
Fünf Architekturprinzipien
Zunächst bedeutet dies, dass die vom Benutzer angeforderten Daten so klein wie möglich sein können. Zu den angeforderten Daten gehören in das System hochgeladene Daten und vom System an den Benutzer zurückgegebene Daten (normalerweise eine Webseite).
Nachdem die vom Benutzer angeforderte Seite zurückgegeben wurde, schließt der Browser beim Rendern der Seite weitere zusätzliche Anfragen ein, beispielsweise CSS/JavaScript, Bilder und Ajax Anfragen, von denen diese Seite abhängt, werden als „zusätzliche Anfragen“ definiert und sollten auf ein Minimum beschränkt werden.
Dies ist die Anzahl der Zwischenknoten, die der Benutzer im Prozess von der Anfrage bis zur Rückgabe der Daten durchlaufen muss.
bezieht sich auf das System oder den Dienst, auf den man sich verlassen muss, um eine Benutzeranfrage abzuschließen. Abhängigkeiten beziehen sich hier auf starke Abhängigkeiten.
Ein einzelner Punkt im System kann als Tabu in der Systemarchitektur bezeichnet werden, da ein einzelner Punkt keine Sicherung und unkontrollierbare Risiken bedeutet. Das wichtigste Prinzip beim Entwurf verteilter Systeme besteht darin, „einzelne Punkte zu eliminieren“. , ein anderer Name ist „Hochverfügbarkeit“.
Architektur ist eine Kunst des Gleichgewichts, und sobald die beste Architektur von der Szene, an die sie sich anpasst, getrennt wird, wird alles leeres Gerede sein. Wir müssen bedenken, dass die hier genannten Punkte nur Richtungen sind. Wir sollten unser Bestes geben, um in diese Richtungen zu arbeiten, aber wir müssen auch andere Faktoren berücksichtigen.
Was genau ist also eine dynamische und statische Trennung? Die sogenannte „dynamische und statische Trennung“ bedeutet eigentlich, die vom Benutzer angeforderten Daten (z. B. eine HTML-Seite) in „dynamische Daten“ und „statische Daten“ zu unterteilen. Einfach ausgedrückt besteht der Hauptunterschied zwischen „dynamischen Daten“ und „statischen Daten“ darin, festzustellen, ob die auf der Seite ausgegebenen Daten mit der URL, dem Browser, der Zeit und der Region zusammenhängen und ob sie private Daten wie Cookies enthalten.
Zuerst sollten Sie statische Daten in der Nähe des Benutzers zwischenspeichern. Statische Daten sind Daten, die relativ unverändert sind, sodass wir sie zwischenspeichern können. Wo wird es zwischengespeichert? Es gibt drei gängige: im Browser des Benutzers, im CDN oder im Cache des Servers. Sie sollten sie je nach Situation so nah wie möglich am Benutzer zwischenspeichern.
Zweitens besteht die statische Transformation darin, HTTP-Verbindungen direkt zwischenzuspeichern. Im Vergleich zum normalen Daten-Caching müssen Sie von der statischen Transformation des Systems gehört haben. Die statische Transformation speichert die HTTP-Verbindung direkt zwischen, anstatt nur die Daten zwischenzuspeichern. Wie in der folgenden Abbildung gezeigt, entnimmt der Web-Proxy-Server direkt den entsprechenden HTTP-Antwortheader und Antworttext entsprechend der Anforderungs-URL und gibt ihn direkt zurück ist so einfach, dass es nicht einmal das HTTP-Protokoll verwendet. Neu zusammengesetzt müssen nicht einmal die HTTP-Anforderungsheader analysiert werden.
Drittens ist auch wichtig, wer statische Daten zwischenspeichert. In verschiedenen Sprachen geschriebene Cache-Software weist unterschiedliche Effizienzen bei der Verarbeitung zwischengespeicherter Daten auf. Nehmen Sie Java als Beispiel, da das Java-System selbst auch seine Schwächen hat (z. B. kann es eine große Anzahl von Verbindungsanforderungen nicht gut verarbeiten, jede Verbindung verbraucht mehr Speicher und der Servlet-Container analysiert das HTTP-Protokoll nur langsam). , sodass Sie das Caching nicht auf der Java-Ebene durchführen können, sondern direkt auf der Webserver-Ebene, sodass Sie einige Schwachstellen auf der Java-Sprachebene im Vergleich zu Webservern (wie Nginx, Apache, Varnish) abschirmen können ist auch besser in der Lage, große gleichzeitige statische Dateianforderungen zu verarbeiten.
