

Alibaba hat ein neues großes Modell als Open Source bereitgestellt, was sehr aufregend ist ~
Nach Tongyi Qianwen-7B(Qwen-7B) hat Alibaba Cloud das groß angelegte visuelle Sprachmodell Qwen-VL auf den Markt gebracht, und das wird auch so sein direkt Open Source, sobald es online geht.

Qwen-VL ist ein großes multimodales Modell, das auf Tongyi Qianwen-7B basiert. Insbesondere unterstützt es mehrere Eingaben wie Bilder, Text und Erkennungsrahmen und kann nicht nur Text, sondern auch Erkennungsrahmen ausgeben Ausgabe
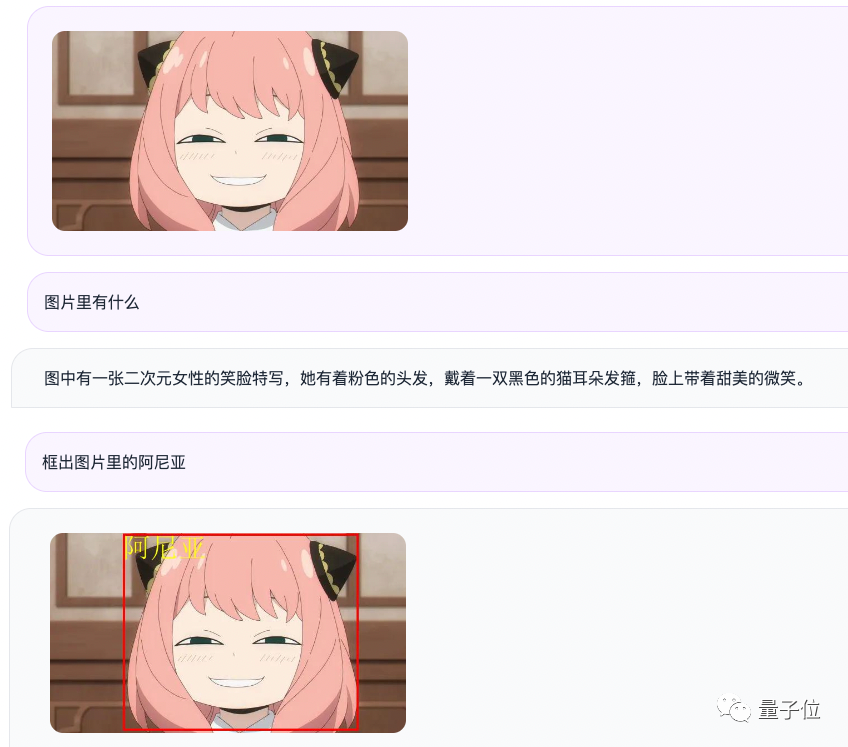
Zum Beispiel geben wir ein Bild von Aniya ein. Durch die Form von Frage und Antwort kann Qwen-VL-Chat den Inhalt des Bildes zusammenfassen und Aniya im Bild genau lokalisieren. Qwen-VL demonstrierte die Stärke des „Hexagonal Warrior“ und belegte den ersten Platz in der standardmäßigen englischen Bewertung der vier Hauptkategorien multimodaler Aufgaben (Zero-shot Caption/VQA/DocVQA/Grounding).
Sobald die Open-Source-Nachrichten herauskamen, erregten sie sofort große Aufmerksamkeit
 Werfen wir einen Blick auf die konkrete Leistung!
Werfen wir einen Blick auf die konkrete Leistung!
Das erste allgemeine Modell, das die chinesische Open-Domain-Positionierung unterstützt
(groß angelegtes visuelles Sprachmodell)
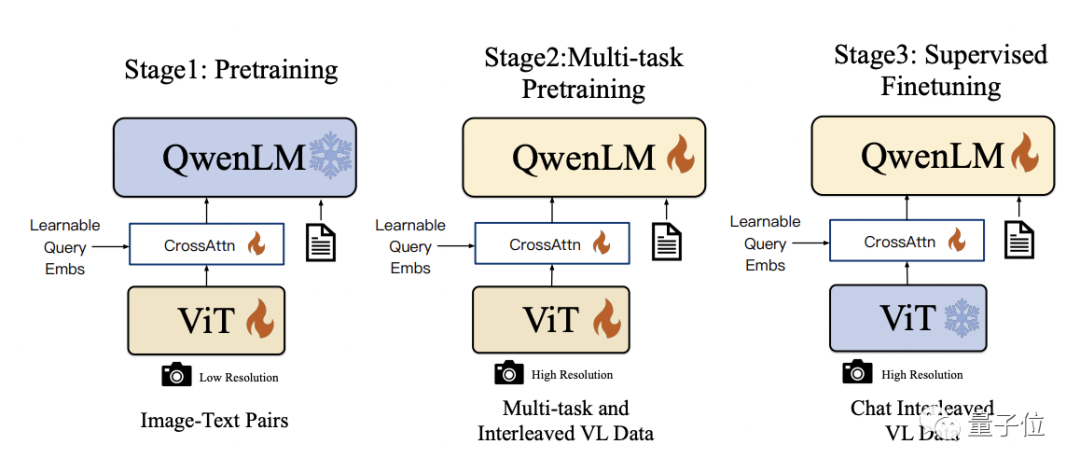
Der spezifische Trainingsprozess ist in drei Schritte unterteilt:
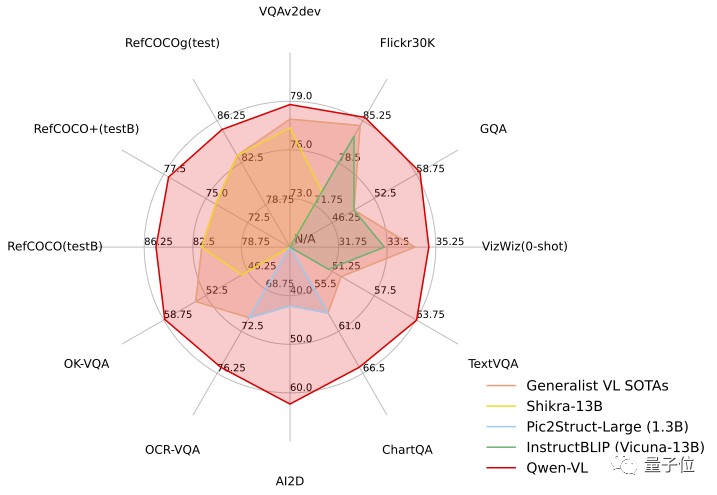
In der standardmäßigen englischen Bewertung von Qwen-VL testeten die Forscher vier Hauptkategorien multimodaler Aufgaben (Zero-shot Caption/VQA/DocVQA/Grounding)
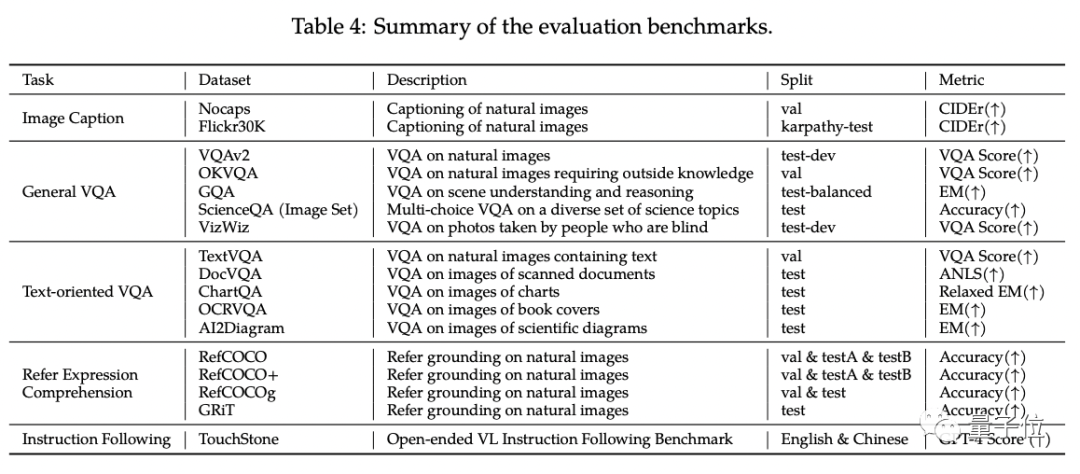
Den Ergebnissen zufolge war Qwen-VL das Beste Ergebnisse wurden beim Vergleich mit Open-Source-LVLM derselben Größe erzielt. Darüber hinaus erstellten die Forscher einen Testsatz
TouchStonebasierend auf dem GPT-4-Bewertungsmechanismus.

