
 Technologie-Peripheriegeräte
KI
Erstellen Sie eine LLM-Anwendung: Nutzen Sie die Vektorsuchfunktionen von Azure Cognitive Services
Technologie-Peripheriegeräte
KI
Erstellen Sie eine LLM-Anwendung: Nutzen Sie die Vektorsuchfunktionen von Azure Cognitive Services
Erstellen Sie eine LLM-Anwendung: Nutzen Sie die Vektorsuchfunktionen von Azure Cognitive Services

Autor |. Simon Bisson
Kuratiert |. Die kognitive Such-API von Microsoft bietet jetzt eine Vektorsuche als Dienst für die Verwendung mit großen Sprachmodellen in Azure OpenAI und mehr.
Tools wie Semantic Core, TypeChat und LangChain ermöglichen die Erstellung von Anwendungen rund um generative KI-Technologien wie Azure OpenAI. Dies liegt daran, dass sie die Auferlegung von Einschränkungen für das zugrunde liegende große Sprachmodell (LLM) ermöglichen, das als Werkzeug zum Erstellen und Ausführen von Schnittstellen in natürlicher Sprache verwendet werden kann
Im Wesentlichen ist ein LLM ein Werkzeug zum Navigieren in semantischen Räumen, in denen tiefe neuronale The Das Netzwerk kann ausgehend vom ersten Hinweis die nächste Silbe in einer Kette von Token vorhersagen. Wenn die Eingabeaufforderung offen ist, überschreitet das LLM möglicherweise seinen Eingabeumfang und produziert etwas, das vernünftig erscheint, in Wirklichkeit aber völliger Unsinn ist.
So wie wir alle dazu neigen, den Ergebnissen von Suchmaschinen zu vertrauen, neigen wir auch dazu, den Ergebnissen von LLM zu vertrauen, weil wir sie als einen weiteren Aspekt vertrauter Technologie betrachten. Das Training großer Sprachmodelle mithilfe vertrauenswürdiger Daten von Websites wie Wikipedia, Stack Overflow und Reddit vermittelt jedoch kein Verständnis des Inhalts, sondern ermöglicht lediglich die Generierung von Text, der denselben Mustern wie der Text in diesen Quellen folgt. Manchmal ist die Ausgabe korrekt, manchmal jedoch auch falsch.
Wie vermeiden wir Fehler und bedeutungslose Ausgaben großer Sprachmodelle und stellen sicher, dass unsere Benutzer genaue und vernünftige Antworten auf ihre Fragen erhalten?
1. Begrenzen Sie große Modelle mit semantischen Speicherbeschränkungen
Was wir tun müssen, ist LLM zu begrenzen, um sicherzustellen, dass es nur Text aus kleineren Datensätzen generiert. Hier kommt der neue LLM-basierte Entwicklungsstack von Microsoft ins Spiel. Es bietet die notwendigen Tools, um Ihr Modell zu steuern und zu verhindern, dass es Fehler generiert.
Sie können ein bestimmtes Ausgabeformat erzwingen, indem Sie Tools wie TypeChat verwenden, oder Orchestrierungspipelines wie Semantic Kernel verwenden, um andere vertrauenswürdige Informationsquellen zu verarbeiten. Dadurch wird das Modell effektiv „verwurzelt“. das Modell in einem bekannten semantischen Raum, wodurch das LLM eingeschränkt wird. Hier kann LLM das tun, was es gut kann: die konstruierte Eingabeaufforderung zusammenfassen und auf der Grundlage dieser Eingabeaufforderung Text generieren, ohne dass es zu Überschreitungen kommt (oder zumindest die Wahrscheinlichkeit einer Überschreitung erheblich verringert wird).
Was Microsoft „semantisches Gedächtnis“ nennt, ist die Grundlage der letzten Methode. Das semantische Gedächtnis verwendet die Vektorsuche, um Hinweise bereitzustellen, die zur Bereitstellung der sachlichen Ausgabe des LLM verwendet werden können. Die Vektordatenbank verwaltet den Kontext der anfänglichen Eingabeaufforderung, die Vektorsuche sucht nach gespeicherten Daten, die mit der anfänglichen Benutzerabfrage übereinstimmen, und das LLM generiert den Text basierend auf diesen Daten. Sehen Sie sich diesen Ansatz in Bing Chat in Aktion an, der die nativen Vektorsuchtools von Bing verwendet, um Antworten zu erstellen, die aus seiner Suchdatenbank abgeleitet werden.
