

Verwenden des Requests-Moduls in Python

Requests ist ein Python-Modul, mit dem verschiedene HTTP-Anfragen gesendet werden können. Es handelt sich um eine benutzerfreundliche Bibliothek mit vielen Funktionen, von der Übergabe von Parametern in URLs über das Senden benutzerdefinierter Header bis hin zur SSL-Überprüfung. In diesem Tutorial erfahren Sie, wie Sie diese Bibliothek verwenden, um einfache HTTP-Anfragen in Python zu senden.
Sie können Anfragen in den Python-Versionen 2.6–2.7 und 3.3–3.6 verwenden. Bevor Sie fortfahren, sollten Sie wissen, dass es sich bei Requests um ein externes Modul handelt. Sie müssen es also installieren, bevor Sie die Beispiele in diesem Tutorial ausprobieren. Sie können es installieren, indem Sie den folgenden Befehl im Terminal ausführen:
pip install requests
Nach der Installation des Moduls können Sie überprüfen, ob die Installation erfolgreich war, indem Sie das Modul mit dem folgenden Befehl importieren:
import requests
Wenn die Installation erfolgreich ist, wird keine Fehlermeldung angezeigt.
Stellen Sie eine GET-Anfrage
Das Senden von HTTP-Anfragen ist mit Requests sehr einfach. Sie importieren zuerst das Modul und stellen dann die Anfrage. Hier ein Beispiel:
import requests
req = requests.get('https://tutsplus.com/')
Alle Informationen zu unserer Anfrage werden jetzt in einem Attribut namens req 的响应对象中。例如,您可以使用 req.encoding 属性获取网页的编码。您还可以使用 req.status_code gespeichert, das den Statuscode der Anfrage erhält.
req.encoding # returns 'utf-8' req.status_code # returns 200
Sie können den req.cookies 访问服务器发回的 cookie。同样,您可以使用 req.headers 获取响应标头。 req.headers 属性返回响应标头的不区分大小写的字典。这意味着 req.headers['Content-Length']、req.headers['content-length'] 和 req。 headers['CONTENT-LENGTH'] 都会返回 'Content-Length'-Wert des Antwortheaders verwenden.
Sie können überprüfen, ob es sich bei der Antwort um eine wohlgeformte HTTP-Umleitung handelt, indem Sie das Attribut req.is_redirect 属性自动处理。它将根据响应返回 True 或 False 。您还可以使用 req.elapsed verwenden, um die Zeit abzurufen, die zwischen dem Senden der Anfrage und dem Erhalt der Antwort verstrichen ist.
Sie übergeben das Attribut get() 函数的 URL 可能与响应的最终 URL 不同。要查看最终的响应 URL,您可以使用 req.url zunächst aus verschiedenen Gründen (einschließlich Weiterleitungen).
import requests
req = requests.get('https://www.tutsplus.com/')
req.encoding # returns 'utf-8'
req.status_code # returns 200
req.elapsed # returns datetime.timedelta(0, 1, 666890)
req.url # returns 'https://tutsplus.com/'
req.history
# returns [<Response [301]>, <Response [301]>]
req.headers['Content-Type']
# returns 'text/html; charset=utf-8'
Es ist großartig, all diese Informationen über die Webseite zu haben, die Sie besuchen, aber höchstwahrscheinlich möchten Sie auf den eigentlichen Inhalt zugreifen. Wenn es sich bei dem Inhalt, auf den Sie zugreifen, um Text handelt, können Sie das Attribut req.text 属性来访问它。然后内容被解析为 unicode。您可以使用 req.encoding verwenden, um die Kodierung zu übergeben, die zum Dekodieren des Texts verwendet wird.
Für Nicht-Text-Antworten können Sie req.content 以二进制形式访问它们。该模块将自动解码 gzip 和 deflate 传输编码。当您处理媒体文件时,这会很有帮助。同样,您可以使用 req.json() verwenden, um auf den JSON-codierten Inhalt der Antwort zuzugreifen (falls vorhanden).
Sie können auch req.raw 从服务器获取原始响应。请记住,您必须在请求中传递 stream=True verwenden, um die ursprüngliche Antwort zu erhalten.
