
 Technologie-Peripheriegeräte
KI
ACM MM 2023 |. DiffBFR: Von Meitu und der Chinesischen Universität für Wissenschaft und Technologie gemeinsam vorgeschlagene Methode zur Wiederherstellung von Flächen zur Geräuschunterdrückung
Technologie-Peripheriegeräte
KI
ACM MM 2023 |. DiffBFR: Von Meitu und der Chinesischen Universität für Wissenschaft und Technologie gemeinsam vorgeschlagene Methode zur Wiederherstellung von Flächen zur Geräuschunterdrückung
ACM MM 2023 |. DiffBFR: Von Meitu und der Chinesischen Universität für Wissenschaft und Technologie gemeinsam vorgeschlagene Methode zur Wiederherstellung von Flächen zur Geräuschunterdrückung

Das Ziel der Blind Face Restoration (BFR) ist die Wiederherstellung qualitativ hochwertiger Gesichtsbilder aus minderwertigen Gesichtsbildern. Dies ist eine wichtige Aufgabe im Bereich Computer Vision und Grafik und wird häufig in verschiedenen Szenarien wie der Wiederherstellung von Überwachungsbildern, der Wiederherstellung alter Fotos und der Superauflösung von Gesichtsbildern eingesetzt. Diese Aufgabe ist jedoch sehr anspruchsvoll, da sie nicht deterministisch ist Eine Verschlechterung beeinträchtigt die Bildqualität und führt sogar zum Verlust von Bildinformationen wie Unschärfe, Rauschen, Downsampling und Komprimierungsartefakten. Frühere BFR-Methoden stützen sich in der Regel auf generative kontradiktorische Netzwerke (GAN), um diese Probleme durch den Entwurf verschiedener gesichtsspezifischer Priors zu lösen, darunter generative Priors, Referenz-Priors und geometrische Priors. Obwohl diese Methoden den neuesten Stand der Technik erreicht haben, können sie das Ziel, realistische Texturen zu erhalten und gleichzeitig Details wiederherzustellen, immer noch nicht vollständig erreichen.
Beim Bildwiederherstellungsprozess sind die Datensätze von Gesichtsbildern normalerweise im hochdimensionalen Raum verstreut und verteilt Die Merkmalsdimensionen weisen eine Long-Tail-Verteilung auf. Anders als bei der Long-Tail-Verteilung bei Bildklassifizierungsaufgaben beziehen sich die Long-Tail-Regionalmerkmale bei der Bildwiederherstellung auf Attribute, die einen geringen Einfluss auf die Identität, aber einen großen Einfluss auf visuelle Effekte haben, wie z. B. Muttermale, Falten und Töne usw.
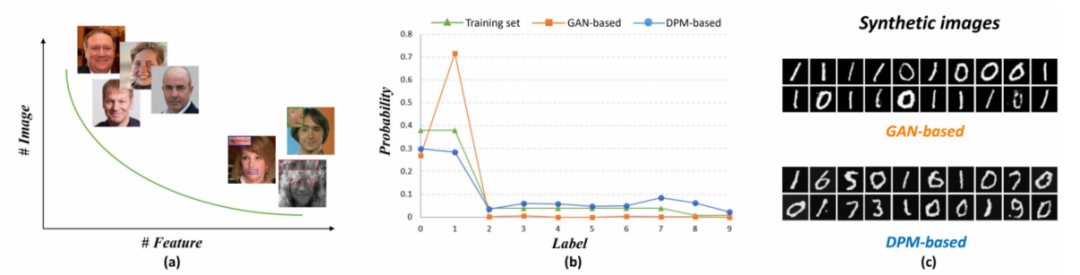
Gemäß Abbildung 1 Die gezeigte Einfachheit besteht darin, dass die experimentellen Ergebnisse ins Chinesische umgeschrieben werden müssen, um die ursprüngliche Bedeutung nicht zu ändern. Wir können feststellen, dass die bisherigen GAN-basierten Methoden offensichtliche Probleme bei der Verarbeitung von Kopf- und Schwanzproben haben Gleichzeitig kommt es beim Reparieren des Bildes zu Überschwingern und zu Detailverlusten. Die auf Diffusion Probistic Models (DPM) basierende Methode kann die Long-Tail-Verteilung besser anpassen und die Tail-Eigenschaften beibehalten, während sie gleichzeitig an die reale Datenverteilung angepasst wird