Semantisches Gedächtnis ermöglicht Vektordatenbanken und Vektorsuchen, um LLM-basierte Anwendungen bereitzustellen. Sie können eine der wachsenden Zahl von Open-Source-Vektordatenbanken verwenden oder Vektorindizes zu Ihren vertrauten SQL- und NoSQL-Datenbanken hinzufügen. Ein neues Produkt, das besonders nützlich erscheint, erweitert Azure Cognitive Search, indem es Ihren Daten einen Vektorindex hinzufügt und eine neue API zum Abfragen dieses Index bereitstellt
2. Vektorindex zu Azure Cognitive Search hinzufügen
Azure Cognitive Search basiert auf der Microsoft-eigenen Suche Werkzeuge. Es bietet eine Kombination aus bekannten Lucene-Abfragen und eigenen Abfragetools in natürlicher Sprache. Azure Cognitive Search ist eine Software-as-a-Service-Plattform, die mithilfe von Cognitive Services-APIs private Daten hosten und auf Inhalte zugreifen kann. Vor kurzem hat Microsoft auch Unterstützung für die Erstellung und Verwendung von Vektorindizes hinzugefügt, die es Ihnen ermöglicht, mithilfe von Ähnlichkeitssuchen relevante Ergebnisse in Ihren Daten einzuordnen und sie in KI-basierten Anwendungen zu verwenden. Dies macht Azure Cognitive Search zu einem idealen Tool für von Azure gehostete LLM-Anwendungen, die mit Semantic Kernel und Azure OpenAI erstellt wurden, und Semantic Kernel-Plugins für Cognitive Search für C# und Python sind ebenfalls verfügbar
Wie bei anderen Azure-Diensten ist Azure Cognitive Search ein verwalteter Dienst Dienst, der mit anderen Azure-Diensten funktioniert. Es ermöglicht Ihnen die Indizierung und Suche in verschiedenen Azure-Speicherdiensten sowie das Hosten von Text, Bildern, Audio und Video. Daten werden in mehreren Regionen gespeichert, was eine hohe Verfügbarkeit gewährleistet und Latenz- und Reaktionszeiten reduziert. Darüber hinaus können Sie für Unternehmensanwendungen Microsoft Entra ID (den neuen Namen für Azure Active Directory) verwenden, um den Zugriff auf private Daten zu steuern.
3 Einbettungsvektoren für Inhalte generieren und speichern. Es ist zu beachten, dass Azure Cognitive Search dies ist ein „Bring Your Own Embedding Vector“-Service. Cognitive Search generiert nicht die benötigten Vektoreinbettungen, daher müssen Sie Azure OpenAI oder die OpenAI-Einbettungs-API verwenden, um Einbettungen für Ihre Inhalte zu erstellen. Dies erfordert möglicherweise die Aufteilung großer Dateien in Blöcke, um sicherzustellen, dass Sie die Token-Grenzwerte des Dienstes einhalten. Seien Sie bereit, bei Bedarf neue Tabellen zu erstellen, um Vektordaten zu indizieren.
