
 Backend-Entwicklung
C++
Wie gehe ich mit Datenstatistikproblemen bei der C++-Big-Data-Entwicklung um?
Backend-Entwicklung
C++
Wie gehe ich mit Datenstatistikproblemen bei der C++-Big-Data-Entwicklung um?
Wie gehe ich mit Datenstatistikproblemen bei der C++-Big-Data-Entwicklung um?


Wie gehe ich mit Datenstatistikproblemen in der C++-Big-Data-Entwicklung um?
Mit dem Aufkommen des Big-Data-Zeitalters ist Datenstatistik in verschiedenen Bereichen zu einem unverzichtbaren Bestandteil geworden. Bei der C++-Big-Data-Entwicklung müssen wir häufig statistische Analysen großer Datenmengen durchführen, um nützliche Informationen und Erkenntnisse zu erhalten. In diesem Artikel werden einige Methoden zur Behandlung von Datenstatistikproblemen in der C++-Big-Data-Entwicklung vorgestellt und entsprechende Codebeispiele bereitgestellt.
- Verwenden Sie die STL-Bibliothek für Datenstatistiken
Die STL (Standard Template Library) in der C++-Standardbibliothek enthält verschiedene Vorlagenklassen und Funktionen für Container und Algorithmen, die Daten einfach speichern und verarbeiten können. Hier ist ein einfaches Beispiel, das zeigt, wie Vektorcontainer und algorithmische Funktionen in der STL-Bibliothek verwendet werden, um die Summe, den Durchschnitt und das Maximum einer Reihe von Ganzzahlen zu berechnen:
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
int sum = std::accumulate(data.begin(), data.end(), 0); // 计算总和
double average = static_cast<double>(sum) / data.size(); // 计算平均值
int max = *std::max_element(data.begin(), data.end()); // 计算最大值
std::cout << "Sum: " << sum << std::endl;
std::cout << "Average: " << average << std::endl;
std::cout << "Max: " << max << std::endl;
return 0;
}- Verwenden Sie Bibliotheken von Drittanbietern für effiziente Datenstatistiken
In Neben der STL-Bibliothek gibt es in C++ viele Bibliotheken von Drittanbietern, mit denen sich Datenstatistiken effizienter durchführen lassen. Beispielsweise bietet die Boost-Bibliothek eine Fülle mathematischer und statistischer Funktionen, mit denen sich verschiedene statistische Berechnungen problemlos durchführen lassen. Das Folgende ist ein Beispiel für eine lineare Regressionsanalyse mit der Boost-Bibliothek:
#include <iostream>
#include <vector>
#include <boost/math/statistics/linear_regression.hpp>
int main() {
std::vector<double> x = {1.0, 2.0, 3.0, 4.0, 5.0};
std::vector<double> y = {2.0, 4.0, 6.0, 8.0, 10.0};
boost::math::statistics::linear_regression<double> reg;
reg.add(x.begin(), x.end(), y.begin(), y.end());
double slope = reg.slope();
double intercept = reg.intercept();
std::cout << "Slope: " << slope << std::endl;
std::cout << "Intercept: " << intercept << std::endl;
return 0;
}- Paralleles Computing beschleunigt die Datenstatistik
Bei der Big-Data-Entwicklung ist die Datenmenge oft sehr groß und Single-Thread-Berechnungen sind möglicherweise zu langsam. Der Einsatz paralleler Computertechnologie kann die Geschwindigkeit der Datenstatistik verbessern. Es gibt Bibliotheken in C++, die paralleles Rechnen ermöglichen, beispielsweise OpenMP und TBB. Das Folgende ist ein Beispiel für die Verwendung der OpenMP-Bibliothek für die parallele Summierung:
#include <iostream>
#include <vector>
#include <omp.h>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < data.size(); ++i) {
sum += data[i];
}
std::cout << "Sum: " << sum << std::endl;
return 0;
}Das obige Beispiel zeigt, wie Datenstatistikprobleme bei der C++-Big-Data-Entwicklung mithilfe der STL-Bibliothek, Bibliotheken von Drittanbietern und paralleler Computertechnologie behandelt werden. Dies ist natürlich nur die Spitze des Eisbergs. C++ verfügt über viele weitere leistungsstarke Funktionen und Tools für die Datenstatistik. Ich hoffe, dass dieser Artikel den Lesern einige Referenzen und Inspirationen bieten und allen dabei helfen kann, Datenstatistikprobleme bei der C++-Big-Data-Entwicklung effizienter zu bewältigen.