Das Meitu Imaging Research Institute (MT Lab) hat mit Forschern der Universität der Chinesischen Akademie der Wissenschaften zusammengearbeitet, um eine neue Methode zur Reparatur blinder Gesichtsbilder, DiffBFR, vorzuschlagen. Diese Methode basiert auf der DPM-Technologie und erreicht erfolgreich die Wiederherstellung blinder Gesichtsbilder, die Reparatur von Gesichtsbildern geringer Qualität (LQ) in klare Bilder hoher Qualität (HQ)
 Der Inhalt, der neu geschrieben werden muss, ist: Papierlink: https://arxiv.org/ abs/2305.04517
Der Inhalt, der neu geschrieben werden muss, ist: Papierlink: https://arxiv.org/ abs/2305.04517
Diese Forschung untersucht die Anpassungsfähigkeit zweier generativer Modelle, Generative Adversarial Networks (GAN) und Deep Partial Models (DPM), im Umgang mit Long-Tail-Problemen. Durch die Gestaltung eines geeigneten Moduls zur Gesichtsrestaurierung können genauere Detailinformationen erhalten werden, wodurch die übermäßige Glättung des Gesichts, die bei generativen Methoden auftreten kann, reduziert und die Präzision und Genauigkeit der Wiederherstellung verbessert werden. Dieses Forschungspapier wurde vom ACM MM 2023 angenommen. Schwanzverteilungen. Daher entscheidet sich DiffBFR für die Verwendung des Diffusionswahrscheinlichkeitsmodells, um die Einbettung von Gesichts-Vorinformationen zu verbessern, und verwendet dieses als Grundgerüst für die Auswahl von DPM als Lösung. Dies liegt daran, dass das Diffusionsmodell über die leistungsstarke Fähigkeit verfügt, qualitativ hochwertige Bilder innerhalb eines beliebigen Verteilungsbereichs zu erzeugen
Um die in der Arbeit gefundene Long-Tail-Verteilung von Merkmalen im Gesichtsdatensatz und das Problem der übermäßigen Glättung in der Vergangenheit zu lösen Diese Studie basiert auf GAN-basierten Methoden und untersuchte ein vernünftiges Design, um die ungefähre Long-Tail-Verteilung besser anzupassen und das Problem der übermäßigen Glättung im Reparaturprozess zu überwinden. Durch einfache Experimente mit GAN und DPM mit derselben Parametergröße im MNIST-Datensatz (Abbildung 1) ergab die Studie, dass die DPM-Methode die Long-Tail-Verteilung angemessen anpassen kann, während GAN den Kopfmerkmalen zu viel Aufmerksamkeit schenkt und diese ignoriert Die Schwanzmerkmale können daher nicht generiert werden. Daher wird DPM als Lösung für BFR ausgewählt. Durch die Einführung zweier Zwischenvariablen schlägt DiffBFR zwei spezifische Reparaturmodule vor. Das Design verfolgt einen zweistufigen Ansatz, bei dem zunächst Identitätsinformationen aus LQ-Bildern wiederhergestellt werden und anschließend Texturdetails basierend auf der Verteilung realer Gesichter verbessert werden. Dieses Design besteht aus zwei Hauptteilen:
(1) Identitätswiederherstellungsmodul (IRM):