Je nach Komplexität der Architektur stehen 3 Optionen zur Auswahl:
Einzelmaschinenbereitstellung:
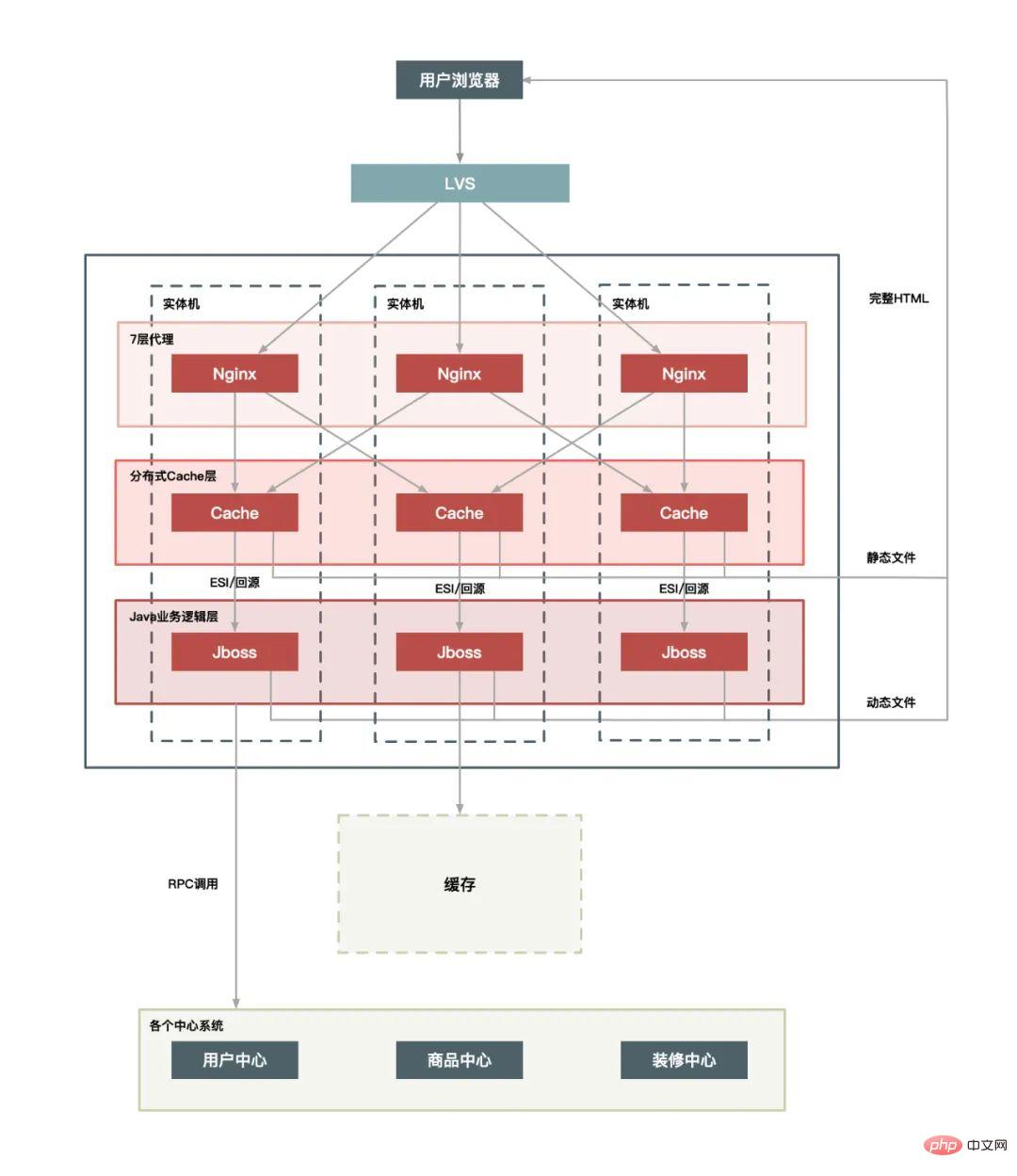
Unified Cache Layer:
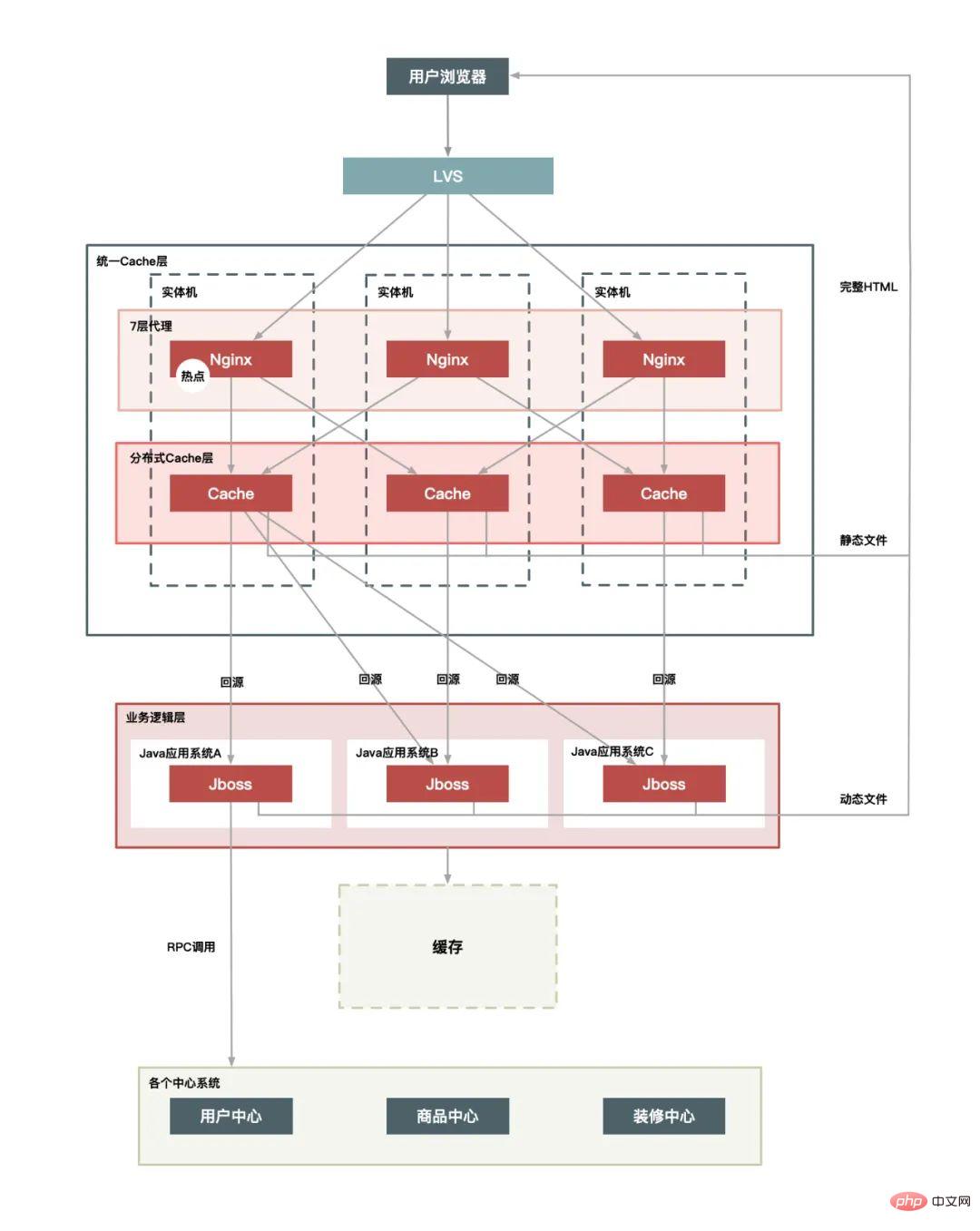