In der kognitiven Azure-Suche verwendet die Vektorsuche ein Modell des nächsten Nachbarn, um eine vom Benutzer ausgewählte Anzahl von Dokumenten zurückzugeben, die der ursprünglichen Abfrage ähneln. Dieser Prozess ruft die Vektorindizierung auf, indem er die Vektoreinbettung der ursprünglichen Abfrage verwendet und ähnliche Vektor- und Indexinhalte aus der Datenbank zurückgibt, die von der LLM-Eingabeaufforderung verwendet werden können
Microsoft verwendet diesen Vektorspeicher als Teil des Retrieval Augmented Generation (RAG)-Entwurfsmusters von Azure Machine Learning und in Verbindung mit seinem Prompt-Flow-Tool. RAG nutzt die Vektorindizierung in der kognitiven Suche, um den Kontext aufzubauen, der die Grundlage für LLM-Eingabeaufforderungen bildet. Dies bietet Ihnen eine einfache Möglichkeit, Vektorindizes zu erstellen und zu verwenden, beispielsweise um die Anzahl ähnlicher Dokumente festzulegen, die von einer einfachen Abfrage zurückgegeben werden. Beginnen Sie mit der Erstellung von Ressourcen für Azure OpenAI und Cognitive Search in derselben Region. Dadurch können Sie den Suchindex mit minimaler Latenz mit Einbettungen laden. Sie müssen die Azure OpenAI-API und die Cognitive Search-API aufrufen, um den Index zu laden. Daher empfiehlt es sich, sicherzustellen, dass Ihr Code auf mögliche Ratenbeschränkungen im Dienst für Sie reagieren kann, indem Sie Code hinzufügen, der Wiederholungsversuche verwaltet. Wenn Sie die Service-API verwenden, sollten Sie asynchrone Aufrufe verwenden, um Einbettungen zu generieren und Indizes zu laden.
Vektoren werden in Suchindizes als Vektorfelder gespeichert, wobei Vektoren Gleitkommazahlen mit Abmessungen sind. Diese Vektoren werden durch einen hierarchisch navigierbaren Small-World-Nachbarschaftsgraphen abgebildet, der Vektoren in Nachbarschaften ähnlicher Vektoren sortiert und so den eigentlichen Prozess der Suche nach Vektorindizes beschleunigt.
Nachdem Sie das Indexschema für die Vektorsuche definiert haben, können Sie Daten in den Index für die kognitive Suche laden. Beachten Sie, dass Daten möglicherweise mehreren Vektoren zugeordnet sind. Wenn Sie beispielsweise die kognitive Suche zum Hosten von Unternehmensdokumenten verwenden, verfügen Sie möglicherweise über einen separaten Vektor für wichtige Dokumentmetadatenbegriffe und Dokumentinhalte. Der Datensatz muss als JSON-Dokument gespeichert werden, was die Verwendung der Ergebnisse zum Zusammenstellen des Eingabeaufforderungskontexts vereinfacht. Der Index muss nicht das Quelldokument enthalten, da er die Verwendung der gängigsten Azure-Speicheroptionen unterstützt
Bevor Sie die Abfrage ausführen, müssen Sie zunächst das Einbettungsmodell Ihrer Wahl mit dem Abfragetext aufrufen. Dadurch wird ein mehrdimensionaler Vektor zurückgegeben, den Sie zum Durchsuchen des Index Ihrer Wahl verwenden können. Geben Sie beim Aufruf der Vektorsuch-API den Zielvektorindex, die gewünschte Anzahl von Übereinstimmungen und die relevanten Textfelder im Index an. Die Auswahl des geeigneten Ähnlichkeitsmaßes kann bei Abfragen sehr hilfreich sein. Am häufigsten wird dabei die Kosinusmetrik verwendet
5 Über einfache Textvektoren hinaus
Die Vektorfunktionen von Azure Cognitive Search gehen über den bloßen Abgleich von Text hinaus. Cognitive Search kann mit mehrsprachigen Einbettungen verwendet werden, um Dokumentsuchen in mehreren Sprachen zu unterstützen. Sie können auch komplexere APIs verwenden. Sie können beispielsweise die semantischen Suchtools von Bing in Hybrid Search kombinieren, um genauere Ergebnisse zu liefern und so die Qualität der Ausgabe von LLM-basierten Anwendungen zu verbessern.