Der Zweck dieses Moduls besteht darin, die Gesichtsdetails in den Ergebnissen beizubehalten. Gleichzeitig wird eine verkürzte Abtastmethode vorgeschlagen, die die Entrauschungsmethode unter Verwendung einer reinen Gaußschen Zufallsverteilung im umgekehrten Prozess ersetzt, indem ein Teil des Rauschens dem Bild mit geringer Qualität hinzugefügt wird. Der Artikel beweist theoretisch, dass diese Änderung die theoretische Evidenzuntergrenze (ELBO) von DPM schrumpft und dadurch ursprünglichere Details wiederherstellt. Basierend auf dem theoretischen Beweis werden zwei kaskadierte bedingte Diffusionsmodelle mit unterschiedlichen Eingabegrößen eingeführt, um den Sampling-Effekt zu verbessern und die Trainingsschwierigkeiten bei der direkten Erzeugung hochauflösender Bilder zu verringern. Gleichzeitig wird weiterhin bewiesen, dass je höher die Qualität der bedingten Eingabe ist, desto näher kommt sie der tatsächlichen Datenverteilung und desto genauer ist das wiederhergestellte Bild. Dies ist auch der Grund, warum DiffBFR zuerst Bilder mit niedriger Auflösung wiederherstellt
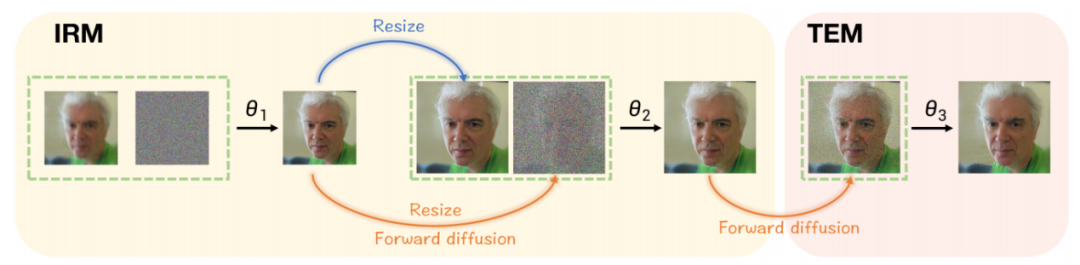
(2) Texture Enhancement Module (TEM):Die zum Texturieren von Polierbildern verwendete Methode besteht darin, ein bedingungsloses Diffusionsmodell einzuführen. Dieses Modell ist völlig unabhängig von Bildern mit geringer Qualität, wodurch die wiederhergestellten Ergebnisse den realen Bilddaten noch näher kommen. Der Artikel beweist theoretisch, dass ein bedingungsloses Diffusionsmodell, das auf rein qualitativ hochwertigen Bildern trainiert wird, zur korrekten Verteilung des Ausgabebildes im Raum auf Pixelebene beiträgt. Das heißt, nach der Verwendung dieses Modells weist die Verteilung von eingefärbten Bildern einen niedrigeren FID auf als vor der Verwendung und ähnelt insgesamt eher der Verteilung von Bildern mit hoher Qualität. Insbesondere werden die Identitätsinformationen durch Abschneiden der Abtastung im Zeitschritt beibehalten und die Textur auf Pixelebene poliert. Die Abtastinferenzschritte von DiffBFR sind in Abbildung 2 dargestellt, und das schematische Diagramm des Abtastinferenzprozesses ist in Abbildung dargestellt 3.
Der Inhalt, der neu geschrieben werden muss, ist: Abbildung 2 zeigt den Sampling-Inferenzschritt der DiffBFR-Methode
Der Inhalt, der neu geschrieben werden muss, ist: Abbildung 3 zeigt das schematische Diagramm des Sampling-Inferenzprozesses der DiffBFR-Methode
 Um die ursprüngliche Bedeutung nicht zu ändern, müssen die experimentellen Ergebnisse ins Chinesische umgeschrieben werden
Um die ursprüngliche Bedeutung nicht zu ändern, müssen die experimentellen Ergebnisse ins Chinesische umgeschrieben werden
Die Visualisierungseffekte der GAN-basierten BFR-Methode und der DPM-basierten Methode werden verglichen , wie in Abbildung 4 dargestellt

Für Abbildung 5 wird die Leistung der SOTA-Methode für BFR verglichen
Im Modell können wir die Leistung von IRM und TEM durch Visualisierung vergleichen 
Im Modell wird die Leistung von IRM und TEM verglichen, wie in Abbildung 8 dargestellt
Der Inhalt, der neu geschrieben werden muss, lautet: Vergleichen Sie die IRM-Leistung von Abbildung 9 unter verschiedenen Parametern. 
