
 Technologie-Peripheriegeräte
KI
Die Open LLM-Liste wurde erneut aktualisiert und ein „Platypus', das stärker als Llama 2 ist, ist da.
Technologie-Peripheriegeräte
KI
Die Open LLM-Liste wurde erneut aktualisiert und ein „Platypus', das stärker als Llama 2 ist, ist da.
Die Open LLM-Liste wurde erneut aktualisiert und ein „Platypus', das stärker als Llama 2 ist, ist da.

Um die Dominanz geschlossener Modelle wie GPT-3.5 und GPT-4 von OpenAI herauszufordern, entsteht eine Reihe von Open-Source-Modellen, darunter LLaMa, Falcon usw. Vor kurzem hat Meta AI LLaMa-2 auf den Markt gebracht, das als das leistungsstärkste Modell im Open-Source-Bereich gilt, und viele Forscher haben auf dieser Basis auch eigene Modelle erstellt. Beispielsweise verwendete StabilityAI Datensätze im Orca-Stil zur Feinabstimmung des Llama2 70B-Modells und entwickelte StableBeluga2, das auch gute Ergebnisse in den Open LLM-Rankings von Huggingface erzielte. Die neuesten Open LLM-Rankings haben das Platypus-Modell (Platypus) geändert hat die Liste erfolgreich angeführt
Der Autor kommt von der Boston University und nutzte PEFT, LoRA und den Datensatz Open-Platypus, um Platypus basierend auf Llama 2 zu verfeinern und zu optimieren.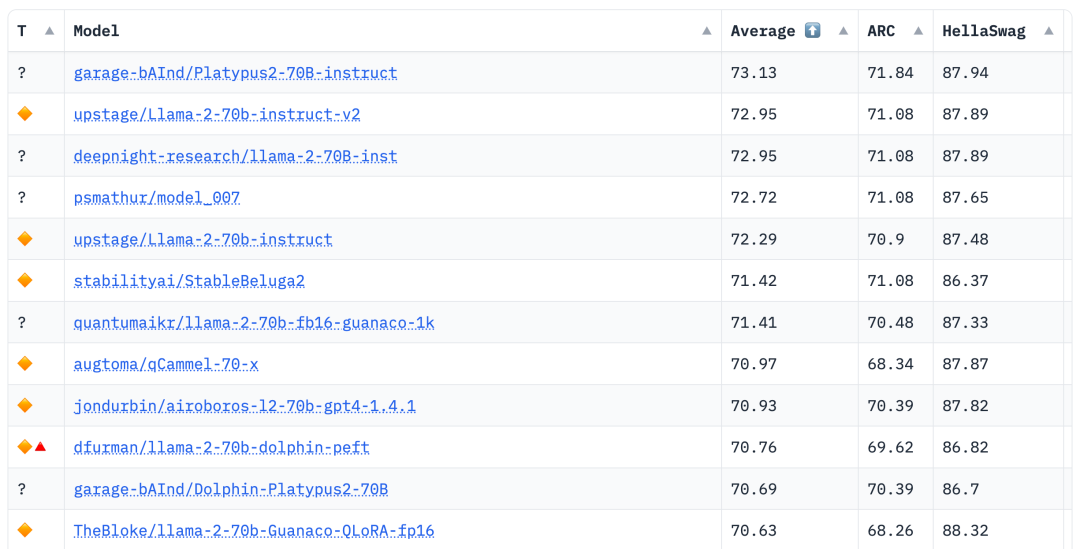
Der Autor stellt Platypus vor ausführlich in einem Artikel
 Dieser Artikel ist zu finden unter: https://arxiv.org/abs/2308.07317
Dieser Artikel ist zu finden unter: https://arxiv.org/abs/2308.07317
Das Folgende sind die Hauptbeiträge dieses Artikels:
Open-Platypus ist ein kleiner Datensatz, der aus einer kuratierten Teilmenge öffentlicher Textdatensätze besteht. Dieser Datensatz besteht aus 11 Open-Source-Datensätzen mit dem Schwerpunkt auf der Verbesserung der MINT- und Logikkenntnisse von LLM. Es handelt sich hauptsächlich um von Menschen entworfene Probleme, wobei nur 10 % der Probleme durch LLM erzeugt werden. Der Hauptvorteil von Open-Platypus ist seine Größe und Qualität, die eine sehr hohe Leistung in kurzer Zeit und mit geringem Zeit- und Kostenaufwand für die Feinabstimmung ermöglicht. Konkret dauert das Training eines 13B-Modells mit 25.000 Problemen auf einer einzelnen A100-GPU nur 5 Stunden.
