Python XML-Daten filtern und filtern. Importieren Sie die erforderlichen Module. Bevor Sie beginnen, wir
 Wie verwende ich PHP-Funktionen zum Suchen und Filtern von Daten?
Jul 24, 2023 am 08:01 AM
Wie verwende ich PHP-Funktionen zum Suchen und Filtern von Daten?
Jul 24, 2023 am 08:01 AM
Wie verwende ich PHP-Funktionen zum Suchen und Filtern von Daten? Bei der Entwicklung mit PHP ist es häufig erforderlich, Daten zu suchen und zu filtern. PHP bietet eine Fülle von Funktionen und Methoden, die uns bei der Durchführung dieser Vorgänge unterstützen. In diesem Artikel werden einige häufig verwendete PHP-Funktionen und -Techniken vorgestellt, die Ihnen beim effizienten Suchen und Filtern von Daten helfen. String-Suche Häufig verwendete String-Suchfunktionen in PHP sind strpos() und strstr(). strpos() wird verwendet, um die Position eines bestimmten Teilstrings in einem String zu finden. Wenn er existiert, wird er zurückgegeben
