Die relationale Datenbank selbst wird eher zu einem Systemengpass, und die Speicherkapazität, die Anzahl der Verbindungen und die Verarbeitungskapazität einer einzelnen Maschine sind begrenzt. Wenn das Datenvolumen einer einzelnen Tabelle aufgrund der großen Anzahl von Abfragedimensionen 1000 W oder 100 G erreicht, sinkt die Leistung bei der Ausführung vieler Vorgänge immer noch erheblich, selbst wenn Slave-Datenbanken hinzugefügt und Indizes optimiert werden. Zu diesem Zeitpunkt muss eine Segmentierung in Betracht gezogen werden. Der Zweck der Segmentierung besteht darin, die Belastung der Datenbank zu verringern und die Abfragezeit zu verkürzen.
1000W oder 100G können als Branchenreferenzwert bezeichnet werden. Die Details hängen von der aktuellen Systemhardwareausstattung, dem Design der Tischstruktur und anderen Faktoren ab.
Der Kerninhalt der Datenbankverteilung ist nichts anderes als die Datensegmentierung (Sharding) sowie die Positionierung und Integration von Daten nach der Segmentierung. Bei der Datensegmentierung werden Daten verteilt in mehreren Datenbanken gespeichert, wodurch die Datenmenge in einer einzelnen Datenbank verringert wird. Durch Erweitern der Anzahl von Hosts können die Leistungsprobleme einer einzelnen Datenbank gemildert werden, wodurch der Zweck einer Verbesserung der Datenbankbetriebsleistung erreicht wird.
Datensegmentierung kann je nach Segmentierungstyp in zwei Arten unterteilt werden: vertikale (vertikale) Segmentierung und horizontale (horizontale) Segmentierung
Vertikale Segmentierung Es gibt zwei gängige Typen: vertikale Unterbibliothek und vertikale Untertabelle.
Beim vertikalen Sharding werden verschiedene Tabellen mit geringer Korrelation basierend auf der Geschäftskopplung in verschiedenen Datenbanken gespeichert. Der Ansatz ähnelt der Aufteilung eines großen Systems in mehrere kleine Systeme, die unabhängig voneinander entsprechend der Unternehmensklassifizierung unterteilt werden. Ähnlich dem Ansatz der „Microservice Governance“ nutzt jeder Microservice eine eigene Datenbank. Wie im Bild gezeigt:
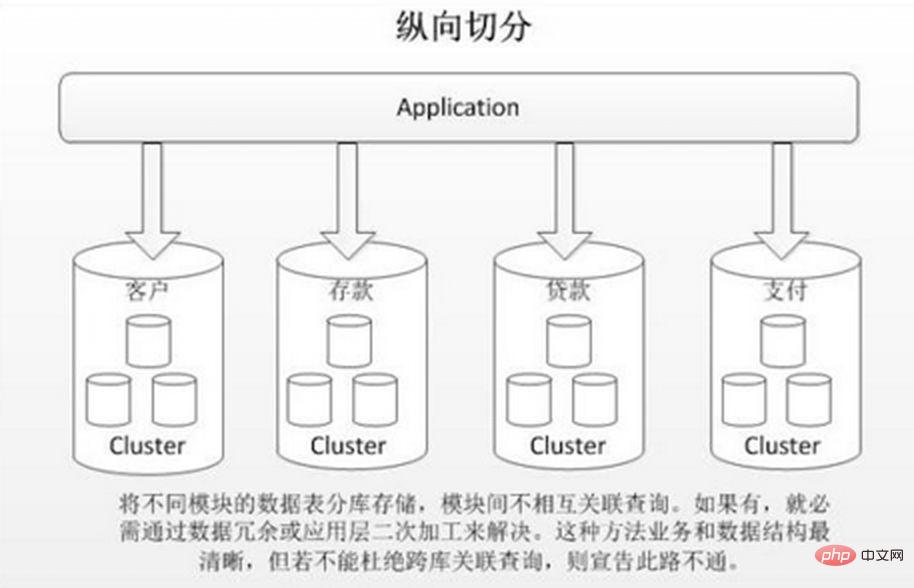
Die vertikale Tabellenaufteilung basiert auf „Spalten“ in der Datenbank. Wenn eine Tabelle viele Felder hat, können Sie eine neue Erweiterungstabelle erstellen und die Felder, die selten verwendet werden oder große Feldlängen haben, in erweiterte Tabellen aufteilen . Tisch. Wenn viele Felder vorhanden sind (z. B. hat eine große Tabelle mehr als 100 Felder), ist die „Aufteilung der großen Tabelle in kleine Tabellen“ einfacher zu entwickeln und zu verwalten und kann auch seitenübergreifende Probleme vermeiden. Die unterste Ebene von MySQL Die über Datenseiten gespeicherte Aufzeichnung, die zu viel Platz einnimmt, führt zu Seitenüberschreitungen, was zu zusätzlichem Leistungsaufwand führt. Darüber hinaus lädt die Datenbank Daten in Zeileneinheiten in den Speicher, sodass die Feldlänge in der Tabelle kürzer und die Zugriffshäufigkeit höher ist. Der Speicher kann mehr Daten laden, die Trefferquote ist höher und die Festplatten-E/A ist höher reduziert und dadurch die Datenbankleistung verbessert.