plus CDN-Schicht:
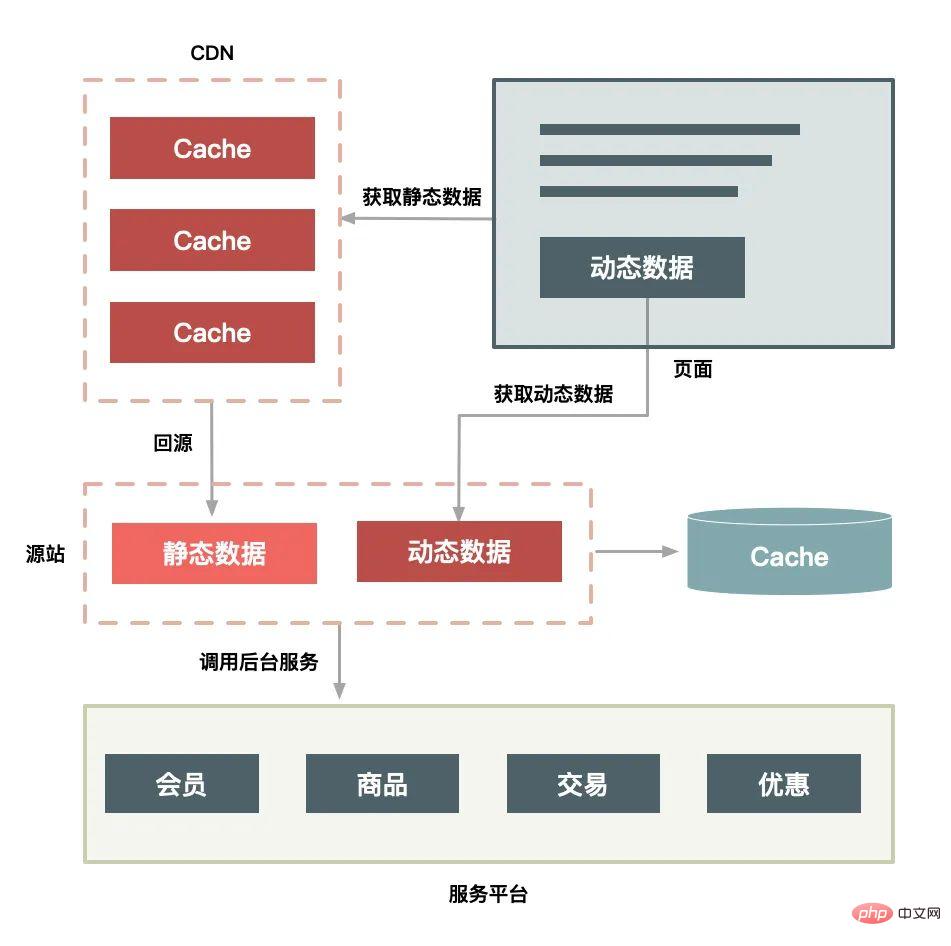
Die CDN-Bereitstellungslösung verfügt außerdem über die folgenden Funktionen:
Hotspots werden in Hotspot-Vorgänge und Hotspot-Daten unterteilt.
