
Nach zwei Jahren habe ich mehr als 100 Lebensläufe überarbeitet und mehr als 200 Probeinterviews geführt.
Erst letzte Woche wurde einem Klassenkameraden während des technischen Interviews mit Alibaba Cloud diese Frage gestellt: Gehen Sie von einer Plattform mit 1 Million Anmeldeanfragen pro Tag und einem Serviceknoten mit 8G-Speicher aus. JVM-Parameter festlegen? Wenn Sie der Meinung sind, dass die Antwort nicht ideal ist, kommen Sie und fragen Sie mich nach einer Bewertung.
Wenn Sie auch eine Änderung des Lebenslaufs, eine Verschönerung des Lebenslaufs, eine Verpackung des Lebenslaufs, Probeinterviews usw. benötigen, können Sie mich kontaktieren. 🔜
Jeder muss lernen, mit Ausnahme des JVM-Konfigurationsschemas. Darüber hinaus ist es die Art und Weise, Probleme zu analysieren und die Perspektive, über Probleme nachzudenken. Diese Ideen und Perspektiven können jedem helfen, immer weiter zu kommen.
Als nächstes kommen wir zum Punkt.
Das Festlegen von JVM-Parametern für 1 Million Anmeldeanfragen pro Tag und 8G-Speicher kann grob in die folgenden 8 Schritte unterteilt werden.
1. Zusammenfassung der Routinen
Jedes neue Geschäftssystem muss die Serverkonfiguration und die JVM-Speicherparameter schätzen, bevor es online geht. Diese Kapazitäts- und Ressourcenplanung ist nicht nur eine zufällige Schätzung des Systemarchitekten, sie muss es auch sein Basierend auf Schätzen Sie das Geschäftsszenario, in dem sich das System befindet, leiten Sie ein Systembetriebsmodell ab und bewerten Sie Indikatoren wie JVM-Leistung und GC-Frequenz. Das Folgende ist ein Modellierungsschritt, den ich basierend auf den Erfahrungen von Experten und meiner eigenen Praxis zusammengefasst habe:
2. Praktische Routinen – nehmen Sie das Einloggen in das System als Beispiel
Einige Schüler sind immer noch verwirrt, nachdem sie diese Schritte gesehen haben, und sie scheinen darüber zu reden, was ich immer noch nicht tue Ich weiß nicht, wie es geht!
Einfach reden, ohne Tricks zu üben, nehmen Sie das Login-System als Beispiel, um den Abzugsprozess zu simulieren:
Man kann also grob schließen, dass ein Anmeldesystem mit 1 Million Anfragen pro Tag gemäß der 3-Instanzen-Clusterkonfiguration von 4C8G, der Zuweisung von 4G-Heapspeicher und 2G-JVM der neuen Generation eine normale Auslastung des Systems gewährleisten kann .
Bewerten Sie grundsätzlich die Ressourcen eines neuen Systems. Wie viel Kapazität und Konfiguration jede Instanz zum Aufbau eines neuen Systems benötigt, wie viele Instanzen im Cluster konfiguriert sind usw., kann nicht durch Klopfen auf Kopf und Brust entschieden werden.
Stellen Sie zunächst zwei Konzepte vor: Durchsatz und niedrige Latenz
Durchsatz = CPU-Zeit zum Ausführen von Benutzeranwendungen / (CPU-Zeit zum Ausführen von Benutzeranwendungen + CPU-Garbage-Collection-Zeit)
Antwortzeit = durchschnittlicher GC-Zeitverbrauch
Normalerweise wird der Durchsatz priorisiert oder die Antwort wird priorisiert. Dies zu priorisieren ist ein Dilemma in der JVM.
Mit zunehmendem Heap-Speicher wird die Menge, die GC auf einmal verarbeiten kann, größer und der Durchsatz wird höher, jedoch wird die Zeit für einen GC länger, was zu einer längeren Wartezeit für Threads führt, die sich dahinter befinden Wenn im Gegensatz dazu der Heap-Speicher klein ist, ist die Zeit für einen GC kurz, die Wartezeit der in der Warteschlange wartenden Threads wird kürzer und die Verzögerung wird verringert, aber die Anzahl der gleichzeitigen Anforderungen wird kleiner (nicht absolut konsistent).
Es ist unmöglich, gleichzeitig den Durchsatz oder die Reaktion zu priorisieren. Dies ist eine Frage, die abgewogen werden muss.
