Heim >
Backend-Entwicklung >
Python-Tutorial >
Vergleich von vier häufig verwendeten Methoden zur Lokalisierung von Elementen für Python-Crawler. Welche bevorzugen Sie?
Vergleich von vier häufig verwendeten Methoden zur Lokalisierung von Elementen für Python-Crawler. Welche bevorzugen Sie?
Bei der Verwendung dieses Python-Crawlers zum Sammeln von Daten ist ein sehr wichtiger Vorgang das „Extrahieren von Daten aus der angeforderten Webseite“. Der erste Schritt besteht darin, die gewünschten Daten richtig zu lokalisieren. In diesem Artikel werden die
häufig verwendeten Methoden zum Auffinden von Webseitenelementen
in mehreren Python-Crawlern verglichen, damit jeder sie lernen kann
“
TraditionellBeautifulSoup operation
BeautifulSoup 操作
基于 BeautifulSoup 的 CSS 选择器(与 PyQuery 类似)
XPathbased on BeautifulSoups CSS-Selektor (mit PyQuery ähnlich)
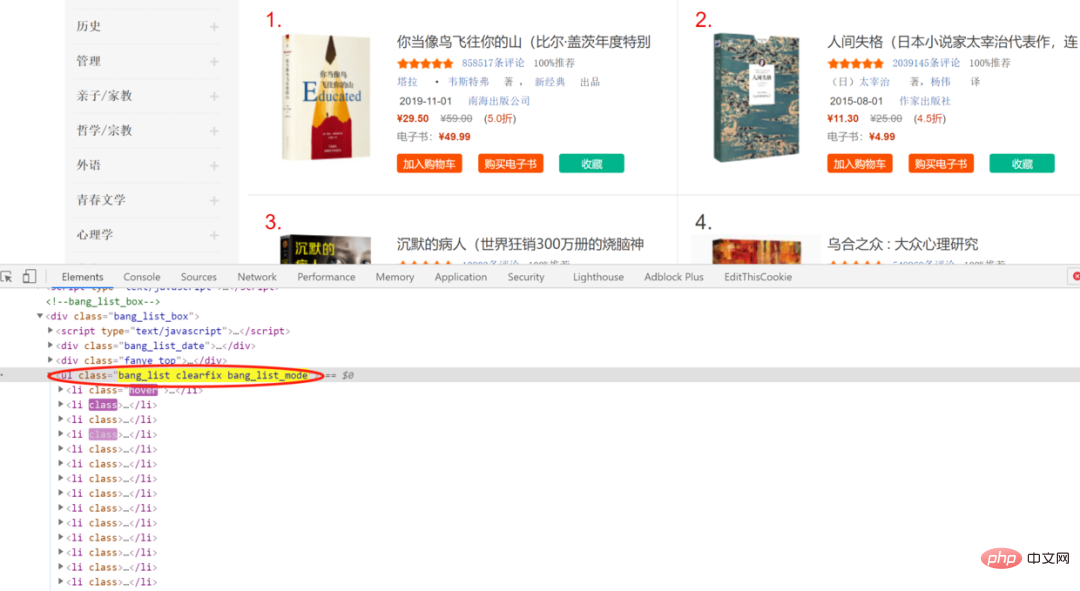
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1</pre><div class="contentsignin">Nach dem Login kopieren</div></div><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-1.jpg" class="lazy"/ alt="Vergleich von vier häufig verwendeten Methoden zur Lokalisierung von Elementen für Python-Crawler. Welche bevorzugen Sie?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%"> Nehmen wir als Beispiel den Titel der ersten 20 Bücher. Stellen Sie zunächst sicher, dass auf der Website keine Anti-Crawling-Maßnahmen eingerichtet sind und ob sie den zu analysierenden Inhalt direkt zurückgeben kann: </p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>import requests
url = &#39;http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1&#39;
response = requests.get(url).text
print(response)</pre><div class="contentsignin">Nach dem Login kopieren</div></div><figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/001/267/443/21d313e128464b6c1113677cb281678c-2.png" class="lazy"/ alt="Vergleich von vier häufig verwendeten Methoden zur Lokalisierung von Elementen für Python-Crawler. Welche bevorzugen Sie?" ></figure><p data-tool="mdnice编辑器" style="max-width:90%">Nach sorgfältiger Prüfung wird festgestellt, dass alle erforderlichen Daten in der Rückgabe enthalten sind Inhalt, was darauf hinweist, dass keine Anti-Crawling-Maßnahmen in Betracht gezogen werden müssen </p><p data-tool="mdnice编辑器" style="padding-top: 8px;padding-bottom: 8px;line-height: 26px;font-size: 16px;">Überprüfen Sie die Webseitenelemente. Später stellen Sie fest, dass die bibliografischen Informationen in <code style="padding: 2px 4px;border-radius: 4px;margin" enthalten sind -right: 2px;margin-left: 2px;background-color: rgba(27, 31, 35, 0.05 );font-family: „Operator Mono“, Consolas, Monaco, Menlo, monospace;word-break: break-all ;color: rgb(255, 100, 65);font-size: 13px;">li</code > in, untergeordnet zu <code style="padding: 2px 4px;border-radius: 4px;margin-right: 2px ;Rand links: 2 Pixel; Hintergrundfarbe: RGBA (27, 31, 35, 0,05); Schriftfamilie: „Operator Mono“, Consolas, Monaco, Menlo, Monospace; Wortumbruch: Break-All; Farbe: RGB (255, 100, 65);font-size: 13px;">class ist bang_list clearfix bang_list_mode'sul in li 中,从属于 class 为 bang_list clearfix bang_list_mode 的 ul 中
Eine weitere Prüfung kann ebenfalls erfolgen offenbaren die entsprechende Position des Buchtitels, die eine wichtige Grundlage für verschiedene Analysemethoden darstellt. >
