
 Backend-Entwicklung
C++
Wie nutzt man C++ für eine leistungsstarke Verarbeitung natürlicher Sprache und intelligenten Dialog?
Backend-Entwicklung
C++
Wie nutzt man C++ für eine leistungsstarke Verarbeitung natürlicher Sprache und intelligenten Dialog?
Wie nutzt man C++ für eine leistungsstarke Verarbeitung natürlicher Sprache und intelligenten Dialog?


Wie nutzt man C++ für leistungsstarke Verarbeitung natürlicher Sprache und intelligenten Dialog?
Einführung:
Natürliche Sprachverarbeitung (NLP) und intelligenter Dialog sind aktuelle Forschungsschwerpunkte im Bereich der künstlichen Intelligenz und werden häufig in der maschinellen Übersetzung, Textanalyse, im intelligenten Kundenservice und anderen Bereichen eingesetzt. In diesem Artikel wird die Verwendung von C++ für die leistungsstarke Verarbeitung natürlicher Sprache und intelligenter Dialoge vorgestellt und Codebeispiele bereitgestellt.
1. Lexikalische Analyse
1. Wortsegmentierungstool
Das Segmentieren von Text ist der erste Schritt in der Verarbeitung natürlicher Sprache, und Sie können zur Verarbeitung das Open-Source-Wortsegmentierungstool in C++ verwenden. MMSEG kann beispielsweise zum Segmentieren von chinesischem Text verwendet werden. Das Folgende ist ein Beispielcode, der MMSEG für die chinesische Wortsegmentierung verwendet:
#include <mmseg/segmenter.h>
void segmentText(const char* text) {
MMSeg::Segmenter segmenter;
if (segmenter.open(text)) {
MMSeg::Chunk chunk;
while (segmenter.getChunk(chunk)) {
cout << chunk.getLexemeText() << endl; // 输出每个词的结果
}
}
} 2. Teil-of-Speech-Tagging
Part-of-Speech-Tagging dient dazu, eine weitere semantische Analyse der Wortsegmentierungsergebnisse durchzuführen, um genauere Informationen für nachfolgende Zwecke bereitzustellen Verarbeitung. Für die Verarbeitung können Sie Open-Source-Tagging-Tools für chinesische Wortarten wie ICTCLAS verwenden. Das Folgende ist ein Beispielcode, der ICTCLAS für die Kennzeichnung von Wortarten verwendet:
#include <ICTCLAS50/ICTCLAS50.h>
void posTagging(const char* text) {
ICTCLAS50 ic;
if (ic.ICTCLAS_Init() != 0) {
ic.ICTCLAS_Exit();
return;
}
int len = strlen(text);
const char* result = ic.ICTCLAS_ParagraphProcess(text, len, false);
if (result) {
// 处理标注结果
cout << result << endl;
}
ic.ICTCLAS_Exit();
} 2. Syntaktische Analyse
Die syntaktische Analyse dient der Analyse der Satzstruktur und der Implementierung einer semantischen Analyse basierend auf Abhängigkeiten. Für die Verarbeitung können Sie Open-Source-Syntaxanalysetools wie Harbin Institute of Technology LTP verwenden. Das Folgende ist ein Beispielcode, der LTP für die Syntaxanalyse verwendet:
#include <ltp/segment_dll.h>
#include <ltp/postag_dll.h>
#include <ltp/parser_dll.h>
void syntacticParsing(const char* text) {
void * segmentor = segmentor_create_segmentor("cws.model");
std::vector<std::string> words;
segmentor_segment(segmentor, text, words);
segmentor_release_segmentor(segmentor);
void * postagger = postagger_create_postagger("pos.model");
std::vector<std::string> tags;
postagger_postag(postagger, words, tags);
postagger_release_postagger(postagger);
void * parser = parser_create_parser("parser.model");
std::vector<int> heads;
std::vector<std::string> deprels;
parser_parse(parser, words, tags, heads, deprels);
parser_release_parser(parser);
for (int i = 0; i < words.size(); ++i) {
cout << words[i] << " " << tags[i] << " " << heads[i] << " " << deprels[i] << endl;
}
} 3. Intelligenter Dialog
Intelligenter Dialog ist eine Technologie, die intelligente Antworten auf von Benutzern gestellte Fragen bietet. Es kann mit Open-Source-Conversational-Bot-Frameworks wie ChatBot erstellt werden. Das Folgende ist ein Beispielcode für die Verwendung von ChatBot für intelligente Dialoge:
#include <ChatBot/ChatBot.h>
void chat(const char* question) {
ChatBot chatbot;
chatbot.loadModel("model.dat"); // 加载预训练模型
std::string answer = chatbot.getResponse(question);
cout << answer << endl;
}Fazit:
In diesem Artikel wird die Verwendung von C++ für leistungsstarke Verarbeitung natürlicher Sprache und intelligenten Dialogen vorgestellt. Durch den Einsatz von Open-Source-Tools und -Frameworks können Sie schnell lexikalische Analysen, syntaktische Analysen und intelligente Dialogfunktionen implementieren. Wir hoffen, dass die Leser durch die Einführung und den Beispielcode dieses Artikels die Methode zur Verwendung von C++ für die Verarbeitung natürlicher Sprache und den intelligenten Dialog verstehen und sie in praktischen Anwendungen anwenden und erweitern können.