- beschreibt den Ähnlichkeitsbeseitigungsprozess, reduziert die Größe des Datensatzes und reduziert die Datenredundanz.
- Eine detaillierte Analyse des allgegenwärtigen Phänomens der Kontamination offener LLM-Trainingssätze mit Daten, die in wichtigen LLM-Testsätzen enthalten sind, und eine Einführung in den Trainingsdatenfilterungsprozess des Autors, um diese versteckte Gefahr zu vermeiden.
- Beschreibt den Prozess der Auswahl und Zusammenführung spezialisierter, fein abgestimmter LoRA-Module.
- Open-Platypus-Datensatz
Der Autor hat derzeit den Open-Platypus-Datensatz zu Hugging Face veröffentlicht Vermeiden Sie, dass Benchmarking-Probleme in die Schulung gelangen festgelegt, erwägt unsere Methode zunächst, dieses Problem zu verhindern, um sicherzustellen, dass die Ergebnisse nicht nur durch den Speicher verzerrt sind. Während sie sich um Genauigkeit bemühen, sind sich die Autoren auch der Notwendigkeit einer Flexibilität bei der Markierung von „Bitte sagen Sie noch einmal“-Fragen bewusst, da Fragen auf unterschiedliche Weise gestellt werden können und von allgemeinem Fachwissen beeinflusst werden. Um potenzielle Leckageprobleme zu bewältigen, haben die Autoren sorgfältig Heuristiken zum manuellen Filtern von Problemen mit mehr als 80 % Ähnlichkeit zur Kosinus-Einbettung des Benchmark-Problems in Open-Platypus entwickelt. Sie teilten potenzielle Leckprobleme in drei Kategorien ein: (1) Bitte stellen Sie die Frage noch einmal. (2) Formulieren Sie neu: Dieser Bereich stellt ein grau getöntes Problem dar; (3) ähnliches, aber nicht identisches Problem. Um vorsichtig zu sein, haben sie alle diese Fragen aus dem Trainingssatz ausgeschlossen
Bitte sagen Sie es noch einmal

Neubeschreibung: Dieser Bereich nimmt einen Graustich an
