
 Technologie-Peripheriegeräte
KI
Eingehende Analyse: Schlüsselkomponenten und Funktionen im AI LLM-Framework
Technologie-Peripheriegeräte
KI
Eingehende Analyse: Schlüsselkomponenten und Funktionen im AI LLM-Framework
Eingehende Analyse: Schlüsselkomponenten und Funktionen im AI LLM-Framework


Dieser Artikel befasst sich eingehend mit der High-Level-Architektur eines Frameworks für künstliche Intelligenz und analysiert seine internen Komponenten und ihre Funktionen im Gesamtsystem. Dieses KI-Framework soll die Kombination traditioneller Software mit großen Sprachmodellen (LLMs) erleichtern.
Der Hauptzweck besteht darin, Entwicklern eine Reihe von Tools zur Verfügung zu stellen, die ihnen helfen, künstliche Intelligenz reibungslos in bereits im Unternehmen verwendete Software zu integrieren. Diese innovative Strategie hat für uns eine Softwareplattform geschaffen, die viele KI-Anwendungen und intelligente Agenten gleichzeitig ausführen und so hochwertigere und komplexere Lösungen realisieren kann.
1. Anwendungsbeispiele des KI-Frameworks
Um ein tieferes Verständnis der Fähigkeiten dieses Frameworks zu erhalten, finden Sie hier einige Anwendungsbeispiele, die mit diesem Framework entwickelt werden können:
- AI Sales Assistant: Dies ist ein Automatische Tools zur Suche nach potenziellen Kunden, zur Analyse ihrer Geschäftsanforderungen und zur Ausarbeitung von Vorschlägen für Ihr Vertriebsteam. Ein solcher KI-Assistent wird effektive Wege finden, um mit Zielkunden in Kontakt zu treten und den ersten Schritt zum Verkauf zu eröffnen.
- AI Real Estate Research Assistant: Dieses Tool kann kontinuierlich neue Angebote auf dem Immobilienmarkt überwachen und qualifizierte Angebote anhand bestimmter Kriterien überprüfen. Darüber hinaus kann es Kommunikationsstrategien entwerfen, weitere Informationen über eine bestimmte Immobilie sammeln und Nutzer in allen Aspekten des Hauskaufs unterstützen.
- AI Zhihu Diskussionszusammenfassungs-AppDiese intelligente App sollte in der Lage sein, Diskussionen über Zhihu zu analysieren und Schlussfolgerungen, Aufgaben und nächste Schritte zu extrahieren, die unternommen werden müssen.
2. KI-Framework-Modul
Das KI-Framework sollte Entwicklern eine Reihe verschiedener Module zur Verfügung stellen, einschließlich Vertragsdefinitionen, Schnittstellen und Implementierungen gängiger Abstraktionen.
Diese Lösung sollte eine solide Grundlage sein, auf der Sie Ihre eigenen Lösungen aufbauen können, indem Sie bewährte Muster verwenden, Ihre eigenen Implementierungen einzelner Module hinzufügen oder von der Community vorbereitete Module verwenden.
- Das Hints and Chaining-Modul ist für die Erstellung von Hints verantwortlich, d. h. für Sprachmodelle geschriebene Programme, und Aufrufketten zu diesen Hinweisen, die nacheinander nacheinander ausgeführt werden. Dieses Modul soll es ermöglichen, verschiedene Techniken zu implementieren, die in Sprachmodellen (LM) und großen Sprachmodellen (LLM) verwendet werden. Es sollte auch in der Lage sein, Eingabeaufforderungen mit Modellen zu kombinieren und Eingabeaufforderungsgruppen zu erstellen, die eine einzelne Funktionalität über mehrere LLM-Modelle hinweg bereitstellen. Das
- Modellmodul ist für die Verarbeitung und Anbindung des LLM-Modells an die Software verantwortlich und stellt es anderen Teilen des Systems zur Verfügung. Das
- Kommunikationsmodul ist für die Handhabung und das Hinzufügen neuer Kommunikationskanäle mit Benutzern verantwortlich, sei es in Form von Chats in einem der Messaging-Programme oder in Form von APIs und Webhooks zur Integration mit anderen Systemen. Das
- Tools-Modul ist für die Bereitstellung von Funktionen zum Hinzufügen von Tools verantwortlich, die von KI-Anwendungen verwendet werden, z. B. die Möglichkeit, den Inhalt einer Website über einen Link zu lesen, eine PDF-Datei zu lesen, online nach Informationen zu suchen oder eine E-Mail zu senden.