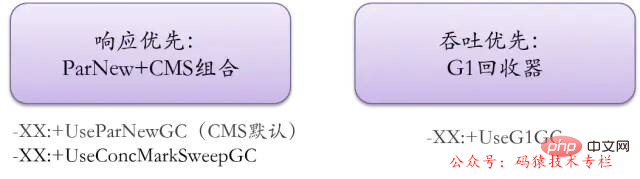
Die aktuelle Mainstream-Garbage-Collector-Konfiguration besteht darin, ParNew in der neuen Generation und CMS-Kombination in der alten Generation zu verwenden oder den G1-Collector vollständig zu verwenden.
Aus der Perspektive zukünftiger Trends ist G1 das offiziell gepflegter und angesehener Müllsammler.
Geschäftssystem:
CMS ist hauptsächlich ein Collector für die alte Generation. Standardmäßig führt es einen Defragmentierungsalgorithmus nach einem FullGC-Algorithmus aus, um Speicherfragmente zu bereinigen.
| CMS GC | Beschreibung: Stoppen Sie die Welt es | Bald | ||
|---|---|---|---|---|
| Langsam | 3. Neumarkierungsphase dient der Korrektur des Benutzers Programmfehler beim gleichzeitigen Markieren. Der Markierungsdatensatz des Teils des Objekts, der weiterhin funktioniert und Markierungsänderungen verursacht. | Ja | Schnell | |
| 4. Garbage Collection | Gleichzeitige Reinigung von Müllobjekten (Mark-and-Sweep-Algorithmus) | Nein | Langsam |
Kurz gesagt:
CM wird für latenzempfindliche Geschäftssysteme empfohlen.
Für große Speicherdienste, die einen hohen Durchsatz erfordern, verwenden Sie den G1-Recycler!
Die allgemeine Idee ist:
Der erste Schritt besteht darin, den Speicher und die Zuordnung zu bewerten ist die Angabe der Heap-Speichergröße, dies muss erfolgen, wenn das System online geht, -Xms anfängliche Heap-Größe, -Xmx maximale Heap-Größe, Hintergrund-Java-Dienste werden im Allgemeinen als die Hälfte des Systemspeichers bezeichnet. Es belegt die Systemressourcen des Servers. Wenn es zu klein ist, kann die JVM nicht die beste Leistung erzielen.
Zweitens müssen Sie die Größe der neuen Generation von -Xmn angeben. Dieser Parameter ist sehr kritisch und sehr flexibel. Obwohl Sun offiziell eine Größe von 3/8 empfiehlt, sollte er entsprechend dem Geschäftsszenario bestimmt werden Bei zustandslosen oder Light-State-Diensten (jetzt für die gängigsten Geschäftssysteme (z. B. Webanwendungen) kann die neue Generation in der Regel sogar 3/4 der Heap-Speichergröße erhalten; für zustandsbehaftete Dienste (üblich wie IM-Dienste, Gateway). Zugriffsschicht und andere Systeme) der neuen Generation kann das Standardverhältnis auf 1/3 gesetzt werden. Der Dienst ist zustandsbehaftet, was bedeutet, dass mehr lokale Cache- und Sitzungsstatusinformationen im Speicher vorhanden sind. Daher sollte in der alten Generation mehr Speicherplatz zum Speichern dieser Objekte eingerichtet werden.
Legen Sie abschließend die Stapelspeichergröße von -Xss fest und legen Sie die Stapelgröße eines einzelnen Threads fest. Der Standardwert hängt von der JDK-Version und dem JDK-System ab und beträgt im Allgemeinen 512 bis 1024 KB. Wenn ein Hintergrunddienst Hunderte von residenten Threads hat, belegt der Stapelspeicher ebenfalls eine Größe von Hunderten von MB.
| JVM-Parameter | Beschreibung | Standardeinstellung | Empfohlen |
|---|---|---|---|
| -Xms | Java-Heap-Speichergröße | OS-Speicher 64/1 | OS-Speicher halb |
| -Xmx | Maximale Größe des Java-Heap-Speichers | OS-Speicher 4/1 | die Hälfte des Betriebssystem-Speichers |
| -Xmn | Die Größe der neuen Generation im Java-Heap-Speicher. Nach Abzug der neuen Generation beträgt die verbleibende Speichergröße Speichergröße der alten Generation | 1/3 des reduzierten Betrags | Sun empfiehlt 3/8 |
| -Xss | Die Stapelspeichergröße jedes Threads | hängt mit idk | sun |
Für 8G-Speicher reicht es normalerweise aus, die Hälfte des maximalen Speichers zuzuweisen, daher wird der JVM normalerweise 4G-Speicher zugewiesen.