Für Abbildung 10 müssen wir die Leistung verschiedener Parameter vergleichen Umzuschreiben ist: Abbildung 11 zeigt die Parametereinstellungen jedes Moduls von DiffBFR 
Die Zusammenfassung besteht darin, die Informationen oder den Prozess der Neuformulierung von Ideen auf prägnante und klare Weise zu kombinieren. Es verändert nicht die ursprüngliche Bedeutung, sondern stellt die gleiche Idee dar, indem es ein anderes Vokabular und eine andere Satzstruktur verwendet. Der Zweck einer Zusammenfassung besteht darin, eine klarere und prägnantere Darstellung bereitzustellen, damit der Leser die übermittelten Informationen leichter verstehen und verarbeiten kann. Zusammenfassungen sind in einer Vielzahl von Situationen nützlich, sei es in wissenschaftlichen Arbeiten, Geschäftsberichten oder alltäglichen Mitteilungen, wo sie zur Vermittlung wichtiger Ideen und Schlussfolgerungen verwendet werden können. Kurz gesagt, die Zusammenfassung ist ein wichtiges Kommunikationsinstrument, das uns helfen kann, Informationen effektiver zu vermitteln und zu verstehen. In diesem Artikel wird ein DiffBFR-Modell zur Wiederherstellung von Gesichtsbildern mit blinder Verschlechterung vorgeschlagen, um die Probleme früherer GAN-basierter Methoden zu lösen Modusabsturz und Probleme mit dem Verschwinden des langen Schwanzes. Durch die Einbettung von Vorwissen in das Diffusionsmodell können hochwertige und klare wiederhergestellte Bilder aus zufälligen, stark beeinträchtigten Gesichtsbildern generiert werden. Konkret schlägt diese Studie zwei Module vor, IRM und TEM, die zur Wiederherstellung der Realität bzw. zur Wiederherstellung von Details verwendet werden. Durch theoretische Ableitung und experimentelle Bilddemonstration wird die Überlegenheit des Modells demonstriert und qualitative und quantitative Vergleiche mit bestehenden Methoden auf dem neuesten Stand der Technik durchgeführt
Was neu geschrieben werden muss, ist: Forschungsteam
Dieses Papier wurde gemeinsam von Forschern des Meitu Imaging Research Institute (MT Lab) und der University of Chinese Academy of Sciences vorgeschlagen. Das Meitu Imaging Research Institute (MT Lab) wurde 2010 gegründet. Es handelt sich um ein Team von Meitu, das sich auf Algorithmenforschung, technische Entwicklung und Produktimplementierung in den Bereichen Computer Vision, Deep Learning, Augmented Reality und anderen Bereichen konzentriert. Seit seiner Gründung widmet sich das Team der Forschung im Bereich Computer Vision und begann 2013 mit dem Einsatz von Deep Learning, um technischen Support für die Software- und Hardwareprodukte von Meitu bereitzustellen. Gleichzeitig bieten sie auch gezielte SaaS-Dienste für mehrere vertikale Bereiche der Bildgebungsbranche an und fördern die ökologische Entwicklung der Produkte der künstlichen Intelligenz von Meitu durch modernste Bildgebungstechnologie. Sie haben an internationalen Top-Wettbewerben wie CVPR, ICCV und ECCV teilgenommen, mehr als zehn Meisterschaften und Zweitplatzierungen gewonnen und mehr als 48 erstklassige internationale wissenschaftliche Konferenzbeiträge veröffentlicht. Das Meitu Imaging Research Institute (MT Lab) engagiert sich seit langem für Forschung und Entwicklung im Bereich der Bildgebung, verfügt über umfangreiche technische Reserven und verfügt über umfangreiche Erfahrung bei der Technologieimplementierung in den Bereichen Bilder, Videos, Design und digitale Menschen
Das obige ist der detaillierte Inhalt vonACM MM 2023 |. DiffBFR: Von Meitu und der Chinesischen Universität für Wissenschaft und Technologie gemeinsam vorgeschlagene Methode zur Wiederherstellung von Flächen zur Geräuschunterdrückung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Das intelligente Fahrsystem Qiankun ADS3.0 von Huawei wird im August auf den Markt kommen und erstmals auf dem Xiangjie S9 eingeführt
Jul 30, 2024 pm 02:17 PM
Das intelligente Fahrsystem Qiankun ADS3.0 von Huawei wird im August auf den Markt kommen und erstmals auf dem Xiangjie S9 eingeführt
Jul 30, 2024 pm 02:17 PM
