
 Technologie-Peripheriegeräte
KI
Ein ausführlicher fünfminütiger technischer Vortrag über die generativen Modelle von GET3D
Technologie-Peripheriegeräte
KI
Ein ausführlicher fünfminütiger technischer Vortrag über die generativen Modelle von GET3D
Ein ausführlicher fünfminütiger technischer Vortrag über die generativen Modelle von GET3D

Teil 01●
Vorwort
In den letzten Jahren ist die 2D-Bilderzeugungstechnologie mit künstlicher Intelligenz zu einem Hilfswerkzeug geworden, das von vielen Designern in tatsächlichen Projekten verwendet wird wird in verschiedenen Geschäftsszenarien angewendet und schafft immer mehr praktischen Wert. Gleichzeitig bewegen sich mit dem Aufstieg des Metaversums viele Branchen in Richtung der Schaffung groß angelegter virtueller 3D-Welten, und vielfältige, qualitativ hochwertige 3D-Inhalte werden für Branchen wie Spiele, Robotik, Architektur usw. immer wichtiger. und soziale Plattformen. Die manuelle Erstellung von 3D-Assets ist jedoch zeitaufwändig und erfordert besondere künstlerische und modellierende Fähigkeiten. Eine der größten Herausforderungen ist die Frage der Skalierung – trotz der großen Anzahl an 3D-Modellen, die auf dem 3D-Markt zu finden sind, erfordert die Bestückung einer Gruppe von Charakteren oder Gebäuden, die in einem Spiel oder Film alle unterschiedlich aussehen, immer noch einen erheblichen künstlerischen Aufwand Zeit. Infolgedessen wird der Bedarf an Tools zur Inhaltserstellung, die sich hinsichtlich Quantität, Qualität und Vielfalt von 3D-Inhalten skalieren lassen, immer deutlicher
 Bilder
Bilder
Siehe Abbildung 1, dies ist ein Foto des Metaverse-Raums ( Quelle: Film „Wreck-It Ralph 2“)
Dank der Tatsache, dass generative 2D-Modelle bei der hochauflösenden Bildsynthese eine realistische Qualität erreicht haben, hat dieser Fortschritt auch die Forschung zur 3D-Inhaltsgenerierung inspiriert. Frühe Methoden zielten darauf ab, 2D-CNN-Generatoren direkt auf 3D-Voxelgitter zu erweitern, aber der hohe Speicherbedarf und die Rechenkomplexität von 3D-Faltungen behinderten den Generierungsprozess bei hohen Auflösungen. Als Alternative haben andere Forschungsarbeiten Punktwolken-, implizite oder Octree-Darstellungen untersucht. Diese Arbeiten konzentrieren sich jedoch hauptsächlich auf die Erzeugung von Geometrie und ignorieren das Erscheinungsbild. Ihre Ausgabedarstellungen müssen auch nachbearbeitet werden, um sie mit Standard-Grafik-Engines kompatibel zu machen.
Um für die Inhaltsproduktion praktisch zu sein, sollten ideale generative 3D-Modelle die folgenden Anforderungen erfüllen:
Die Fähigkeit haben, 3D-Grafiken mit Geometrie zu generieren Details und beliebige Topologie Fähigkeit von Formen
Inhalt umschreiben: (b) Die Ausgabe sollte ein texturiertes Netz sein, was ein allgemeiner Ausdruck ist, der von Standard-Grafiksoftware wie Blender und Maya verwendet wird
Kann mit 2D-Bildern in ihrer jetzigen Form überwacht werden viel kleiner als explizite 3D-Formen Allgemeiner
Teil 02
Einführung in generative 3D-Modelle
Um den Prozess der Inhaltserstellung zu erleichtern und praktische Anwendungen zu ermöglichen, sind generative 3D-Netzwerke zu einem aktiven Forschungsgebiet geworden, das in der Lage ist, qualitativ hochwertige und vielfältige 3D-Modelle zu erzeugen Vermögenswerte. Jedes Jahr werden viele generative 3D-Modelle auf ICCV, NeurlPS, ICML und anderen Konferenzen veröffentlicht, darunter die folgenden hochmodernen Modelle:
Textured3DGAN ist ein generatives Modell, das eine Erweiterung der Faltungsmethode zur Generierung texturierter 3D-Netze darstellt. Es kann lernen, mithilfe von GANs unter 2D-Überwachung Texturnetze aus physischen Bildern zu generieren. Im Vergleich zu früheren Methoden lockert Textured3DGAN die Anforderungen an Schlüsselpunkte im Schritt der Posenschätzung und verallgemeinert die Methode auf unbeschriftete Bildsammlungen und neue Kategorien/Datensätze wie ImageNet.
