

Spring Boot+MyBatis+Atomikos+MySQL (mit Quellcode)
In tatsächlichen Projekten versuchen wir, verteilte Transaktionen zu vermeiden. Allerdings ist es manchmal wirklich notwendig, einige Dienste aufzuteilen, was zu Problemen bei verteilten Transaktionen führt.
Gleichzeitig sind verteilte Transaktionen auch eine Marktfrage in Vorstellungsgesprächen. Sie können mit diesem Fall üben und im Vorstellungsgespräch 123 sprechen.
Hier ist eine geschäftliche Kastanie: Wenn ein Benutzer einen Coupon erhält, muss die Häufigkeit, mit der der Benutzer den Coupon erhält, abgezogen werden, und dann wird eine Aufzeichnung darüber aufgezeichnet, wie oft der Benutzer den Coupon erhält.
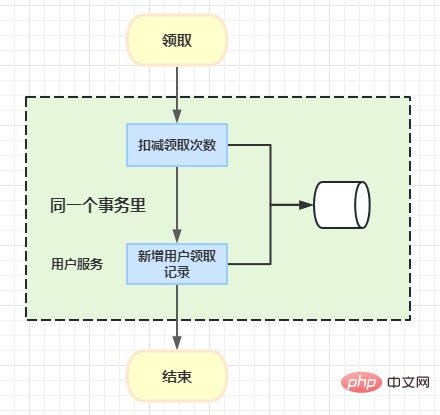
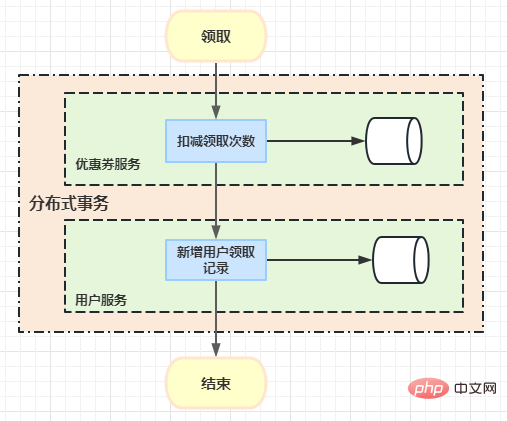
Ursprünglich können Sie hier die Nachrichtenwarteschlangenmethode verwenden und asynchron verwenden, um Benutzersammlungsdatensätze hinzuzufügen. Allerdings besteht hier die Anforderung, dass Benutzer ihre Sammlungsdatensätze unmittelbar nach Erhalt einsehen können müssen. Deshalb haben wir hier Atomikos eingeführt, um verteilte Transaktionsprobleme zu implementieren.
Verteilte Transaktionen
Verteilte Transaktionen sind Transaktionen, die sich über mehrere Computer oder Datenbanken erstrecken, und es kann zu Netzwerkverzögerungen, Ausfällen oder Inkonsistenzen zwischen diesen Computern oder Datenbanken kommen. Verteilte Transaktionen müssen die Atomizität, Konsistenz, Isolation und Dauerhaftigkeit aller Vorgänge sicherstellen, um die Richtigkeit und Integrität der Daten sicherzustellen.
Was sind die verteilten Transaktionsprotokolle?
Es gibt zwei Haupttypen verteilter Transaktionsprotokolle: 2PC (Two-Phase Commit) und 3PC (Three-Phase Commit).
2PC ist derzeit das am häufigsten verwendete verteilte Transaktionsprotokoll und sein Prozess ist in zwei Phasen unterteilt: die Vorbereitungsphase und die Übermittlungsphase. In der Vorbereitungsphase gibt der Transaktionskoordinator eine Vorbereitungsanforderung an alle Teilnehmer aus, und die Teilnehmer führen die lokale Transaktion in den Vorbereitungszustand aus und geben die Vorbereitungsergebnisse an den Transaktionskoordinator zurück. Wenn in der Festschreibungsphase alle Teilnehmer erfolgreich ausgeführt werden, sendet der Transaktionskoordinator eine Festschreibungsanforderung an alle Teilnehmer und die Teilnehmer schreiben die lokale Transaktion fest. Andernfalls sendet der Transaktionskoordinator eine Rollback-Anfrage an alle Teilnehmer und die Teilnehmer führen ein Rollback der lokalen Transaktion durch Transaktionsrolle.