Das obige ist der detaillierte Inhalt vonWie gehe ich mit Datenstatistikproblemen bei der C++-Big-Data-Entwicklung um?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Gründe, warum Tabellen in Oracle gesperrt sind und wie man damit umgeht
Mar 03, 2024 am 09:36 AM
Gründe, warum Tabellen in Oracle gesperrt sind und wie man damit umgeht
Mar 03, 2024 am 09:36 AM
Gründe für Tabellensperren in Oracle und wie man damit umgeht In Oracle-Datenbanken sind Tabellensperren ein häufiges Phänomen und es gibt viele Gründe für Tabellensperren. In diesem Artikel werden einige häufige Gründe für die Sperrung von Tabellen untersucht und einige Verarbeitungsmethoden sowie zugehörige Codebeispiele bereitgestellt. 1. Arten von Sperren In der Oracle-Datenbank werden Sperren hauptsächlich in gemeinsame Sperren (SharedLock) und exklusive Sperren (ExclusiveLock) unterteilt. Für Lesevorgänge werden gemeinsame Sperren verwendet, sodass mehrere Sitzungen gleichzeitig dieselbe Ressource lesen können.
 JSON-Verarbeitungsmethoden und Implementierung in C++
Aug 21, 2023 pm 11:58 PM
JSON-Verarbeitungsmethoden und Implementierung in C++
Aug 21, 2023 pm 11:58 PM
JSON ist ein leichtes Datenaustauschformat, das leicht zu lesen und zu schreiben sowie für Maschinen leicht zu analysieren und zu generieren ist. Die Verwendung des JSON-Formats erleichtert die Datenübertragung zwischen verschiedenen Systemen. In C++ gibt es viele Open-Source-JSON-Bibliotheken für die JSON-Verarbeitung. In diesem Artikel werden einige häufig verwendete JSON-Verarbeitungsmethoden und -Implementierungen in C++ vorgestellt. JSON-Verarbeitungsmethoden in C++ RapidJSON RapidJSON ist ein schneller C++-JSON-Parser/Generator, der DOM, SAX und bereitstellt
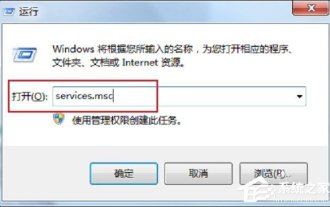 Umgang mit dem nicht verfügbaren RPC-Server im Win7-System
Jul 19, 2023 pm 04:57 PM
Umgang mit dem nicht verfügbaren RPC-Server im Win7-System
Jul 19, 2023 pm 04:57 PM
Bei der Nutzung von Computern stoßen wir häufig auf einige Probleme, von denen einige Menschen überfordern können. Bei einigen Benutzern tritt dieses Problem auf. Wenn sie den Computer einschalten und den Drucker verwenden, erscheint eine Meldung, dass der RPC-Server nicht verfügbar ist. Was ist passiert? was mache ich? Als Reaktion auf dieses Problem teilen wir Ihnen die Lösung für die Nichtverfügbarkeit des Win7rpc-Servers mit. 1. Drücken Sie die Tasten „Win+R“, um „Ausführen“ zu öffnen, und geben Sie „services.msc“ in das Eingabefeld „Ausführen“ ein. 2. Nachdem Sie die Dienstliste eingegeben haben, suchen Sie den RemoteProcedureCall(RPC)Locator-Dienst. 3. Wählen Sie den Dienst aus und doppelklicken Sie. Der Standardstatus ist wie folgt: 4. Ändern Sie den Starttyp des RPCLoader-Dienstes in „Automatisch“.
 Umgang mit Array-Out-of-Bounds-Problemen in der C++-Entwicklung
Aug 21, 2023 pm 10:04 PM
Umgang mit Array-Out-of-Bounds-Problemen in der C++-Entwicklung
Aug 21, 2023 pm 10:04 PM
Umgang mit Array-Out-of-Bounds-Problemen in der C++-Entwicklung In der C++-Entwicklung sind Array-Out-of-Bounds-Probleme ein häufiger Fehler, der zu Programmabstürzen, Datenbeschädigung und sogar Sicherheitslücken führen kann. Daher ist die korrekte Behandlung von Array-Out-of-Bounds-Problemen ein wichtiger Teil der Sicherstellung der Programmqualität. In diesem Artikel werden einige gängige Verarbeitungsmethoden und Vorschläge vorgestellt, die Entwicklern helfen sollen, Probleme mit Array-Out-of-Bounds zu vermeiden. Zunächst ist es wichtig, die Ursache des Array-Out-of-Bounds-Problems zu verstehen. „Array außerhalb der Grenzen“ bezieht sich auf einen Index, der beim Zugriff auf ein Array seinen Definitionsbereich überschreitet. Dies geschieht normalerweise im folgenden Szenario: Beim Zugriff auf das Array werden negative Zahlen verwendet
 So verwenden Sie PHP-Funktionen zur Verarbeitung großer Datenmengen
Jun 16, 2023 am 10:45 AM
So verwenden Sie PHP-Funktionen zur Verarbeitung großer Datenmengen
Jun 16, 2023 am 10:45 AM
Mit der Entwicklung des Internets sind wir täglich großen Datenmengen ausgesetzt, die gespeichert, verarbeitet und analysiert werden müssen. PHP ist eine serverseitige Skriptsprache, die heute weit verbreitet ist und auch für die Verarbeitung großer Datenmengen verwendet wird. Bei der Verarbeitung großer Datenmengen kann es leicht zu Speicherüberlauf und Leistungsengpässen kommen. In diesem Artikel wird erläutert, wie Sie mit PHP-Funktionen große Datenmengen verarbeiten. 1. Aktivieren Sie das Speicherlimit. Standardmäßig beträgt das Speicherlimit von PHP 128 MB, was bei der Verarbeitung großer Datenmengen zu einem Problem werden kann. Größer zu handhaben
 Was tun, wenn der MySQL-Verbindungsfehler 1017 auftritt?