Am 29. Juli nahm Yu Chengdong, Huawei-Geschäftsführer, Vorsitzender von Terminal BG und Vorsitzender von Smart Car Solutions BU, an der Übergabezeremonie des 400.000sten Neuwagens von AITO Wenjie teil, hielt eine Rede und kündigte an, dass die Modelle der Wenjie-Serie dies tun werden Dieses Jahr auf den Markt kommen Im August wurde die Huawei Qiankun ADS 3.0-Version auf den Markt gebracht und es ist geplant, die Upgrades sukzessive von August bis September voranzutreiben. Das Xiangjie S9, das am 6. August auf den Markt kommt, wird erstmals mit dem intelligenten Fahrsystem ADS3.0 von Huawei ausgestattet sein. Mit Hilfe von Lidar wird Huawei Qiankun ADS3.0 seine intelligenten Fahrfähigkeiten erheblich verbessern, über integrierte End-to-End-Funktionen verfügen und eine neue End-to-End-Architektur von GOD (allgemeine Hinderniserkennung)/PDP (prädiktiv) einführen Entscheidungsfindung und Kontrolle), Bereitstellung der NCA-Funktion für intelligentes Fahren von Parkplatz zu Parkplatz und Aktualisierung von CAS3.0
 Ein weiteres Snapdragon 8Gen3-Tablet ~ OPPOPad3 enthüllt
Jul 29, 2024 pm 04:26 PM
Ein weiteres Snapdragon 8Gen3-Tablet ~ OPPOPad3 enthüllt
Jul 29, 2024 pm 04:26 PM
Letzten Monat hat OnePlus sein erstes Tablet mit Snapdragon 8 Gen3 herausgebracht: OnePlus Tablet Pro. Den neuesten Nachrichten zufolge wird auch die „Baby-Ersatz“-Version dieses Tablets, OPPOPad3, erscheinen. Das Bild oben zeigt OPPOPad2. Das Aussehen und die Konfiguration des OPPOPad3 entsprechen genau denen des OnePlus Tablet Pro. Farbe: Gold, Blau (anders als die grüne und dunkelgraue Speicherversion von OnePlus). /12/16GB+512GB Erscheinungsdatum: Neue Produkte für den gleichen Zeitraum im vierten Quartal dieses Jahres (Oktober-Dezember): Finden
 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Herausgeber | ScienceAI Basierend auf begrenzten klinischen Daten wurden Hunderte medizinischer Algorithmen genehmigt. Wissenschaftler diskutieren darüber, wer die Werkzeuge testen soll und wie dies am besten geschieht. Devin Singh wurde Zeuge, wie ein pädiatrischer Patient in der Notaufnahme einen Herzstillstand erlitt, während er lange auf eine Behandlung wartete, was ihn dazu veranlasste, den Einsatz von KI zu erforschen, um Wartezeiten zu verkürzen. Mithilfe von Triage-Daten aus den Notaufnahmen von SickKids erstellten Singh und Kollegen eine Reihe von KI-Modellen, um mögliche Diagnosen zu stellen und Tests zu empfehlen. Eine Studie zeigte, dass diese Modelle die Zahl der Arztbesuche um 22,3 % verkürzen können und die Verarbeitung der Ergebnisse pro Patient, der einen medizinischen Test benötigt, um fast drei Stunden beschleunigt. Der Erfolg von Algorithmen der künstlichen Intelligenz in der Forschung bestätigt dies jedoch nur
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Das Nubia Z60S Pro startet bei 2.999 Yuan und senkt damit die Preisschwelle für die Satellitenkommunikation von Mobiltelefonen
Jul 25, 2024 pm 01:00 PM
Das Nubia Z60S Pro startet bei 2.999 Yuan und senkt damit die Preisschwelle für die Satellitenkommunikation von Mobiltelefonen
Jul 25, 2024 pm 01:00 PM
Am 23. Juli brachte Nubia offiziell sein erstes Satellitentelefon auf den Markt – das Nubia Z60SPro. Mit einem Preis von 2.999 Yuan ist es das günstigste Satellitenkommunikationstelefon auf dem Markt. Ni Fei, Präsident der Terminal-Geschäftseinheit von ZTE und Präsident von Nubia Technology Co., Ltd., sagte in den sozialen Medien auch, dass die Satellitenkommunikationstechnologie aufgrund der hohen Preisschwelle nicht populär geworden sei. Er glaubt, dass diese Technologie für Menschen in Notfällen eine Option werden sollte, um die persönliche Sicherheit zu gewährleisten. 1. Das Nubia Z60SPro wurde auf den Markt gebracht und führte die Satellitenkommunikationstechnologie in 2.000-Yuan-Mobiltelefone ein, sodass mehr Verbraucher von dieser fortschrittlichen Technologie profitieren können. Nubias Ziel ist es, die Satellitenkommunikation von einem „Luxusprodukt“ in Mobiltelefonen in ein Reisebegleitungsartefakt für normale Menschen zu verwandeln, das immer häufiger eingesetzt wird