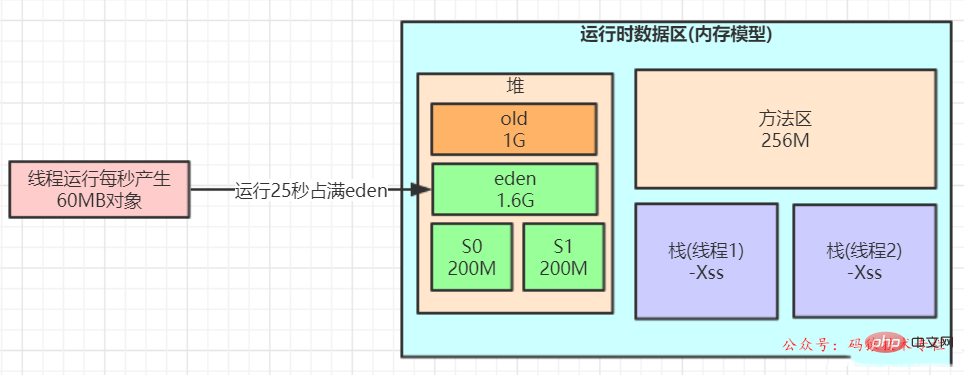
Einführung eines Leistungs-Stresstest-Links, um Schüler zu testen Drücken Sie die Anmeldeschnittstelle auf 1 Sekunde. Die Objektgenerierungsgeschwindigkeit beträgt 60 MB, wobei der kombinierte Recycler von ParNew+CMS verwendet wird. Die normale JVM-Parameterkonfiguration ist wie folgt:
-Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
Eine solche Einstellung kann aufgrund der
Dynamik zu häufigem vollständigen GC führen Prinzip der Objektaltersbeurteilung. Warum? Während des Stresstests ist der Eden-Bereich in kurzer Zeit voll (z. B. nach 20 Sekunden). Wenn das Objekt zu diesem Zeitpunkt erneut ausgeführt wird, wird MinorGC ausgelöst
Angenommen Nach diesem GC lädt S1 100 Millionen und wird in 20 Sekunden erneut ausgelöst. Die zusätzlichen 100 Millionen Objekte im S1-Bereich können zu diesem Zeitpunkt nicht mehr erfolgreich in den S2-Bereich verschoben werden Der Altersmechanismus der JVM wird ausgelöst und ein Stapel von Objekten von etwa 100 Millionen wird zur Speicherung auf die alte Generation übertragen. Wenn er über einen bestimmten Zeitraum weiter ausgeführt wird, kann das System innerhalb einer Stunde einen FullGC auslösen.
Bei der Zuteilung gemäß dem Standardverhältnis von 8:1:1 beträgt der Überlebensbereich nur etwa 10 % von 1G, also zehn bis 100 Millionen,
如果 每次minor GC垃圾回收过后进入survivor对象很多,并且survivor对象大小很快超过 Survivor 的 50% , 那么会触发动态年龄判定规则,让部分对象进入老年代.
而一个GC过程中,可能部分WEB请求未处理完毕, 几十兆对象,进入survivor的概率,是非常大的,甚至是一定会发生的.
如何解决这个问题呢?为了让对象尽可能的在新生代的eden区和survivor区, 尽可能的让survivor区内存多一点,达到200兆左右,
于是我们可以更新下JVM参数设置:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8 说明: ‐Xmn2048M ‐XX:SurvivorRatio=8 年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
survivor达到200m,如果几十兆对象到底survivor, survivor 也不一定超过 50%
这样可以防止每次垃圾回收过后,survivor对象太早超过 50% ,
这样就降低了因为对象动态年龄判断原则导致的对象频繁进入老年代的问题,
Dynamische Altersbeurteilungsregeln für Objekte, die in die alte Generation eintreten (Berechnungsschwellenwert für das dynamische Aufstiegsalter): Wenn während der Minor GC die Größe von Objekten mit Alter 1 bis N im Survivor 50 % des Survivor überschreitet, werden Objekte größer als oder gleich dem Alter N wird bei Eintritt ins hohe Alter platziert.
Die Kernoptimierungsstrategie besteht darin, kurzfristig überlebende Objekte so weit wie möglich im Überlebenden zu belassen und nicht in die alte Generation einzutreten. Auf diese Weise werden diese Objekte während des Minor-GC recycelt und gelangen nicht in die alte Generation und Ursache voller GC.
Besonders zu erwähnen ist hier die Bewertung des Speichers und der Zuweisung.