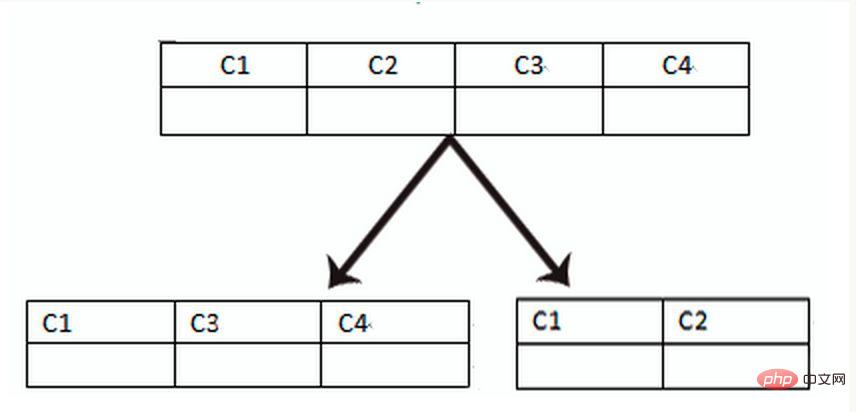
Vorteile der vertikalen Segmentierung:
1. Lösen Sie die Kopplung auf Geschäftssystemebene und machen Sie das Geschäft klar. 2. Ähnlich wie bei der Governance von Microservices kann auch eine hierarchische Verwaltung, Wartung und Überwachung durchgeführt werden Daten verschiedener Unternehmen, Erweiterung usw. 3. In Szenarien mit hoher Parallelität erhöht die vertikale Segmentierung den Engpass bei E/A, Datenbankverbindungen und Einzelmaschinen-Hardwareressourcen bis zu einem gewissen Grad
Nachteile:
1 verbunden werden und kann nur durch Schnittstellenaggregation gelöst werden. Verbesserung 2. Die Komplexität der verteilten Transaktionsverarbeitung. 3. Es besteht immer noch das Problem des übermäßigen Datenvolumens in einer einzelnen Tabelle (das eine horizontale Aufteilung erfordert). 2. Horizontal (horizontal). Slicing
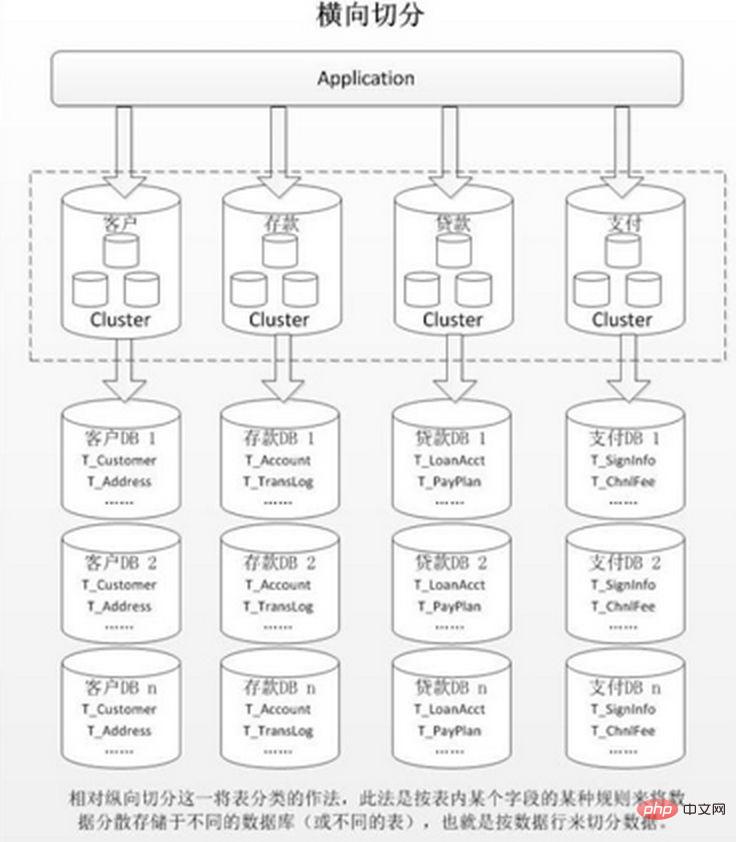
1. Es gibt keinen Leistungsengpass durch übermäßiges Datenvolumen und hohe Parallelität in einer einzelnen Datenbank, was die Systemstabilität und Ladekapazität verbessert. 2. Die anwendungsseitige Transformation ist gering müssen die Geschäftsmodule aufteilen
Nachteile:
1. Es ist schwierig, die Transaktionskonsistenz über Shards hinweg sicherzustellen. 3. Die mehrfache Erweiterung von Daten ist schwierig.
Nach dem horizontalen Slicing wird dies der Fall sein in mehreren Datenbanken/Tabellen erscheinen, ist der Inhalt jeder Bibliothek/Tabelle unterschiedlich. Einige typische Daten-Sharding-Regeln sind:
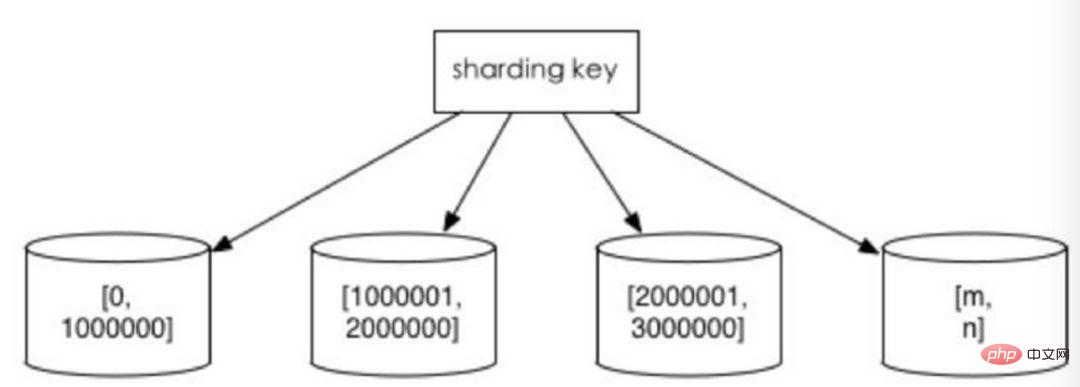
nach Zeitintervall oder ID-Intervall. Beispiel: Verteilen Sie Daten verschiedener Monate oder sogar Tage nach Datum in verschiedene Bibliotheken. Weisen Sie der ersten Bibliothek Datensätze mit Benutzer-IDs von 1 bis 9999 zu, der zweiten Bibliothek Datensätze mit Benutzer-IDs von 10.000 bis 20.000. In gewisser Weise ist die in einigen Systemen verwendete „Trennung heißer und kalter Daten“, bei der einige weniger genutzte historische Daten in andere Bibliotheken migriert werden und nur heiße Datenabfragen in Geschäftsfunktionen bereitgestellt werden, eine ähnliche Praxis.