Microsoft produziert schnell die Tools und Technologien, die es zum Aufbau seiner eigenen GPT-4-basierten Bing-Suchmaschine sowie verschiedener Copiloten verwendet hat. Orchestrierungs-Engines wie Semantic Kernel und der Prompt Flow von Azure AI Studio sind der Kern des Microsoft-Ansatzes für die Arbeit mit großen Sprachmodellen. Nachdem diese Grundlagen nun gelegt sind, sehen wir, wie das Unternehmen weitere der notwendigen Basistechnologien einführt. Vektorsuche und Vektorindizierung sind der Schlüssel zur Bereitstellung präziser Antworten. Durch die Entwicklung vertrauter Tools zur Bereitstellung dieser Dienste hilft Microsoft uns, die Kosten und den Lernaufwand zu minimieren
Das obige ist der detaillierte Inhalt vonErstellen Sie eine LLM-Anwendung: Nutzen Sie die Vektorsuchfunktionen von Azure Cognitive Services. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

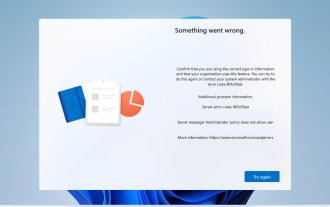 Fehlercode 801c03ed: So beheben Sie ihn unter Windows 11
Oct 04, 2023 pm 06:05 PM
Fehlercode 801c03ed: So beheben Sie ihn unter Windows 11
Oct 04, 2023 pm 06:05 PM
Fehler 801c03ed wird normalerweise von der folgenden Meldung begleitet: Die Administratorrichtlinie erlaubt diesem Benutzer nicht, dem Gerät beizutreten. Diese Fehlermeldung verhindert, dass Sie Windows installieren und sich einem Netzwerk anschließen können, wodurch Sie Ihren Computer nicht mehr verwenden können. Daher ist es wichtig, dieses Problem so schnell wie möglich zu beheben. Was ist der Fehlercode 801c03ed? Dies ist ein Windows-Installationsfehler, der aus folgendem Grund auftritt: Das Azure-Setup lässt keinen Beitritt neuer Benutzer zu. Geräteobjekte sind in Azure nicht aktiviert. Hardware-Hash-Fehler im Azure-Panel. Wie behebe ich den Fehlercode 03c11ed unter Windows 801? 1. Überprüfen Sie die Intune-Einstellungen. Melden Sie sich beim Azure-Portal an. Navigieren Sie zu Geräte und wählen Sie Geräteeinstellungen. Ändern Sie „Benutzer können
 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Caltech-Chinesen nutzen KI, um mathematische Beweise zu untergraben! Beschleunigen Sie 5-mal schockiert Tao Zhexuan, 80 % der mathematischen Schritte sind vollständig automatisiert
Apr 23, 2024 pm 03:01 PM
Caltech-Chinesen nutzen KI, um mathematische Beweise zu untergraben! Beschleunigen Sie 5-mal schockiert Tao Zhexuan, 80 % der mathematischen Schritte sind vollständig automatisiert
Apr 23, 2024 pm 03:01 PM
LeanCopilot, dieses formale Mathematikwerkzeug, das von vielen Mathematikern wie Terence Tao gelobt wurde, hat sich erneut weiterentwickelt? Soeben gab Caltech-Professorin Anima Anandkumar bekannt, dass das Team eine erweiterte Version des LeanCopilot-Papiers veröffentlicht und die Codebasis aktualisiert hat. Adresse des Bildpapiers: https://arxiv.org/pdf/2404.12534.pdf Die neuesten Experimente zeigen, dass dieses Copilot-Tool mehr als 80 % der mathematischen Beweisschritte automatisieren kann! Dieser Rekord ist 2,3-mal besser als der vorherige Basiswert von Aesop. Und wie zuvor ist es Open Source unter der MIT-Lizenz. Auf dem Bild ist er Song Peiyang, ein chinesischer Junge
 Wie wirkt sich LLM von „Mensch + RPA' bis „Mensch + generative KI + RPA' auf die RPA-Mensch-Computer-Interaktion aus?
Jun 05, 2023 pm 12:30 PM
Wie wirkt sich LLM von „Mensch + RPA' bis „Mensch + generative KI + RPA' auf die RPA-Mensch-Computer-Interaktion aus?
