

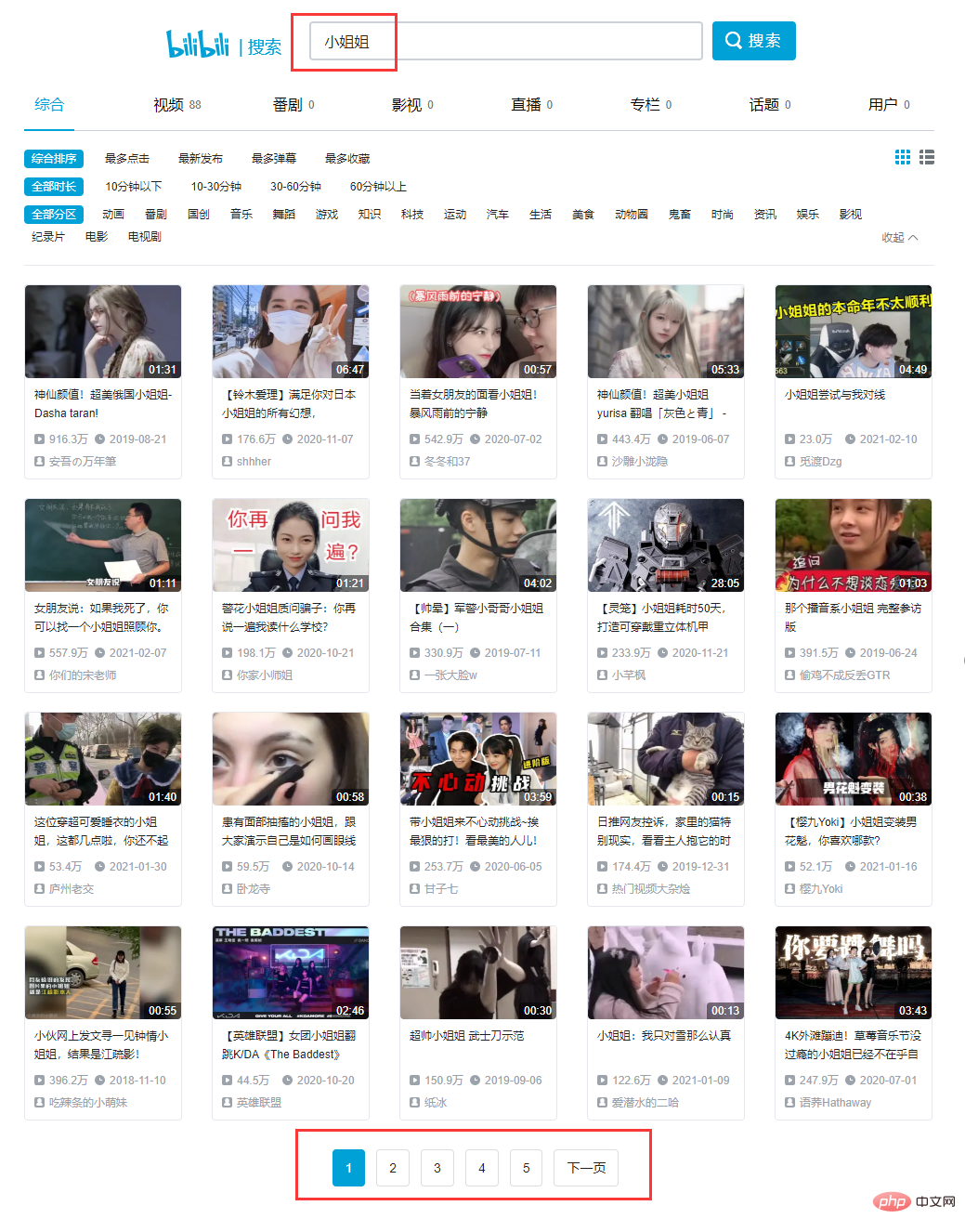
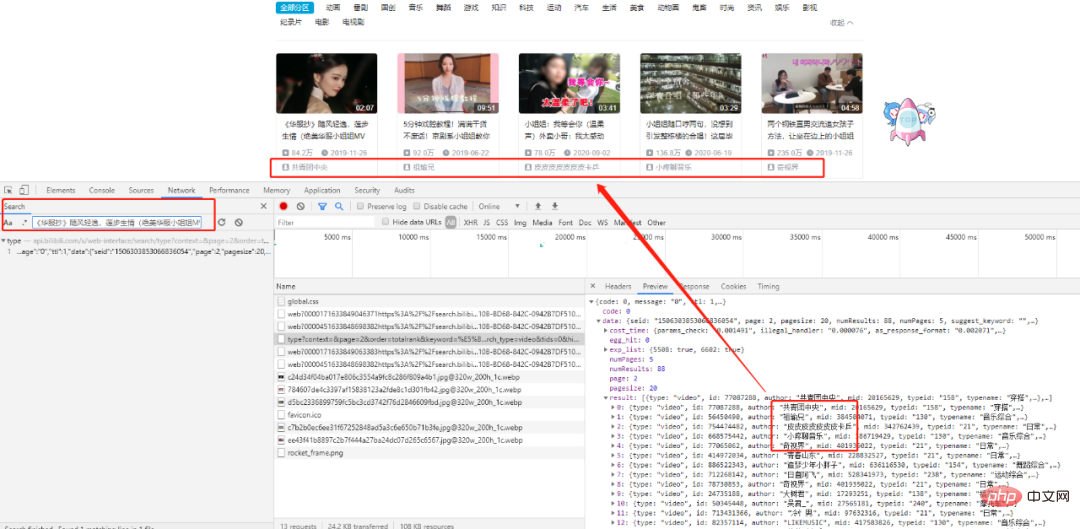
Suchen Sie nach dem ersten Titel. Nach sorgfältiger Analyse finden wir, dass alle Daten in einem Datensatz im JSON-Format vorliegen und unser Ziel in der Ergebnisliste ist.
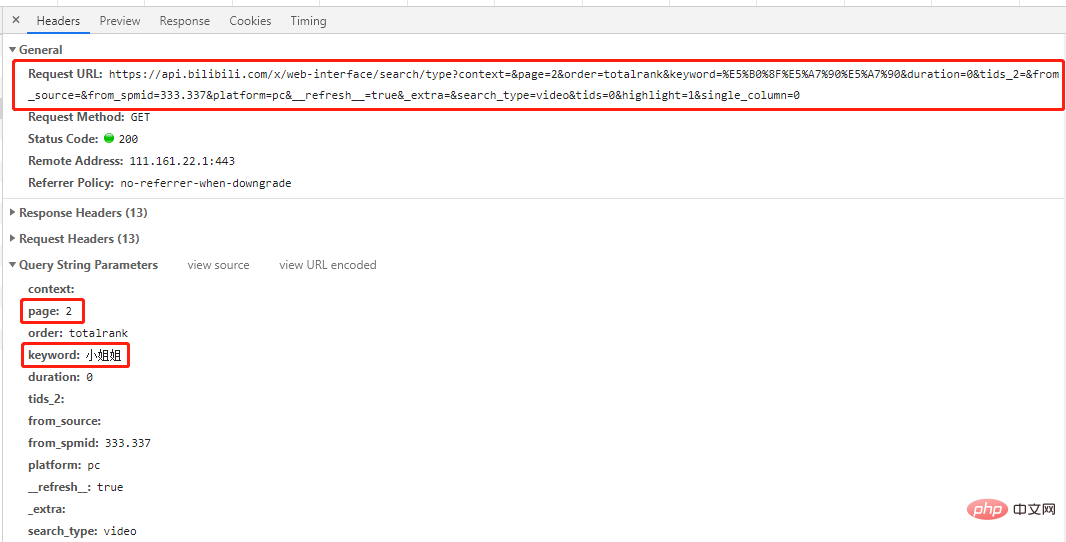
Dies ist eine Get-Anfrage, und die Anzahl der Einträge in der Anfrage beträgt. Seite und SchlüsselwortZwei Einträge entsprechen den angeforderten Seitenzahlen bzw. Schlüsselwörtern.
Schauen Sie sich noch ein paar Seiten an, um das Muster zu finden:
# 第一页 'https://api.bilibili.com/x/web-interface/search/all/v2?context=&page=1&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&tids=0&highlight=1&single_column=0' # 第二页 'https://api.bilibili.com/x/web-interface/search/type?context=&page=2&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0' # 第三页 'https://api.bilibili.com/x/web-interface/search/type?context=&page=3&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
Sie können sehen, dass mit Ausnahme von Seite 1 nur die Seitenparameter in den URLs anderer Seiten unterschiedlich sind gleich sein Sie können die gewünschten Ergebnisse erzielen (versuchen Sie es selbst).
Nur der Seitenparameter ist für alle Seiten-URLs unterschiedlich, die anderen sind gleich.