Die Vorteile davon sind:
1. Die Größe einer einzelnen Tabelle ist kontrollierbar. 2. Es ist natürlich einfach, den gesamten Sharded-Cluster zu erweitern Es besteht keine Notwendigkeit, die Daten anderer Shards zu migrieren. 3. Bei der Verwendung von Shard-Feldern für die Bereichssuche kann das kontinuierliche Sharding Shards für schnelle Abfragen schnell finden und so Probleme bei Shard-übergreifenden Abfragen effektiv vermeiden.
Nachteile:
Hotspot-Daten werden zu einem Leistungsengpass. Kontinuierliches Sharding kann Daten-Hotspots aufweisen, z. B. Sharding nach Zeitfeldern. Einige Shards speichern Daten im letzten Zeitraum und werden möglicherweise häufig gelesen und geschrieben, während einige Shards historische Daten speichern, die selten abgefragt werden
Nachteile:
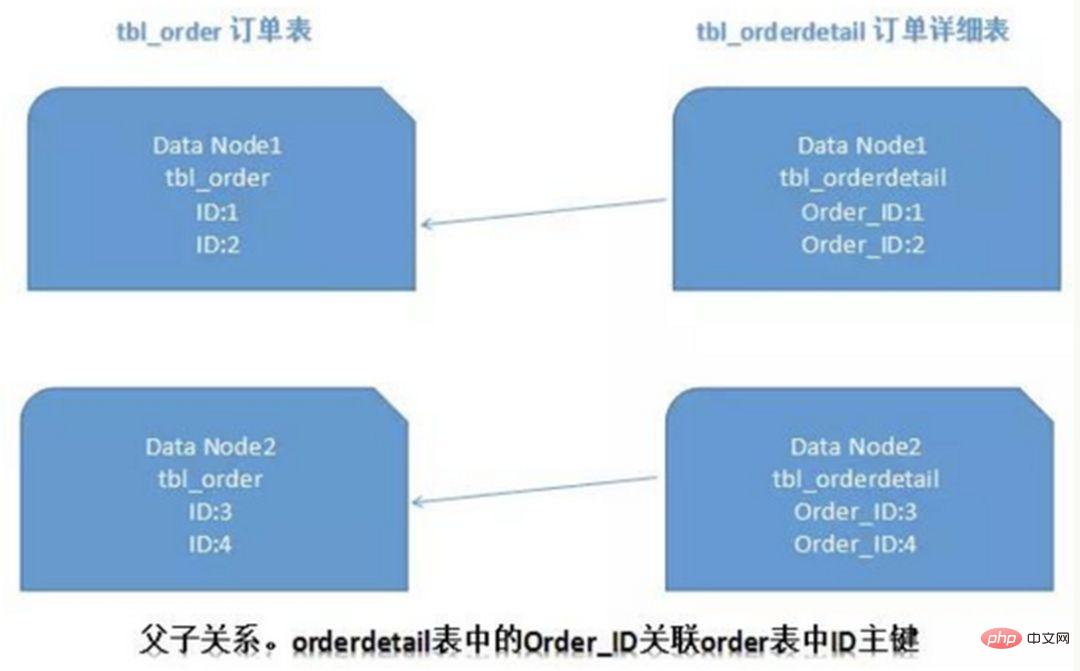
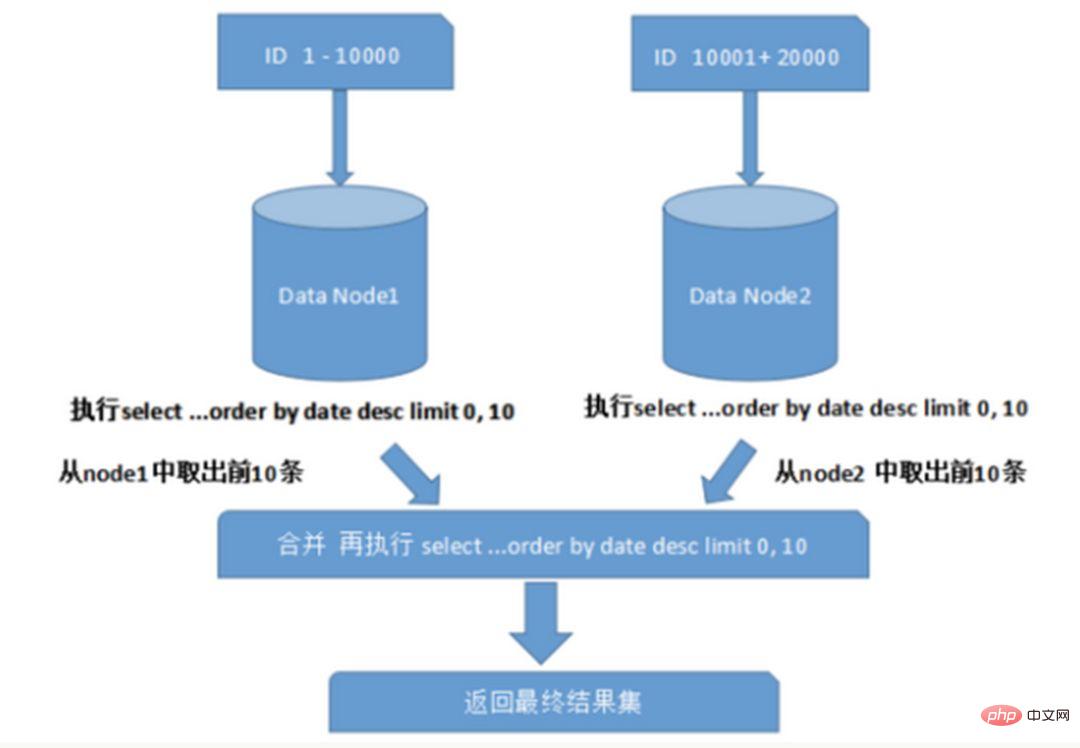
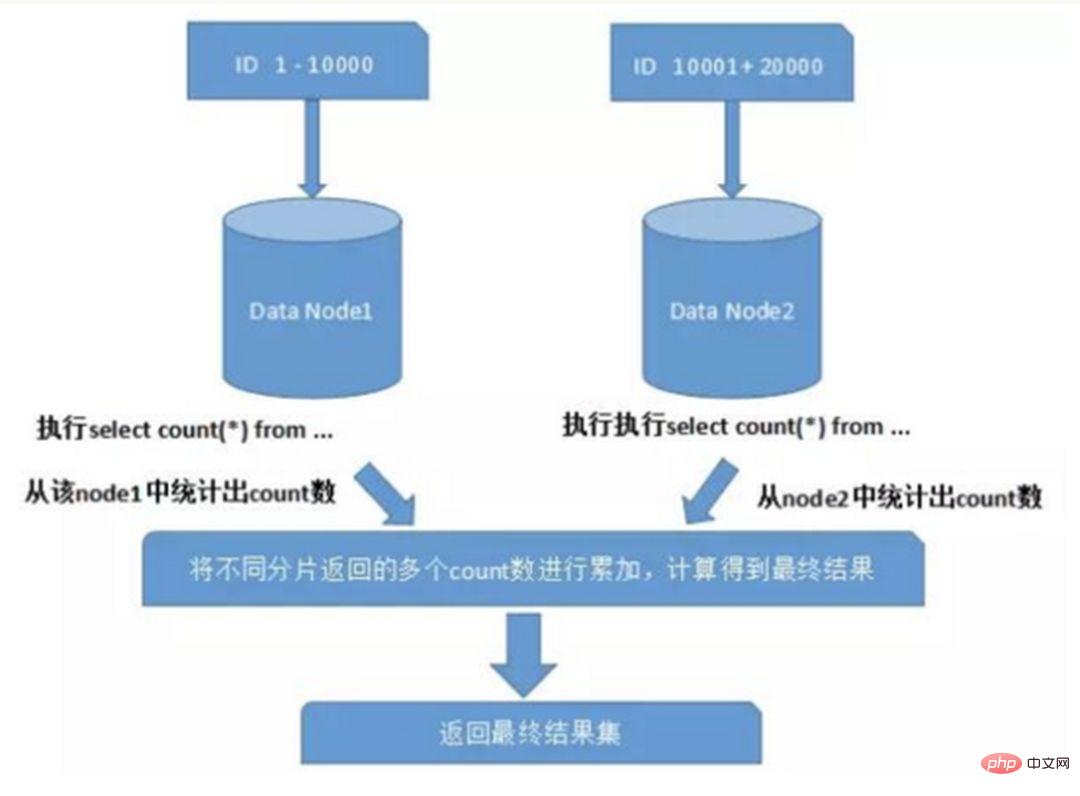
1. Wenn der Sharding-Cluster später erweitert wird, müssen alte Daten migriert werden (mit Ein konsistenter Hash-Algorithmus kann dieses Problem besser vermeiden.) 2. Es ist leicht, sich dem komplexen Problem der Cross-Shard-Abfrage zu stellen. Wenn beispielsweise im obigen Beispiel „cusno“ nicht in den häufig verwendeten Abfragebedingungen enthalten ist, wird die Datenbank nicht gefunden. Daher ist es erforderlich, Abfragen an vier Bibliotheken gleichzeitig zu initiieren und dann die Daten im Speicher zusammenzuführen , nehmen Sie den Mindestsatz und geben Sie ihn an die Anwendung zurück. Stattdessen wurde die Bibliothek zu einer Belastung. 2. Probleme, die durch Unterdatenbanken und Untertabellen verursacht werden Ein typisches Anti-Paradigmen-Design, das Raum für Zeit nutzt und Join-Abfragen für die Leistung vermeidet. Beispiel: Wenn die Bestelltabelle die Benutzer-ID speichert, wird auch eine redundante Kopie des Benutzernamens gespeichert, sodass beim Abfragen