Die sogenannten „Hot Operations“, wie z. B. eine große Anzahl von Seitenaktualisierungen, eine große Anzahl von Einkaufswagen hinzufügen, eine große Anzahl von Bestellungen um 0:00 Uhr bei Double Eleven usw., fallen alle in diese Kategorie . Für das System können diese Vorgänge in „Leseanfragen“ und „Schreibanfragen“ abstrahiert werden. Diese beiden Hotspot-Anfragen werden auf sehr unterschiedliche Weise behandelt. Der Optimierungsraum für Leseanfragen ist im Allgemeinen größer Die Idee der Optimierung besteht darin, auf der Grundlage der CAP-Theorie diesen Inhalt im Detail vorzustellen.
Die „Hotspot-Daten“ sind leichter zu verstehen, also die Daten, die der Hotspot-Anfrage des Benutzers entsprechen. Hotspot-Daten werden in „statische Hotspot-Daten“ und „dynamische Hotspot-Daten“ unterteilt.
Die sogenannten „statischen Hotspot-Daten“ beziehen sich auf Hotspot-Daten, die im Voraus vorhergesagt werden können. Beispielsweise können wir durch die Registrierung vorab Verkäufer herausfiltern und diese heißen Produkte über das Registrierungssystem markieren. Darüber hinaus können wir Big-Data-Analysen nutzen, um beliebte Produkte im Voraus zu entdecken. Beispielsweise analysieren wir historische Transaktionsdatensätze und Benutzer-Warenkorbdaten, um herauszufinden, welche Produkte möglicherweise beliebter sind und sich besser verkaufen vorab analysiert werden.
Die sogenannten „dynamischen Hotspot-Daten“ beziehen sich auf Hotspots, die nicht im Voraus vorhersehbar sind und vorübergehend während des Betriebs des Systems entstehen. Wenn beispielsweise ein Verkäufer auf Douyin wirbt, wird das Produkt sofort beliebt, sodass es in kurzer Zeit in großen Mengen gekauft wird.
Da Hotspot-Vorgänge Benutzerverhalten sind, können wir sie nicht ändern, aber wir können einige Einschränkungen und Schutzmaßnahmen vornehmen. Daher werde ich in diesem Artikel hauptsächlich die Optimierung von Hotspot-Daten vorstellen.
Optimierung
Der effektivste Weg, Hotspot-Daten zu optimieren, ist das Zwischenspeichern Hotspot-Daten: Wenn Hotspot-Daten von statischen Daten getrennt werden, können statische Daten für eine lange Zeit zwischengespeichert werden. Das Zwischenspeichern von Hotspot-Daten ist jedoch eher ein „temporärer“ Cache, d. h. unabhängig davon, ob es sich um statische oder dynamische Daten handelt, werden sie für einige Sekunden kurz in einer Warteschlange zwischengespeichert der LRU-Eliminierungsalgorithmus.
Einschränkungen
Einschränkung ist eher ein Schutzmechanismus, und es gibt viele Möglichkeiten, ihn einzuschränken. Führen Sie beispielsweise einen konsistenten Hash für die ID des Produkts durch, auf das zugegriffen wird, und legen Sie dann eine Verarbeitungswarteschlange für jeden Bucket fest. Damit heiße Produkte verarbeitet werden können. Durch die Beschränkung auf eine Anforderungswarteschlange wird verhindert, dass bestimmte heiße Produkte zu viele Serverressourcen beanspruchen und dazu führen, dass andere Anforderungen niemals Verarbeitungsressourcen vom Server erhalten.
Isolierung
Das erste Prinzip des Flash-Sale-Systemdesigns besteht darin, diese Art von heißen Daten zu isolieren. Lassen Sie nicht zu, dass 1 % der Anfragen die anderen 99 % beeinträchtigen 1 % der Anfragen. Gezielte Optimierung. Isolation kann unterteilt werden in: Geschäftsisolation, Systemisolation und Datenisolation.
So glätten Sie Verkehrsspitzen
Genau wie auf den Straßen in der Stadt gibt es aufgrund der Probleme der Morgen- und Abendspitze eine Lösung durch Spitzenverschiebung und Verkehrsbeschränkungen.
Das Vorhandensein von Peak-Clipping kann erstens die Serververarbeitung stabiler machen und zweitens die Ressourcenkosten des Servers einsparen.
Für das Flash-Sale-Szenario dient das Peak-Clipping im Wesentlichen dazu, die Ausgabe von Benutzeranfragen weiter zu verzögern, um einige ungültige Anfragen zu reduzieren und herauszufiltern. Es folgt dem Prinzip „Die Anzahl der Anfragen sollte so gering wie möglich sein“.