Der erste Schritt besteht darin, die Größe des Heap-Speichers anzugeben. Dies ist erforderlich, wenn das System online geht , -Xmx Die maximale Heap-Größe wird im Allgemeinen als die Hälfte des Systemspeichers in Java-Hintergrunddiensten angegeben. Wenn sie zu groß ist, werden die Systemressourcen des Servers beansprucht. Wenn sie zu klein ist, kann die beste Leistung der JVM nicht erzielt werden ausgeübt werden.
Zweitens müssen Sie die Größe der neuen Generation von -Xmn angeben. Dieser Parameter ist sehr wichtig und bietet große Flexibilität. Obwohl Sun offiziell eine Größe von 3/8 empfiehlt, sollte er entsprechend dem Geschäftsszenario bestimmt werden:
Der Dienst ist zustandsbehaftet, was bedeutet, dass mehr lokale Cache- und Sitzungsstatusinformationen im Speicher vorhanden sind, was bedeutet, dass mehr Platz für die alte Generation zum Speichern dieser Objekte eingerichtet werden sollte.
-Xss-Stapelspeichergröße, legen Sie die Stapelgröße eines einzelnen Threads fest. Der Standardwert hängt von der JDK-Version und dem JDK-System ab und beträgt im Allgemeinen 512 bis 1024 KB. Wenn ein Hintergrunddienst Hunderte von residenten Threads hat, belegt der Stapelspeicher ebenfalls eine Größe von Hunderten von MB.
Angenommen, ein kleiner GC dauert zwanzig bis dreißig Sekunden und die meisten Objekte werden im Allgemeinen innerhalb weniger Sekunden zu Müll.
Wenn das Objekt beispielsweise so lange nicht recycelt wurde, wurde es 2 Jahre lang nicht recycelt Minuten kann man davon ausgehen, dass es sich bei diesen Objekten um Objekte handelt, die lange überleben und daher in die alte Generation verschoben werden, anstatt weiterhin den Überlebensbereichsraum zu belegen.
所以,可以将默认的15岁改小一点,比如改为5,
那么意味着对象要经过5次minor gc才会进入老年代,整个时间也有一两分钟了(5*30s= 150s),和几秒的时间相比,对象已经存活了足够长时间了。
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5
对于多大的对象直接进入老年代(参数-XX:PretenureSizeThreshold),一般可以结合自己系统看下有没有什么大对象 生成,预估下大对象的大小,一般来说设置为1M就差不多了,很少有超过1M的大对象,
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M
JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),
如果内存较大(超过4个G,只是经验 值),还是建议使用G1.
这里是4G以内,又是主打“低延时” 的业务系统,可以使用下面的组合:
ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC)
新生代的采用ParNew回收器,工作流程就是经典复制算法,在三块区中进行流转回收,只不过采用多线程并行的方式加快了MinorGC速度。
老生代的采用CMS。再去优化老年代参数:比如老年代默认在标记清除以后会做整理,还可以在CMS的增加GC频次还是增加GC时长上做些取舍,
如下是响应优先的参数调优:
XX:CMSInitiatingOccupancyFraction=70
设定CMS在对内存占用率达到70%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC)
XX:+UseCMSInitiatinpOccupancyOnly
和上面搭配使用,否则只生效一次
-XX:+AlwaysPreTouch
强制操作系统把内存真正分配给IVM,而不是用时才分配。
综上,只要年轻代参数设置合理,老年代CMS的参数设置基本都可以用默认值,如下所示:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M ‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC ‐XX:CMSInitiatingOccupancyFraction=70 ‐XX:+UseCMSInitiatingOccupancyOnly ‐XX:+AlwaysPreTouch
参数解释
1.‐Xms3072M ‐Xmx3072M 最小最大堆设置为3g,最大最小设置为一致防止内存抖动
2.‐Xss1M 线程栈1m
3.‐Xmn2048M ‐XX:SurvivorRatio=8 年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
4.-XX:MaxTenuringThreshold=5 年龄为5进入老年代 5.‐XX:PretenureSizeThreshold=1M 大于1m的大对象直接在老年代生成
6.‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC 使用ParNew+cms垃圾回收器组合
7.‐XX:CMSInitiatingOccupancyFraction=70 老年代中对象达到这个比例后触发fullgc
8.‐XX:+UseCMSInitiatinpOccupancyOnly 老年代中对象达到这个比例后触发fullgc,每次
9.‐XX:+AlwaysPreTouch
‐XX:CMSInitiatingOccupancyFraction=70 2px;padding: 2px 4px;Umriss: 0px;Schriftgröße: 14px;Randradius: 4px;Hintergrundfarbe: rgba(27, 31, 35, 0.05);Schriftfamilie: „Operator Mono“, Consolas, Monaco , Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);">‐XX:+UseCMSInitiatinpOccupancyOnly