der Bestelldetails keine Abfrage der „Käuferbenutzertabelle“ erforderlich ist. Diese Methode verfügt jedoch nur über begrenzte anwendbare Szenarien und eignet sich eher für Situationen, in denen es nur wenige abhängige Felder gibt. Es ist auch schwierig, die Datenkonsistenz redundanter Felder sicherzustellen. Muss dieser, nachdem der Käufer den Benutzernamen geändert hat, in den historischen Bestellungen synchron aktualisiert werden? Dies sollte auch im Zusammenhang mit tatsächlichen Geschäftsszenarien betrachtet werden. Auf Systemebene gibt es zwei Abfragen. Die Ergebnisse der ersten Abfrage konzentrieren sich auf das Auffinden der zugehörigen Daten-ID und initiieren dann eine zweite Anfrage basierend auf der ID, um die zugehörige zu erhalten Daten. Abschließend werden die gewonnenen Daten in Felder zusammengestellt. Wenn Sie in einer relationalen Datenbank zunächst die Beziehung zwischen Tabellen bestimmen und diese zugehörigen Tabellendatensätze auf demselben Shard speichern können, ist dies besser So vermeiden Sie Probleme mit Cross-Shard-Joins. Im Fall von 1:1 oder 1:n erfolgt die Aufteilung üblicherweise nach dem ID-Primärschlüssel der Haupttabelle. Wie in der folgenden Abbildung dargestellt: Auf diese Weise können die Bestelltabelle und die Bestelldetail-Bestelldetailtabelle auf Datenknoten1 teilweise über orderId mit der Abfrage verknüpft werden, und das Gleiche gilt für Datenknoten2. Bei Abfragen über mehrere Knoten und mehrere Datenbanken hinweg können Probleme wie die Begrenzung von Paging und Reihenfolge nach Sortierung auftreten. Wenn das Sortierfeld ein Sharding-Feld ist, ist es einfacher, den angegebenen Shard anhand der Sharding-Regeln zu finden. Wenn das Sortierfeld kein Sharding-Feld ist, wird es komplizierter. Die Daten müssen zuerst in verschiedenen Shard-Knoten sortiert und zurückgegeben werden. Anschließend werden die von verschiedenen