

Sollte ich Redis oder Zookeeper für verteilte Sperren verwenden?
Verteilte Sperren werden normalerweise implementiert in:
Datenbank Cache (zum Beispiel: Redis) Zookeeper usw
Verwenden Sie in der tatsächlichen Entwicklung The Die häufigsten sind Redis und Zookeeper, daher wird in diesem Artikel nur auf diese beiden eingegangen.
Bevor wir dieses Problem besprechen, schauen wir uns zunächst ein Geschäftsszenario an:
System A ist ein E-Commerce-System, das derzeit auf einer Maschine bereitgestellt wird. Es gibt eine Schnittstelle, über die Benutzer Bestellungen im System aufgeben können, aber Benutzer müssen Sie Sie müssen den Lagerbestand überprüfen, um sicherzustellen, dass genügend Lagerbestand vorhanden ist, bevor Sie eine Bestellung für den Benutzer aufgeben.
Da das System über einen gewissen Grad an Parallelität verfügt, wird der Bestand der Produkte vorab im Bestand von Redis中,用户下单的时候会更新Redis gespeichert.
Die Systemarchitektur ist derzeit wie folgt:
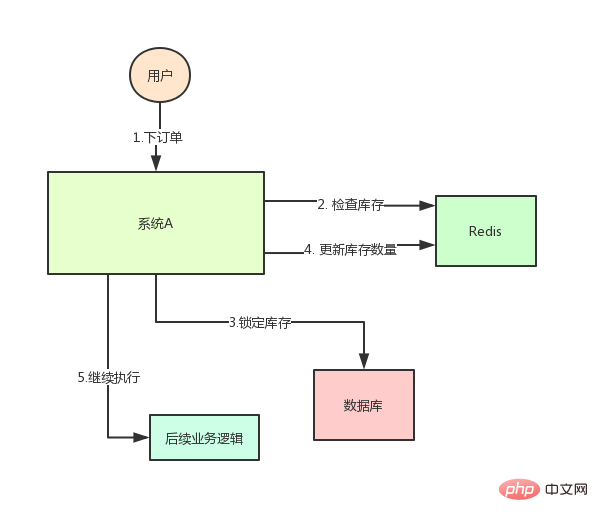
Aber das wird ein Problem schaffen: Wenn zu einem bestimmten Zeitpunkt der Bestand eines bestimmten Produkts in Redis 1 ist, kommen zu diesem Zeitpunkt zwei Anfragen Gleichzeitig wird einer davon Nach der Ausführung von Schritt 3 in der obigen Abbildung wird der Bestand in der Datenbank auf 0 aktualisiert, Schritt 4 wurde jedoch noch nicht ausgeführt.
Die andere Anfrage erreichte Schritt 2 und stellte fest, dass der Bestand immer noch 1 war, also fuhr sie mit Schritt 3 fort.
Das Ergebnis ist, dass 2 Artikel verkauft werden, tatsächlich aber nur 1 Artikel auf Lager ist.
Offensichtlich stimmt etwas nicht! Dies ist ein typisches Problem mit überverkauftem Lagerbestand.
An diesem Punkt können wir uns leicht eine Lösung vorstellen: Verwenden Sie eine Sperre, um die Schritte 2, 3 und 4 zu sperren, sodass nach Abschluss ein anderer Thread eintreten kann, um Schritt 2 auszuführen .
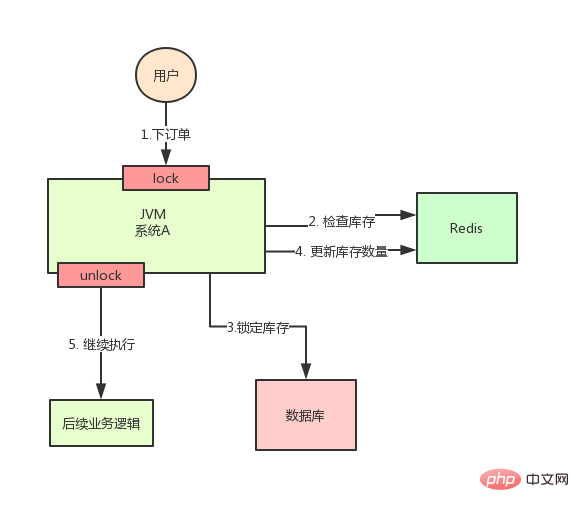
Verwenden Sie gemäß der obigen Abbildung beim Ausführen von Schritt 2 das von Java bereitgestellte synchronisierte oder ReentrantLock zum Sperren und geben Sie die Sperre dann frei, nachdem Schritt 4 ausgeführt wurde.