-XX:+HeapDumpOnOutOfMemoryError
Nach dem Login kopieren
在Out Of Memory,JVM快死掉的时候,输出Heap Dump到指定文件。
不然开发很多时候还真不知道怎么重现错误。
路径只指向目录,JVM会保持文件名的唯一性,叫java_pid${pid}.hprof。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=${LOGDIR}/Nach dem Login kopieren
因为如果指向特定的文件,而文件已存在,反而不能写入。
输出4G的HeapDump,会导致IO性能问题,在普通硬盘上,会造成20秒以上的硬盘IO跑满,
需要注意一下,但在容器环境下,这个也会影响同一宿主机上的其他容器。
GC的日志的输出也很重要:
-Xloggc:/dev/xxx/gc.log
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
Nach dem Login kopieren
GC的日志实际上对系统性能影响不大,打日志对排查GC问题很重要。
一份通用的JVM参数模板
一般来说,大企业或者架构师团队,都会为项目的业务系统定制一份较为通用的JVM参数模板,但是许多小企业和团队可能就疏于这一块的设计,如果老板某一天突然让你负责定制一个新系统的JVM参数,你上网去搜大量的JVM调优文章或博客,结果发现都是零零散散的、不成体系的JVM参数讲解,根本下不了手,这个时候你就需要一份较为通用的JVM参数模板了,不能保证性能最佳,但是至少能让JVM这一层是稳定可控的,
在这里给大家总结了一份模板:
基于4C8G系统的ParNew+CMS回收器模板(响应优先),新生代大小根据业务灵活调整!
-Xms4g
-Xmx4g
-Xmn2g
-Xss1m
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=10
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=70
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+AlwaysPreTouch
-XX:+HeapDumpOnOutOfMemoryError
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
Nach dem Login kopieren
如果是GC的吞吐优先,推荐使用G1,基于8C16G系统的G1回收器模板:
G1收集器自身已经有一套预测和调整机制了,因此我们首先的选择是相信它,
即调整-XX:MaxGCPauseMillis=N参数,这也符合G1的目的——让GC调优尽量简单!
同时也不要自己显式设置新生代的大小(用-Xmn或-XX:NewRatio参数),
如果人为干预新生代的大小,会导致目标时间这个参数失效。
-Xms8g
-Xmx8g
-Xss1m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=150
-XX:InitiatingHeapOccupancyPercent=40
-XX:+HeapDumpOnOutOfMemoryError
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
Nach dem Login kopieren
G1参数
描述
默认值
XX:MaxGCPauseMillis=N
最大GC停顿时间。柔性目标,JVM满足90%,不保证100%。
200
-XX:nitiatingHeapOccupancyPercent=n
当整个堆的空间使用百分比超过这个值时,就会融发MixGC
45
Für -XX:MaxGCPauseMillis Für Code> weist die Parametereinstellung eine klare Tendenz auf: niedriger ↓: Die Verzögerung ist geringer, aber MinorGC ist häufig, MixGC recycelt den alten Bereich weniger und erhöht das Risiko einer vollständigen GC. Erhöhen ↑: Es werden mehr Objekte gleichzeitig recycelt, aber auch die Gesamtreaktionszeit des Systems wird verlängert. <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:MaxGCPauseMillis来说,参数的设置带有明显的倾向性:调低↓:延迟更低,但MinorGC频繁,MixGC回收老年代区减少,增大Full GC的风险。调高↑:单次回收更多的对象,但系统整体响应时间也会被拉长。
针对InitiatingHeapOccupancyPercent
Zusammenfassung der OptimierungUmfassende Optimierungsideen für das System, bevor es online geht:1. Geschäftsschätzung: Bewerten Sie dann anhand der erwarteten Parallelität und des durchschnittlichen Speicherbedarfs jeder Aufgabe, wie viele Maschinen zum Hosten erforderlich sind , welche Konfiguration für jede Maschine erforderlich ist. 2. Kapazitätsschätzung: Ordnen Sie dann entsprechend der Aufgabenverarbeitungsgeschwindigkeit des Systems die Größe der Eden- und Surivior-Bereiche sowie die Speichergröße der alten Generation angemessen zu. 3. Recycler-Auswahl: Für Systeme mit Antwortpriorität wird empfohlen, den ParNew+CMS-Recycler für durchsatzorientierte Multi-Core-Dienste mit großem Speicher (Heap-Größe ≥ 8G) zu verwenden . 🎜4. Optimierungsidee: Lassen Sie kurzlebige Objekte in der MinorGC-Stufe recyceln (gleichzeitig können die überlebenden Objekte nach dem Recycling
5. Der bisher zusammengefasste Optimierungsprozess basiert hauptsächlich auf der Test- und Verifizierungsphase vor dem Online-Gehen. Daher versuchen wir, die JVM-Parameter der Maschine auf den optimalen Wert einzustellen, bevor wir online gehen!