- Das Speichermodul sollte für die Speicherverwaltung verantwortlich sein und das Hinzufügen zusätzlicher Speicherfunktionsimplementierungen für KI-Anwendungen ermöglichen, wobei der aktuelle Status, Daten und aktuell ausgeführte Aufgaben gespeichert werden.
- WissensbasismodulDieses Modul sollte für die Verwaltung von Zugriffsrechten verantwortlich sein und das Hinzufügen neuer Quellen für organisatorisches Wissen ermöglichen, wie z. B. Informationen über Prozesse, Dokumente, Anleitungen und alle elektronisch erfassten Informationen in der Organisation.
- Routing-ModulDieses Modul sollte für die Weiterleitung externer Informationen vom Kommunikationsmodul an die entsprechende KI-Anwendung verantwortlich sein. Seine Aufgabe besteht darin, die Absicht des Benutzers zu ermitteln und die richtige Anwendung zu starten. Wenn die Anwendung zuvor gestartet wurde und den Vorgang noch nicht abgeschlossen hat, sollte sie fortgesetzt werden und Daten vom Kommunikationsmodul weiterleiten.
- KI-AnwendungsmodulDieses Modul sollte das Hinzufügen spezialisierter KI-Anwendungen ermöglichen, die sich auf die Ausführung bestimmter Aufgaben konzentrieren, wie z. B. die Automatisierung oder Teilautomatisierung von Prozessen. Eine Beispiellösung könnte eine Slack- oder Teams-Chatzusammenfassungsanwendung sein. Eine solche Anwendung kann eine oder mehrere miteinander verknüpfte Eingabeaufforderungen umfassen, die Tools und Speicher nutzen und Informationen aus einer Wissensdatenbank nutzen.
- AI-Agent-ModulDieses Modul sollte fortgeschrittenere Versionen von Anwendungen enthalten, die autonom mit dem LLM-Modell kommunizieren und zugewiesene Aufgaben automatisch oder halbautomatisch ausführen können.
- Modul „Verantwortung und Transparenz“Das Modul „Verantwortung und Transparenz“ zeichnet alle Interaktionen zwischen Benutzern und KI-Systemen auf. Es verfolgt Abfragen, Antworten, Zeitstempel und Urheberschaft, um zwischen von Menschen generierten und von KI generierten Inhalten zu unterscheiden. Diese Protokolle bieten Einblick in autonome Aktionen der KI und Nachrichten zwischen dem Modell und der Software.
- BenutzermodulZusätzlich zu den grundlegenden Benutzerverwaltungsfunktionen sollte dieses Modul auch die Zuordnung von Benutzerkonten über integrierte Systeme aus verschiedenen Modulen hinweg verwalten.
- BerechtigungsmodulDieses Modul sollte Benutzerberechtigungsinformationen speichern und den Benutzerzugriff auf Ressourcen steuern, um sicherzustellen, dass sie nur auf geeignete Ressourcen und Anwendungen zugreifen können.
