

Boruvka-Algorithmus in C++ für minimalen Spanning Tree


In der Graphentheorie ist das Finden des Minimum Spanning Tree (MST) eines verbundenen gewichteten Graphen ein häufiges Problem. MST ist eine Teilmenge von Diagrammkanten, die alle Eckpunkte verbindet und das Gesamtkantengewicht minimiert. Ein effizienter Algorithmus zur Lösung dieses Problems ist der Boruvka-Algorithmus.
Grammatik
struct Edge {
int src, dest, weight;
};
// Define the structure to represent a subset for union-find
struct Subset {
int parent, rank;
};
Algorithmus
Lassen Sie uns nun die Schritte skizzieren, die zum Finden des minimalen Spannbaums im Boruvka-Algorithmus erforderlich sind −
Initialisieren Sie MST mit dem leeren Satz.
Erstellen Sie für jeden Scheitelpunkt eine Teilmenge, wobei jede Teilmenge nur einen Scheitelpunkt enthält.
Wiederholen Sie die folgenden Schritte, bis der minimale Spannbaum (MST) V-1-Kanten hat (V ist die Anzahl der Eckpunkte im Diagramm) −
Finden Sie für jede Teilmenge die günstigste Kante, die sie mit der anderen Teilmenge verbindet.
Fügen Sie ausgewählte Kanten zu einem minimalen Spannbaum hinzu.
Führen Sie eine Vereinigungsoperation für eine Teilmenge ausgewählter Kanten durch.
Geben Sie den minimalen Spannbaum aus.
Methode
Im Boruvka-Algorithmus gibt es mehrere Möglichkeiten, die günstigste Kante zu finden, die jede Teilmenge verbindet. Hier sind zwei gängige Methoden −
Methode 1: Einfache Methode
Iterieren Sie für jede Teilmenge alle Kanten und finden Sie die kleinste Kante, die sie mit der anderen Teilmenge verbindet.
Verfolgen Sie ausgewählte Kanten und führen Sie Verbindungsoperationen durch.
Beispiel
#include <iostream>
#include <vector>
#include <algorithm>
struct Edge {
int src, dest, weight;
};
// Define the structure to represent a subset for union-find
struct Subset {
int parent, rank;
};
// Function to find the subset of an element using path compression
int find(Subset subsets[], int i) {
if (subsets[i].parent != i)
subsets[i].parent = find(subsets, subsets[i].parent);
return subsets[i].parent;
}
// Function to perform union of two subsets using union by rank
void unionSets(Subset subsets[], int x, int y) {
int xroot = find(subsets, x);
int yroot = find(subsets, y);
if (subsets[xroot].rank < subsets[yroot].rank)
subsets[xroot].parent = yroot;
else if (subsets[xroot].rank > subsets[yroot].rank)
subsets[yroot].parent = xroot;
else {
subsets[yroot].parent = xroot;
subsets[xroot].rank++;
}
}
// Function to find the minimum spanning tree using Boruvka's algorithm
void boruvkaMST(std::vector<Edge>& edges, int V) {
std::vector<Edge> selectedEdges; // Stores the edges of the MST
Subset* subsets = new Subset[V];
int* cheapest = new int[V];
// Initialize subsets and cheapest arrays
for (int v = 0; v < V; v++) {
subsets[v].parent = v;
subsets[v].rank = 0;
cheapest[v] = -1;
}
int numTrees = V;
int MSTWeight = 0;
// Keep combining components until all components are in one tree
while (numTrees > 1) {
for (int i = 0; i < edges.size(); i++) {
int set1 = find(subsets, edges[i].src);
int set2 = find(subsets, edges[i].dest);
if (set1 != set2) {
if (cheapest[set1] == -1 || edges[cheapest[set1]].weight > edges[i].weight)
cheapest[set1] = i;
if (cheapest[set2] == -1 || edges[cheapest[set2]].weight > edges[i].weight)
cheapest[set2] = i;
}
}
for (int v = 0; v < V; v++) {
if (cheapest[v] != -1) {
int set1 = find(subsets, edges[cheapest[v]].src);
int set2 = find(subsets, edges[cheapest[v]].dest);
if (set1 != set2) {
selectedEdges.push_back(edges[cheapest[v]]);
MSTWeight += edges[cheapest[v]].weight;
unionSets(subsets, set1, set2);
numTrees--;
}
cheapest[v] = -1;
}
}
}
// Output the MST weight and edges
std::cout << "Minimum Spanning Tree Weight: " << MSTWeight << std::endl;
std::cout << "Selected Edges:" << std::endl;
for (const auto& edge : selectedEdges) {
std::cout << edge.src << " -- " << edge.dest << " \tWeight: " << edge.weight << std::endl;
}
delete[] subsets;
delete[] cheapest;
}
int main() {
// Pre-defined input for testing purposes
int V = 6;
int E = 9;
std::vector<Edge> edges = {
{0, 1, 4},
{0, 2, 3},
{1, 2, 1},
{1, 3, 2},
{1, 4, 3},
{2, 3, 4},
{3, 4, 2},
{4, 5, 1},
{2, 5, 5}
};
boruvkaMST(edges, V);
return 0;
}
Ausgabe
Minimum Spanning Tree Weight: 9 Selected Edges: 0 -- 2 Weight: 3 1 -- 2 Weight: 1 1 -- 3 Weight: 2 4 -- 5 Weight: 1 3 -- 4 Weight: 2
Erklärung
lautet:Erklärung
Wir definieren zunächst zwei Strukturen – Edge und Subset. Kante stellt eine Kante im Diagramm dar, einschließlich Quelle, Ziel und Gewicht der Kante. Die Teilmenge stellt eine Teilmenge der Union-Abfragedatenstruktur dar, einschließlich übergeordneter und Ranking-Informationen.