Auf diese Weise sind die drei Schritte 2, 3 und 4 „gesperrt“ und mehrere Threads können nur seriell ausgeführt werden.
Aber die guten Zeiten hielten nicht lange an, die Parallelität des gesamten Systems nahm zu und eine Maschine konnte damit nicht mehr umgehen. Jetzt müssen wir eine Maschine hinzufügen, wie unten gezeigt:
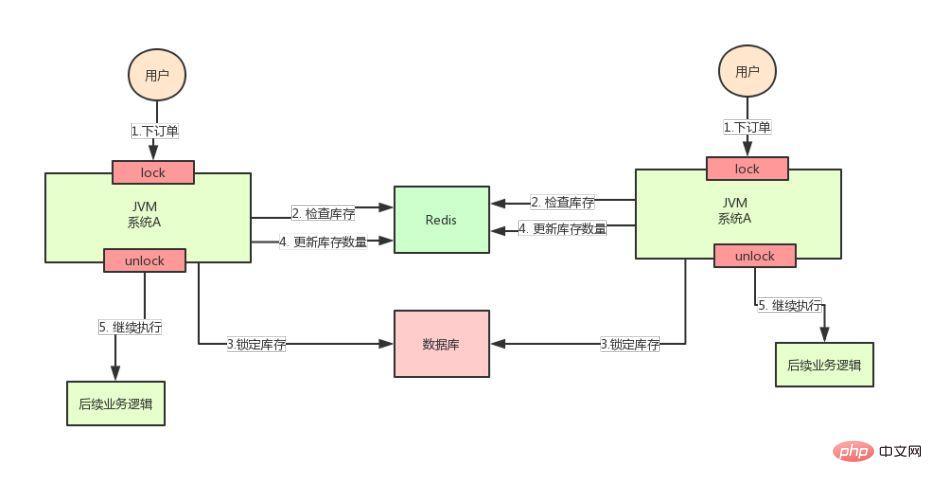
Nach dem Hinzufügen der Maschine sieht das System wie im Bild oben gezeigt aus, mein Gott!
Gehen Sie davon aus, dass die Anfragen von zwei Benutzern gleichzeitig eingehen, aber auf verschiedenen Computern landen. Können diese beiden Anfragen gleichzeitig ausgeführt werden, oder tritt das Problem des überverkauften Lagerbestands auf?
Warum? Da die beiden A-Systeme im Bild oben in zwei verschiedenen JVMs ausgeführt werden, gelten die von ihnen hinzugefügten Sperren nur für Threads in ihren eigenen JVMs und sind für Threads in anderen JVMs ungültig.
Das Problem hier ist also: Der von Java bereitgestellte native Sperrmechanismus schlägt in einem Bereitstellungsszenario mit mehreren Maschinen fehl
Dies liegt daran, dass die von den beiden Maschinen hinzugefügten Sperren nicht dieselben sind (die beiden Sperren befinden sich in unterschiedlichen JVMs). .
Dann wird das Problem nicht gelöst, solange wir sicherstellen, dass die den beiden Maschinen hinzugefügten Schlösser gleich sind?
An diesem Punkt ist es an der Zeit, dass verteilte Sperren ihren großen Auftritt haben. Die Idee verteilter Sperren ist:
Bereitstellung eines globalen und einzigartigen „Dings“ für den Erwerb von Sperren im gesamten System und dann in jedem System Wenn es bei Bedarf sperren kann, bitten alle dieses „Ding“, eine Sperre zu erhalten, sodass verschiedene Systeme es als dieselbe Sperre betrachten können.
Dieses „Ding“ kann Redis, Zookeeper oder eine Datenbank sein.