# 导包 import re import time import json import random import requests from fake_useragent import UserAgent
2.2 获取页面信息
# 获取页面信息
def get_datas(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = chardet.detect(r.content)['encoding']
datas = json.loads(r.text)
return datas# 获取图片链接信息
def get_hrefs(datas):
titles,hrefs = [],[]
for data in datas['data']['result']:
# 标题
title = data['title']
# 时长
duration = data['duration']
# 播放量
video_review =data['video_review']
# 发布时间
date_rls = data['pubdate']
pubdate = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 作者
author = data['author']
# 图片链接
link_pic = data['pic']
href_pic = 'https:' + link_pic
titles.append(title)
hrefs.append(href_pic)
return titles, hrefs代码解析了视频标题,时长,播放量,发布时间,作者,图片链接等参数,这里我们只取标题和图片链接,其他参数可根据需要自行增,删。
# 保存图片
def download_jpg(titles, hrefs):
path = "D:/B站小姐姐/"
if not os.path.exists(path):
os.mkdir(path)
for i in range(len(hrefs)):
title_t = titles[i].replace('/','').replace(',','').replace('?','')
title_t = title_t.replace(' ','').replace('|','').replace('。','')
filename = '{}{}.jpg'.format(path,title_t)
with open(filename, 'wb') as f:
req = requests.get(url=hrefs[i], headers=headers)
f.write(req.content)
time.sleep(random.uniform(1.5,3.4))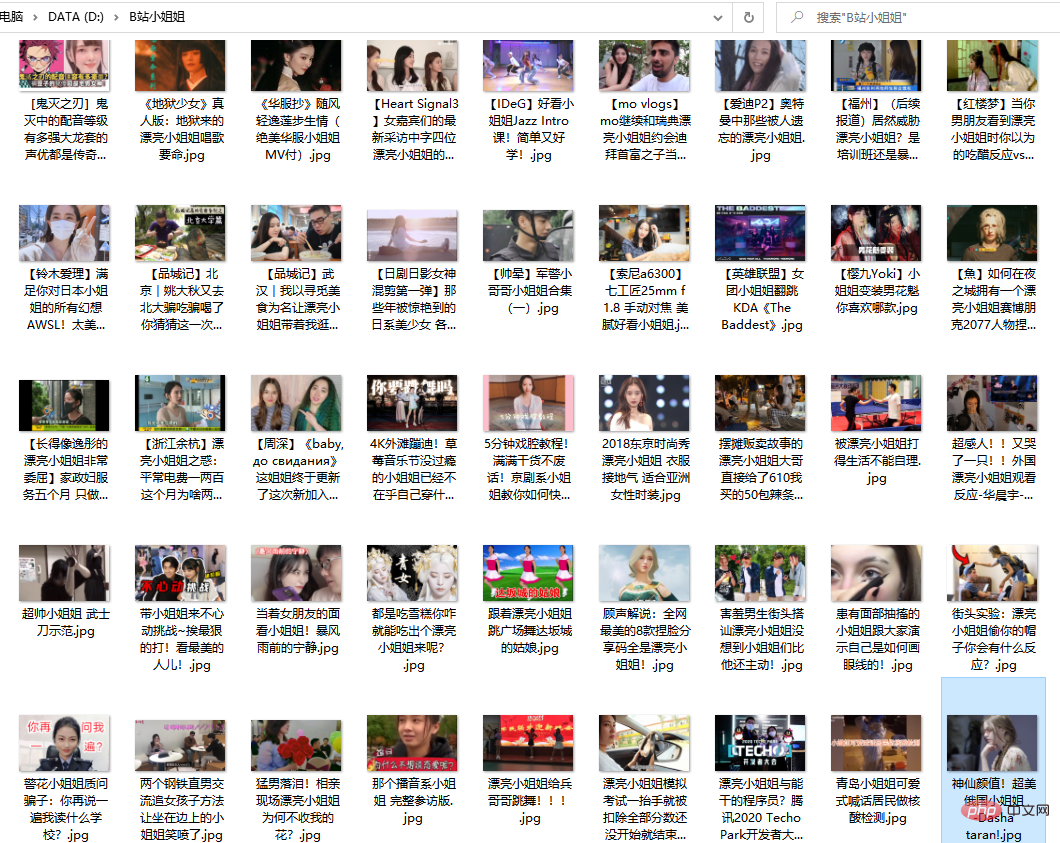
Das obige ist der detaillierte Inhalt vonCrawler|Python crawlt Bilder von Mädchen aus Station B, Motivation zum Lernen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