Einige Dateien, die Sie mit dem Anforderungsmodul aus dem Internet herunterladen, können groß sein. In diesem Fall ist es unklug, die gesamte Antwort oder Datei sofort in den Speicher zu laden. Mit der iter_content(chunk_size = 1,decode_unicode=False)-Methode können Sie Dateien in Blöcken oder Blöcken herunterladen.
Eine Iteration dieser Methode chunk_size 字节数中的响应数据。当请求上设置了 stream=True 时,此方法将避免一次将整个文件读入内存以获得大量响应。 chunk_size 参数可以是整数,也可以是 None。当设置为整数值时,chunk_size bestimmt die Anzahl der Bytes, die in den Speicher eingelesen werden sollen.
Wenn chunk_size 设置为 None 且 stream 设置为 True 时,数据将被读取为无论收到的块大小如何,它都会到达。当 chunk_size 设置为 None 且 stream 设置为 False , werden alle Daten als ein einzelner Block zurückgegeben.
Lassen Sie uns das Anfragemodul verwenden, um einige Bilder von Pilzen herunterzuladen. Hier ist das aktuelle Bild:

Dies ist der Code, den Sie benötigen:
import requests
req = requests.get('path/to/mushrooms.jpg', stream=True)
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
'path/to/mushrooms.jpg' 是实际的图像 URL。您可以将任何其他图像的 URL 放在这里来下载其他内容。给定的图像文件大小为 162kb,并且您已将 chunk_size 设置为 50,000 字节。这意味着“Received a Chunk”消息应在终端中打印四次。最后一个块的大小将仅为 32350 字节,因为前三次迭代后仍待接收的文件部分为 32350 字节。
您还可以用类似的方式下载视频。我们可以简单地将其值设置为 None,而不是指定固定的 chunk_size,然后视频将以提供的任何块大小下载。以下代码片段将从 Mixkit 下载高速公路的视频:
import requests
req = requests.get('path/to/highway/video.mp4', stream=True)
req.raise_for_status()
with open('highway.mp4', 'wb') as fd:
for chunk in req.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
尝试运行代码,您将看到视频作为单个块下载。
如果您决定使用 stream 参数,则应记住以下几点。响应正文的下载会被推迟,直到您使用 content 属性实际访问其值。这样,如果某些标头值之一看起来不正确,您就可以避免下载文件。
另请记住,在将流的值设置为 True 时启动的任何连接都不会关闭,除非您消耗所有数据或使用 close() 方法。确保连接始终关闭的更好方法是在 with 语句中发出请求,即使您部分读取了响应,如下所示:
import requests
with requests.get('path/to/highway/video.mp4', stream=True) as rq:
with open('highway.mp4', 'wb') as fd:
for chunk in rq.iter_content(chunk_size=None):
print('Received a Chunk')
fd.write(chunk)
由于我们之前下载的图片文件比较小,您也可以使用以下代码一次性下载:
import requests
req = requests.get('path/to/mushrooms.jpg')
req.raise_for_status()
with open('mushrooms.jpg', 'wb') as fd:
fd.write(req.content)
我们跳过了设置 stream 参数的值,因此默认设置为 False。这意味着所有响应内容将立即下载。借助 content 属性,将响应内容捕获为二进制数据。
请求还允许您在 URL 中传递参数。当您在网页上搜索某些结果(例如特定图像或教程)时,这会很有帮助。您可以使用 GET 请求中的 params 关键字将这些查询字符串作为字符串字典提供。这是一个例子:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular&min_height=600&q=Forest&min_width=800'
发出 POST 请求
发出 POST 请求与发出 GET 请求一样简单。您只需使用 post() 方法而不是 get() 即可。当您自动提交表单时,这会很有用。例如,以下代码将向 httpbin.org 域发送 post 请求,并将响应 JSON 作为文本输出。
import requests
req = requests.post('https://httpbin.org/post', data = {'username': 'monty', 'password': 'something_complicated'})
req.raise_for_status()
print(req.text)
'''
{
"args": {},
"data": "",
"files": {},
"form": {
"password": "something_complicated",
"username": "monty"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "45",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.28.1",