Die Suchfunktion ist eine Hilfsfunktion, die Pfadkomprimierung verwendet, um eine Teilmenge von Elementen zu finden. Es findet rekursiv die Vertreter (übergeordnete Knoten) der Teilmenge, zu der das Element gehört, und komprimiert den Pfad, um zukünftige Abfragen zu optimieren.
Die FunktionunionSets ist eine weitere Hilfsfunktion, die zwei Teilmengen durch rangweise Zusammenführung zusammenführt. Es findet Vertreter zweier Teilmengen und führt sie basierend auf ihrem Rang zusammen, um einen ausgewogenen Baum zu erhalten.
DieboruvkaMST-Funktion verwendet als Eingabe einen Kantenvektor und eine Anzahl von Eckpunkten (V). Es implementiert den Boruvka-Algorithmus, um MST zu finden.
Innerhalb der boruvkaMST-Funktion erstellen wir einen Vektor selectedEdges, um die Kanten von MST zu speichern.
Wir erstellen ein Array von Subset-Strukturen zur Darstellung von Subsets und initialisieren sie mit Standardwerten.
Wir erstellen außerdem ein Array günstigstes, um den günstigsten Rand für jede Teilmenge zu verfolgen.
Die Variable numTrees wird auf die Anzahl der Scheitelpunkte initialisiert und MSTWeight wird auf 0 initialisiert.
Der Algorithmus funktioniert durch wiederholtes Kombinieren von Komponenten, bis sich alle Komponenten in einem Baum befinden. Die Hauptschleife läuft, bis numTrees 1 wird.
In jeder Iteration der Hauptschleife iterieren wir über alle Kanten und ermitteln die minimal gewichtete Kante für jede Teilmenge. Wenn eine Kante zwei verschiedene Teilmengen verbindet, aktualisieren wir das günstigste Array mit dem Index der am wenigsten gewichteten Kante.
Als nächstes durchlaufen wir alle Teilmengen. Wenn eine Teilmenge eine Kante mit minimalem Gewicht hat, fügen wir sie dem selectedEdges-Vektor hinzu, aktualisieren MSTWeight, führen die Vereinigungsoperation der Teilmengen durch und reduzieren den Wert von numTrees.
Abschließend geben wir die MST-Gewichte und ausgewählten Kanten aus.
Die Hauptfunktion fordert den Benutzer auf, die Anzahl der Scheitelpunkte und Kanten einzugeben. Dann nimmt es die Eingabe (Quelle, Ziel, Gewicht) für jede Kante und ruft die boruvkaMST-Funktion mit der Eingabe auf.
Methode 2: Prioritätswarteschlange verwenden
Erstellen Sie eine nach Gewicht sortierte Prioritätswarteschlange, um Kanten zu speichern.
Finden Sie für jede Teilmenge die Kante mit minimalem Gewicht, die sie mit einer anderen Teilmenge aus der Prioritätswarteschlange verbindet.
Verfolgen Sie ausgewählte Kanten und führen Sie Verbindungsoperationen durch.