JVM-Optimierung ist nur ein Mittel, aber nicht alle Probleme können durch JVM-Optimierung gelöst werden. Wir können einige der folgenden Prinzipien befolgen:
Bevor Sie online gehen, sollten Sie zunächst darüber nachdenken Einstellen der JVM-Parameter der Maschine auf das Optimum; Reduzieren Sie die Anzahl der erstellten Objekte (Codeebene); Reduzieren Sie die Verwendung globaler Variablen und großer Objekte (Codeebene); Anpassungen optimieren und Code optimieren, JVM-Optimierung ist der letzte Ausweg (Code- und Architekturebene); -
Es ist besser, die GC-Situation zu analysieren und den Code zu optimieren, als JVM-Parameter zu optimieren (Codeebene); Nach den oben genannten Prinzipien haben wir festgestellt, dass die effektivste Optimierungsmethode tatsächlich die Optimierung der Architektur und der Codeebene ist, während die JVM-Optimierung der letzte Ausweg ist, der auch als letzter „Squeeze“ der Serverkonfiguration bezeichnet werden kann . Was ist ZGC?
ZGC (Z Garbage Collector) ist ein von Oracle entwickelter Garbage Collector mit geringer Latenz als Hauptziel.
Es handelt sich um einen Kollektor, der auf dem dynamischen Regionsspeicherlayout (vorübergehend) ohne Altersgenerierung basiert und Technologien wie Lesebarrieren, gefärbte Zeiger und Speichermehrfachzuordnung verwendet, um gleichzeitige Markierungssortierungsalgorithmen zu implementieren.
Neu in JDK 11 hinzugefügt, befindet es sich noch im experimentellen Stadium.
Die Hauptfunktionen sind: Terabyte Speicher recyceln (maximal 4T) und die Pausenzeit beträgt nicht mehr als 10 ms.
Vorteile: geringe Pausen, hoher Durchsatz, wenig zusätzlicher Speicherverbrauch während der ZGC-Erfassung
Nachteile: schwebender Müll
Wird derzeit nur sehr wenig verwendet und es dauert immer noch Zeit, bis das Schreiben wirklich populär wird.
Wie wählt man einen Müllsammler aus?
Wie wählt man in einem realen Szenario aus? Hier sind einige Vorschläge, die Ihnen hoffentlich helfen werden:
1 Wenn Ihr Heap-Speicher nicht sehr groß ist (z. B. 100 MB), ist die Wahl eines seriellen Kollektors im Allgemeinen die beste Wahl am effizientesten. Parameter: -XX:+UseSerialGC Code>. <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:+UseSerialGC 。
2、如果你的应用运行在单核的机器上,或者你的虚拟机核数只有 单核,选择串行收集器依然是合适的,这时候启用一些并行收集器没有任何收益。参数:-XX:+UseSerialGC 。
3、如果你的应用是“吞吐量”优先的,并且对较长时间的停顿没有什么特别的要求。选择并行收集器是比较好的。参数:-XX:+UseParallelGC
-XX:+UseSerialGC Code>. 🎜🎜3. Wenn Ihre Anwendung „Durchsatz“ priorisiert und keine besonderen Anforderungen an lange Pausen stellt. Es ist besser, einen Parallelkollektor zu wählen. Parameter: <code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0,05);font-family: „Operator Mono“, Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);">-XX:+UseParallelGC Code>. 🎜<p data-tool="mdnice编辑器" style='margin-top: 0.8em;margin-bottom: 0.8em;padding-top: 8px;padding-bottom: 8px;outline: 0px;color: rgb(53, 53, 53);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.8px;text-align: left;white-space: normal;word-spacing: 0.8px;background-color: rgb(255, 255, 255);line-height: 1.75;'>4. Wenn Ihre Anwendung hohe Anforderungen an die Reaktionszeit stellt und weniger Pausen wünscht. Selbst eine Pause von 1 Sekunde führt zu einer großen Anzahl von Anforderungsfehlern. Daher ist es sinnvoll, G1, ZGC oder CMS zu wählen. Obwohl die GC-Pausen dieser Kollektoren normalerweise kürzer sind, sind für die Bewältigung der Arbeit einige zusätzliche Ressourcen erforderlich, und der Durchsatz ist normalerweise geringer. Parameter: <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:+UseConcMarkSweepGC 、 -XX:+UseG1GC 、 -XX:+UseZGC usw. Ausgehend von den oben genannten Ausgangspunkten stellen unsere gewöhnlichen Webserver sehr hohe Anforderungen an die Reaktionsfähigkeit.