3. AI-Framework-Komponentenarchitektur
Um die Interaktion zwischen verschiedenen Modulen in der AI-Framework-Architektur besser zu veranschaulichen, finden Sie im Folgenden eine Übersicht über ein Komponentendiagramm:
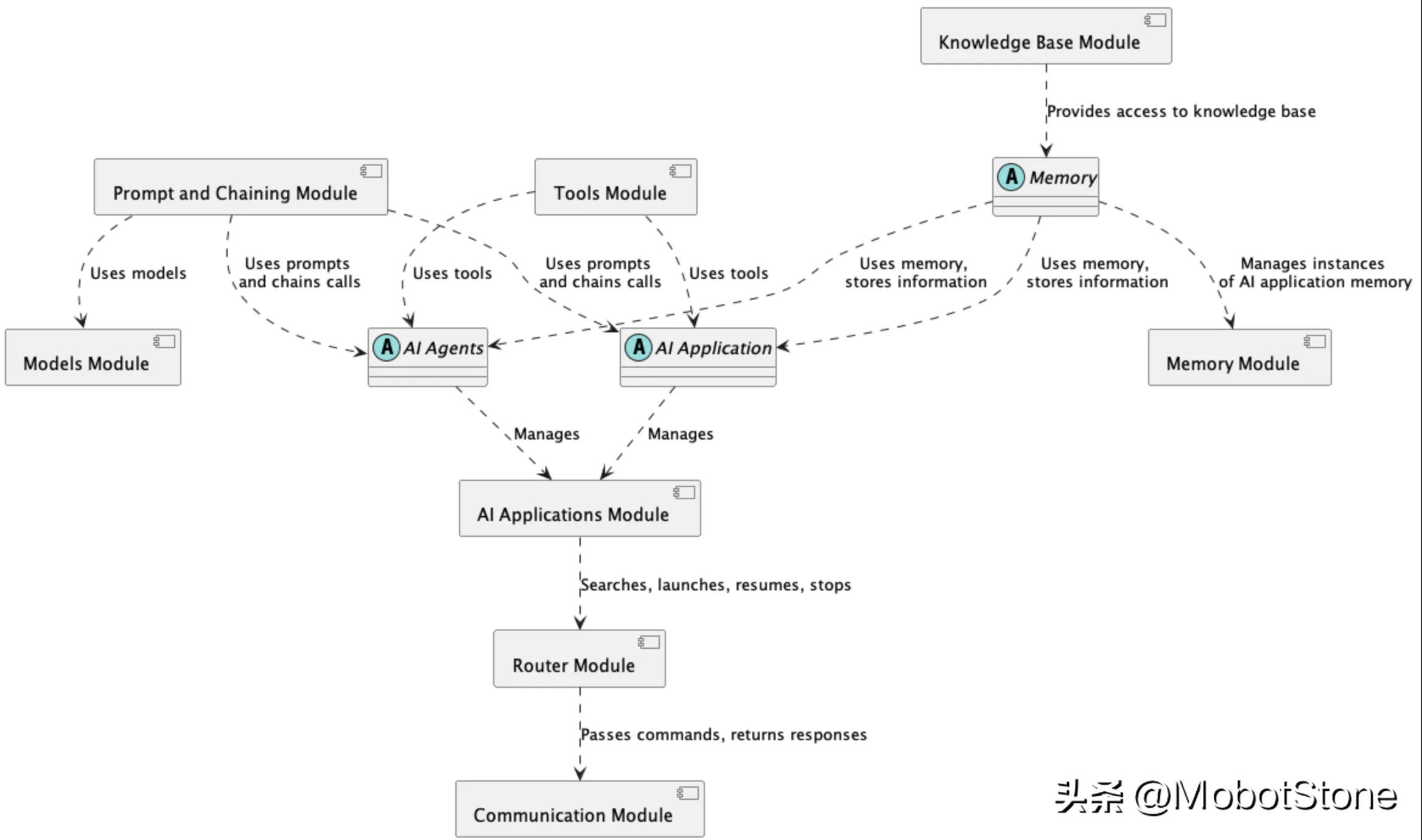
Dieses Diagramm zeigt die Beziehung zwischen den Schlüsseln Komponenten des Frameworks Beziehungen:
- Eingabeaufforderungen und verkettete Module: Erstellen Sie Eingabeaufforderungen für KI-Modelle und verketten Sie mehrere Eingabeaufforderungen durch verkettete Aufrufe, um eine komplexere Logik zu erreichen.
- Speichermodul: Speicherverwaltung durch Speicherabstraktion. Das Wissensdatenbankmodul bietet Zugriff auf Wissensquellen.