Die Textbeschreibung ist nicht sehr intuitiv. Schauen wir uns das Bild unten an:
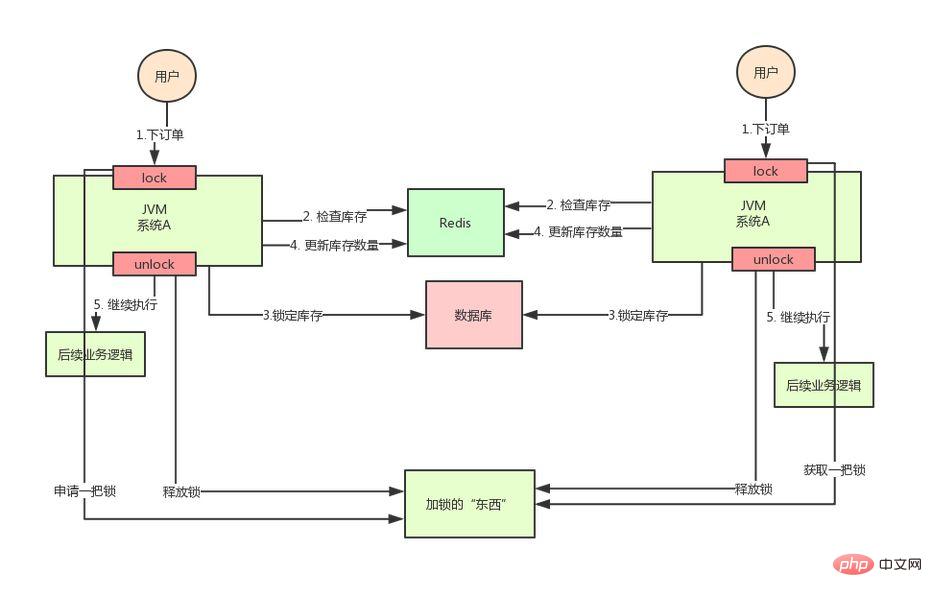
Durch die obige Analyse wissen wir, dass die Verwendung des nativen Sperrmechanismus von Java bei überverkauften Lagerbeständen die Thread-Sicherheit in einer verteilten Umgebung nicht gewährleisten kann Daher müssen wir eine verteilte Sperrlösung verwenden.
Wie implementiert man also verteilte Sperren? Dann lesen Sie weiter!
Implementierung verteilter Sperren auf Basis von Redis
Oben wird analysiert, warum verteilte Sperren verwendet werden sollten. Hier werfen wir einen genaueren Blick darauf, wie verteilte Sperren bei der Implementierung gehandhabt werden sollten.
Die häufigste Lösung besteht darin, Redis als verteilte Sperre zu verwenden
Die Idee, Redis für verteilte Sperren zu verwenden, ist ungefähr folgende: Legen Sie in Redis einen Wert fest, der angibt, dass die Sperre hinzugefügt wurde, und löschen Sie dann den Schlüssel, wenn die Sperre aufgehoben wird.
Der spezifische Code lautet wie folgt:
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
SET anyLock unique_value NX PX 30000
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endEs gibt mehrere wichtige Punkte bei dieser Methode:
Achten Sie darauf, den Befehl SET key value NX PX milliseconds zu verwenden
Wenn nicht, legen Sie zuerst den Wert fest und dann Legen Sie die Ablaufzeit fest. Es handelt sich nicht um eine atomare Operation. Es kann zu einem Absturz kommen, bevor die Ablaufzeit festgelegt wird, was zu einem Deadlock führt (der Schlüssel ist dauerhaft vorhanden). Der Wert muss eindeutig sein. Dies dient der Überprüfung dass der Wert und beim Entsperren der Schlüssel nur dann gelöscht wird, wenn die Sperren konsistent sind.
Neben der Überlegung, wie der Client verteilte Sperren implementiert, müssen Sie auch die Bereitstellung von Redis berücksichtigen.