Die Selektivität konzentriert sich tatsächlich auf CMS, G1 und ZGC. Für einige geplante Aufgaben ist die Verwendung eines Parallelkollektors die bessere Wahl.
Was ist Metaspace? Was ist permanente Generation? Warum Metaspace statt permanenter Generierung verwenden?
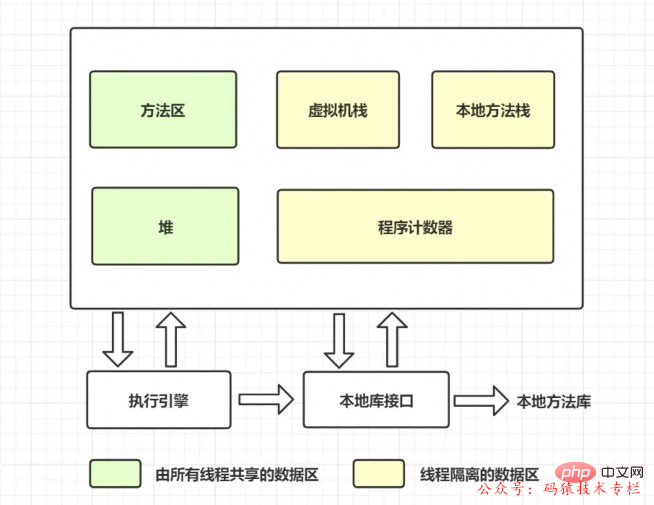
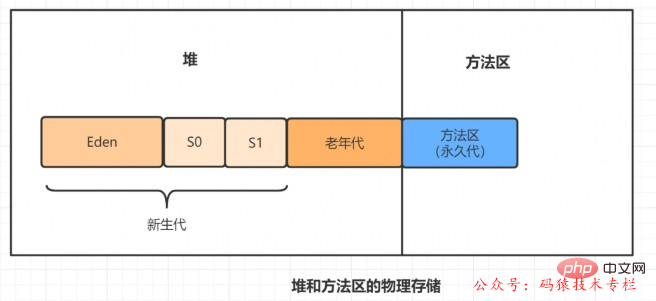
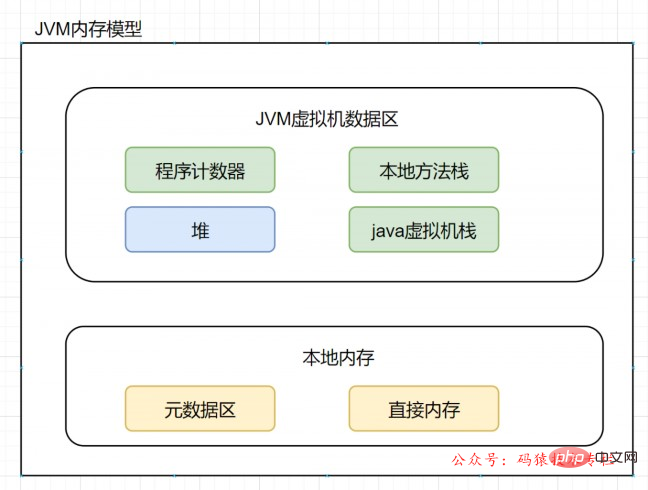
Lassen Sie uns zunächst den Methodenbereich überprüfen und uns das Datenspeicherdiagramm bei laufender virtueller Maschine wie folgt ansehen:
Der Methodenbereich ist wie der Heap ein Speicherbereich, der von jedem Thread gemeinsam genutzt wird. Er wird zum Speichern von Daten wie Klasseninformationen, Konstanten, statischen Variablen und just-in-time-kompiliertem Code verwendet die virtuelle Maschine.
Was ist permanente Generation? Was hat das mit dem Methodenbereich zu tun?
Wenn Sie auf der virtuellen HotSpot-Maschine entwickeln und bereitstellen, bezeichnen viele Programmierer den Methodenbereich als permanente Generation.
Man kann sagen, dass der Methodenbereich die Spezifikation ist und die permanente Generierung die Implementierung der Spezifikation durch Hotspot ist.