"X-Amzn-Trace-Id": "Root=1-63ad437e-67f5db6a161314861484f2eb"
},
"json": null,
"origin": "YOUR.IP.ADDRESS",
"url": "https://httpbin.org/post"
}
'''
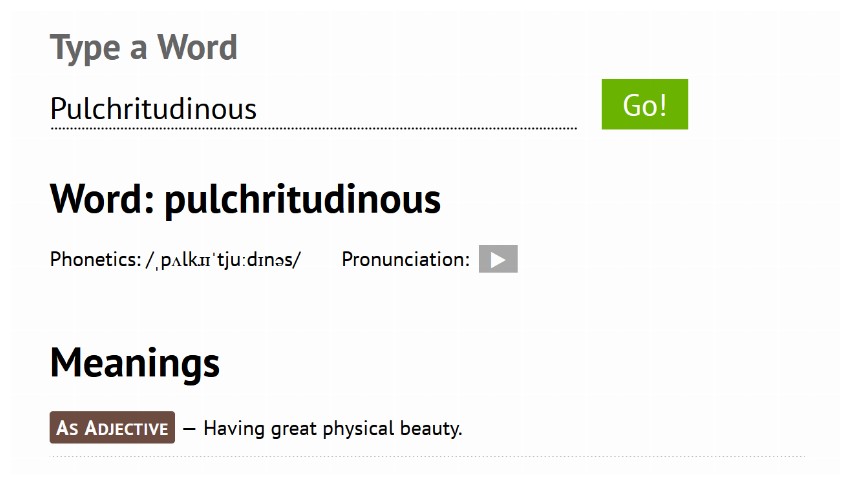
您可以将这些 POST 请求发送到任何可以处理它们的 URL。举个例子,我的一位朋友创建了一个网页,用户可以在其中输入单词并使用 API 获取其含义以及发音和其他信息。我们可以用我们查询的单词向URL发出POST请求,然后将结果保存为HTML页面,如下所示:
import requests
word = 'Pulchritudinous'
filename = word.lower() + '.html'
req = requests.post('https://tutorialio.com/tools/dictionary.php', data = {'query': word})
req.raise_for_status()
with open(filename, 'wb') as fd:
fd.write(req.content)
执行上面的代码,它会返回一个包含该单词信息的页面,如下图所示。
发送 Cookie 和标头
如前所述,您可以使用 req.cookies 和 req.headers 访问服务器发回给您的 cookie 和标头。请求还允许您通过请求发送您自己的自定义 cookie 和标头。当您想要为您的请求设置自定义用户代理时,这会很有帮助。
要将 HTTP 标头添加到请求中,您只需将它们通过 dict 传递到 headers 参数即可。同样,您还可以使用传递给 cookies 参数的 dict 将自己的 cookie 发送到服务器。
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie 也可以在 Cookie Jar 中传递。它们提供了更完整的界面,允许您通过多个路径使用这些 cookie。这是一个例子:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
会话对象
有时,在多个请求中保留某些参数很有用。 Session 对象正是这样做的。例如,它将在使用同一会话发出的所有请求中保留 cookie 数据。 Session 对象使用 urllib3 的连接池。这意味着底层 TCP 连接将被重复用于向同一主机发出的所有请求。这可以显着提高性能。您还可以将 Requests 对象的方法与 Session 对象一起使用。
以下是使用和不使用会话发送的多个请求的示例:
import requests
reqOne = requests.get('https://tutsplus.com/')
reqOne.cookies['_tuts_session']
#returns 'cc118d94a84f0ea37c64f14dd868a175'
reqTwo = requests.get('https://code.tutsplus.com/tutorials')
reqTwo.cookies['_tuts_session']
#returns '3775e1f1d7f3448e25881dfc35b8a69a'
ssnOne = requests.Session()
ssnOne.get('https://tutsplus.com/')
ssnOne.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
reqThree = ssnOne.get('https://code.tutsplus.com/tutorials')
reqThree.cookies['_tuts_session']
#returns '4c3dd2f41d2362108fbb191448eab3b4'
正如您所看到的,会话cookie在第一个和第二个请求中具有不同的值,但当我们使用Session对象时它具有相同的值。当您尝试此代码时,您将获得不同的值,但在您的情况下,使用会话对象发出的请求的 cookie 将具有相同的值。
当您想要在所有请求中发送相同的数据时,会话也很有用。例如,如果您决定将 cookie 或用户代理标头与所有请求一起发送到给定域,则可以使用 Session 对象。这是一个例子:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
如您所见,"visit-month" 会话 cookie 随所有三个请求一起发送。但是, "visit-year" cookie 仅在第二次请求期间发送。第三个请求中也没有提及 "vist-year" cookie。这证实了单个请求上设置的 cookie 或其他数据不会与其他会话请求一起发送。
结论
本教程中讨论的概念应该可以帮助您通过传递特定标头、cookie 或查询字符串来向服务器发出基本请求。当您尝试抓取网页以获取信息时,这将非常方便。现在,一旦您找出 URL 中的模式,您还应该能够自动从不同的网站下载音乐文件和壁纸。
学习 Python
无论您是刚刚入门还是希望学习新技能的经验丰富的程序员,都可以通过我们完整的 Python 教程指南学习 Python。
Das obige ist der detaillierte Inhalt vonVerwenden des Requests-Moduls in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python haben jeweils ihre eigenen Vorteile und wählen nach den Projektanforderungen. 1.PHP ist für die Webentwicklung geeignet, insbesondere für die schnelle Entwicklung und Wartung von Websites. 2. Python eignet sich für Datenwissenschaft, maschinelles Lernen und künstliche Intelligenz mit prägnanter Syntax und für Anfänger.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer Studienzeit
Apr 14, 2025 am 12:02 AM