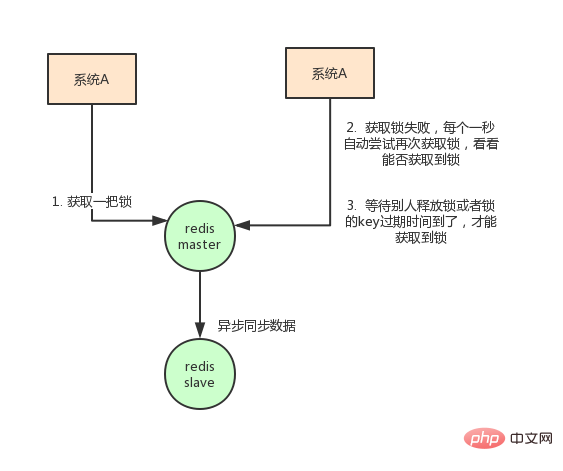 Einzelmaschinenmodus
EinzelmaschinenmodusMaster-Slave + Sentinel-Wahlmodus
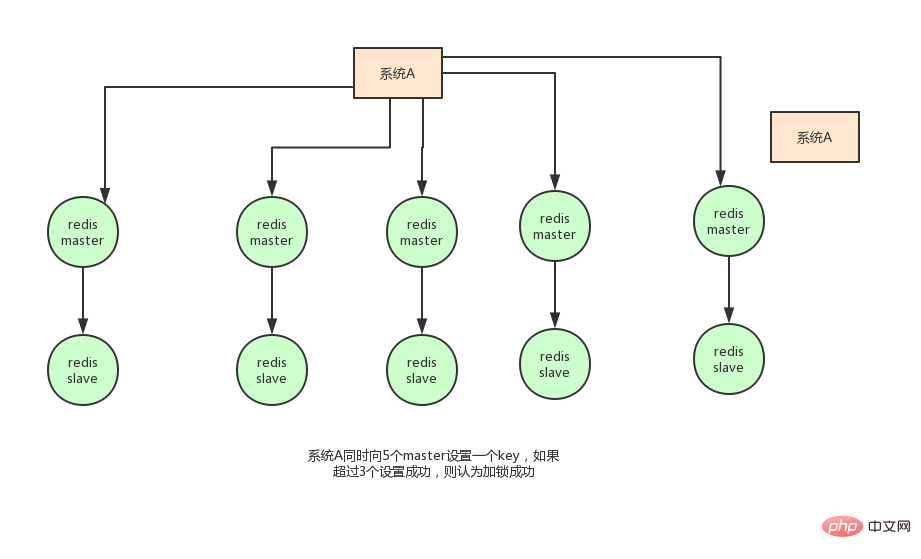
Redis-Clustermodus Der Nachteil der Verwendung von Redis für verteilte Sperren ist: Wenn Sie Verwenden Sie eine einzelne Maschine. Im Bereitstellungsmodus gibt es einen einzigen Problempunkt, solange Redis fehlschlägt. Das Sperren wird nicht funktionieren. Beim Sperren wird nur ein Knoten gesperrt. Selbst wenn der Master-Knoten ausfällt und ein Master-Slave-Schalter auftritt, kann es zu einem Sperrverlust kommen. Auf der Grundlage der obigen Überlegungen hat der Autor von Redis dieses Problem tatsächlich auch berücksichtigt. Er hat einen RedLock-Algorithmus vorgeschlagen. Die Bedeutung dieses Algorithmus ist ungefähr so: Angenommen, der Bereitstellungsmodus von Redis ist Redis-Cluster Es gibt insgesamt 5 Master-Knoten. Führen Sie die folgenden Schritte aus, um eine Sperre zu erhalten:
获取当前时间戳,单位是毫秒 轮流尝试在每个master节点上创建锁,过期时间设置较短,一般就几十毫秒 尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1) 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了 要是锁建立失败了,那么就依次删除这个锁 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁
但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确。
另一种方式:Redisson
此外,实现Redis的分布式锁,除了自己基于redis client原生api来实现之外,还可以使用开源框架:Redission
Redisson是一个企业级的开源Redis Client,也提供了分布式锁的支持。我也非常推荐大家使用,为什么呢?
回想一下上面说的,如果自己写代码来通过redis设置一个值,是通过下面这个命令设置的。
SET anyLock unique_value NX PX 30000
这里设置的超时时间是30s,假如我超过30s都还没有完成业务逻辑的情况下,key会过期,其他线程有可能会获取到锁。
这样一来的话,第一个线程还没执行完业务逻辑,第二个线程进来了也会出现线程安全问题。所以我们还需要额外的去维护这个过期时间,太麻烦了~
我们来看看redisson是怎么实现的?先感受一下使用redission的爽:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://192.168.31.101:7001")
.addNodeAddress("redis://192.168.31.101:7002")
.addNodeAddress("redis://192.168.31.101:7003")
.addNodeAddress("redis://192.168.31.102:7001")
.addNodeAddress("redis://192.168.31.102:7002")
.addNodeAddress("redis://192.168.31.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
lock.unlock();就是这么简单,我们只需要通过它的api中的lock和unlock即可完成分布式锁,他帮我们考虑了很多细节:
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
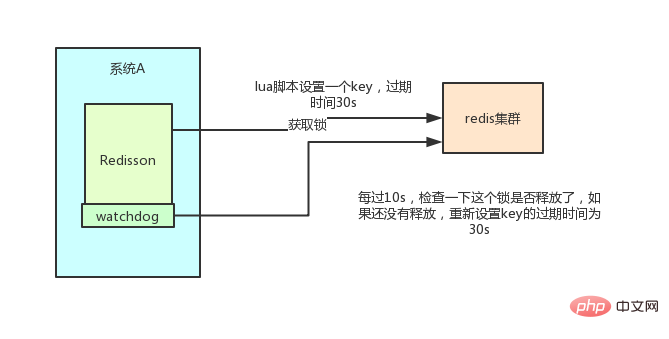
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个
watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
redisson的“看门狗”逻辑保证了没有死锁发生。
(如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
这里稍微贴出来其实现代码:
// 加锁逻辑
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 调用一段lua脚本,设置一些key、过期时间
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
// lock acquired
if (ttlRemaining == null) {
// 看门狗逻辑
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
// 看门狗最终会调用了这里