Beispiel
#include <iostream>
#include <vector>
#include <queue>
#include <climits>
using namespace std;
// Edge structure representing a weighted edge in the graph
struct Edge {
int destination;
int weight;
Edge(int dest, int w) : destination(dest), weight(w) {}
};
// Function to find the shortest path using Dijkstra's algorithm
vector<int> dijkstra(const vector<vector<Edge>>& graph, int source) {
int numVertices = graph.size();
vector<int> dist(numVertices, INT_MAX);
vector<bool> visited(numVertices, false);
dist[source] = 0;
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;
pq.push(make_pair(0, source));
while (!pq.empty()) {
int u = pq.top().second;
pq.pop();
if (visited[u]) {
continue;
}
visited[u] = true;
for (const Edge& edge : graph[u]) {
int v = edge.destination;
int weight = edge.weight;
if (dist[u] + weight < dist[v]) {
dist[v] = dist[u] + weight;
pq.push(make_pair(dist[v], v));
}
}
}
return dist;
}
int main() {
int numVertices = 4;
vector<vector<Edge>> graph(numVertices);
// Adding edges to the graph
graph[0].push_back(Edge(1, 2));
graph[0].push_back(Edge(2, 5));
graph[1].push_back(Edge(2, 1));
graph[1].push_back(Edge(3, 7));
graph[2].push_back(Edge(3, 3));
int source = 0;
vector<int> shortestDistances = dijkstra(graph, source);
cout << "Shortest distances from source vertex " << source << ":\n";
for (int i = 0; i < numVertices; i++) {
cout << "Vertex " << i << ": " << shortestDistances[i] << endl;
}
return 0;
}
Ausgabe
Shortest distances from source vertex 0: Vertex 0: 0 Vertex 1: 2 Vertex 2: 3 Vertex 3: 6
Erklärung
lautet:Erklärung
Bei diesem Ansatz verwenden wir eine Prioritätswarteschlange, um den Prozess zum Finden der minimal gewichteten Kante für jede Teilmenge zu optimieren. Nachfolgend finden Sie eine detaillierte Erklärung des Codes −
Die Codestruktur und Hilfsfunktionen (wie find und unionSets) bleiben dieselben wie bei der vorherigen Methode.
DieboruvkaMST-Funktion wurde geändert, um eine Prioritätswarteschlange zu verwenden, um die minimal gewichtete Kante für jede Teilmenge effizient zu finden.
Anstatt das günstigste Array zu verwenden, erstellen wir jetzt eine Edge Priority Queue (pq). Wir initialisieren es mit den Kanten des Diagramms.
Die Hauptschleife läuft, bis numTrees 1 wird, ähnlich wie bei der vorherigen Methode.
In jeder Iteration extrahieren wir die Kante mit minimalem Gewicht (minEdge) aus der Prioritätswarteschlange.
Dann verwenden wir die Suchfunktion, um die Teilmenge zu finden, zu der die Quelle und das Ziel von minEdge gehören.
Wenn die Teilmengen unterschiedlich sind, fügen wir minEdge zum selectedEdges-Vektor hinzu, aktualisieren MSTWeight, führen eine Zusammenführung der Teilmengen durch und reduzieren numTrees.
Der Vorgang wird fortgesetzt, bis sich alle Komponenten in einem Baum befinden.
Abschließend geben wir die MST-Gewichte und ausgewählten Kanten aus.
Die Hauptfunktionalität ist die gleiche wie bei der vorherigen Methode, wir haben zu Testzwecken vordefinierte Eingaben.
Fazit
Der Boruvka-Algorithmus bietet eine effiziente Lösung zum Finden des minimalen Spannbaums eines gewichteten Diagramms. Unser Team hat bei der Implementierung des Algorithmus in C++ zwei verschiedene Wege eingehend untersucht: einen traditionellen oder „naiven“ Ansatz. Ein anderer nutzt Prioritätswarteschlangen. Hängt von den spezifischen Anforderungen des jeweiligen Problems ab. Jede Methode hat bestimmte Vorteile und kann entsprechend umgesetzt werden. Durch das Verständnis und die Implementierung des Boruvka-Algorithmus können Sie Minimal-Spanning-Tree-Probleme in C++-Projekten effizient lösen.
Das obige ist der detaillierte Inhalt vonBoruvka-Algorithmus in C++ für minimalen Spanning Tree. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

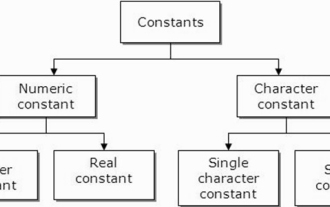 Was sind Konstanten in der C-Sprache? Können Sie ein Beispiel nennen?