Shards zurückgegebenen Ergebnismengen zusammengefasst und erneut sortiert und schließlich an den Benutzer zurückgegeben. Wie im Bild gezeigt: Das obige Bild übernimmt nur die Daten der ersten Seite, was keinen großen Einfluss auf die Leistung hat. Wenn jedoch die Anzahl der erhaltenen Seiten sehr groß ist, wird die Situation viel komplizierter, da die Daten in jedem Shard-Knoten zufällig sein können. Für die Genauigkeit der Sortierung müssen die ersten N Datenseiten aller Knoten sortiert werden Abschließend wird die Gesamtsortierung durchgeführt, sodass CPU- und Speicherressourcen verbraucht werden. Je größer die Anzahl der Seiten, desto schlechter wird die Systemleistung. Wenn Sie Funktionen wie Max, Min, Sum und Count zur Berechnung verwenden, müssen Sie auch zuerst die entsprechende Funktion auf jedem Shard ausführen, dann die Ergebnissätze jedes Shards zusammenfassen und erneut berechnen, und schließlich werden die Ergebnisse zurückgegeben. Wie im Bild gezeigt: 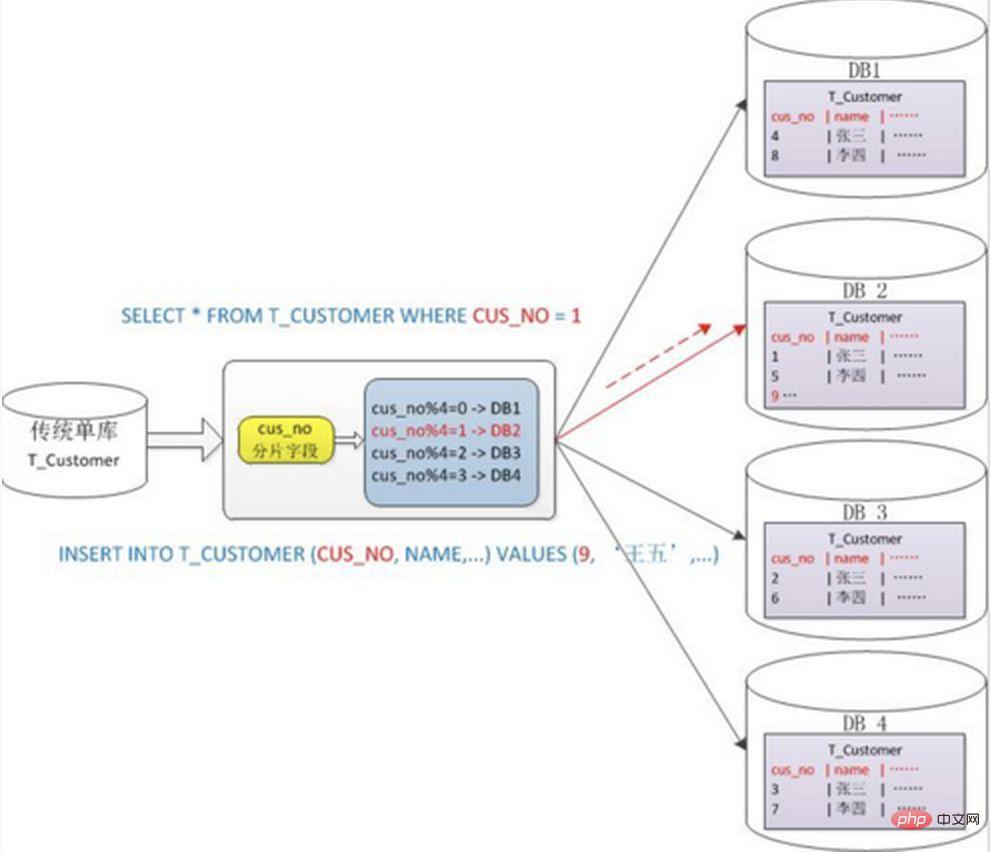 und Netzwerk-E/A und Hardware durchbrechen. Der Engpass an Ressourcen und der Anzahl der Verbindungen bringt auch einige Probleme mit sich. Diese technischen Herausforderungen und entsprechende Lösungen werden im Folgenden beschrieben.
und Netzwerk-E/A und Hardware durchbrechen. Der Engpass an Ressourcen und der Anzahl der Verbindungen bringt auch einige Probleme mit sich. Diese technischen Herausforderungen und entsprechende Lösungen werden im Folgenden beschrieben.
Verteilte Transaktionen
Wenn aktualisierte Inhalte gleichzeitig in verschiedenen Bibliotheken verteilt werden, treten zwangsläufig Probleme mit datenbankübergreifenden Transaktionen auf. Cross-Shard-Transaktionen sind ebenfalls verteilte Transaktionen, und es gibt keine einfache Lösung. Im Allgemeinen können sie mit dem „XA-Protokoll“ und dem „Zwei-Phasen-Commit“ verarbeitet werden.