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
// 这个任务会延迟10s执行
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 这个操作会将key的过期时间重新设置为30s
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
// 通过递归调用本方法,无限循环延长过期时间
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), new ExpirationEntry(threadId, task)) != null) {
task.cancel();
}
}另外,redisson还提供了对redlock算法的支持,
它的用法也很简单:
RedissonClient redisson = Redisson.create(config);
RLock lock1 = redisson.getFairLock("lock1");
RLock lock2 = redisson.getFairLock("lock2");
RLock lock3 = redisson.getFairLock("lock3");
RedissonRedLock multiLock = new RedissonRedLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();小结:
本节分析了使用Redis作为分布式锁的具体落地方案,以及其一些局限性,然后介绍了一个Redis的客户端框架redisson。这也是我推荐大家使用的,比自己写代码实现会少care很多细节。
基于zookeeper实现分布式锁
常见的分布式锁实现方案里面,除了使用redis来实现之外,使用zookeeper也可以实现分布式锁。
在介绍zookeeper(下文用zk代替)实现分布式锁的机制之前,先粗略介绍一下zk是什么东西:
Zookeeper是一种提供配置管理、分布式协同以及命名的中心化服务。
zk的模型是这样的:zk包含一系列的节点,叫做znode,就好像文件系统一样每个znode表示一个目录,然后znode有一些特性:
Geordneter Knoten: Wenn derzeit ein übergeordneter Knoten vorhanden ist
/lock,我们可以在这个父节点下面创建子节点;zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号
也就是说,如果是第一个创建的子节点,那么生成的子节点为
zookeeper bietet eine optionale Sortierfunktion, zum Beispiel können wir einen untergeordneten Knoten „/lock/node-“ erstellen und die Reihenfolge angeben, dann zookeeper fügt beim Generieren von untergeordneten Knoten automatisch eine ganzzahlige Seriennummer basierend auf der aktuellen Anzahl untergeordneter Knoten hinzu/lock/node-0000000000,下一个节点则为/lock/node-0000000001Das heißt, wenn es sich um den ersten erstellten untergeordneten Knoten handelt, hat der generierte untergeordnete Knoten die Größe - Knotenerstellung
- Knotenlöschung
- Knotendatenänderung
/lock/node-0000000000, der nächste Knoten ist /lock/node-0000000001 und so weiter.
- Basierend auf einigen Aufgrund der Eigenschaften von zk können wir leicht einen Implementierungsplan für die Verwendung von zk zum Implementieren verteilter Sperren erstellen: Knoten in zk. Zum Beispiel im Verzeichnis /lock/.
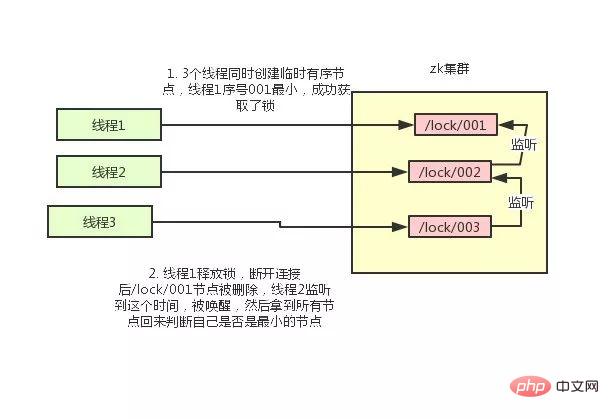
- Nach erfolgreicher Erstellung des Knotens alle temporären Knoten im Verzeichnis /lock abrufen und dann feststellen, ob der vom aktuellen Thread erstellte Knoten der Knoten mit der kleinsten Seriennummer aller Knoten ist
- Wenn der vom aktuellen Thread erstellte Knoten der Knoten mit der kleinsten Sequenznummer aller Knoten ist, wird davon ausgegangen, dass der Sperrenerwerb erfolgreich war.
- Wenn der vom aktuellen Thread erstellte Knoten nicht der Knoten mit der kleinsten Seriennummer aller Knoten ist, fügen Sie dem Knoten vor der Knotenseriennummer einen Ereignis-Listener hinzu.