- Tool-Modul: Stellt Tools bereit, die von KI-Anwendungen und -Agenten verwendet werden können.
- Routing-Modul: Direkte Abfragen an entsprechende KI-Anwendungen. Bewerbungen werden im KI-Bewerbungsmodul verwaltet.
- Kommunikationsmodul: Verwaltet Kommunikationskanäle wie Chat.
Diese Komponentenarchitektur zeigt, wie verschiedene Module zusammenarbeiten, um den Aufbau komplexer KI-Lösungen zu ermöglichen. Der modulare Aufbau ermöglicht eine einfache Erweiterung der Funktionalität durch Hinzufügen neuer Komponenten.
4. Moduldynamisches Beispiel
Um die Zusammenarbeit zwischen KI-Framework-Modulen zu veranschaulichen, analysieren wir einen typischen Informationsverarbeitungspfad im System:
- Benutzer sendet eine Anfrage über die Chat-Funktion über das Kommunikationsmodul.
- Das Routing-Modul analysiert den Inhalt und ermittelt aus dem Anwendungsmodul die passende KI-Anwendung.
- Die Anwendung ruft die erforderlichen Daten aus dem Speichermodul ab, um den Konversationskontext wiederherzustellen.
- Als nächstes erstellt es mithilfe des Befehlsmoduls die entsprechenden Befehle und übergibt sie vom Modellmodul an das KI-Modell.
- Bei Bedarf werden die Tools im Tools-Modul ausgeführt, z. B. die Online-Suche nach Informationen.
- Schließlich gibt es über das Kommunikationsmodul eine Antwort an den Benutzer zurück.
- Wichtige Informationen werden im Speichermodul gespeichert, um das Gespräch fortzusetzen.
Dank dieser Funktionsweise sollen Framework-Module in der Lage sein, miteinander zusammenzuarbeiten, um KI-Anwendungen und Agenten die Umsetzung komplexer Szenarien zu ermöglichen.
5. Zusammenfassung
Das KI-Framework sollte umfassende Werkzeuge für den Aufbau moderner KI-basierter Systeme bereitstellen. Seine flexible, modulare Architektur sollte eine einfache Erweiterung der Funktionalität und Integration in die vorhandene Software eines Unternehmens ermöglichen. Dank KI-Frameworks sollen Programmierer in der Lage sein, mithilfe von Sprachmodellen schnell eine Vielzahl innovativer Lösungen zu entwerfen und umzusetzen. Mit vorgefertigten Modulen sollen sie sich auf Geschäftslogik und Anwendungsfunktionalität konzentrieren können. Dadurch ist es möglich, dass KI-Frameworks die digitale Transformation vieler Organisationen deutlich beschleunigen.
Das obige ist der detaillierte Inhalt vonEingehende Analyse: Schlüsselkomponenten und Funktionen im AI LLM-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum verwenden große Sprachmodelle SwiGLU als Aktivierungsfunktion?
Apr 08, 2024 pm 09:31 PM
Warum verwenden große Sprachmodelle SwiGLU als Aktivierungsfunktion?
Apr 08, 2024 pm 09:31 PM
Wenn Sie sich mit der Architektur großer Sprachmodelle befasst haben, ist Ihnen möglicherweise der Begriff „SwiGLU“ in den neuesten Modellen und Forschungsarbeiten aufgefallen. Man kann sagen, dass SwiGLU die am häufigsten verwendete Aktivierungsfunktion in großen Sprachmodellen ist. Wir werden sie in diesem Artikel ausführlich vorstellen. SwiGLU ist eigentlich eine von Google im Jahr 2020 vorgeschlagene Aktivierungsfunktion, die die Eigenschaften von SWISH und GLU kombiniert. Der vollständige chinesische Name von SwiGLU lautet „bidirektionale Gated Linear Unit“. Es optimiert und kombiniert zwei Aktivierungsfunktionen, SWISH und GLU, um die nichtlineare Ausdrucksfähigkeit des Modells zu verbessern. SWISH ist eine sehr häufige Aktivierungsfunktion, die in großen Sprachmodellen weit verbreitet ist, während GLU bei Aufgaben zur Verarbeitung natürlicher Sprache eine gute Leistung gezeigt hat.