Das obige ist der detaillierte Inhalt vonWie nutzt man C++ für eine leistungsstarke Verarbeitung natürlicher Sprache und intelligenten Dialog?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Ein Leitfaden für Anfänger zur Verarbeitung natürlicher Sprache in PHP
Jun 11, 2023 pm 06:30 PM
Ein Leitfaden für Anfänger zur Verarbeitung natürlicher Sprache in PHP
Jun 11, 2023 pm 06:30 PM
Mit der Entwicklung der Technologie der künstlichen Intelligenz ist die Verarbeitung natürlicher Sprache (NLP) zu einer sehr wichtigen Technologie geworden. NLP kann uns helfen, die menschliche Sprache besser zu verstehen und zu analysieren, um einige automatisierte Aufgaben zu erfüllen, wie z. B. intelligenten Kundenservice, Stimmungsanalyse, maschinelle Übersetzung usw. In diesem Artikel behandeln wir die Grundlagen und Tools für die Verarbeitung natürlicher Sprache mit PHP. Was ist die Verarbeitung natürlicher Sprache? Die Verarbeitung natürlicher Sprache ist eine Methode, die künstliche Intelligenz zur Verarbeitung nutzt
 Technologie und Anwendungen zur Erkennung benannter Entitäten und zur Beziehungsextraktion in der Java-basierten Verarbeitung natürlicher Sprache
Jun 18, 2023 am 09:43 AM
Technologie und Anwendungen zur Erkennung benannter Entitäten und zur Beziehungsextraktion in der Java-basierten Verarbeitung natürlicher Sprache
Jun 18, 2023 am 09:43 AM
Mit dem Aufkommen des Internetzeitalters ist eine große Menge an Textinformationen in unser Blickfeld geströmt, gefolgt von einem wachsenden Bedarf der Menschen an Informationsverarbeitung und -analyse. Gleichzeitig hat das Internetzeitalter auch zu einer rasanten Entwicklung der Technologie zur Verarbeitung natürlicher Sprache geführt, die es den Menschen ermöglicht, wertvolle Informationen besser aus Texten zu gewinnen. Unter ihnen sind die Technologie zur Erkennung benannter Entitäten und zur Extraktion von Beziehungen eine der wichtigsten Forschungsrichtungen im Bereich der Anwendungen zur Verarbeitung natürlicher Sprache. 1. Technologie zur Erkennung benannter Entitäten Benannte Entitäten beziehen sich auf Personen, Orte, Organisationen, Zeit, Währung, Enzyklopädiewissen, Messbegriffe und Berufe.
 Verarbeitung natürlicher Sprache: Computer in die Lage versetzen, menschliche Sprache zu verstehen und zu verarbeiten
Sep 21, 2023 pm 03:53 PM
Verarbeitung natürlicher Sprache: Computer in die Lage versetzen, menschliche Sprache zu verstehen und zu verarbeiten
Sep 21, 2023 pm 03:53 PM
Natural Language Processing (NLP) ist eine wichtige und spannende Technologie im Bereich der künstlichen Intelligenz. Ihr Ziel ist es, Computer in die Lage zu versetzen, menschliche Sprache zu verstehen, zu analysieren und zu generieren. Die Entwicklung von NLP hat enorme Fortschritte gemacht und ermöglicht es Computern, besser mit Menschen zu interagieren und ein breiteres Anwendungsspektrum zu erreichen. In diesem Artikel werden die Konzepte, Technologien, Anwendungen und Zukunftsaussichten der Verarbeitung natürlicher Sprache untersucht. Das Konzept der Verarbeitung natürlicher Sprache ist eine Disziplin, die untersucht, wie Computer in die Lage versetzt werden, menschliche Sprache zu verstehen und zu verarbeiten. Die Komplexität und Mehrdeutigkeit der menschlichen Sprache stellt Computer vor große Herausforderungen beim Verstehen und Verarbeiten. Das Ziel von NLP ist die Entwicklung von Algorithmen und Modellen, die es Computern ermöglichen, Informationen aus Texten zu extrahieren
 Wie kann die Verwendung von Java-Funktionen in der Verarbeitung natürlicher Sprache die Konversationsinteraktion erleichtern?
Apr 30, 2024 am 08:03 AM
Wie kann die Verwendung von Java-Funktionen in der Verarbeitung natürlicher Sprache die Konversationsinteraktion erleichtern?
Apr 30, 2024 am 08:03 AM
Java-Funktionen werden im NLP häufig verwendet, um benutzerdefinierte Lösungen zu erstellen, die das Erlebnis von Gesprächsinteraktionen verbessern. Diese Funktionen können zur Textvorverarbeitung, Stimmungsanalyse, Absichtserkennung und Entitätsextraktion verwendet werden. Durch die Verwendung von Java-Funktionen zur Stimmungsanalyse können Anwendungen beispielsweise den Tonfall des Benutzers verstehen und angemessen reagieren, wodurch das Gesprächserlebnis verbessert wird.