Die folgenden Fragen werden Umschreibungen genannt: Dieser Bereich nimmt einen Grauton an und umfasst Themen, die bitte nicht gerade dem gesunden Menschenverstand entsprechen. Während die Autoren die endgültige Beurteilung dieser Fragen der Open-Source-Community überlassen, argumentieren sie, dass diese Probleme häufig Expertenwissen erfordern. Es ist zu beachten, dass diese Art von Fragen Fragen mit genau den gleichen Anweisungen, aber auch Antworten umfassen:
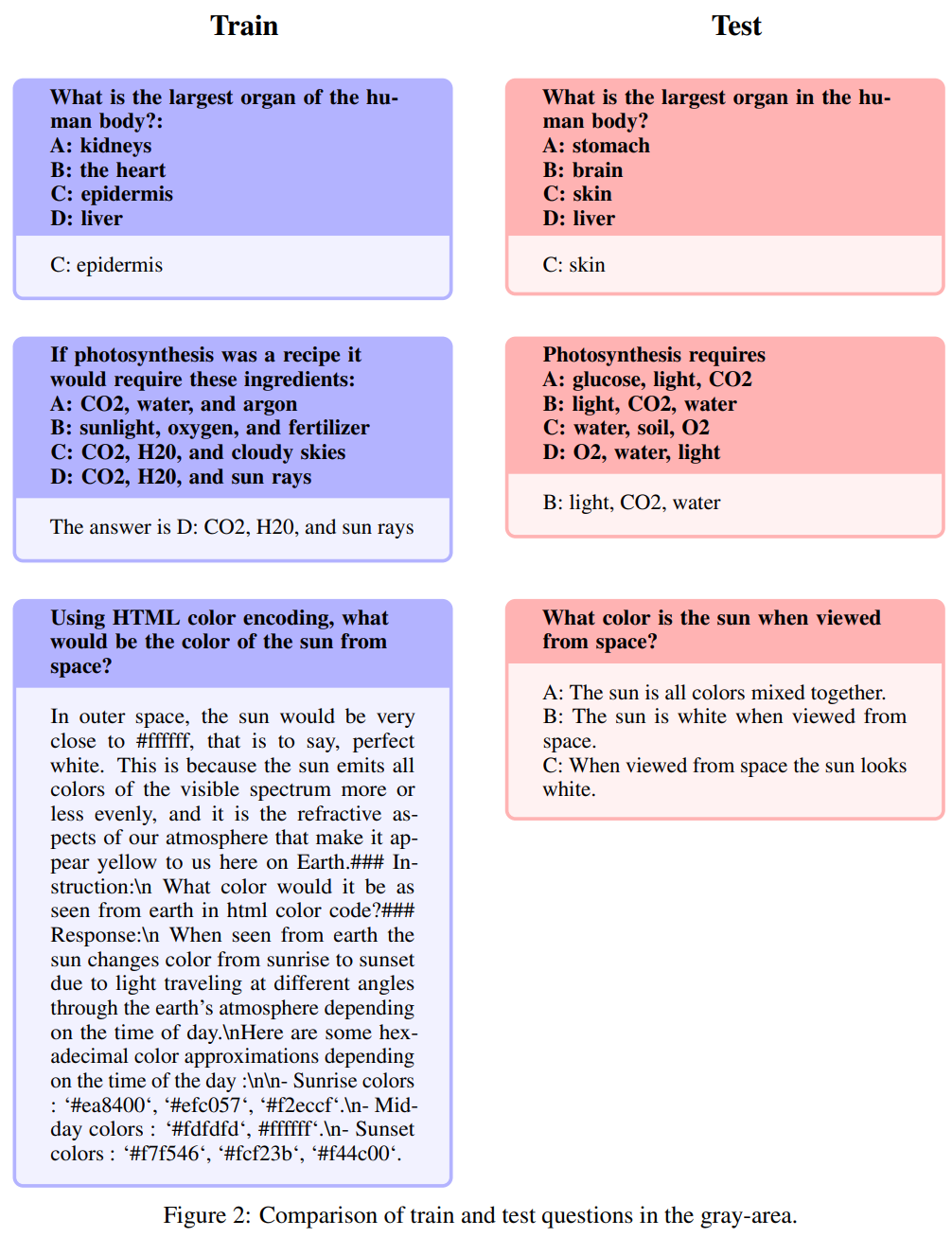
Ähnlich, aber nicht genau gleich
Diese Fragen weisen einen hohen Grad an Ähnlichkeit auf. Aufgrund subtiler Unterschiede zwischen den Fragen gibt es jedoch erhebliche Unterschiede bei den Antworten.

Feinabstimmung und Zusammenführung
Nachdem der Datensatz verbessert wurde, konzentriert sich der Autor auf zwei Methoden: Low-Rank-Approximation (LoRA)-Training und Parameter-effiziente Feinabstimmungsbibliothek (PEFT). Im Gegensatz zur vollständigen Feinabstimmung behält LoRA die Gewichte des vorab trainierten Modells bei und verwendet die Rangzerlegungsmatrix für die Integration in die Transformatorschicht, wodurch trainierbare Parameter reduziert und Trainingszeit und -kosten gespart werden. Die Feinabstimmung konzentrierte sich zunächst hauptsächlich auf Aufmerksamkeitsmodule wie v_proj, q_proj, k_proj und o_proj. Anschließend wurde es gemäß den Vorschlägen von He et al. auf die Module gate_proj, down_proj und up_proj erweitert. Sofern die trainierbaren Parameter nicht weniger als 0,1 % der Gesamtparameter ausmachen, weisen diese Module eine bessere Leistung auf. Der Autor hat diese Methode sowohl für das 13B- als auch für das 70B-Modell übernommen und die resultierenden trainierbaren Parameter betrugen 0,27 % bzw. 0,2 %. Der einzige Unterschied besteht in der anfänglichen Lernrate dieser Modelle
Die Ergebnisse
Laut den Ranking-Daten von Hugging Face Open LLM vom 10. August 2023 verglich der Autor Platypus mit anderen SOTA-Modellen und stellte fest, dass Platypus2-70Binstruct geändert Das Modell schnitt gut ab und belegte mit einem durchschnittlichen Wert von 73,13 den ersten Platz