DIB-R: ist ein differenzierbarer Renderer, der auf Interpolation basiert und PyTorch verwendet Framework für maschinelles Lernen unten. Dieser Renderer wurde dem 3D Deep Learning PyTorch GitHub-Repository (Kaolin) hinzugefügt. Diese Methode ermöglicht die analytische Berechnung von Farbverläufen für alle Pixel im Bild. Die Kernidee besteht darin, die Vordergrundrasterung als gewichtete Interpolation lokaler Attribute und die Hintergrundrasterung als distanzbasierte Aggregation globaler Geometrie zu behandeln. Auf diese Weise können Informationen wie Form, Textur und Licht aus einem einzelnen Bild vorhergesagt werden.
PolyGen: PolyGen ist ein autoregressives generatives Modell basierend auf der Transformer-Architektur zur direkten Modellierung von Netzen. Das Modell sagt der Reihe nach die Scheitelpunkte und Flächen des Netzes voraus. Wir haben das Modell mit dem ShapeNet Core V2-Datensatz trainiert und die Ergebnisse kommen den von Menschen erstellten Netzmodellen bereits sehr nahe
SurfGen: Konfrontative 3D-Formsynthese mit einem expliziten Oberflächendiskriminator. Das durchgängig trainierte Modell ist in der Lage, hochauflösende 3D-Formen mit unterschiedlichen Topologien zu generieren.
GET3D ist ein generatives Modell, das durch Lernen von Bildern hochwertige 3D-Texturformen erzeugen kann. Sein Kern ist differenzierbare Oberflächenmodellierung, differenzierbares Rendering und generative gegnerische 2D-Netzwerke. Durch Training an einer Sammlung von 2D-Bildern kann GET3D direkt explizit texturierte 3D-Netze mit komplexer Topologie, reichhaltigen geometrischen Details und hochauflösenden Texturen generieren (Quelle: Offizielle GET3D-Papier-Website https://nv-tlabs.github.io/GET3D/)
GET3D ist ein kürzlich vorgeschlagenes generatives 3D-Modell, das mehrere Modelle mit komplexen Geometrien wie ShapeNet, Turbosquid und Renderpeople verwendet Stühle, Motorräder, Autos, Menschen und Gebäude, die modernste Leistung bei der unbegrenzten Generierung von 3D-Formen demonstrieren 
Teil 03
Die Architektur und Eigenschaften von GET3D
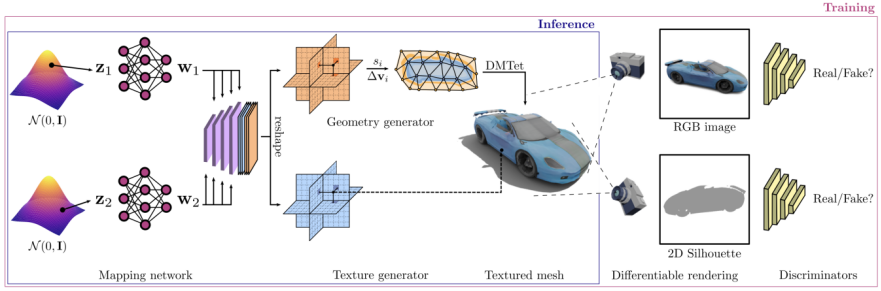 Bilder
Bilder
Die GET3D-Architektur stammt von der offiziellen GET3D-Papierwebsite.
