

Der Herausgeber hat Folgendes verschlüsselt: aHR0cHM6Ly93d3cuc2hpeGlzZW5nLmNvbS8= Aus Sicherheitsgründen haben wir die URL mit Base64 kodiert, und Sie können die URL durch Base64-Dekodierung erhalten.
Font-Anti-Crawling: Eine gängige Anti-Crawling-Technologie, eine Anti-Crawling-Strategie, die durch die Kombination von Webseiten und Front-End-Schriftartendateien ergänzt wird -Crawling-Technologie sind 58.com und Autohome. Viele Mainstream-Websites oder APPs verwenden jetzt auch Font-Anti-Crawling-Technologie, um ihren Websites oder APPs eine Anti-Crawling-Maßnahme hinzuzufügen.
Font-Anti-Crawling-Prinzip: Ersetzen Sie bestimmte Daten auf der Seite durch benutzerdefinierte Schriftarten. Wenn wir nicht die richtige Dekodierungsmethode verwenden, können wir nicht den richtigen Dateninhalt erhalten.
Verwenden Sie benutzerdefinierte Schriftarten in HTML über @font-face, wie unten gezeigt:

Das Syntaxformat lautet:
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}Schriftartendateien sind im Allgemeinen vom Typ ttf, eot und woff weit verbreitet, sodass im Allgemeinen jeder auf Dateien vom Typ woff stößt.
Nehmen Sie die Datei vom Typ Woff als Beispiel. Was ist ihr Inhalt und welche Codierungsmethode wird verwendet, damit die Daten und der Code eins zu eins übereinstimmen?
Wir nehmen als Beispiel die Schriftartdatei einer Rekrutierungswebsite. Rufen Sie den Baidu-Schriftart-Compiler auf und öffnen Sie die Schriftartdatei, wie in der Abbildung unten gezeigt:

Öffnen Sie eine Schriftart nach dem Zufallsprinzip, wie in der Abbildung unten gezeigt:
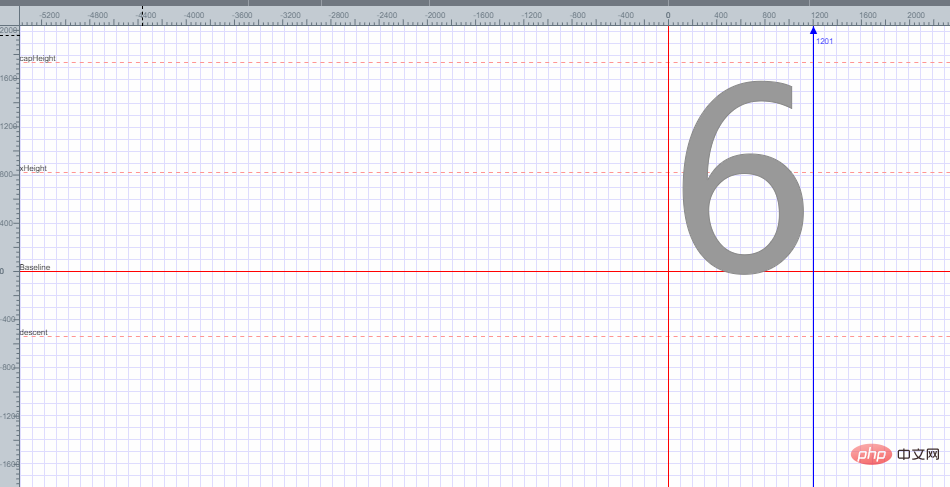
Sie können feststellen, dass Schriftart 6 in einer Ebenenkoordinate platziert ist und die Codierung von Schriftart 6 basierend auf jedem Punkt der Ebenenkoordinaten erhalten wird. Ich werde hier nicht erklären, wie die Codierung von Schriftart 6 erhalten wird.
Wie kann das Problem des Anti-Kletterns von Schriftarten gelöst werden?
Zunächst kann die Zuordnungsbeziehung als Wörterbuch betrachtet werden. Es gibt ungefähr zwei häufig verwendete Methoden:
Die erste: Extrahieren Sie manuell die entsprechende Beziehung zwischen einem Satz von Codes und Zeichen und zeigen Sie sie in Form eines an Wörterbuch. Der Code lautet wie folgt:
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])Definieren Sie zunächst ein Wörterbuch, das eins zu eins zwischen der Schriftart und dem entsprechenden Code entspricht, und ersetzen Sie dann die Daten einzeln durch eine for-Schleife.