Endgültige Konsistenz
2. Knotenübergreifendes Abfrageverknüpfungsproblem
1) Globale Tabelle
2) Feldredundanz
3) Datenassemblierung
4) ER-Sharding
3. Knotenübergreifende Paging-, Sortier- und Funktionsprobleme
1) UUID
2) Kombiniert mit der Datenbank zur Pflege der Primärschlüssel-ID-Tabelle
Das Stub-Feld wird als eindeutiger Index festgelegt. Derselbe Stub-Wert hat nur einen Datensatz in der Sequenztabelle und kann für mehrere Tabellen gleichzeitig verwendet werden. Der Inhalt der Sequenztabelle lautet wie folgt: CREATE TABLE `sequence` ( `id` bigint(20) unsigned NOT NULL auto_increment, `stub` char(1) NOT NULL default '', PRIMARY KEY (`id`), UNIQUE KEY `stub` (`stub`) ) ENGINE=MyISAM;
+-------------------+------+ | id | stub | +-------------------+------+ | 72157623227190423 | a | +-------------------+------+
REPLACE INTO sequence (stub) VALUES ('a'); SELECT LAST_INSERT_ID();
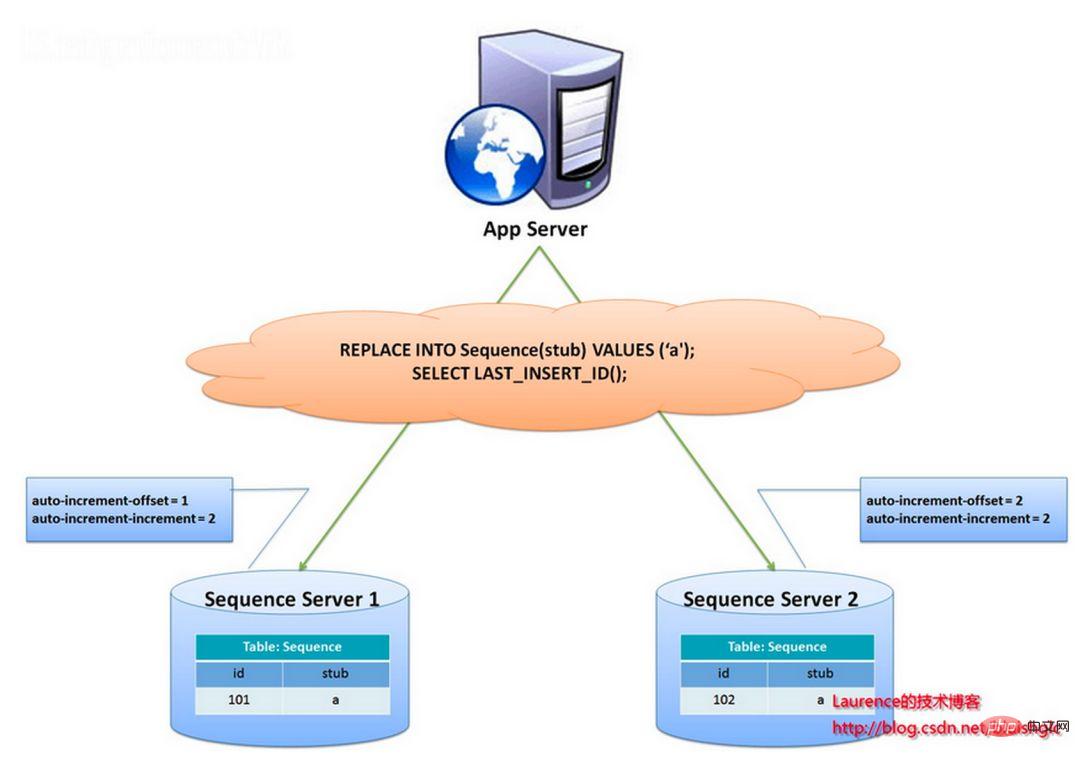
Die ID wird von zwei Datenbankservern generiert und es werden unterschiedliche auto_increment-Werte festgelegt. Der Startwert der ersten Sequenz ist 1 und jeder Schritt erhöht sich um 2. Der Startwert der anderen Sequenz ist 2 und jeder Schritt erhöht sich um 2. Infolgedessen sind die von der ersten Station generierten IDs alle ungerade Zahlen (1, 3, 5, 7 ...) und die von der zweiten Station generierten IDs sind alle gerade Zahlen (2, 4, 6, 8 ...). .).
Diese Lösung verteilt den Druck der ID-Generierung gleichmäßig auf die beiden Maschinen. Es bietet außerdem Systemfehlertoleranz, wenn auf der ersten Maschine ein Fehler auftritt, kann automatisch auf die zweite Maschine umgeschaltet werden, um die ID zu erhalten. Es hat jedoch die folgenden Nachteile: Beim Hinzufügen von Maschinen zum System ist die horizontale Erweiterung jedes Mal komplizierter, und der Druck auf die Datenbank ist immer noch sehr hoch kann nur durch den Einsatz von Heap-Maschinen verbessert werden.
Sie können die Optimierung basierend auf der Flickr-Lösung fortsetzen, Batch-Methoden verwenden, um den Schreibdruck der Datenbank zu reduzieren, jedes Mal eine Reihe von ID-Nummernsegmenten abrufen und diese dann nach der Verwendung in der Datenbank abrufen, was die Reduzierung erheblich reduzieren kann der Druck auf die Datenbank. Wie in der folgenden Abbildung dargestellt:
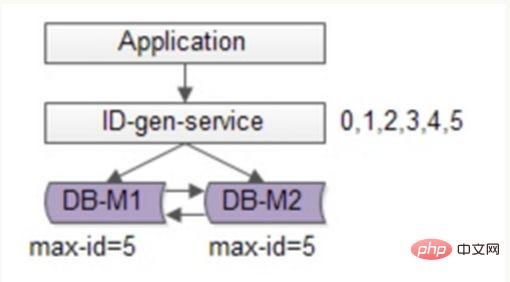
Um die Verfügbarkeit sicherzustellen, werden immer noch zwei DBs verwendet. In der Datenbank wird nur die aktuelle maximale ID gespeichert. Der ID-Generierungsdienst ruft jedes Mal 6 IDs in Stapeln ab und ändert zunächst die Maxi-ID auf 5. Wenn die Anwendung auf den ID-Generierungsdienst zugreift, muss sie nicht auf die Datenbank zugreifen, und die IDs 0 bis 5 werden nacheinander aus dem Nummernsegment versendet Cache. Nachdem diese IDs ausgegeben wurden, ändern Sie die maximale ID auf 11, und die IDs 6 bis 11 können beim nächsten Mal verteilt werden. Dadurch wird der Druck auf die Datenbank auf 1/6 des Originals reduziert.
Der Snowflake-Algorithmus von Twitter löst die Notwendigkeit für verteilte Systeme, globale IDs zu generieren, indem er eine 64-Bit-Long-Nummer generiert:
Die erste Ziffer wird nicht verwendet
Die nächsten 41 Bits entsprechen der Zeit auf Millisekundenebene, und die Länge von 41 Bits kann 69 Jahre Zeit darstellen
5-stellige Datencenter-ID, 5-stellige Worker-ID. Die 10-Bit-Länge unterstützt den Einsatz von bis zu 1024 Knoten. Die letzten 12 Bits sind Zählungen innerhalb von Millisekunden, und die 12-Bit-Zählsequenznummer unterstützt jeden Knoten dabei, 4096 ID-Sequenzen pro Millisekunde zu generieren Der Vorteil ist: Die Anzahl der Millisekunden ist hoch und die generierten IDs steigen im Allgemeinen entsprechend dem Zeittrend an. Es ist nicht auf Systeme von Drittanbietern angewiesen und die QPS beträgt theoretisch etwa 409,6 W /s (1000*2^12) und die gesamte Verteilung Es wird keine ID-Kollision im System geben; Bits können entsprechend dem eigenen Geschäft flexibel zugewiesen werden.