3PC ist eine verbesserte Version von 2PC, die eine auf 2PC basierende Vorbereitungs- und Einreichungsphase hinzufügt. In der Vorbereitungsphase für die Übermittlung fragt der Koordinator die Teilnehmer, ob sie ihre Einwilligung erteilen können. Wenn der Teilnehmer seine Einwilligung zurückgibt, wird er direkt in der Übermittlungsphase übermittelt, andernfalls wird er in der Übermittlungsphase zurückgesetzt.
Was sind die gängigen Lösungen für verteilte Transaktionen?
Zu den Implementierungslösungen für verteilte Transaktionslösungen gehören:
Verteilte Transaktionslösungen basierend auf Nachrichtenwarteschlangen (wie die Open-Source-Lösung von RocketMQ) Verteilte Transaktionslösungen basierend auf verteilten Transaktions-Frameworks (wie Seata, TCC-Transaction und andere Frameworks) Verteilte Transaktionslösungen basierend auf dem XA-Protokoll (wie JTA usw.) -
Verteilte Transaktionslösungen basierend auf zuverlässiger Nachrichtenkonsistenz (wie Alibabas verteilte Transaktions-Middleware GTS) Verteilt Transaktionslösung basierend auf dem CAP-Prinzip (z. B. Event-Sourcing-Modus in der CQRS-Architektur)
Was ist JTA?
JTA (Java Transaction API) ist die Programmierschnittstellenspezifikation von J2EE. Es handelt sich um die JAVA-Implementierung des XA-Protokolls. Es definiert hauptsächlich:
Eine Transaktionsmanagerschnittstellejavax.transaction.TransactionManager,定义了有关事务的开始、提交、撤回等>操作。
一个满足XA规范的资源定义接口javax.transaction.xa.XAResource,一种资源如果要支持JTA事务,就需要让它的资源实现该XAResource
XAResource-Schnittstelle und implementieren Sie die von dieser Schnittstelle definierte zweiphasige Übermittlungsschnittstelle.
Wenn wir eine Anwendung haben, die die JTA-Schnittstelle zum Implementieren von Transaktionen verwendet, benötigt sie beim Ausführen einen Container, der JTA implementiert. Im Allgemeinen ist dies ein J2EE-Container, wie z. B. JBoss, Websphere und andere Anwendungsserver. Es gibt jedoch auch einige unabhängige Frameworks, die JTA implementieren. Beispielsweise stellen Atomikos und Bitronix alle JTA-Implementierungsframeworks in Form von JAR-Paketen bereit. Auf diese Weise können wir Anwendungssysteme ausführen, die JTA verwenden, um Transaktionen auf Servern wie Tomcat oder Jetty zu implementieren. 🎜Wie oben im Unterschied zwischen lokalen Transaktionen und externen Transaktionen erwähnt, sind JTA-Transaktionen externe Transaktionen und können zur Implementierung von Transaktionalität für mehrere Ressourcen verwendet werden. Genau das macht es mit jeder Ressource XAResource来进行两阶段提交的控制。感兴趣的同学可以看看这个接口的方法,除了commit, rollback等方法以外,还有end(), forget(), isSameRM(), prepare() und noch mehr. Allein anhand dieser Schnittstellen können Sie sich die Komplexität von JTA bei der Implementierung zweiphasiger Transaktionen vorstellen.
Was ist XA?