Hinweis: Diese Methode eignet sich hauptsächlich für Daten mit wenigen Schriftartzuordnungen.
Zweite Methode: Laden Sie zuerst die Schriftartendatei der Website herunter, konvertieren Sie dann die Schriftartendatei in eine XML-Datei, suchen Sie den Code der darin enthaltenen Schriftartenzuordnungsbeziehung, dekodieren Sie ihn mit der Dekodierfunktion und kombinieren Sie dann den dekodierten Code in einem Wörterbuch , und dann entsprechend dem Wörterbuchinhalt Ersetzen Sie die Daten einzeln. Da der Code relativ lang ist, werde ich den Beispielcode hier nicht schreiben. Der Code für diese Methode wird später in der eigentlichen Kampfübung gezeigt.
Okay, lassen Sie uns kurz über das Anti-Crawling von Schriftarten sprechen. Als nächstes werden wir offiziell eine Rekrutierungswebsite crawlen.
Betreten Sie zunächst eine Rekrutierungswebsite und öffnen Sie den Entwicklermodus, wie im Bild unten gezeigt:
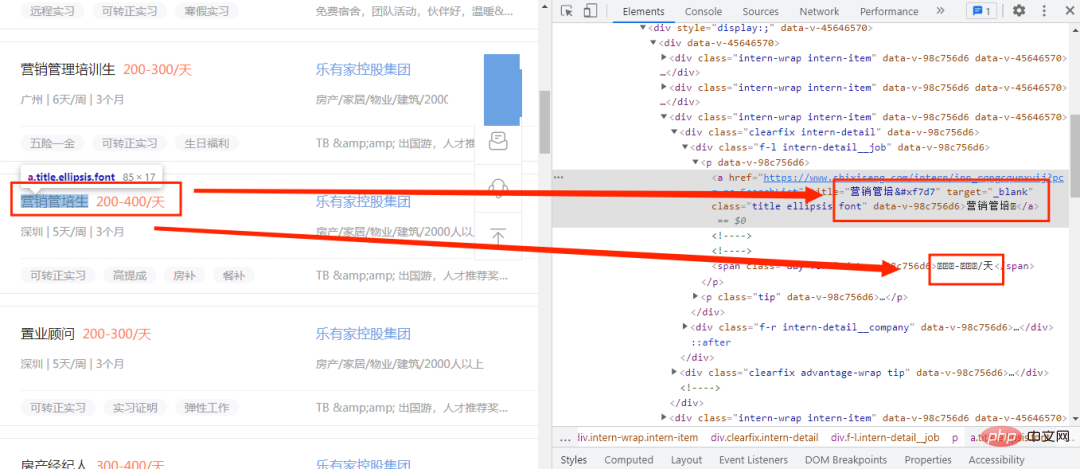
Hier sehen wir, dass nur die neuen Wörter im Code nicht normal funktionieren, sondern zunächst durch Codes ersetzt werden. Zu diesem Zeitpunkt müssen wir die Schriftartdatei finden Wo finde ich die Schriftartdatei? Öffnen Sie zunächst den Entwicklermodus und klicken Sie auf die Option „Netzwerk“, wie in der Abbildung unten gezeigt:
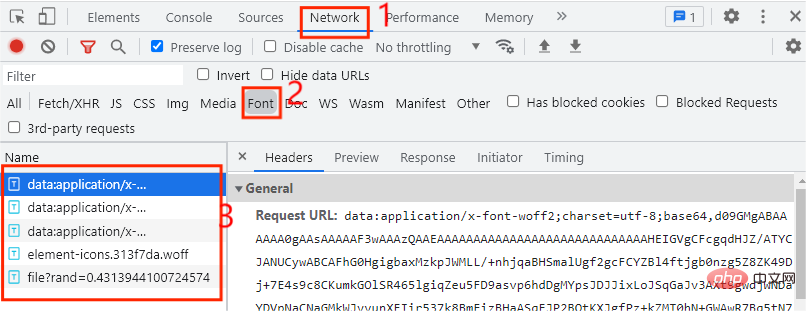
Im Allgemeinen werden Schriftartdateien auf der Registerkarte „Schriftarten“ abgelegt von 5 Einträgen hier, also welcher davon benutzerdefiniert ist Was die Einträge der Schriftartendatei betrifft, wird die benutzerdefinierte Schriftartendatei jedes Mal ausgeführt, wenn wir auf die nächste Seite klicken. Zu diesem Zeitpunkt müssen wir nur auf die nächste Seite klicken die Webseite, wie in der Abbildung unten gezeigt:
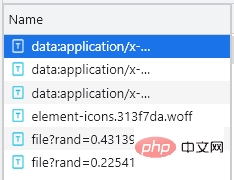
Sie können sehen, dass es einen zusätzlichen Eintrag gibt, der mit „file“ beginnt. Zu diesem Zeitpunkt können Sie zunächst feststellen, dass es sich bei der Datei um eine benutzerdefinierte Schriftartdatei handelt . Die Download-Methode ist sehr einfach. Sie müssen nur die URL des Eintrags kopieren, der mit der Datei beginnt, und sie nach dem Herunterladen im Baidu-Schriftart-Compiler öffnen
 Zu diesem Zeitpunkt stellte ich fest, dass die Datei nicht geöffnet werden konnte. Die Website meldete, dass dieser Dateityp nicht unterstützt wird, und versuche es Öffnen Sie es, wie im Bild unten gezeigt:
Zu diesem Zeitpunkt stellte ich fest, dass die Datei nicht geöffnet werden konnte. Die Website meldete, dass dieser Dateityp nicht unterstützt wird, und versuche es Öffnen Sie es, wie im Bild unten gezeigt:  Es wurde zu diesem Zeitpunkt erfolgreich geöffnet.