Der Nachteil besteht darin, dass es stark von der Maschinenuhr abhängt. Wenn die Uhr zurückgestellt wird, kann es zu einer doppelten ID-Generierung kommen.
Durch die Kombination der Datenbank und der einzigartigen ID-Lösung von Snowflake können Sie auf die ausgereiftere Lösung der Branche zurückgreifen: Leaf – das verteilte ID-Generierungssystem von Meituan-Dianping, das Hochverfügbarkeit, Notfallwiederherstellung usw. berücksichtigt verteilte Bereitstellung und andere Probleme.
Wenn sich das Unternehmen schnell entwickelt und mit Leistungs- und Speicherengpässen konfrontiert ist, ist es unumgänglich, das Problem der historischen Datenmigration in Betracht zu ziehen. Der allgemeine Ansatz besteht darin, zuerst die historischen Daten zu lesen und die Daten dann gemäß den angegebenen Sharding-Regeln auf jeden Shard-Knoten zu schreiben. Darüber hinaus muss eine Kapazitätsplanung auf der Grundlage des aktuellen Datenvolumens und der QPS sowie der Geschwindigkeit der Geschäftsentwicklung durchgeführt werden, um die ungefähre Anzahl der erforderlichen Shards zu berechnen (im Allgemeinen wird empfohlen, das Datenvolumen einer einzelnen Tabelle anzugeben). Ein einzelner Shard überschreitet nicht 1000 W.)
Wenn die numerische Bereichsanalyse für Shards verwendet wird, müssen Sie zum Erweitern nur Knoten hinzufügen, und es besteht keine Notwendigkeit, Shard-Daten zu migrieren. Wenn numerisches Modulo-Sharding verwendet wird, ist es relativ mühsam, spätere Erweiterungsprobleme zu berücksichtigen.
Lassen Sie uns darüber sprechen, wann Sie eine Datensegmentierung in Betracht ziehen sollten.
Nicht alle Tabellen müssen aufgeteilt werden, dies hängt hauptsächlich von der Wachstumsrate der Daten ab. Die Segmentierung wird die Komplexität des Unternehmens bis zu einem gewissen Grad erhöhen. Neben der Datenspeicherung und -abfrage ist die Datenbank auch eine ihrer wichtigen Aufgaben, um das Unternehmen bei der besseren Umsetzung seiner Anforderungen zu unterstützen.
Verwenden Sie den Trick der Unterdatenbank und Untertabelle nicht, es sei denn, dies ist unbedingt erforderlich, um „Überdesign“ und „vorzeitige Optimierung“ zu vermeiden. Bevor Sie Datenbanken und Tabellen aufteilen, sollten Sie nicht nur um der Aufteilung willen versuchen, zuerst das zu tun, was Sie können, z. B. die Hardware zu aktualisieren, das Netzwerk zu aktualisieren, Lese- und Schreibvorgänge zu trennen, den Index zu optimieren usw. Wenn die Datenmenge den Engpass einer einzelnen Tabelle erreicht, sollten Sie das Sharding von Datenbanken und Tabellen in Betracht ziehen.
2) Bei DDL-Änderungen an einer großen Tabelle wird MySQL dies tun Sperren Sie die gesamte Tabelle. In diesem Zeitraum kann das Unternehmen nicht auf diese Tabelle zugreifen, was große Auswirkungen haben wird. Wenn Sie pt-online-schema-change verwenden, werden während der Nutzung Trigger und Schattentabellen erstellt, was ebenfalls viel Zeit in Anspruch nimmt. Während dieser Operation wird sie als Risikozeit gezählt. Durch Aufteilen der Datentabelle und Reduzieren des Gesamtbetrags kann dieses Risiko verringert werden.
3)大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
举个例子,假如项目一开始设计的用户表如下:
id bigint #用户的IDname varchar #用户的名字last_login_time datetime #最近登录时间personal_info text #私人信息..... #其他信息字段
在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 lastloginname 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personalinfo 是不变的或很少更新的,此时在业务角度,就要将 lastlogintime 拆分出去,新建一个 usertime 表。
personalinfo 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 userext 表了。
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
鸡蛋不要放在一个篮子里。在业务层面上垂直切分,将不相关的业务的数据库分隔,因为每个业务的数据量、访问量都不同,不能因为一个业务把数据库搞挂而牵连到其他业务。利用水平切分,当一个数据库出现问题时,不会影响到100%的用户,每个库只承担业务的一部分数据,这样整体的可用性就能提高。
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
User(uid, login_name, passwd, sex, age, nickname) uid为用户ID, 主键login_name, passwd, sex, age, nickname, 用户属性
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
1. Benutzeranmeldung: Benutzerinformationen über Anmeldename/Telefon/E-Mail abfragen, 1 % der Anfragen gehören zu diesem Typ 2. Benutzerinformationsabfrage: Nach der Anmeldung Benutzerinformationen über UID abfragen, 99 % der Anfragen gehören zu diesem TypVorgang side: Backend-Zugriff, unterstützt betriebliche Anforderungen und führt Paging-Abfragen basierend auf Alter, Geschlecht, Anmeldezeit, Registrierungszeit usw. durch. Es handelt sich um ein internes System mit geringem Zugriffsvolumen und geringen Anforderungen an Verfügbarkeit und Konsistenz.
Wenn die Datenmenge immer größer wird, muss die Datenbank horizontal segmentiert werden. Zu den oben beschriebenen Segmentierungsmethoden gehören „basierend auf dem numerischen Bereich“ und „basierend auf dem numerischen Modul“. ".