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Mar 01, 2024 pm 09:16 PM
Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Mar 01, 2024 pm 09:16 PM
Da sich die Leistung groß angelegter Open-Source-Sprachmodelle weiter verbessert, hat sich auch die Leistung beim Schreiben und Analysieren von Code, Empfehlungen, Textzusammenfassungen und Frage-Antwort-Paaren (QA) verbessert. Aber wenn es um die Qualitätssicherung geht, mangelt es LLM oft an Problemen im Zusammenhang mit ungeschulten Daten, und viele interne Dokumente werden im Unternehmen aufbewahrt, um Compliance, Geschäftsgeheimnisse oder Datenschutz zu gewährleisten. Wenn diese Dokumente abgefragt werden, kann LLM Halluzinationen hervorrufen und irrelevante, erfundene oder inkonsistente Inhalte produzieren. Eine mögliche Technik zur Bewältigung dieser Herausforderung ist Retrieval Augmented Generation (RAG). Dabei geht es darum, die Antworten durch Verweise auf maßgebliche Wissensdatenbanken über die Trainingsdatenquelle hinaus zu verbessern, um die Qualität und Genauigkeit der Generierung zu verbessern. Das RAG-System umfasst ein Retrieval-System zum Abrufen relevanter Dokumentfragmente aus dem Korpus
 Optimierung von LLM mithilfe der SPIN-Technologie für das Feinabstimmungstraining für das Selbstspiel
Jan 25, 2024 pm 12:21 PM
Optimierung von LLM mithilfe der SPIN-Technologie für das Feinabstimmungstraining für das Selbstspiel
Jan 25, 2024 pm 12:21 PM
2024 ist ein Jahr der rasanten Entwicklung für große Sprachmodelle (LLM). In der Ausbildung von LLM sind Alignment-Methoden ein wichtiges technisches Mittel, einschließlich Supervised Fine-Tuning (SFT) und Reinforcement Learning mit menschlichem Feedback, das auf menschlichen Präferenzen basiert (RLHF). Diese Methoden haben eine entscheidende Rolle bei der Entwicklung von LLM gespielt, aber Alignment-Methoden erfordern eine große Menge manuell annotierter Daten. Angesichts dieser Herausforderung ist die Feinabstimmung zu einem dynamischen Forschungsgebiet geworden, in dem Forscher aktiv an der Entwicklung von Methoden arbeiten, mit denen menschliche Daten effektiv genutzt werden können. Daher wird die Entwicklung von Ausrichtungsmethoden weitere Durchbrüche in der LLM-Technologie fördern. Die University of California hat kürzlich eine Studie zur Einführung einer neuen Technologie namens SPIN (SelfPlayfInetuNing) durchgeführt. S
 Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern
Jan 14, 2024 pm 06:30 PM
Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern
Jan 14, 2024 pm 06:30 PM
Halluzinationen sind ein häufiges Problem bei der Arbeit mit großen Sprachmodellen (LLMs). Obwohl LLM glatte und kohärente Texte erzeugen kann, sind die generierten Informationen oft ungenau oder inkonsistent. Um LLM vor Halluzinationen zu schützen, können externe Wissensquellen wie Datenbanken oder Wissensgraphen zur Bereitstellung sachlicher Informationen genutzt werden. Auf diese Weise kann sich LLM auf diese zuverlässigen Datenquellen verlassen, was zu genaueren und zuverlässigeren Textinhalten führt. Vektordatenbank und Wissensgraph-Vektordatenbank Eine Vektordatenbank ist ein Satz hochdimensionaler Vektoren, die Entitäten oder Konzepte darstellen. Sie können verwendet werden, um die Ähnlichkeit oder Korrelation zwischen verschiedenen Entitäten oder Konzepten zu messen, die anhand ihrer Vektordarstellungen berechnet werden. Eine Vektordatenbank kann Ihnen anhand der Vektorentfernung sagen, dass „Paris“ und „Frankreich“ näher beieinander liegen als „Paris“ und
