

In diesem Artikel wird eine PDF-basierte Python-Büroautomatisierungslösung vorgestellt, die ebenfalls eine echte Nachfrage einer Finanzdame darstellt. Werfen wir zunächst einen Blick auf die Nachfrage.
In einem bestimmten Ordner befinden sich mehrere Rechnungen vom Typ PDF
Jedes Rechnungs-PDF ist vom Typ Reines Bild. Die darin enthaltenen Textinformationen können nicht manuell kopiert werden (tatsächlich können Sie die meisten Rechnungen kopieren). Teil des Textes, aber wir werden es in Form von Bildern erklären), ungefähr wie in der folgenden Abbildung dargestellt: 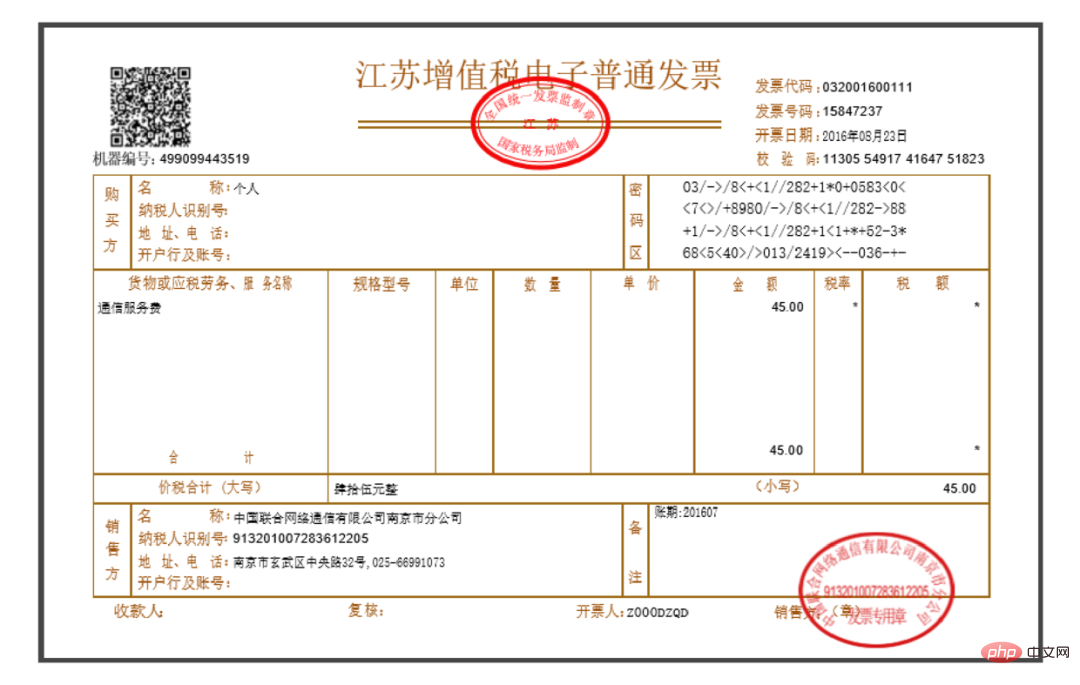
Die Anforderungen, die erfüllt werden müssen, sind: Erhalten Sie den Gesamtbetrag, die Steueridentifikationsnummer und den Emittenten , das heißt, die folgenden drei Kästchen Position: 
Abschließend mit Batch-Vorgängen kombiniert, nach Erhalt der oben genannten Informationen in Excel speichern! 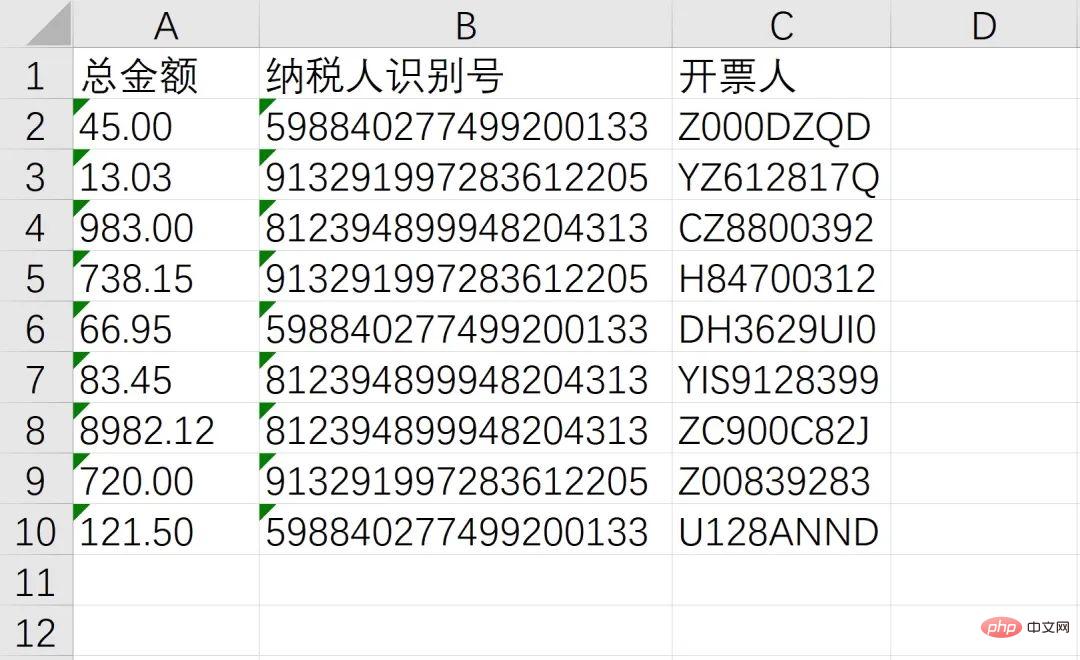
Die Anforderung ist im Wesentlichen ein Bilderkennungsproblem, da der Inhalt in PDF vom Bildtyp ist und der Text mit herkömmlichen Methoden nicht direkt extrahiert werden kann. Die Lösung besteht darin, mithilfe