比如当前线程获取到的节点序号为
/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:
具体的实现思路就是这样,至于代码怎么写,这里比较复杂就不贴出来了。
Curator介绍
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。
他的使用方式也比较简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock"); interProcessMutex.acquire(); interProcessMutex.release();
其实现分布式锁的核心源码如下:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}其实curator实现分布式锁的底层原理和上面分析的是差不多的。这里我们用一张图详细描述其原理:
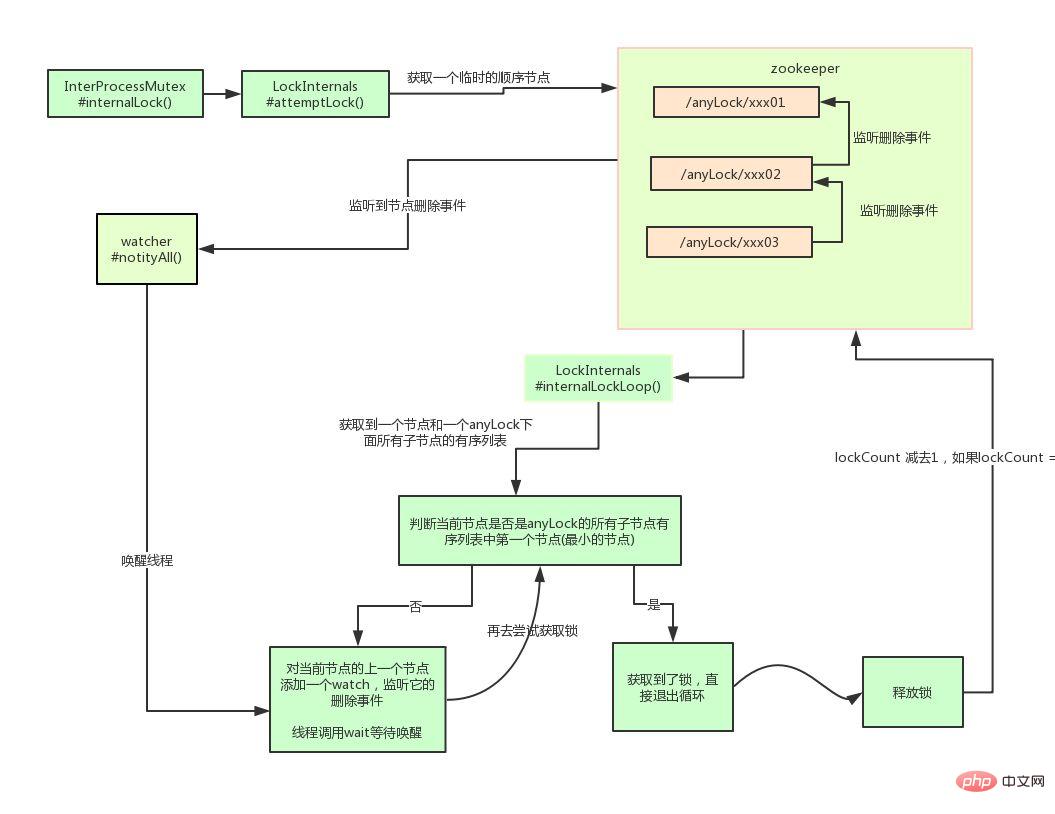
小结:
本节介绍了Zookeeperr实现分布式锁的方案以及zk的开源客户端的基本使用,简要的介绍了其实现原理。
Vergleich der Vor- und Nachteile der beiden Lösungen
Nachdem Sie die beiden Implementierungslösungen für verteilte Sperren kennengelernt haben, müssen in diesem Abschnitt die jeweiligen Vor- und Nachteile der Redis- und ZK-Implementierungslösungen erörtert werden.
Für die verteilte Sperre von Redis gibt es die folgenden Nachteile:
Der Weg, die Sperre zu erwerben, ist einfach und grob. Wenn die Sperre nicht erworben werden kann, wird weiterhin versucht, die Sperre zu erwerben, was Leistung verbraucht . Darüber hinaus bestimmt die Designpositionierung von Redis, dass seine Daten nicht stark konsistent sind. In einigen extremen Fällen können Probleme auftreten. Das Sperrmodell ist nicht robust genug Selbst wenn der Redlock-Algorithmus zur Implementierung verwendet wird, gibt es in einigen komplexen Szenarien keine Garantie dafür, dass die Implementierung zu 100 % problemlos ist. Eine Diskussion über Redlock finden Sie unter Wie Um eine verteilte Sperre durchzuführen Redis-Verteilung Bei Sperren müssen Sie tatsächlich ständig versuchen, die Sperre selbst zu erhalten, was mehr Leistung verbraucht.