 Detaillierte Erläuterung der GQA, des in großen Modellen häufig verwendeten Aufmerksamkeitsmechanismus und der Pytorch-Codeimplementierung
Apr 03, 2024 pm 05:40 PM
Detaillierte Erläuterung der GQA, des in großen Modellen häufig verwendeten Aufmerksamkeitsmechanismus und der Pytorch-Codeimplementierung
Apr 03, 2024 pm 05:40 PM
Grouped Query Attention (GroupedQueryAttention) ist eine Methode zur Aufmerksamkeit für mehrere Abfragen in großen Sprachmodellen. Ihr Ziel besteht darin, die Qualität von MHA zu erreichen und gleichzeitig die Geschwindigkeit von MQA beizubehalten. GroupedQueryAttention gruppiert Abfragen und Abfragen innerhalb jeder Gruppe haben die gleiche Aufmerksamkeitsgewichtung, was dazu beiträgt, die Rechenkomplexität zu reduzieren und die Inferenzgeschwindigkeit zu erhöhen. In diesem Artikel erklären wir die Idee der GQA und wie man sie in Code übersetzt. GQA befindet sich im Artikel GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
Jan 18, 2024 pm 05:27 PM
RoSA: Eine neue Methode zur effizienten Feinabstimmung großer Modellparameter
Jan 18, 2024 pm 05:27 PM
Da Sprachmodelle in einem noch nie dagewesenen Ausmaß skaliert werden, wird eine umfassende Feinabstimmung für nachgelagerte Aufgaben unerschwinglich teuer. Um dieses Problem zu lösen, begannen Forscher, der PEFT-Methode Aufmerksamkeit zu schenken und sie zu übernehmen. Die Hauptidee der PEFT-Methode besteht darin, den Umfang der Feinabstimmung auf einen kleinen Satz von Parametern zu beschränken, um die Rechenkosten zu senken und gleichzeitig eine hochmoderne Leistung bei Aufgaben zum Verstehen natürlicher Sprache zu erzielen. Auf diese Weise können Forscher Rechenressourcen einsparen und gleichzeitig eine hohe Leistung aufrechterhalten, wodurch neue Forschungsschwerpunkte auf dem Gebiet der Verarbeitung natürlicher Sprache entstehen. RoSA ist eine neue PEFT-Technik, die durch Experimente mit einer Reihe von Benchmarks gezeigt hat, dass sie frühere Low-Rank-Adaptive- (LoRA) und reine Sparse-Feinabstimmungsmethoden mit demselben Parameterbudget übertrifft. Dieser Artikel wird näher darauf eingehen
 LLMLingua: Integrieren Sie LlamaIndex, komprimieren Sie Hinweise und stellen Sie effiziente Inferenzdienste für große Sprachmodelle bereit
Nov 27, 2023 pm 05:13 PM
LLMLingua: Integrieren Sie LlamaIndex, komprimieren Sie Hinweise und stellen Sie effiziente Inferenzdienste für große Sprachmodelle bereit
Nov 27, 2023 pm 05:13 PM
Das Aufkommen großer Sprachmodelle (LLMs) hat Innovationen in mehreren Bereichen angeregt. Die zunehmende Komplexität von Eingabeaufforderungen, die durch Strategien wie CoT-Eingabeaufforderungen (Chain-of-Think) und kontextuelles Lernen (ICL) vorangetrieben werden, stellt jedoch rechnerische Herausforderungen dar. Diese langwierigen Eingabeaufforderungen erfordern erhebliche Ressourcen für die Argumentation und erfordern daher effiziente Lösungen. In diesem Artikel wird die Integration von LLMLingua mit dem proprietären LlamaIndex vorgestellt, um effizientes Denken durchzuführen. LLMLingua ist ein von Microsoft-Forschern bei EMNLP2023 veröffentlichtes Verfahren, das die Fähigkeit von LLML, wichtige Informationen in langen Kontextszenen zu erkennen, durch schnelle Komprimierung verbessert. LLMLingua und llamindex