Um Verkehrsspitzen zu erreichen, besteht die einfachste Lösung darin, Nachrichtenwarteschlangen zu verwenden, um den momentanen Verkehr zu puffern, synchrone direkte Anrufe in asynchrone indirekte Pushs umzuwandeln und eine Warteschlange zu übertragen, die den momentanen Verkehr abwickelt an einem Ende seinen Höhepunkt erreicht und am anderen Ende sanft Botschaften ausstößt.
Zusätzlich zu Nachrichtenwarteschlangen gibt es viele ähnliche Warteschlangenmethoden, wie zum Beispiel:
Es ist ersichtlich, dass diese Methoden ein gemeinsames Merkmal haben, nämlich die Umwandlung der „einstufigen Operation“ in eine „zweistufige Operation“, bei der die hinzugefügte einstufige Operation als Funktion verwendet wird Puffer.
Das ist sehr wichtig, Alle anderen Schritte sind Hilfsschritte. Wenn 100 Stück auf Lager sind, verkaufen Sie einfach 100 Stück und reduzieren Sie den Wert in der Datenbank auf 0. Was ist das Problem? Ja, das ist theoretisch der Fall, aber in bestimmten Geschäftsszenarien ist die „Reduzierung des Lagerbestands“ nicht so einfach.
Klicken Sie auf der Produktseite auf die Schaltfläche „Jetzt kaufen“, überprüfen Sie die Informationen und klicken Sie auf „Bestellung absenden“. Nachdem Sie eine Bestellung aufgegeben haben, können Sie erst dann wirklich kaufen, wenn Sie den Zahlungsvorgang abgeschlossen haben. Denn „Sicherheit in der Tasche“ heißt es so schön.
Vorgänge zur Bestandsreduzierung haben im Allgemeinen die folgenden Methoden:
Das heißt, nachdem der Käufer eine Bestellung aufgegeben hat, wird die Kaufmenge des Käufers vom Gesamtbestand des Produkts abgezogen. Das Aufgeben einer Bestellung zur Reduzierung des Lagerbestands ist die einfachste Möglichkeit, den Lagerbestand zu reduzieren, und es ist auch die genaueste Kontrollmethode. Bei der Bestellung wird der Warenbestand direkt über den Transaktionsmechanismus der Datenbank gesteuert, sodass überverkaufte Konditionen auftreten nicht vorkommen. Sie müssen jedoch wissen, dass manche Leute nach der Bestellung möglicherweise nicht bezahlen.
Das heißt, nachdem der Käufer die Bestellung aufgegeben hat, wird der Lagerbestand nicht sofort reduziert, sondern der Lagerbestand wird tatsächlich reduziert, bis ein Benutzer bezahlt, andernfalls wird der Lagerbestand für andere Käufer reserviert. Da der Lagerbestand jedoch erst nach erfolgter Zahlung reduziert wird, kann es bei relativ hoher Parallelität dazu kommen, dass der Käufer nach der Bestellung nicht zahlen kann, weil die Ware möglicherweise von anderen gekauft wurde.
Diese Methode ist relativ kompliziert. Nachdem der Käufer eine Bestellung aufgegeben hat, wird der Lagerbestand für einen bestimmten Zeitraum (z. B. 10 Minuten) reserviert Käufer können nach der Veröffentlichung weiterhin kaufen. Bevor der Käufer zahlt, überprüft das System, ob der Lagerbestand der Bestellung noch reserviert ist: Wenn keine Reservierung vorliegt, wird die Einbehaltung erneut versucht. Wenn der Lagerbestand nicht ausreicht (d. h. die Einbehaltung schlägt fehl), erfolgt keine Zahlung kann fortgefahren werden; wenn die Einbehaltung erfolgreich ist, ist die Zahlung abgeschlossen und der Lagerbestand wird tatsächlich abgezogen.
Apropos Hochverfügbarkeitskonstruktion des Systems: Es handelt sich tatsächlich um ein Systemprojekt, das alle Phasen der Systemkonstruktion berücksichtigen muss, was bedeutet, dass es tatsächlich durchlaufen wird den gesamten Lebenszyklus des Systemaufbaus, wie im Bild unten dargestellt:
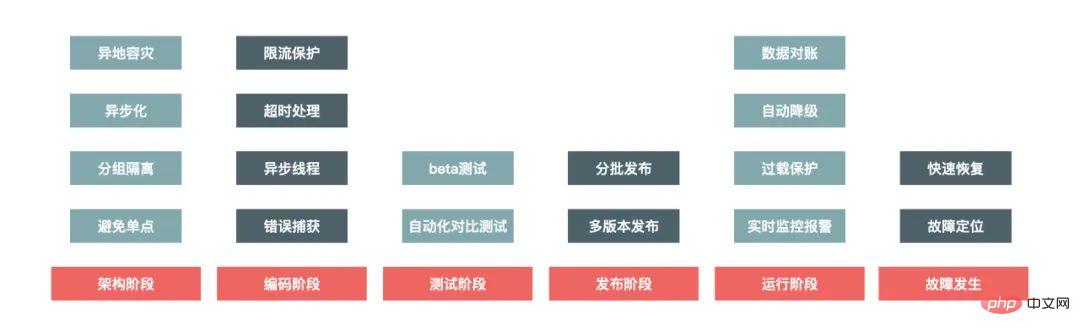
Die Architekturphase berücksichtigt hauptsächlich die Skalierbarkeit und Fehlertoleranz des Systems und vermeidet Einzelpunktprobleme im System. Wenn beispielsweise bei der Einheitsbereitstellung mehrerer Computerräume ein bestimmter Computerraum in einer bestimmten Stadt einen Gesamtausfall erleidet, hat dies dennoch keine Auswirkungen auf den Betrieb der gesamten Website.