Aber andererseits ist die Verwendung von Redis zur Implementierung verteilter Sperren in vielen Unternehmen weit verbreitet, und in den meisten Fällen werden Sie nicht auf die sogenannten „extrem komplexen Szenarien“ stoßen
Die Verwendung von Redis als verteilte Sperre ist also der Fall Keine schlechte Idee. Das Wichtigste an einer guten Lösung ist, dass Redis eine hohe Leistung bietet und Erfassungs- und Freigabesperrvorgänge mit hoher Parallelität unterstützen kann.
Für zk-verteilte Schlösser:
Zookeepers natürliche Designpositionierung ist verteilte Koordination und starke Konsistenz. Das Schlossmodell ist robust, einfach zu bedienen und für verteilte Schlösser geeignet. Wenn Sie die Sperre nicht erhalten können, müssen Sie nur einen Listener hinzufügen. Es ist nicht erforderlich, ständig abzufragen, und der Leistungsverbrauch ist gering.
Aber ZK hat auch seine Mängel: Wenn mehr Clients häufig Sperren beantragen und Sperren freigeben, ist der Druck auf den ZK-Cluster größer.
Zusammenfassung:
Zusammenfassend haben sowohl Redis als auch Zookeeper ihre Vor- und Nachteile. Wir können diese Themen als Referenzfaktoren bei der Technologieauswahl verwenden.
Das obige ist der detaillierte Inhalt vonSollte ich Redis oder Zookeeper für verteilte Sperren verwenden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Verwendung von ZooKeeper für die verteilte Sperrenverarbeitung in der Java-API-Entwicklung
Jun 17, 2023 pm 10:36 PM
Verwendung von ZooKeeper für die verteilte Sperrenverarbeitung in der Java-API-Entwicklung
Jun 17, 2023 pm 10:36 PM
Da sich moderne Anwendungen ständig weiterentwickeln und der Bedarf an Hochverfügbarkeit und Parallelität wächst, werden verteilte Systemarchitekturen immer häufiger eingesetzt. In einem verteilten System laufen mehrere Prozesse oder Knoten gleichzeitig und erledigen Aufgaben gemeinsam, wobei die Synchronisierung zwischen Prozessen besonders wichtig wird. Da viele Knoten in einer verteilten Umgebung gleichzeitig auf gemeinsam genutzte Ressourcen zugreifen können, ist der Umgang mit Parallelitäts- und Synchronisierungsproblemen zu einer wichtigen Aufgabe in einem verteilten System geworden. In dieser Hinsicht hat sich ZooKeeper zu einer sehr beliebten Lösung entwickelt. ZooKee
 Verwendung von ZooKeeper und Curator für die verteilte Koordination und Verwaltung in Beego
Jun 22, 2023 pm 09:27 PM
Verwendung von ZooKeeper und Curator für die verteilte Koordination und Verwaltung in Beego
Jun 22, 2023 pm 09:27 PM
Mit der rasanten Entwicklung des Internets sind verteilte Systeme zu einer der Infrastrukturen in vielen Unternehmen und Organisationen geworden. Damit ein verteiltes System ordnungsgemäß funktioniert, muss es koordiniert und verwaltet werden. In dieser Hinsicht sind ZooKeeper und Curator zwei lohnenswerte Tools. ZooKeeper ist ein sehr beliebter verteilter Koordinationsdienst, der uns dabei helfen kann, den Status und die Daten zwischen Knoten in einem Cluster zu koordinieren. Curator ist eine Kapselung von ZooKeeper
 Sollte ich Redis oder Zookeeper für verteilte Sperren verwenden?
Aug 22, 2023 pm 03:48 PM
Sollte ich Redis oder Zookeeper für verteilte Sperren verwenden?
Aug 22, 2023 pm 03:48 PM
Verteilte Sperren werden normalerweise auf folgende Weise implementiert: Datenbank, Cache (z. B. Redis), Zookeeper usw. In der tatsächlichen Entwicklung werden am häufigsten Redis und Zookeeper verwendet, daher wird in diesem Artikel nur auf diese beiden eingegangen.
 Wie verwende ich die Zookeeper-Erweiterung von PHP?