Um die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Nginx SSL -Zertifikat -Aktualisierung Debian Tutorial
Apr 13, 2025 am 07:21 AM
Nginx SSL -Zertifikat -Aktualisierung Debian Tutorial
Apr 13, 2025 am 07:21 AM
In diesem Artikel werden Sie begleitet, wie Sie Ihr NginXSSL -Zertifikat auf Ihrem Debian -System aktualisieren. Schritt 1: Installieren Sie zuerst CertBot und stellen Sie sicher, dass Ihr System Certbot- und Python3-CertBot-Nginx-Pakete installiert hat. If not installed, please execute the following command: sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx Step 2: Obtain and configure the certificate Use the certbot command to obtain the Let'sEncrypt certificate and configure Nginx: sudocertbot--nginx Follow the prompts to select
 Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Gitlabs Plug-in-Entwicklungshandbuch zu Debian
Apr 13, 2025 am 08:24 AM
Die Entwicklung eines Gitlab -Plugins für Debian erfordert einige spezifische Schritte und Kenntnisse. Hier ist ein grundlegender Leitfaden, mit dem Sie mit diesem Prozess beginnen können. Wenn Sie zuerst GitLab installieren, müssen Sie GitLab in Ihrem Debian -System installieren. Sie können sich auf das offizielle Installationshandbuch von GitLab beziehen. Holen Sie sich API Access Token, bevor Sie die API -Integration durchführen. Öffnen Sie das GitLab -Dashboard, finden Sie die Option "AccessTokens" in den Benutzereinstellungen und generieren Sie ein neues Zugriffs -Token. Wird generiert
 So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
So konfigurieren Sie den HTTPS -Server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Das Konfigurieren eines HTTPS -Servers auf einem Debian -System umfasst mehrere Schritte, einschließlich der Installation der erforderlichen Software, der Generierung eines SSL -Zertifikats und der Konfiguration eines Webservers (z. B. Apache oder NGINX) für die Verwendung eines SSL -Zertifikats. Hier ist eine grundlegende Anleitung unter der Annahme, dass Sie einen Apacheweb -Server verwenden. 1. Installieren Sie zuerst die erforderliche Software, stellen Sie sicher, dass Ihr System auf dem neuesten Stand ist, und installieren Sie Apache und OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
 Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Welcher Dienst ist Apache
Apr 13, 2025 pm 12:06 PM
Apache ist der Held hinter dem Internet. Es ist nicht nur ein Webserver, sondern auch eine leistungsstarke Plattform, die enormen Datenverkehr unterstützt und dynamische Inhalte bietet. Es bietet eine extrem hohe Flexibilität durch ein modulares Design und ermöglicht die Ausdehnung verschiedener Funktionen nach Bedarf. Modularität stellt jedoch auch Konfigurations- und Leistungsherausforderungen vor, die ein sorgfältiges Management erfordern. Apache eignet sich für Serverszenarien, die hoch anpassbare und entsprechende komplexe Anforderungen erfordern.