Jun 05, 2023 pm 12:30 PM
Bildquelle@visualchinesewen|Wang Jiwei Wie wirkt sich LLM von „Mensch + RPA“ auf „Mensch + generative KI + RPA“ auf die RPA-Mensch-Computer-Interaktion aus? Wie wirkt sich LLM aus einer anderen Perspektive auf RPA aus der Perspektive der Mensch-Computer-Interaktion aus? Wird RPA, das die Mensch-Computer-Interaktion in der Programmentwicklung und Prozessautomatisierung betrifft, nun auch durch LLM verändert? Wie wirkt sich LLM auf die Mensch-Computer-Interaktion aus? Wie verändert generative KI die RPA-Mensch-Computer-Interaktion? Erfahren Sie mehr darüber in einem Artikel: Die Ära der großen Modelle steht vor der Tür und die auf LLM basierende generative KI verändert die RPA-Mensch-Computer-Interaktion rasant. Die generative KI definiert die Mensch-Computer-Interaktion neu und LLM beeinflusst die Veränderungen in der RPA-Softwarearchitektur. Wenn man fragt, welchen Beitrag RPA zur Programmentwicklung und -automatisierung leistet, lautet eine der Antworten, dass es die Mensch-Computer-Interaktion (HCI, h
 Plaud bringt den tragbaren NotePin AI-Recorder für 169 US-Dollar auf den Markt
Aug 29, 2024 pm 02:37 PM
Plaud bringt den tragbaren NotePin AI-Recorder für 169 US-Dollar auf den Markt
Aug 29, 2024 pm 02:37 PM
Plaud, das Unternehmen hinter dem Plaud Note AI Voice Recorder (erhältlich bei Amazon für 159 US-Dollar), hat ein neues Produkt angekündigt. Das als NotePin bezeichnete Gerät wird als KI-Speicherkapsel beschrieben und ist wie der Humane AI Pin tragbar. Der NotePin ist
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
Jun 12, 2024 am 10:32 AM
GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) erfreut sich zunehmender Beliebtheit und hat sich zu einer leistungsstarken Ergänzung zu herkömmlichen Vektorsuchmethoden entwickelt. Diese Methode nutzt die strukturellen Merkmale von Graphdatenbanken, um Daten in Form von Knoten und Beziehungen zu organisieren und dadurch die Tiefe und kontextbezogene Relevanz der abgerufenen Informationen zu verbessern. Diagramme haben einen natürlichen Vorteil bei der Darstellung und Speicherung vielfältiger und miteinander verbundener Informationen und können problemlos komplexe Beziehungen und Eigenschaften zwischen verschiedenen Datentypen erfassen. Vektordatenbanken können diese Art von strukturierten Informationen nicht verarbeiten und konzentrieren sich mehr auf die Verarbeitung unstrukturierter Daten, die durch hochdimensionale Vektoren dargestellt werden. In RAG-Anwendungen können wir durch die Kombination strukturierter Diagrammdaten und unstrukturierter Textvektorsuche gleichzeitig die Vorteile beider nutzen, worauf in diesem Artikel eingegangen wird. Struktur
 Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Mar 01, 2024 pm 09:16 PM
Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Mar 01, 2024 pm 09:16 PM
Da sich die Leistung groß angelegter Open-Source-Sprachmodelle weiter verbessert, hat sich auch die Leistung beim Schreiben und Analysieren von Code, Empfehlungen, Textzusammenfassungen und Frage-Antwort-Paaren (QA) verbessert. Aber wenn es um die Qualitätssicherung geht, mangelt es LLM oft an Problemen im Zusammenhang mit ungeschulten Daten, und viele interne Dokumente werden im Unternehmen aufbewahrt, um Compliance, Geschäftsgeheimnisse oder Datenschutz zu gewährleisten. Wenn diese Dokumente abgefragt werden, kann LLM Halluzinationen hervorrufen und irrelevante, erfundene oder inkonsistente Inhalte produzieren. Eine mögliche Technik zur Bewältigung dieser Herausforderung ist Retrieval Augmented Generation (RAG). Dabei geht es darum, die Antworten durch Verweise auf maßgebliche Wissensdatenbanken über die Trainingsdatenquelle hinaus zu verbessern, um die Qualität und Genauigkeit der Generierung zu verbessern. Das RAG-System umfasst ein Retrieval-System zum Abrufen relevanter Dokumentfragmente aus dem Korpus