Aug 28, 2023 pm 10:45 PM
Was sind Konstanten in der C-Sprache? Können Sie ein Beispiel nennen?
Aug 28, 2023 pm 10:45 PM
Eine Konstante wird auch als Variable bezeichnet. Sobald sie definiert ist, ändert sich ihr Wert während der Ausführung des Programms nicht. Daher können wir eine Variable als Konstante deklarieren, die auf einen festen Wert verweist. Es wird auch Text genannt. Konstanten müssen mit dem Schlüsselwort Const definiert werden. Syntax Die Syntax der in der Programmiersprache C verwendeten Konstanten ist wie folgt: consttypeVariableName; (oder) Verschiedene Arten von Konstanten Die verschiedenen Arten von Konstanten, die in der Programmiersprache C verwendet werden, sind wie folgt: Ganzzahlige Konstanten – Beispiel: 1,0 ,34, 4567 Gleitkommakonstanten – Beispiel: 0,0, 156,89, 23,456 Oktal- und Hexadezimalkonstanten – Beispiel: Hex: 0x2a, 0xaa.. Oktal
 VSCode und VS C++ IntelliSense funktionieren nicht oder rufen keine Bibliotheken auf
Feb 29, 2024 pm 01:28 PM
VSCode und VS C++ IntelliSense funktionieren nicht oder rufen keine Bibliotheken auf
Feb 29, 2024 pm 01:28 PM
VS Code und Visual Studio C++ IntelliSense können Bibliotheken möglicherweise nicht abrufen, insbesondere bei der Arbeit an großen Projekten. Wenn wir mit der Maus über #Include<wx/wx.h> fahren, wird die Fehlermeldung „Quelldatei 'string.h' kann nicht geöffnet werden“ angezeigt (abhängig von „wx/wx.h“) und manchmal reagiert die Funktion zur automatischen Vervollständigung nicht. In diesem Artikel erfahren Sie, was Sie tun können, wenn VSCode und VSC++ IntelliSense nicht funktionieren oder Bibliotheken nicht extrahieren. Warum funktioniert mein Intellisense nicht in C++? Bei der Arbeit mit großen Dateien kommt es manchmal zu IntelliSense
 Wie man den Algorithmus von Prim in C++ verwendet
Sep 20, 2023 pm 12:31 PM
Wie man den Algorithmus von Prim in C++ verwendet
Sep 20, 2023 pm 12:31 PM
Titel: Verwendung des Prim-Algorithmus und Codebeispiele in C++ Einführung: Der Prim-Algorithmus ist ein häufig verwendeter Minimum-Spanning-Tree-Algorithmus, der hauptsächlich zur Lösung des Minimum-Spanning-Tree-Problems in der Graphentheorie verwendet wird. In C++ kann der Algorithmus von Prim durch sinnvolle Datenstrukturen und Algorithmusimplementierung effektiv genutzt werden. In diesem Artikel wird die Verwendung des Prim-Algorithmus in C++ vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Einführung in den Prim-Algorithmus Der Prim-Algorithmus ist ein gieriger Algorithmus. Er beginnt mit einem Scheitelpunkt und erweitert schrittweise den Scheitelpunktsatz des minimalen Spannbaums, bis er ihn enthält
 Beheben Sie den Xbox-Fehlercode 8C230002
Feb 27, 2024 pm 03:55 PM
Beheben Sie den Xbox-Fehlercode 8C230002
Feb 27, 2024 pm 03:55 PM
Können Sie aufgrund des Fehlercodes 8C230002 keine Inhalte auf Ihrer Xbox kaufen oder ansehen? Einige Benutzer erhalten diese Fehlermeldung immer wieder, wenn sie versuchen, Inhalte auf ihrer Konsole zu kaufen oder anzusehen. Leider liegt ein Problem mit dem Xbox-Dienst vor. Versuchen Sie es später erneut. Wenn Sie Hilfe zu diesem Problem benötigen, besuchen Sie www.xbox.com/errorhelp. Statuscode: 8C230002 Dieser Fehlercode wird normalerweise durch vorübergehende Server- oder Netzwerkprobleme verursacht. Es kann jedoch auch andere Gründe geben, beispielsweise die Datenschutzeinstellungen oder die Kindersicherung Ihres Kontos, die Sie möglicherweise daran hindern, bestimmte Inhalte zu kaufen oder anzusehen. Beheben Sie den Xbox-Fehlercode 8C230002, wenn Sie beim Versuch, Inhalte auf Ihrer Xbox-Konsole anzusehen oder zu kaufen, den Fehlercode 8C erhalten
 Rekursives Programm zum Ermitteln minimaler und maximaler Elemente eines Arrays in C++