Das Wichtigste bei der Codierung besteht darin, die Robustheit des Codes sicherzustellen. Wenn es beispielsweise um Remote-Anrufprobleme geht, muss ein angemessener Timeout-Exit-Mechanismus eingerichtet werden, um zu verhindern, dass er von anderen heruntergezogen wird Systeme und die vom Aufruf zurückgegebene Ergebnismenge müssen ebenfalls sichergestellt werden. Um zu verhindern, dass die zurückgegebenen Ergebnisse den Verarbeitungsbereich des Programms überschreiten, besteht die häufigste Methode darin, Fehlerausnahmen zu erfassen und Standardverarbeitungsergebnisse für unvorhergesehene Fehler bereitzustellen.
Testen dient hauptsächlich dazu, die Abdeckung von Testfällen sicherzustellen und sicherzustellen, dass wir im schlimmsten Fall auch über entsprechende Verarbeitungsverfahren verfügen.
Außerdem gibt es einige Dinge, die bei der Veröffentlichung beachtet werden müssen, da während der Veröffentlichung am wahrscheinlichsten Fehler auftreten, sodass ein Notfall-Rollback-Mechanismus vorhanden sein muss.
Die Laufzeit ist der normale Zustand des Systems. Das Wichtigste im laufenden Zustand ist, dass die Überwachung des Systems genau sein muss Wenn Probleme festgestellt werden, müssen der Alarm korrekt und die Alarmdaten genau und detailliert sein, um die Fehlerbehebung zu erleichtern.
Wenn ein Fehler auftritt, ist das Erste und Wichtigste, den Verlust rechtzeitig zu stoppen. Wenn beispielsweise der Produktpreis aufgrund eines Programmproblems falsch ist, muss das Produkt aus dem Regal genommen werden oder der Kauflink muss rechtzeitig geschlossen werden, um größere Vermögensverluste zu verhindern. Dann gilt es, die Dienste zeitnah wiederherstellen zu können, die Ursache zu lokalisieren und das Problem zu beheben.
Wie können wir den normalen Betrieb unseres Systems bei starkem Verkehr maximieren?
Das sogenannte „Downgrade“ bedeutet, dass bestimmte nicht zum Kerngeschäft gehörende Funktionen des Systems eingeschränkt oder heruntergefahren werden, wenn die Kapazität des Systems ein bestimmtes Niveau erreicht, wodurch begrenzte Ressourcen für weitere Kerngeschäfte reserviert werden. Da es sich um einen zielgerichteten und geplanten Ausführungsprozess handelt, benötigen wir für ein Downgrade im Allgemeinen eine Reihe von Plänen zur Koordinierung der Ausführung. Wenn wir es systematisieren, können wir eine Verschlechterung durch ein Planungssystem und ein Vermittlungssystem erreichen.
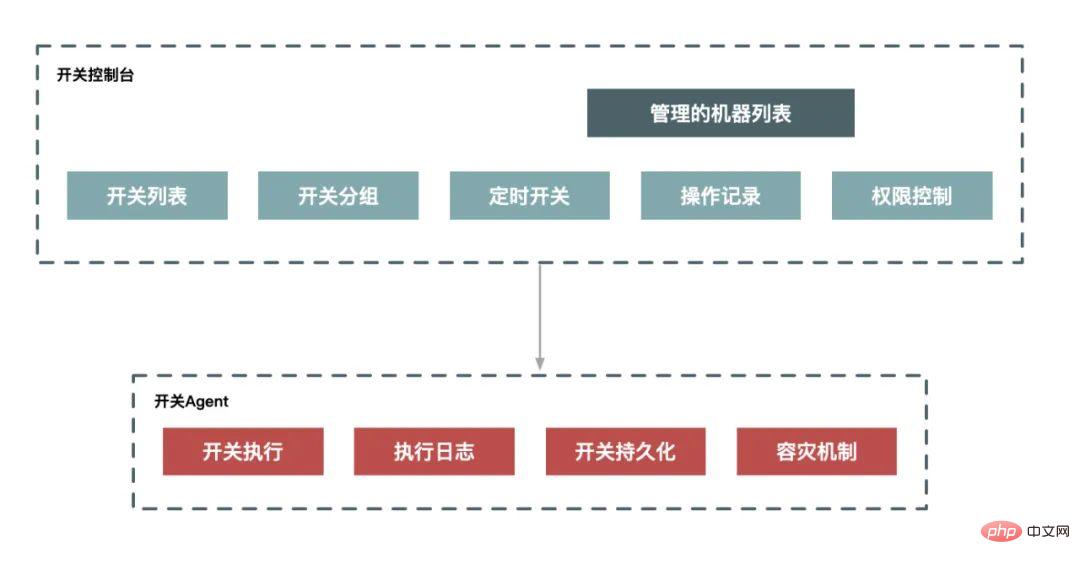
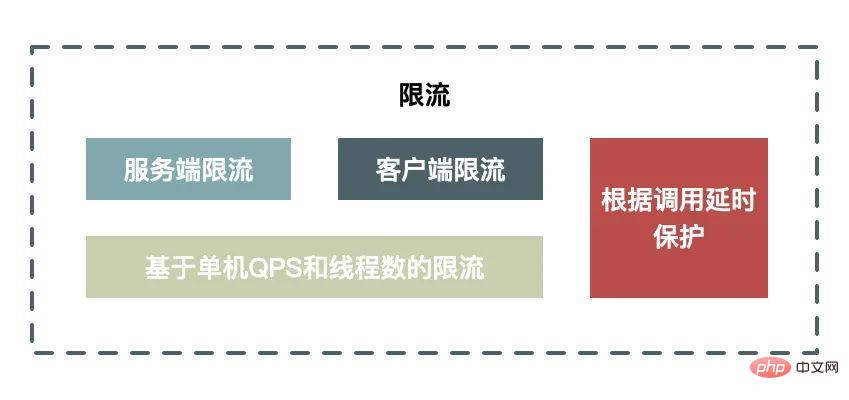