der optischen Zeichenerkennung (OCR) den Text im Bild zu erkennen. Gleichzeitig ist jedoch zu beachten, dass es sich bei PDF nicht um ein Bild handelt. Um die OCR abzuschließen, müssen Sie zusätzlich zur OCR selbst Folgendes herunterladen. Ghostscript 和 ImageMagick 用来完成类型转换。已 Windows Am Beispiel des Systems müssen Sie Folgendes installieren drei Software auf Ihrem Computer:
Ghostscript 32 位Ghostscript 32 位ImageMagick 32 位tesseract-OCR 32 位三个软件的下载安装没有特殊的地方(tesseract 配置稍复杂但网络有上诸多教程,这里不再赘述),读者可自行搜索下载及配置,下面讲解代码。首先导入需要的模块:
from wand.image import Image from PIL import Image as PI import pyocr import pyocr.builders import io import re import os import shutil
具体的模块用途可以参考下面具体代码。其中 wand 和 pyocr 由于是非标准库需要自行额外安装。打开命令行输入:
pip install wand pip install pyocr
本需求还涉及对接 Excel,可考虑利用 openpyxl 库的 Workbook 用以创建新的 Excel 文件:
from openpyxl import Workbook
需求中的 发票.pdf 放在桌面上。可通过下面基于 os 模块的代码获取桌面路径:
# 获取桌面路径包装成一个函数
def GetDesktopPath():
return os.path.join(os.path.expanduser("~"), 'Desktop')
path = GetDesktopPath() + r'\发票.pdf'获取配置好的 tesseract
ImageMagick 32位🎜🎜tool = pyocr.get_available_tools()[0]
Nach dem Login kopierenNach dem Login kopieren具体的模块用途可以参考下面具体代码。其中 wand und pyocr行输入:🎜