"Nach numerischem Bereich": Basierend auf der Primärschlüssel-UID werden die Daten entsprechend dem UID-Bereich horizontal in mehrere Datenbanken unterteilt. Beispiel: Benutzer-db1 speichert Daten mit UID-Bereichen von 0 bis 1000w und Benutzer-db2 speichert Daten mit UID-Bereichen von 1000w bis 2000wuid.
Der Vorteil ist: Die Erweiterung ist einfach, wenn die Kapazität nicht ausreicht, fügen Sie einfach eine neue Datenbank hinzu.
Der Nachteil ist : Das Anforderungsvolumen ist im Allgemeinen ungleichmäßig, neu registrierte Benutzer sind aktiver, sodass der neue Benutzer-db2 eine höhere Auslastung hat als Benutzer-db1, was zu einer unausgewogenen Serverauslastung führt
"Demnach zum numerischen Wert Modul ": Die Primärschlüssel-UID wird auch als Grundlage für die Aufteilung verwendet, und die Daten werden basierend auf dem Wertmodulo der UID horizontal in mehrere Datenbanken unterteilt. Beispiel: Benutzer-DB1 speichert UID-Daten Modulo 1, Benutzer-DB2 speichert UID-Daten Modulo 0.
Die Vorteile sind : Das Datenvolumen und das Anforderungsvolumen sind gleichmäßig verteilt.
Die Nachteile sind : Die Erweiterung ist mühsam. Wenn die Kapazität nicht ausreicht, ist ein erneutes Aufwärmen erforderlich. Eine reibungslose Migration der Daten muss berücksichtigt werden.
Nach der horizontalen Segmentierung kann die Nachfrage nach UID gut befriedigt und direkt an eine bestimmte Datenbank weitergeleitet werden. Bei Abfragen, die auf Nicht-UID basieren, wie z. B. login_name, ist nicht bekannt, auf welche Bibliothek zugegriffen werden soll. In diesem Fall müssen alle Bibliotheken durchlaufen werden, was die Leistung erheblich verringert.
Für die Benutzerseite kann die Lösung „Einrichten einer Zuordnungsbeziehung von Nicht-UID-Attributen zu UID“ übernommen werden, für die Betriebsseite kann die Lösung „Trennung von Front-End und Back-End“ übernommen werden.
1) Zuordnungsbeziehung
Zum Beispiel: Anmeldename kann nicht direkt in der Datenbank gefunden werden, er kann erstellt login_name→uid的映射关系 und in einer Indextabelle gespeichert werden oder Cache. Wenn Sie auf den Anmeldenamen zugreifen, fragen Sie zuerst die dem Anmeldenamen entsprechende UID über die Zuordnungstabelle ab und suchen Sie dann die spezifische Bibliothek über die UID.
Die Zuordnungstabelle hat nur zwei Spalten und kann viele Daten enthalten. Wenn die Datenmenge zu groß ist, kann die Zuordnungstabelle auch horizontal geteilt werden. Diese Art der Indexstruktur im KV-Format kann den Cache verwenden, um die Abfrageleistung zu optimieren. Die Zuordnungsbeziehung ändert sich nicht häufig und die Cache-Trefferquote ist sehr hoch. 2) Genmethode Welche Bibliothek sich darin befindet, dann können diese 3 Bits als Unterbibliotheksgene betrachtet werden.
Die obige Zuordnungsbeziehungsmethode erfordert zusätzlichen Speicher der Zuordnungstabelle. Bei Abfragen nach Nicht-UID-Feldern ist ein zusätzlicher Datenbank- oder Cache-Zugriff erforderlich. Wenn Sie redundante Speicherung und Abfragen eliminieren möchten, können Sie die f-Funktion verwenden, um das Loginname-Gen als Unterbibliotheksgen von uid zu verwenden. Beziehen Sie sich beim Generieren der UID auf das oben beschriebene Schema zur verteilten eindeutigen ID-Generierung plus die letzten drei Bitwerte = f (Anmeldename). Wenn Sie den Anmeldenamen abfragen, müssen Sie nur den Wert von f(Anmeldename)%8 berechnen, um die spezifische Bibliothek zu finden. Dafür ist jedoch eine Kapazitätsplanung im Vorfeld erforderlich, die Abschätzung, in wie viele Datenbanken das Datenvolumen in den nächsten Jahren aufgeteilt werden muss, und die Reservierung einer bestimmten Anzahl an Bits von Datenbankgenen.
Diese Art von Geschäft eignet sich am besten für die Lösung „Trennung von Front-End und Back-End“. Das Back-End-Geschäft auf der Betriebsseite extrahiert unabhängige Dienste und DBs, um die Kopplung mit dem Front-End-Geschäftssystem zu lösen. Da die Betriebsseite keine hohen Anforderungen an Verfügbarkeit und Konsistenz stellt, ist es möglich, nicht auf die Echtzeitbibliothek zuzugreifen, sondern die Daten für den Zugriff über Binlog asynchron mit der Betriebsbibliothek zu synchronisieren. Wenn die Datenmenge groß ist, können Sie auch die ES-Suchmaschine oder Hive verwenden, um die komplexen Abfragemethoden im Hintergrund zu erfüllen. 5. Unterstützt Unterdatenbanken und Untertabellen-Middleware -Tabelle:
Das obige ist der detaillierte Inhalt vonWann wird die Datenbank in Datenbanken und Tabellen unterteilt? Wie teilen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Datenbank drei Paradigmen
Datenbank drei Paradigmen
 So löschen Sie eine Datenbank
So löschen Sie eine Datenbank
 So stellen Sie eine Verbindung zur Datenbank in VB her
So stellen Sie eine Verbindung zur Datenbank in VB her
 MySQL-Datenbank wiederherstellen
MySQL-Datenbank wiederherstellen
 So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
So stellen Sie eine Verbindung zum Zugriff auf die Datenbank in VB her
 So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
So lösen Sie das Problem eines ungültigen Datenbankobjektnamens
 So verbinden Sie VB mit dem Zugriff auf die Datenbank
So verbinden Sie VB mit dem Zugriff auf die Datenbank
 So stellen Sie mit vb eine Verbindung zur Datenbank her
So stellen Sie mit vb eine Verbindung zur Datenbank her









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