Strombegrenzung bedeutet, dass wir das System schützen müssen, indem wir einen Teil des Datenverkehrs einschränken, wenn die Systemkapazität den Engpass erreicht, und nicht nur eine manuelle Umschaltung durchführen, sondern auch einen automatischen Schutz unterstützen können Maßnahmen.
Vor- und Nachteile der clientseitigen Strombegrenzung und der serverseitigen Strombegrenzung:
Die clientseitige Strombegrenzung hat den Vorteil, dass die Ausgabe von Anforderungen begrenzt und der Systemverbrauch reduziert wird, indem die Ausgabe nutzloser Anforderungen reduziert wird. Der Nachteil besteht darin, dass es bei verstreuten Clients unmöglich ist, einen angemessenen Strombegrenzungsschwellenwert festzulegen: Wenn der Schwellenwert zu klein eingestellt ist, wird der Client eingeschränkt, bevor der Server den Engpass erreicht. Wenn er zu groß eingestellt ist, wird dies nicht der Fall sein in der Lage sein, die Grenze zu erreichen.
Der Vorteil der serverseitigen Strombegrenzung besteht darin, dass ein angemessener Schwellenwert entsprechend der Leistung des Servers festgelegt werden kann. Der Nachteil besteht darin, dass es sich bei den eingeschränkten Anforderungen um ungültige Anforderungen handelt und die Verarbeitung dieser ungültigen Anforderungen selbst auch Serverressourcen verbraucht.
Zähleralgorithmus (festes Fenster)
Der Zähleralgorithmus verwendet einen Zähler, um die Anzahl der Besuche innerhalb eines Zyklus zu akkumulieren Begrenzungsstrategie wird ausgelöst. Zu Beginn des nächsten Zyklus wird der Wert gelöscht und erneut gezählt.
Dieser Algorithmus lässt sich sehr einfach in einer eigenständigen oder verteilten Umgebung implementieren. Er kann mithilfe der inkrementellen atomaren Selbstinkrementierung und der Thread-Sicherheit von Redis problemlos implementiert werden.
Schiebefenster-Algorithmus
Der Schiebefenster-Algorithmus unterteilt den Zeitraum in N kleine Zeiträume, zeichnet die Anzahl der Besuche in jedem kleinen Zeitraum auf und löscht abgelaufene kleine Zeiträume basierend auf dem Zeitgleiten. Dieser Algorithmus kann das kritische Problem des Festfensteralgorithmus gut lösen.
Leaky-Bucket-Algorithmus
Der Leaky-Bucket-Algorithmus besteht darin, die Zugriffsanforderung bei ihrem Eintreffen direkt in den Leaky-Bucket zu stellen. Wenn die aktuelle Kapazität die Obergrenze (aktueller Grenzwert) erreicht hat, wird sie verworfen (was den Fehler auslöst). aktuelle Limitpolitik). Der Leaky Bucket gibt Zugriffsanfragen (d. h. die Anforderungen werden weitergeleitet) mit einer festen Rate frei, bis der Leaky Bucket leer ist.