Es wurde zu diesem Zeitpunkt erfolgreich geöffnet. https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
font.saveXML('file.xml')首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
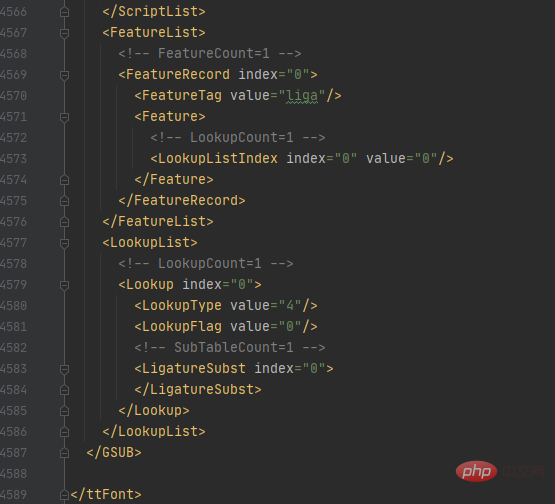
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
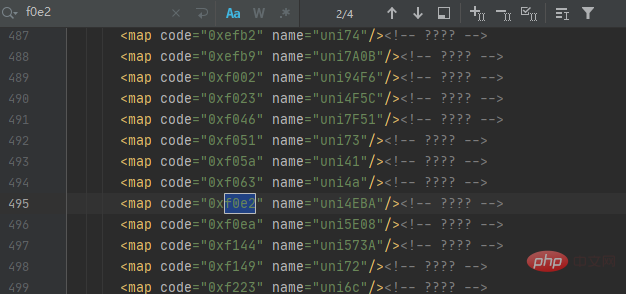
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
get_data(get_dict(),url)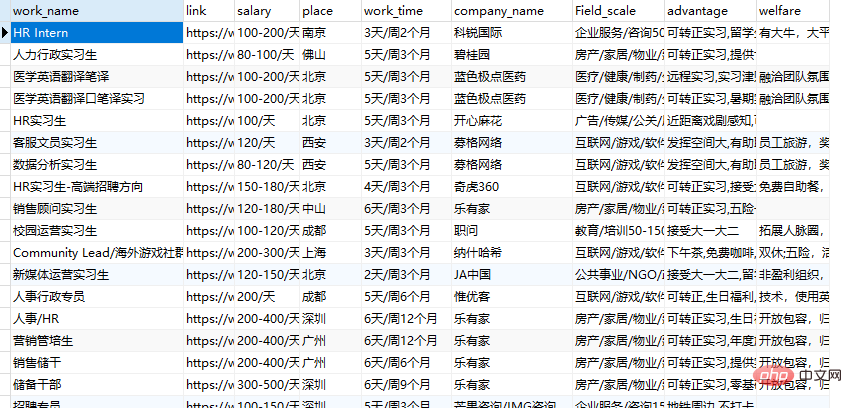
Das obige ist der detaillierte Inhalt vonBringen Sie Ihnen Schritt für Schritt bei, wie Sie JS zurückentwickeln, um das Crawlen von Schriftarten umzukehren und Informationen von einer Personalbeschaffungswebsite zu erhalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