image_pdf = Image(filename=path, resolution=300) image_jpeg = image_pdf.convert('jpeg')
本需求还涉及对接 Excel,可考虑利用 openpyxl 库的 Workbook 用以创建新的 Excel 文件:🎜
image_lst = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
image_lst.append(img_page.make_blob('jpeg'))发票.pdf 放在桌面上。可通过下面基于 os 模块的代码获取桌面路径:🎜new_img = PI.open(io.BytesIO(image_lst[0])) new_img.show()
获取配置好的 tesseract 便于后面调用:🎜
tool = pyocr.get_available_tools()[0]
通过 wand 模块将 PDF 文件转化为分辨率为 300 的 jpeg 图片形式:
image_pdf = Image(filename=path, resolution=300) image_jpeg = image_pdf.convert('jpeg')
将图片解析为二进制矩阵:
image_lst = []
for img in image_jpeg.sequence:
img_page = Image(image=img)
image_lst.append(img_page.make_blob('jpeg'))用 io 模块的 BytesIO 方法读取二进制内容为图片形式:
new_img = PI.open(io.BytesIO(image_lst[0])) new_img.show()
接下来分别截取需要提取部位字符串的图片了,尽量让图片中只有需要识别的部分,获取识别出来容易简单处理获得需要的内容。
首先以总金额为例,截取图片用 image.crop((left, top, right, bottom)) 四个参数需要反复调试才能确定。经确定四个参数分别是 1600 760 1830 900,尝试截取和预览图片:
### 解析1Z开头码 left = 350 top = 600 right = 1300 bottom = 730 image_obj1 = new_img.crop((left, top, right, bottom)) image_obj1.show()
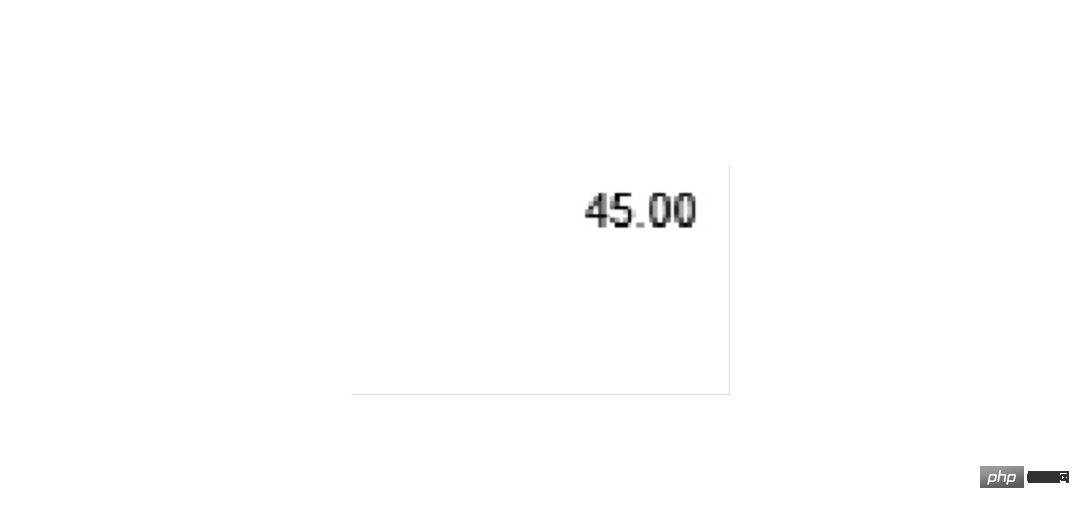
截取成功后可以交给 OCR 了,代码为 tool.image_to_string()