Ein 3D-SDF (gerichtetes Distanzfeld) wird durch zwei mögliche Codierungen generiert und ein Texturfeld, verwenden Sie dann DMTet (Deep Marching Tetrahedra), um das 3D-Oberflächennetz aus SDF zu extrahieren, und fragen Sie das Texturfeld in der Oberflächenpunktwolke ab, um die Farbe zu erhalten. Der gesamte Prozess wird mithilfe eines auf 2D-Bildern definierten gegnerischen Verlusts trainiert. Insbesondere RGB-Bilder und -Konturen werden mithilfe eines auf Rasterung basierenden differenzierbaren Renderers erhalten. Schließlich werden zwei 2D-Diskriminatoren verwendet, jeweils für RGB-Bilder und Konturen, um zu unterscheiden, ob die Eingabe echt oder gefälscht ist. Das gesamte Modell kann End-to-End trainiert werden.
GET3D ist auch in anderen Aspekten sehr flexibel und kann neben der Darstellung expliziter Netze als Ausgabe auch problemlos an andere Aufgaben angepasst werden, darunter:
Getrennte Geometrie- und Texturimplementierung: Gute Entkopplung zwischen Geometrie und Textur wird erreicht, was eine sinnvolle Interpolation von latenten Geometriecodes und latenten Texturcodes ermöglicht
Durch die Durchführung eines zufälligen Spaziergangs im latenten Raum, bei der Erzeugung glatter Übergänge zwischen verschiedenen Formklassen und der Generierung entsprechender 3D-Formen, um dies zu erreichen
Neue Formen generieren: Dies kann durch das Hinzufügen von kleinem Rauschen zum lokalen latenten Code gestört werden, wodurch Formen erzeugt werden, die ähnlich aussehen, sich aber lokal leicht unterscheiden.
Unüberwachte Materialgenerierung: In Kombination mit DIBR++ können Materialien völlig unbeaufsichtigt generiert und produziert werden aussagekräftige, ansichtsabhängige Lichteffekte
Textgesteuerte Formgenerierung: Durch die Kombination von StyleGAN NADA, die Nutzung rechnerisch gerenderter 2D-Bilder und vom Benutzer bereitgestellter Texte. Mithilfe des gerichteten CLIP-Verlusts zur Feinabstimmung des 3D-Generators können Benutzer eine große Anzahl sinnvoller generieren Formen durch Textaufforderungen
 Bilder
Bilder
Bitte beachten Sie Abbildung 4, die den Prozess der Generierung von Formen basierend auf Text zeigt. Die Quelle dieser Abbildung ist die offizielle Website des GET3D-Papiers, die URL lautet https://nv-tlabs.github.io/GET3D/
Teil 04
Zusammenfassung
Obwohl GET3D einen Schritt in Richtung eines praktischen 3D gemacht hat Modell zur Texturformerzeugung Ein wichtiger Schritt, der jedoch noch einige Einschränkungen aufweist. Insbesondere basiert der Trainingsprozess immer noch auf der Kenntnis von 2D-Silhouetten und Kameraverteilungen. Daher kann GET3D derzeit nur auf Basis synthetischer Daten ausgewertet werden. Eine vielversprechende Erweiterung besteht darin, Fortschritte bei der Instanzsegmentierung und der Kamerapositionsschätzung zu nutzen, um dieses Problem zu lindern und GET3D auf reale Daten auszuweiten. GET3D wird derzeit nur nach Kategorien trainiert und wird in Zukunft auf mehrere Kategorien erweitert, um die Vielfalt zwischen den Kategorien besser darzustellen. Hoffentlich bringt diese Forschung die Menschen der Nutzung künstlicher Intelligenz für die kostenlose Erstellung von 3D-Inhalten einen Schritt näher