In Java7 und früheren Versionen ist der Methodenbereich in der permanenten Generation implementiert.
Was ist Metaspace? Was hat das mit dem Methodenbereich zu tun?
Für Java8 hat HotSpots die permanente Generierung abgebrochen und durch Metaspace ersetzt.
Mit anderen Worten, der Methodenbereich ist immer noch vorhanden, aber die Implementierung hat sich geändert, von der permanenten Generierung zum Metaspace.
Warum wird die permanente Generation durch Metaspace ersetzt?
Der Methodenbereich der permanenten Generierung grenzt an den vom Heap verwendeten physischen Speicher an.
Die permanente Generation wird über die folgenden zwei Parameter konfiguriert~
-XX:PremSize Code>: Legen Sie die Anfangsgröße der permanenten Generation fest : 4px ;Hintergrundfarbe: rgba(27, 31, 35, 0,05);Schriftfamilie: „Operator Mono“, Consolas, Monaco, Menlo, Monospace;Wortumbruch: break-all;Farbe: rgb(255, 93 , 108 );">-XX:MaxPermSize: Legen Sie den Maximalwert der permanenten Generation fest, der Standardwert ist 64M-XX:PremSize:设置永久代的初始大小-XX:MaxPermSizepermanente Generation, wenn viele Klassen dynamisch generiert werden, java.lang Es ist wahrscheinlich, dass .OutOfMemoryError auftritt: PermGen-Speicherplatzfehler, da die Konfiguration des permanenten Generierungsraums begrenzt ist. Das typischste Szenario ist, wenn in der Webentwicklung viele JSP-Seiten vorhanden sind.
Nach JDK8 existiert der Methodenbereich im Metaspace. Der physische Speicher ist nicht mehr kontinuierlich mit dem Heap verbunden, sondern existiert direkt im lokalen Speicher. Theoretisch entspricht die Größe desSpeichers der Maschine der Größe des Metaraums.
Sie können die Größe des Metaspace über die folgenden Parameter festlegen:-XX:MetaspaceSize Code>, die anfängliche Speicherplatzgröße. Wenn dieser Wert erreicht ist, wird die Speicherbereinigung zum Entladen des Typs ausgelöst. Gleichzeitig passt der GC den Wert an: Wenn eine große Menge Speicherplatz freigegeben wird, wird der Wert entsprechend reduziert ; wenn nur wenig Speicherplatz freigegeben wird, erhöhen Sie diesen Wert entsprechend, wenn er MaxMetaspaceSize nicht überschreitet. <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集-XX:MaxMetaspaceFreeRatioBei Verwendung von Metaspace wird die Anzahl der ladbaren Metadatenklassen nicht mehr durch MaxPermSize gesteuert, sondern durch den tatsächlich verfügbaren Speicherplatz des Systems.
Was ist Stop The World? Was ist OopMap? Was ist ein sicherer Ort?
Der Prozess der Müllabfuhr umfasst die Bewegung von Objekten.
Um die Korrektheit von Objektreferenzaktualisierungen sicherzustellen, müssen alle Benutzerthreads angehalten werden. Eine Pause wie diese wird vom Designer der virtuellen Maschine als „Stop The World“ beschrieben. Auch als STW bezeichnet. In HotSpot gibt es eine Datenstruktur (Zuordnungstabelle) namens
OopMap. Sobald die Klassenladeaktion abgeschlossen ist, berechnet HotSpot, welche Art von Daten sich an welchem Offset im Objekt befindet, und zeichnet sie in OopMap auf.
Während des Just-in-Time-Kompilierungsprozesses wird auch eine OopMap an
bestimmten Orten generiert, die aufzeichnet, welche Orte auf dem Stapel und in den Registern Referenzen sind. Diese spezifischen Positionen befinden sich hauptsächlich an: 1. Das Ende der Schleife (nicht gezählte Schleife)
2. Bevor die Methode zurückkehrt / nach dem Aufruf der Aufrufanweisung der Methode
3 Die Orte, an denen Ausnahmen ausgelöst werden können
Diese Orte werden Sicherheitspunkte genannt.
Wenn das Benutzerprogramm ausgeführt wird, ist es nicht möglich, die Speicherbereinigung an irgendeiner Stelle im Code-Anweisungsfluss anzuhalten und zu starten, aber es muss an einem sicheren Punkt ausgeführt werden, bevor es angehalten werden kann.
Das obige ist der detaillierte Inhalt vonAlibaba-Terminal: 1 Million Anmeldeanfragen pro Tag, 8G-Speicher, wie werden JVM-Parameter festgelegt?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