XA ist eine verteilte Transaktionsarchitektur (oder ein Protokoll), die von der X/Open-Organisation vorgeschlagen wird. Die XA-Architektur definiert hauptsächlich die Schnittstelle zwischen dem (globalen) Transaktionsmanager und dem (lokalen) Ressourcenmanager. Die XA-Schnittstelle ist eine bidirektionale Systemschnittstelle, die eine Kommunikationsbrücke zwischen dem Transaktionsmanager und einem oder mehreren Ressourcenmanagern bildet. Mit anderen Worten: Bei einer auf XA basierenden Transaktion können wir die Transaktionsverwaltung für mehrere Ressourcen durchführen. Beispielsweise greift ein System auf mehrere Datenbanken zu oder greift sowohl auf Datenbanken als auch auf Ressourcen wie Nachrichten-Middleware zu. Auf diese Weise können wir alle übermittelten oder alle abgebrochenen Transaktionen direkt in mehreren Datenbanken und Nachrichten-Middleware implementieren. Die XA-Spezifikation ist keine Java-Spezifikation, sondern eine universelle Spezifikation. Derzeit unterstützen verschiedene Datenbanken und viele Nachrichten-Middleware die XA-Spezifikation.
JTA ist eine Spezifikation für die Java-Entwicklung, die der XA-Spezifikation entspricht. Wenn wir also sagen, dass wir JTA verwenden, um verteilte Transaktionen zu implementieren, meinen wir eigentlich, JTA-Spezifikationen zu verwenden, um Transaktionen mit mehreren Datenbanken, Nachrichten-Middleware und anderen Ressourcen im System zu implementieren.
Was ist Atomikos?
Atomikos ist ein sehr beliebter Open-Source-Transaktionsmanager und kann in Ihre Spring Boot-Anwendung eingebettet werden. Der Tomcat-Anwendungsserver implementiert die JTA-Spezifikation nicht. Wenn Sie Tomcat als Anwendungsserver verwenden, müssen Sie eine Transaktionsmanagerklasse eines Drittanbieters als globalen Transaktionsmanager verwenden. Dies übernimmt das Atomikos-Framework und integriert die Transaktionsverwaltung in die Anwendung. Hängt nicht vom Anwendungsserver ab.
Spring Boot integriert Atomikos
Es ist sinnlos, über eine Reihe von Theorien zu sprechen. Zeigen Sie mir den Code.
Technologie-Stack: Spring Boot+MyBatis+Atomikos+MySQL
Wenn Sie dem Code in diesem Artikel folgen, achten Sie auf Ihre MySQL-Version.
Erstellen Sie zunächst zwei Datenbanken (my-db_0 und my-db_1) und erstellen Sie dann in jeder Datenbank eine Tabelle.
In Datenbank my-db_0:
CREATE TABLE `t_user_0` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `age` int NOT NULL, `gender` int NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8;
In Datenbank my-db_1:
CREATE TABLE `t_user_1` ( `id` bigint NOT NULL AUTO_INCREMENT, `user_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `age` int NOT NULL, `gender` int NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
Dies dient nur zur Demonstration verteilter Transaktionen. Machen Sie sich keine Gedanken über die spezifische Bedeutung der Tabelle. Gesamtprojektstruktur
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tian</groupId>
<artifactId>spring-boot-atomikos</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<name>spring-boot-atomikos</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- mybatis依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!--分布式事务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 要使生成的jar可运行,需要加入此插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/java</directory>
<excludes>
<exclude>**/*.java</exclude>
</excludes>
</resource>
<resource>
<!-- 编译xml文件 -->