Das obige ist der detaillierte Inhalt vonEin ausführlicher fünfminütiger technischer Vortrag über die generativen Modelle von GET3D. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Sie müssen bedenken, insbesondere wenn Sie Teams-Benutzer sind, dass Microsoft seiner arbeitsorientierten Videokonferenz-App eine neue Reihe von 3DFluent-Emojis hinzugefügt hat. Nachdem Microsoft letztes Jahr 3D-Emojis für Teams und Windows angekündigt hatte, wurden im Rahmen des Prozesses tatsächlich mehr als 1.800 bestehende Emojis für die Plattform aktualisiert. Diese große Idee und die Einführung des 3DFluent-Emoji-Updates für Teams wurden erstmals über einen offiziellen Blogbeitrag beworben. Das neueste Teams-Update bringt FluentEmojis in die App. Laut Microsoft werden uns die aktualisierten 1.800 Emojis täglich zur Verfügung stehen
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Als sich das Gerücht verbreitete, dass das neue Windows 11 in der Entwicklung sei, war jeder Microsoft-Nutzer neugierig, wie das neue Betriebssystem aussehen und was es bringen würde. Nach Spekulationen ist Windows 11 da. Das Betriebssystem kommt mit neuem Design und funktionalen Änderungen. Zusätzlich zu einigen Ergänzungen werden Funktionen eingestellt und entfernt. Eine der Funktionen, die es in Windows 11 nicht gibt, ist Paint3D. Während es immer noch klassisches Paint bietet, das sich gut für Zeichner, Kritzler und Kritzler eignet, verzichtet es auf Paint3D, das zusätzliche Funktionen bietet, die sich ideal für 3D-Ersteller eignen. Wenn Sie nach zusätzlichen Funktionen suchen, empfehlen wir Autodesk Maya als beste 3D-Designsoftware. wie
 Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
ChatGPT hat der KI-Branche eine Portion Hühnerblut injiziert, und alles, was einst undenkbar war, ist heute zur gängigen Praxis geworden. Text-to-3D, das immer weiter voranschreitet, gilt nach Diffusion (Bilder) und GPT (Text) als nächster Hotspot im AIGC-Bereich und hat beispiellose Aufmerksamkeit erhalten. Nein, ein Produkt namens ChatAvatar befindet sich in einer unauffälligen öffentlichen Betaphase, hat schnell über 700.000 Aufrufe und Aufmerksamkeit erregt und wurde auf Spacesoftheweek vorgestellt. △ChatAvatar wird auch die Imageto3D-Technologie unterstützen, die 3D-stilisierte Charaktere aus KI-generierten Einzel-/Mehrperspektive-Originalgemälden generiert. Das von der aktuellen Beta-Version generierte 3D-Modell hat große Beachtung gefunden.
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
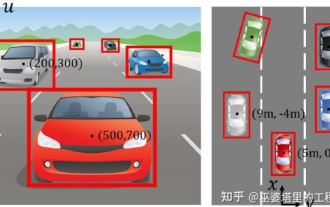 Eine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren
Jun 02, 2023 pm 03:42 PM
Eine ausführliche Interpretation des visuellen 3D-Wahrnehmungsalgorithmus für autonomes Fahren
Jun 02, 2023 pm 03:42 PM
Für autonome Fahranwendungen ist es letztlich notwendig, 3D-Szenen wahrzunehmen. Der Grund ist einfach. Ein Fahrzeug kann nicht auf der Grundlage der aus einem Bild gewonnenen Wahrnehmungsergebnisse fahren. Selbst ein menschlicher Fahrer kann nicht auf der Grundlage eines Bildes fahren. Da die Entfernung des Objekts und die Tiefeninformationen der Szene nicht in den 2D-Wahrnehmungsergebnissen widergespiegelt werden können, sind diese Informationen der Schlüssel für das autonome Fahrsystem, um korrekte Urteile über die Umgebung zu fällen. Im Allgemeinen werden die Sichtsensoren (z. B. Kameras) autonomer Fahrzeuge über der Karosserie oder am Rückspiegel im Fahrzeuginneren installiert. Egal wo sie ist, was die Kamera erhält, ist die Projektion der realen Welt in der perspektivischen Ansicht (PerspectiveView) (Weltkoordinatensystem zu Bildkoordinatensystem). Diese Sicht ist dem menschlichen visuellen System sehr ähnlich.