Aug 31, 2023 pm 07:37 PM
Rekursives Programm zum Ermitteln minimaler und maximaler Elemente eines Arrays in C++
Aug 31, 2023 pm 07:37 PM
Als Eingabe nehmen wir das Integer-Array Arr[]. Ziel ist es, mithilfe einer rekursiven Methode die größten und kleinsten Elemente in einem Array zu finden. Da wir Rekursion verwenden, durchlaufen wir das gesamte Array, bis wir Länge = 1 erreichen, und geben dann A[0] zurück, was den Basisfall bildet. Andernfalls wird das aktuelle Element mit dem aktuellen Minimal- oder Maximalwert verglichen und sein Wert für nachfolgende Elemente rekursiv aktualisiert. Schauen wir uns verschiedene Eingabe- und Ausgabeszenarien dafür an −Input −Arr={12,67,99,76,32};Output −Maximum value in the array: 99 Explanation &mi
 China Eastern Airlines gibt bekannt, dass das Passagierflugzeug C919 bald in Betrieb genommen wird
May 28, 2023 pm 11:43 PM
China Eastern Airlines gibt bekannt, dass das Passagierflugzeug C919 bald in Betrieb genommen wird
May 28, 2023 pm 11:43 PM
Laut Nachrichten vom 25. Mai gab China Eastern Airlines bei der Leistungsbesprechung die neuesten Fortschritte beim Passagierflugzeug C919 bekannt. Nach Angaben des Unternehmens ist der mit COMAC unterzeichnete C919-Kaufvertrag im März 2021 offiziell in Kraft getreten und das erste C919-Flugzeug wurde bis Ende 2022 ausgeliefert. Es wird erwartet, dass das Flugzeug bald offiziell in Betrieb genommen wird. China Eastern Airlines wird Shanghai als Hauptbasis für den kommerziellen Betrieb der C919 nutzen und plant die Einführung von insgesamt fünf C919-Passagierflugzeugen in den Jahren 2022 und 2023. Das Unternehmen gab an, dass zukünftige Einführungspläne auf der Grundlage der tatsächlichen Betriebsbedingungen und der Streckennetzplanung festgelegt werden. Nach Auffassung des Herausgebers handelt es sich bei der C919 um Chinas neue Generation globaler Single-Aisle-Hauptlinienpassagierflugzeuge mit völlig unabhängigen geistigen Eigentumsrechten und entspricht international anerkannten Lufttüchtigkeitsstandards. Sollen
 C++-Programm zum Drucken spiralförmiger Zahlenmuster
Sep 05, 2023 pm 06:25 PM
C++-Programm zum Drucken spiralförmiger Zahlenmuster
Sep 05, 2023 pm 06:25 PM
Die Anzeige von Zahlen in verschiedenen Formaten ist eines der grundlegenden Codierungsprobleme beim Lernen. Verschiedene Codierungskonzepte wie bedingte Anweisungen und Schleifenanweisungen. Es gibt verschiedene Programme, in denen wir Sonderzeichen wie Sternchen verwenden, um Dreiecke oder Quadrate zu drucken. In diesem Artikel drucken wir Zahlen in Spiralform, genau wie Quadrate in C++. Wir nehmen die Anzahl der Zeilen n als Eingabe, beginnen in der oberen linken Ecke und bewegen uns nach rechts, dann nach unten, dann nach links, dann nach oben, dann wieder nach rechts und so weiter und so fort. Spiralmuster mit Zahlen 123456724252627282982340414243309223948494431102138474645321120373635343312191817161514
 Die Funktion des Schlüsselworts void in der C-Sprache
Feb 19, 2024 pm 11:33 PM
Die Funktion des Schlüsselworts void in der C-Sprache
Feb 19, 2024 pm 11:33 PM
void ist in C ein spezielles Schlüsselwort, das zur Darstellung eines leeren Typs verwendet wird, also Daten ohne einen bestimmten Typ. In der C-Sprache wird void normalerweise in den folgenden drei Aspekten verwendet. Der Rückgabetyp der Funktion ist void. In der Sprache C können Funktionen unterschiedliche Rückgabetypen haben, z. B. int, float, char usw. Wenn die Funktion jedoch keinen Wert zurückgibt, kann der Rückgabetyp auf void gesetzt werden. Dies bedeutet, dass die Funktion nach Ausführung keinen bestimmten Wert zurückgibt. Zum Beispiel: voidhelloWorld()