![[Python NLTK] Tutorial: Einfacher Einstieg und viel Spaß mit der Verarbeitung natürlicher Sprache](https://img.php.cn/upload/article/000/465/014/170882721469561.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Python NLTK] Tutorial: Einfacher Einstieg und viel Spaß mit der Verarbeitung natürlicher Sprache
Feb 25, 2024 am 10:13 AM
[Python NLTK] Tutorial: Einfacher Einstieg und viel Spaß mit der Verarbeitung natürlicher Sprache
Feb 25, 2024 am 10:13 AM
1. Einführung in NLTK NLTK ist ein Toolkit zur Verarbeitung natürlicher Sprache für die Programmiersprache Python, das 2001 von Steven Bird und Edward Loper erstellt wurde. NLTK bietet eine breite Palette von Textverarbeitungstools, darunter Textvorverarbeitung, Wortsegmentierung, Teil-der-Sprache-Tagging, syntaktische Analyse, semantische Analyse usw., die Entwicklern dabei helfen können, Daten in natürlicher Sprache einfach zu verarbeiten. 2.NLTK-Installation NLTK kann über den folgenden Befehl installiert werden: fromnltk.tokenizeimportWord_tokenizetext="Hello, world!Thisisasampletext."tokens=word_tokenize(te
 So konfigurieren Sie die Verarbeitung natürlicher Sprache mit IntelliJ IDEA auf Linux-Systemen
Jul 05, 2023 pm 10:45 PM
So konfigurieren Sie die Verarbeitung natürlicher Sprache mit IntelliJ IDEA auf Linux-Systemen
Jul 05, 2023 pm 10:45 PM
Konfigurationsmethode für die Verwendung von IntelliJIDEA für die Verarbeitung natürlicher Sprache auf Linux-Systemen. IntelliJIDEA ist eine leistungsstarke integrierte Entwicklungsumgebung (IDE), die für mehrere Programmiersprachen geeignet ist. In diesem Artikel erfahren Sie, wie Sie IntelliJIDEA auf einem Linux-System konfigurieren, um die Entwicklung der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) zu erleichtern. Schritt 1: Laden Sie IntelliJIDEA herunter und installieren Sie es. Zuerst müssen wir zur offiziellen Website https://www gehen.
 Lernen Sie die Verarbeitung natürlicher Sprache und Textanalyse in JavaScript
Nov 03, 2023 pm 04:32 PM
Lernen Sie die Verarbeitung natürlicher Sprache und Textanalyse in JavaScript
Nov 03, 2023 pm 04:32 PM
Das Erlernen der Verarbeitung natürlicher Sprache und der Textanalyse in JavaScript erfordert spezifische Codebeispiele. Natural Language Processing (NLP) ist eine Disziplin, die künstliche Intelligenz und Informatik umfasst. Sie untersucht die Interaktion zwischen Computern und menschlicher natürlicher Sprache. Im Kontext der heutigen rasanten Entwicklung der Informationstechnologie wird NLP häufig in verschiedenen Bereichen eingesetzt, beispielsweise im intelligenten Kundenservice, bei der maschinellen Übersetzung, beim Text Mining usw. JavaScript als Frontend-Entwicklung
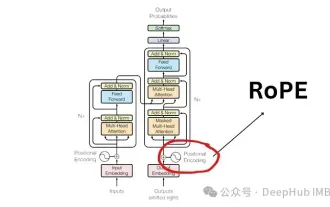 Detaillierte Erläuterung der Rotationspositionskodierung RoPE, die häufig in großen Sprachmodellen verwendet wird: Warum ist sie besser als die absolute oder relative Positionskodierung?
Apr 01, 2024 pm 08:19 PM
Detaillierte Erläuterung der Rotationspositionskodierung RoPE, die häufig in großen Sprachmodellen verwendet wird: Warum ist sie besser als die absolute oder relative Positionskodierung?
Apr 01, 2024 pm 08:19 PM
Die Transformer-Architektur ist seit der Veröffentlichung des Artikels „AttentionIsAllYouNeed“ im Jahr 2017 ein Eckpfeiler im Bereich der Verarbeitung natürlicher Sprache (NLP). Sein Design ist seit Jahren weitgehend unverändert geblieben, wobei das Jahr 2022 mit der Einführung von Rotary Position Encoding (RoPE) eine große Entwicklung auf diesem Gebiet markiert. Das Einbetten gedrehter Positionen ist die hochmoderne NLP-Positionseinbettungstechnik. Die meisten gängigen großen Sprachmodelle (wie Llama, Llama2, PaLM und CodeGen) verwenden es bereits. In diesem Artikel werfen wir einen detaillierten Blick darauf, was Rotationspositionskodierungen sind und wie sie die Vorteile der absoluten und relativen Positionseinbettungen geschickt kombinieren. Die Notwendigkeit einer Positionskodierung, um Ro zu verstehen