Jun 02, 2023 pm 09:01 PM
Wie verwende ich die Zookeeper-Erweiterung von PHP?
Jun 02, 2023 pm 09:01 PM
PHP ist eine sehr beliebte Programmiersprache, die häufig in Webanwendungen und serverseitiger Entwicklung verwendet wird. Zookeeper ist ein verteilter Koordinierungsdienst zur Verwaltung, Koordinierung und Überwachung verteilter Anwendungen und Dienste. Die Verwendung von Zookeeper in PHP-Anwendungen kann die Leistung und Zuverlässigkeit Ihrer Anwendung verbessern. In diesem Artikel wird die Verwendung der Zookeeper-Erweiterung für PHP vorgestellt. 1. Installieren Sie die Zookeeper-Erweiterung. Um die Zookeeper-Erweiterung verwenden zu können, müssen Sie Zookeeper installieren.
 Verwendung von ZooKeeper zur Implementierung der Dienstregistrierung und -erkennung in Beego
Jun 22, 2023 am 08:21 AM
Verwendung von ZooKeeper zur Implementierung der Dienstregistrierung und -erkennung in Beego
Jun 22, 2023 am 08:21 AM
In der Microservice-Architektur ist die Registrierung und Erkennung von Diensten ein sehr wichtiges Thema. Um dieses Problem zu lösen, können wir ZooKeeper als Service-Registrierungscenter verwenden. In diesem Artikel stellen wir vor, wie Sie ZooKeeper im Beego-Framework verwenden, um die Registrierung und Erkennung von Diensten zu implementieren. 1. Einführung in ZooKeeper ZooKeeper ist ein verteilter Open-Source-Koordinierungsdienst. Es ist eines der Unterprojekte von Apache Hadoop. Die Hauptrolle von ZooKeeper
![[Empfohlene Sammlung] Seelenfolter! Die 31-Schuss-Kanone des Tierpflegers](https://img.php.cn/upload/article/202308/28/2023082816453271532.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Empfohlene Sammlung] Seelenfolter! Die 31-Schuss-Kanone des Tierpflegers
Aug 28, 2023 pm 04:45 PM
[Empfohlene Sammlung] Seelenfolter! Die 31-Schuss-Kanone des Tierpflegers
Aug 28, 2023 pm 04:45 PM
ZooKeeper ist ein verteilter Open-Source-Koordinierungsdienst. Es handelt sich um eine Software, die Konsistenzdienste für verteilte Anwendungen bereitstellt. Verteilte Anwendungen können Aufgaben wie Datenveröffentlichung/-abonnement, Lastausgleich, Benennungsdienst, verteilte Koordination/Benachrichtigung, Clusterverwaltung, Master-Wahl, verteilte Sperren und verteilte Warteschlangen sowie andere Funktionen implementieren.
 ZooKeeper-Vergleich der Redis-Implementierung verteilter Sperren
Jun 20, 2023 pm 03:19 PM
ZooKeeper-Vergleich der Redis-Implementierung verteilter Sperren
Jun 20, 2023 pm 03:19 PM
Mit der rasanten Entwicklung der Internet-Technologie sind verteilte Systeme in modernen Anwendungen weit verbreitet, insbesondere in großen Internetunternehmen. In einem verteilten System ist es jedoch sehr schwierig, die Konsistenz zwischen Knoten aufrechtzuerhalten. Daher ist der verteilte Sperrmechanismus zu einer der Grundlagen zur Lösung dieses Problems geworden. Bei der Implementierung verteilter Sperren sind Redis und ZooKeeper beliebte Tools. In diesem Artikel werden sie verglichen und analysiert. Redis implementiert verteilte Sperren. Redis ist ein Open-Source-Speicherdatenspeicher
 So integrieren Sie Dubbo Zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
So integrieren Sie Dubbo Zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
dockerpullzookeeperdockerrun --namezk01-p2181:2181--restartalways-d2e30cac00aca zeigt an, dass zookeeper Zookeeper und Dubbo erfolgreich gestartet hat. • ZooKeeperZooKeeper ist ein verteilter Open-Source-Koordinierungsdienst für verteilte Anwendungen. Es handelt sich um eine Software, die konsistente Dienste für verteilte Anwendungen bereitstellt. Zu den bereitgestellten Funktionen gehören: Konfigurationswartung, Domänennamendienste, verteilte Synchronisierung, Gruppendienste usw. DubboDubbo ist Alibabas Open-Source-Framework für verteilte Dienste. Sein größtes Merkmal ist seine mehrschichtige Struktur.