<directory>src/main/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
</resource>
</resources>
</build>
</project>Nach dem Login kopieren
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tian</groupId>
<artifactId>spring-boot-atomikos</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.0.RELEASE</version>
</parent>
<name>spring-boot-atomikos</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- mybatis依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!--分布式事务-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 要使生成的jar可运行,需要加入此插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/java</directory>
<excludes>
<exclude>**/*.java</exclude>
</excludes>
</resource>
<resource>
<!-- 编译xml文件 -->
<directory>src/main/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
</resource>
</resources>
</build>
</project>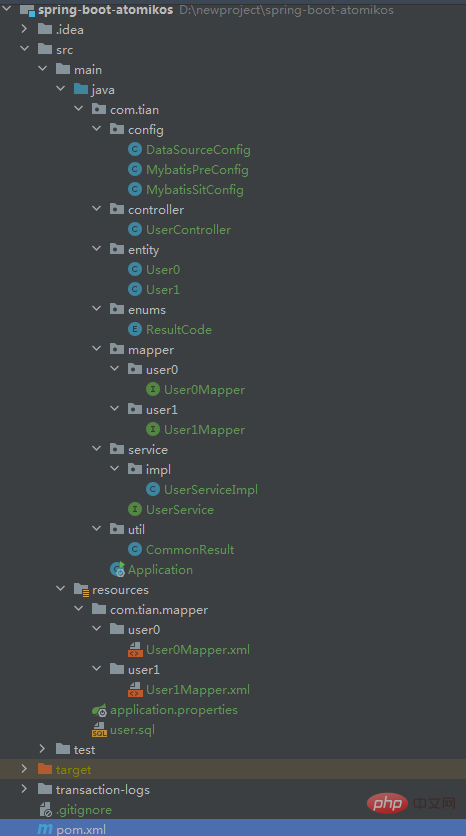 MyBatis Scan
MyBatis Scan server.port=9001 spring.application.name=atomikos-demo spring.datasource.user0.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.user0.url=jdbc:mysql://localhost:3306/my-db_0?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true spring.datasource.user0.user=root spring.datasource.user0.password=123456 spring.datasource.user1.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.user1.url=jdbc:mysql://localhost:3306/my-db_1?characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true spring.datasource.user1.user=root spring.datasource.user1.password=123456 mybatis.mapperLocations=classpath:/com/tian/mapper/*/*.xml mybatis.typeAliasesPackage=com.tian.entity mybatis.configuration.cache-enabled=true
Der andere ist im Grunde derselbe, das heißt, der Scanpfad wurde geändert in: mapper.xml
Der andere ist im Grunde derselbe und wird hier veröffentlicht. Die entsprechende Mapper-Schnittstelle ist ebenfalls sehr einfach. Hier ist eine:
("classpath*:com/tian/mapper/user1/*.xml")Service
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tian.mapper.user0.User0Mapper">
<!-- -->
<cache eviction="LRU" flushInterval="10000" size="1024" />
<resultMap id="BaseResultMap" type="com.tian.entity.User0">
<id column="id" jdbcType="BIGINT" property="id" />
<result column="user_name" jdbcType="VARCHAR" property="userName" />
<result column="age" jdbcType="INTEGER" property="age" />
<result column="gender" jdbcType="INTEGER" property="gender" />
</resultMap>
<sql id="Base_Column_List">
id, user_name, age, gender
</sql>
<insert id="insert" parameterType="com.tian.entity.User0">
insert into t_user_0 (id, user_name,age, gender)
values (#{id,jdbcType=BIGINT}, #{userName,jdbcType=VARCHAR},#{age,jdbcType=INTEGER},#{gender,jdbcType=INTEGER})
</insert>
</mapper>Controller
public interface User0Mapper {
int insert(User0 record);
}Projektstartklasse
Das obige ist der detaillierte Inhalt vonSpring Boot+MyBatis+Atomikos+MySQL (mit Quellcode). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
Fähigkeiten zur Verarbeitung von Big-Data-Strukturen: Chunking: Teilen Sie den Datensatz auf und verarbeiten Sie ihn in Blöcken, um den Speicherverbrauch zu reduzieren. Generator: Generieren Sie Datenelemente einzeln, ohne den gesamten Datensatz zu laden, geeignet für unbegrenzte Datensätze. Streaming: Lesen Sie Dateien oder fragen Sie Ergebnisse Zeile für Zeile ab, geeignet für große Dateien oder Remote-Daten. Externer Speicher: Speichern Sie die Daten bei sehr großen Datensätzen in einer Datenbank oder NoSQL.
 Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Die MySQL-Abfrageleistung kann durch die Erstellung von Indizes optimiert werden, die die Suchzeit von linearer Komplexität auf logarithmische Komplexität reduzieren. Verwenden Sie PreparedStatements, um SQL-Injection zu verhindern und die Abfrageleistung zu verbessern. Begrenzen Sie die Abfrageergebnisse und reduzieren Sie die vom Server verarbeitete Datenmenge. Optimieren Sie Join-Abfragen, einschließlich der Verwendung geeigneter Join-Typen, der Erstellung von Indizes und der Berücksichtigung der Verwendung von Unterabfragen. Analysieren Sie Abfragen, um Engpässe zu identifizieren. Verwenden Sie Caching, um die Datenbanklast zu reduzieren. Optimieren Sie den PHP-Code, um den Overhead zu minimieren.
 Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Das Sichern und Wiederherstellen einer MySQL-Datenbank in PHP kann durch Befolgen dieser Schritte erreicht werden: Sichern Sie die Datenbank: Verwenden Sie den Befehl mysqldump, um die Datenbank in eine SQL-Datei zu sichern. Datenbank wiederherstellen: Verwenden Sie den Befehl mysql, um die Datenbank aus SQL-Dateien wiederherzustellen.
 Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich Daten in eine MySQL-Tabelle ein? Mit der Datenbank verbinden: Stellen Sie mit mysqli eine Verbindung zur Datenbank her. Bereiten Sie die SQL-Abfrage vor: Schreiben Sie eine INSERT-Anweisung, um die einzufügenden Spalten und Werte anzugeben. Abfrage ausführen: Verwenden Sie die Methode query(), um die Einfügungsabfrage auszuführen. Bei Erfolg wird eine Bestätigungsmeldung ausgegeben.
 Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
So verwenden Sie gespeicherte MySQL-Prozeduren in PHP: Verwenden Sie PDO oder die MySQLi-Erweiterung, um eine Verbindung zu einer MySQL-Datenbank herzustellen. Bereiten Sie die Anweisung zum Aufrufen der gespeicherten Prozedur vor. Führen Sie die gespeicherte Prozedur aus. Verarbeiten Sie die Ergebnismenge (wenn die gespeicherte Prozedur Ergebnisse zurückgibt). Schließen Sie die Datenbankverbindung.
 So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
Eine der wichtigsten Änderungen, die in MySQL 8.4 (der neuesten LTS-Version von 2024) eingeführt wurden, besteht darin, dass das Plugin „MySQL Native Password“ nicht mehr standardmäßig aktiviert ist. Darüber hinaus entfernt MySQL 9.0 dieses Plugin vollständig. Diese Änderung betrifft PHP und andere Apps
 Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Das Erstellen einer MySQL-Tabelle mit PHP erfordert die folgenden Schritte: Stellen Sie eine Verbindung zur Datenbank her. Erstellen Sie die Datenbank, falls sie nicht vorhanden ist. Wählen Sie eine Datenbank aus. Tabelle erstellen. Führen Sie die Abfrage aus. Schließen Sie die Verbindung.
 Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Oracle-Datenbank und MySQL sind beide Datenbanken, die auf dem relationalen Modell basieren, aber Oracle ist in Bezug auf Kompatibilität, Skalierbarkeit, Datentypen und Sicherheit überlegen, während MySQL auf Geschwindigkeit und Flexibilität setzt und eher für kleine bis mittlere Datensätze geeignet ist. ① Oracle bietet eine breite Palette von Datentypen, ② bietet erweiterte Sicherheitsfunktionen, ③ ist für Anwendungen auf Unternehmensebene geeignet; ① MySQL unterstützt NoSQL-Datentypen, ② verfügt über weniger Sicherheitsmaßnahmen und ③ ist für kleine bis mittlere Anwendungen geeignet.