txt1= tool.image_to_string(image_obj1) print(txt1)

同样,通过方位的调试就可以准确切割到需要的部分进行识别:
left = 560 top = 1260 right = 900 bottom = 1320 image_obj2 = new_img.crop((left, top, right, bottom)) # image_obj2.show() txt2 = tool.image_to_string(image_obj2) # print(txt2)
最后是开票人的识别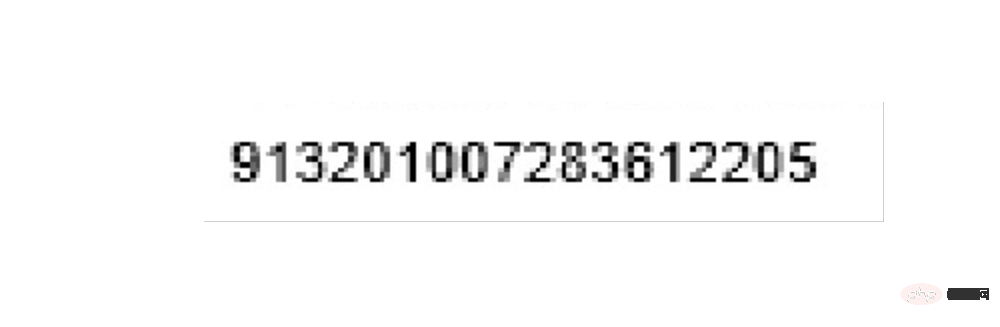
left = 1420 top = 1420 right = 1700 bottom = 1500 image_obj3 = new_img.crop((left, top, right, bottom)) # image_obj3.show() txt3 = tool.image_to_string(image_obj3) # print(txt3)
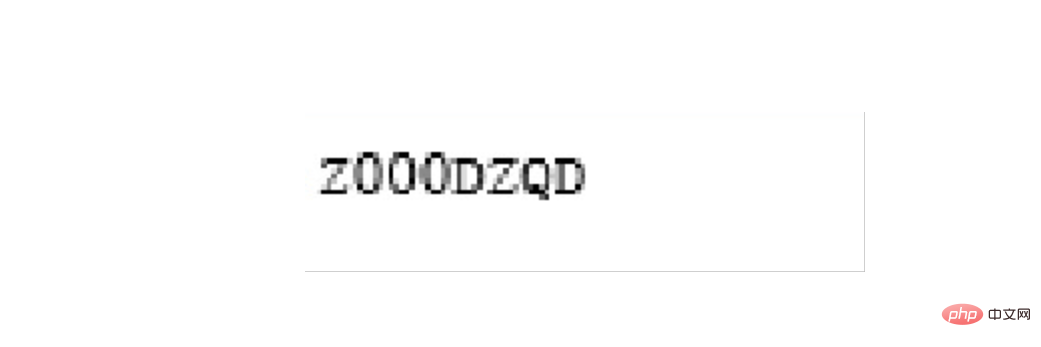
需要确认识别的内容是否正确,如果识别正确率欠佳可以考虑通过图片处理技术消除噪声,也可以去官网下载更高精度的训练包提高识别的正确性
至此,我们成功的识别了总金额、纳税人识别号、开票人三个消息,接下来就通过非常熟悉的 openpyxl 写入Excel,并使用 os 模块实现批量操作即可
workbook = Workbook() sheet = workbook.active header = ['总金额', '纳税人识别号', '开票人'] sheet.append(header) sheet.append([txt1, txt2, txt3]) workbook.save(GetDesktopPath() + r'\汇总.xlsx')
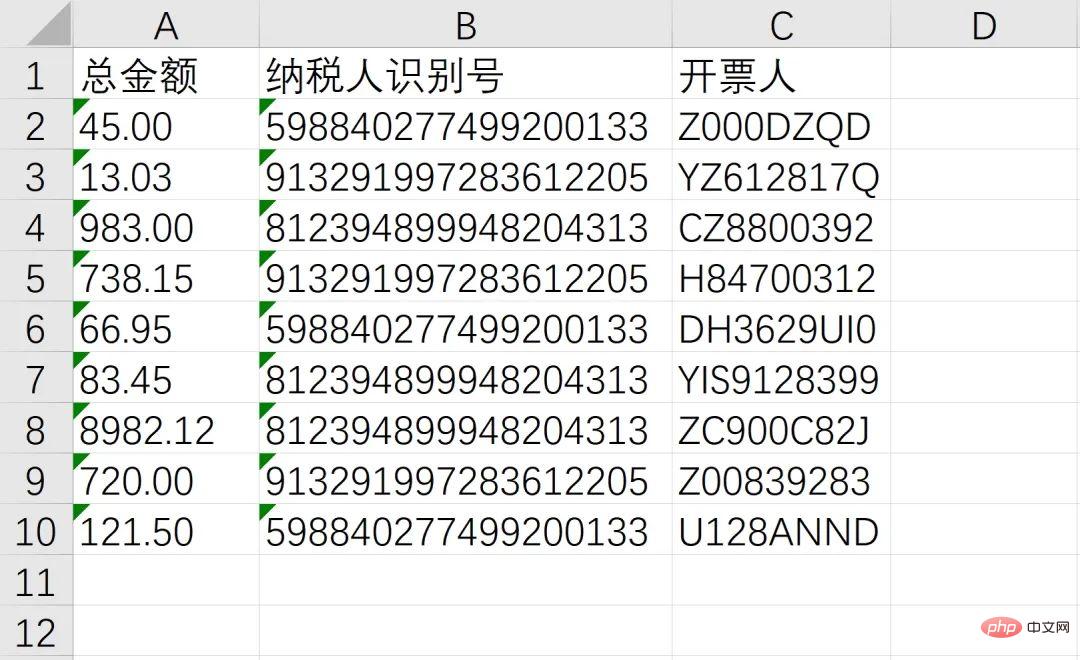
综上,整个需求就成功实现,从效果来看还是非常不错的!完整源码可由文中代码组合而成(已全部分享在文中),感兴趣的读者可以自己尝试!
最后想说的是,其实本文的案例可以衍生出很多实用的办公自动化脚本,例如
Das obige ist der detaillierte Inhalt vonTipps |. Python extrahiert und organisiert PDF-Rechnungen automatisch in Stapeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