1. Traditionelle BeautifulSoup-Operation
Die klassische BeautifulSoup-Methode verwendet aus bs4 importieren Sie BeautifulSoup und übergeben Sie dann soup = BeautifulSoup(html, "lxml") Konvertieren Sie Text in eine bestimmte Standardstruktur, indem Sie find Methodenreihe Analyse, der Code lautet wie folgt:
import requests
from bs4 import BeautifulSoup
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def bs_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 锁定ul后获取20个li
for li in li_list:
title = li.find('div', class_='name').find('a')['title'] # 逐个解析获取书名
print(title)
if __name__ == '__main__':
bs_for_parse(response)
Nach dem Login kopieren
🎜🎜 20 Buchtitel erfolgreich erhalten. Einige davon sind lang und können über reguläre Ausdrücke oder andere Zeichenfolgenmethoden verarbeitet werden. In diesem Artikel werden sie nicht im Detail vorgestellt
import requests
from bs4 import BeautifulSoup
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def css_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')
for li in li_list:
title = li.select('div.name > a')[0]['title']
print(title)
if __name__ == '__main__':
css_for_parse(response)
Nach dem Login kopieren
3. XPath
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装 XPath Helper 插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests
from lxml import html
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def xpath_for_parse(response):
selector = html.fromstring(response)
books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for book in books:
title = book.xpath('div[@class="name"]/a/@title')[0]
print(title)
if __name__ == '__main__':
xpath_for_parse(response)
Nach dem Login kopieren
4. 正则表达式
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是 re
import requests
from bs4 import BeautifulSoup
from lxml import html
import re
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1'
response = requests.get(url).text
def bs_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li')
for li in li_list:
title = li.find('div', class_='name').find('a')['title']
print(title)
def css_for_parse(response):
soup = BeautifulSoup(response, "lxml")
li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li')
for li in li_list:
title = li.select('div.name > a')[0]['title']
print(title)
def xpath_for_parse(response):
selector = html.fromstring(response)
books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for book in books:
title = book.xpath('div[@class="name"]/a/@title')[0]
print(title)
def re_for_parse(response):
reg = '<div class="name"><a href="http://product.dangdang.com/\d+.html" target="_blank" title="(.*?)">'
for title in re.findall(reg, response):
print(title)
if __name__ == '__main__':
# bs_for_parse(response)
# css_for_parse(response)
# xpath_for_parse(response)
re_for_parse(response)
Nach dem Login kopieren
Das obige ist der detaillierte Inhalt vonVergleich von vier häufig verwendeten Methoden zur Lokalisierung von Elementen für Python-Crawler. Welche bevorzugen Sie?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn


Die klassische BeautifulSoup-Methode verwendet







 Die klassische BeautifulSoup-Methode verwendet
Die klassische BeautifulSoup-Methode verwendet 
 观察几个数目相信就有答案了:
观察几个数目相信就有答案了:









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