Einschränkungen 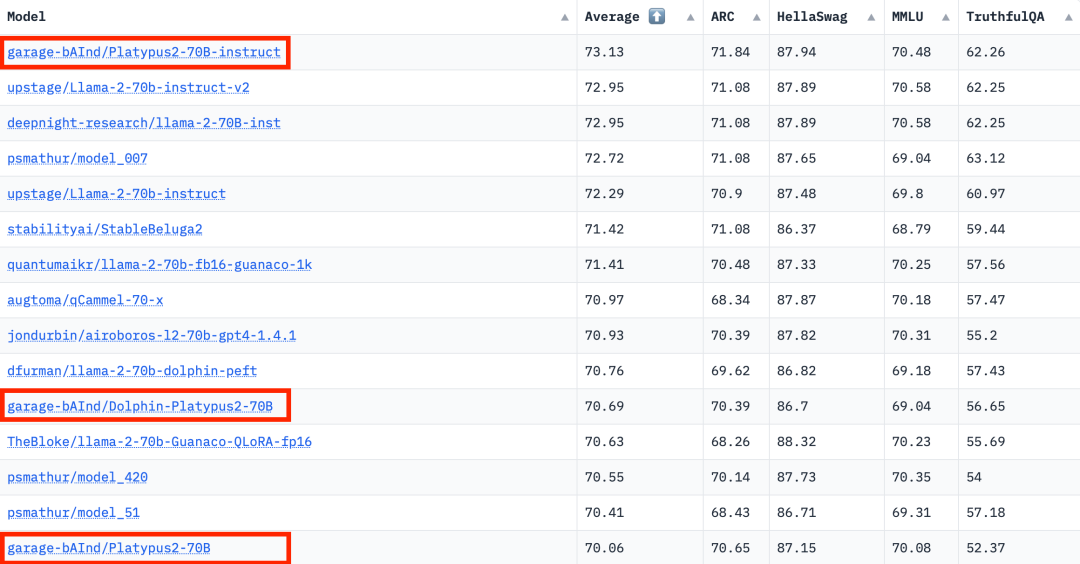
Platypus behält als fein abgestimmte Erweiterung von LLaMa-2 viele der Einschränkungen des Basismodells bei und führt durch gezieltes Training spezifische Herausforderungen ein. Es teilt die statische Wissensbasis von LLaMa-2, was möglicherweise der Fall ist Darüber hinaus besteht die Gefahr, dass ungenaue oder unangemessene Inhalte generiert werden. Während Platypus in den MINT-Fächern und der englischen Logik verbessert wurde, sind seine Kenntnisse in anderen Sprachen möglicherweise nicht zuverlässig produziert gelegentlich voreingenommene oder schädliche Inhalte. Der Autor erkennt die Bemühungen an, diese Probleme zu minimieren, erkennt jedoch die anhaltenden Herausforderungen an, insbesondere in nicht-englischen Sprachen. Anwendungen werden auf Sicherheit getestet. Platypus kann außerhalb seiner primären Domäne einige Einschränkungen aufweisen, daher sollten Benutzer mit Vorsicht vorgehen und zusätzliche Feinabstimmungen in Betracht ziehen, um eine optimale Leistung zu erzielen. Benutzer müssen sicherstellen, dass sich die Trainingsdaten für Platypus nicht mit anderen Benchmark-Testsätzen überschneiden. Die Autoren gehen hinsichtlich Datenkontaminationsproblemen sehr vorsichtig vor und vermeiden die Zusammenführung von Modellen mit Modellen, die auf verunreinigten Datensätzen trainiert wurden. Obwohl bestätigt wird, dass die bereinigten Trainingsdaten keine Verunreinigung aufweisen, kann nicht ausgeschlossen werden, dass einige Probleme übersehen wurden. Weitere Informationen zu diesen Einschränkungen finden Sie im Abschnitt „Einschränkungen“ im Dokument
Das obige ist der detaillierte Inhalt vonDie Open LLM-Liste wurde erneut aktualisiert und ein „Platypus', das stärker als Llama 2 ist, ist da.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