Jun 30, 2023 am 11:57 AM
Was tun, wenn der MySQL-Verbindungsfehler 1017 auftritt?
Jun 30, 2023 am 11:57 AM
Wie gehe ich mit dem MySQL-Verbindungsfehler 1017 um? MySQL ist ein relationales Open-Source-Datenbankverwaltungssystem, das häufig in der Website-Entwicklung und Datenspeicherung eingesetzt wird. Bei der Verwendung von MySQL können jedoch verschiedene Fehler auftreten. Einer der häufigsten Fehler ist der Verbindungsfehler 1017 (MySQL-Fehlercode 1017). Der Verbindungsfehler 1017 weist auf einen Datenbankverbindungsfehler hin, der normalerweise durch einen falschen Benutzernamen oder ein falsches Passwort verursacht wird. Wenn MySQL die Authentifizierung mit dem angegebenen Benutzernamen und Passwort nicht durchführen kann
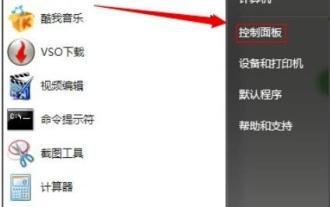 Schritte zur Lösung des Problems der hohen Speichernutzung in Win7
Dec 27, 2023 pm 10:27 PM
Schritte zur Lösung des Problems der hohen Speichernutzung in Win7
Dec 27, 2023 pm 10:27 PM
Der Speicherplatz des Computers hängt von der Laufruhe des Computers ab. Mit der Zeit wird der Speicher voll und die Auslastung wird zu hoch sein, was zu einer Verzögerung des Computers führt. Werfen wir einen Blick auf die folgenden Lösungen. Was tun, wenn die Speicherauslastung von Win7 zu hoch ist: Methode 1. Automatische Updates deaktivieren 1. Klicken Sie auf „Start“, um die „Systemsteuerung“ zu öffnen. 2. Klicken Sie auf „Windows Update“. 3. Klicken Sie links auf „Einstellungen ändern“. 4. Wählen Sie das aus „Niemals nach Updates suchen“-Methode 2. Software-Löschung: Deinstallieren Sie alle nutzlosen Software. Methode 3: Schließen Sie Prozesse und beenden Sie alle nutzlosen Prozesse, sonst wird im Hintergrund viel Werbung angezeigt, die den Speicher füllt. Methode 4: Deaktivieren Sie auch viele nutzlose Dienste im System, was nicht nur die Sicherheit gewährleistet, sondern auch Platz spart.
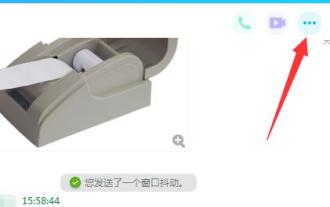 So lösen Sie QQ-Remotedesktopverbindungsprobleme
Dec 26, 2023 am 11:55 AM
So lösen Sie QQ-Remotedesktopverbindungsprobleme
Dec 26, 2023 am 11:55 AM
QQ ist eine Chat-Software von Tencent. Fast jeder hat ein QQ-Konto und kann beim Chatten eine Verbindung herstellen. Einige Benutzer haben jedoch das Problem, dass sie keine Verbindung herstellen können. Schauen wir uns unten um. Was tun, wenn QQ Remote Desktop keine Verbindung herstellen kann: 1. Öffnen Sie die Chat-Oberfläche, klicken Sie auf das Symbol „…“ in der oberen rechten Ecke. 2. Wählen Sie das rote Computersymbol aus und klicken Sie auf „Einstellungen“. 3. Klicken Sie auf „Berechtigungen festlegen—> „Remotedesktop“ 4. Aktivieren Sie „Remotedesktop die Verbindung mit diesem Computer zulassen“