Token-Bucket-Algorithmus
Der Token-Bucket-Algorithmus besteht darin, dass das Programm Token mit einer Rate von r (r=Zeitraum/aktueller Grenzwert) zum Token-Bucket hinzufügt, bis der Token-Bucket voll ist, und dem Token Token hinzufügt Bucket, wenn die Anforderung eintrifft. Bucket-Anforderungstoken. Wenn das Token erhalten wird, wird die Anforderung weitergeleitet. Andernfalls wird die aktuelle Begrenzungsrichtlinie ausgelöst den Dienst direkt verweigern. Wenn die Systemlast einen bestimmten Schwellenwert erreicht, beispielsweise die CPU-Auslastung 90 % erreicht oder der Systemlastwert 2*CPU-Kerne erreicht, lehnt das System alle Anfragen direkt ab. Diese Methode ist die heftigste, aber auch effektivste Systemschutzmethode . Für das Flash-Sale-System entwerfen wir beispielsweise einen Überlastschutz in folgenden Aspekten:
Ein einfacher Lawinenprozess:
1) Großflächiger Ausfall des Redis-Clusters;
2) Caching-Fehler, aber es gibt immer noch eine große Anzahl von Anfragen für den Zugriff auf den Cache-Dienst Redis; Bei fehlgeschlagenen Redis-Anfragen werden die Anfragen an die Datenbank umgeleitet
4) Datenbankanfragen nehmen stark zu, was dazu führt, dass die Datenbank abstürzt
5) Da die meisten Ihrer Anwendungsdienste auf die Datenbank- und Redis-Dienste angewiesen sind, wird dies bald der Fall sein verursachen eine Lawine des Serverclusters und schließlich wird das gesamte System vollständig zusammenbrechen.
Lösung:
Vorab: Hochverfügbarer Cache Hochverfügbarer Cache soll den gesamten Cache-Ausfall verhindern. Selbst wenn einzelne Knoten, Maschinen oder sogar Computerräume heruntergefahren werden, kann das System weiterhin Dienste bereitstellen und sowohl Redis Sentinel als auch Redis Cluster können eine hohe Verfügbarkeit erreichen.
Laufend: Cache-Downgrade (vorübergehende Unterstützung) Wie stellen wir sicher, dass der Dienst weiterhin verfügbar ist, wenn ein starker Anstieg der Besuche zu Problemen mit dem Dienst führt? Hystrix, das in China weit verbreitet ist, verwendet drei Methoden: Sicherung, Herabstufung und Strombegrenzung, um Verluste nach Lawinen zu reduzieren. Solange die Datenbank nicht tot ist, kann das System immer auf Anfragen reagieren. Kommen wir nicht jedes Mal zum Frühlingsfest 12306 hierher? Solange Sie noch antworten können, haben Sie zumindest die Chance, ein Ticket zu ergattern. Nach dem Ereignis: Redis-Sicherung und schnelles Aufwärmen 1) Redis-Datensicherung und -wiederherstellung 2) Schnelles Cache-Aufwärmen Cache-Aufschlüsselung bedeutet, dass der Hotspot-Datenspeicher abläuft. Mehrere Threads fordern gleichzeitig Hotspot-Daten an. Da der Cache gerade abgelaufen ist, werden alle gleichzeitigen Anforderungen an die Datenbank gesendet, um Daten abzufragen. Lösung: Tatsächlich erfolgt der Cache-Ausfall in den meisten tatsächlichen Geschäftsszenarien in Echtzeit, aber er wird die Datenbank nicht zu stark belasten, da im allgemeinen Unternehmensgeschäft das Ausmaß der Parallelität nicht so hoch sein wird hoch . Wenn Ihnen das passiert, können Sie diese Hotspot-Schlüssel natürlich so einstellen, dass sie niemals ablaufen. Eine andere Methode besteht darin, eine Mutex-Sperre zu verwenden, um den Thread-Zugriff auf die Abfragedatenbank zu steuern. Dies führt jedoch zu einer Verringerung des Systemdurchsatzes und muss in tatsächlichen Situationen verwendet werden. Cache-Penetration bezieht sich auf die Abfrage von Daten, die definitiv nicht vorhanden sind. Da sich keine Informationen über die Daten im Cache befinden, werden diese direkt auf der Datenbankebene abgefragt Diese Art der Abfrage von Daten, die nicht vorhanden sein dürfen, kann eine Gefahr für das System darstellen Darf nicht vorhanden sein, um häufige Anfragen an das System zu stellen, nein, um genau zu sein, Angriffe auf das System, die Anfragen erreichen die Datenbankschicht, was zu Datenbanklähmungen und Systemausfällen führt. Lösung: Die Lösungen in der Cache-Penetrationsbranche sind relativ ausgereift. Die am häufigsten verwendeten sind die folgenden: Da dieser Artikel ein theoretischer Artikel ist, enthält der gesamte Artikel keine einzige Codezeile, sondern was im Artikel vorgeschlagen wird, ist im Grunde das, was im Flash-Sale-System passiert ist, und Die Probleme, die in jedem System auftreten können, sind unterschiedlich. Cache-Aufschlüsselung
Cache-Penetration
Zusammenfassung
Das obige ist der detaillierte Inhalt vonMehr als 6.000 Wörter |. Punkte, die beim Entwerfen des Flash Kill-Systems zu beachten sind. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