 Qwen-VL-Chat hat in diesem Vergleichstest den neuesten Stand der Technik (SOTA) erreicht
Qwen-VL-Chat hat in diesem Vergleichstest den neuesten Stand der Technik (SOTA) erreicht
Wer sich für Qwen-VL interessiert, findet die Demo auf der Magic Community und Huggingface Kommen Sie vorbei und probieren Sie es direkt aus. Der Link befindet sich am Ende des Artikels
Qwen-VL unterstützt Forscher und Entwickler bei der Sekundärentwicklung und ermöglicht die kommerzielle Nutzung. Es ist jedoch zu beachten, dass Sie, wenn Sie es kommerziell nutzen möchten, zuerst den Fragebogenantrag ausfüllen müssen
Projektlink: https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope .cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen -VL-Chat
https://github.com/QwenLM/Qwen-VL
Das obige ist der detaillierte Inhalt vonDas Ali-Riesenmodell ist wieder Open Source! Es verfügt über vollständige Bildverständnis- und Objekterkennungsfunktionen. Es basiert auf dem allgemeinen Problemsatz 7B und ist für kommerzielle Anwendungen geeignet.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Office-Software gibt es?
Welche Office-Software gibt es?
 Einführung in die Bedeutung von Cloud-Download-Fenstern
Einführung in die Bedeutung von Cloud-Download-Fenstern
 Was tun, wenn die temporäre Dateiumbenennung fehlschlägt?
Was tun, wenn die temporäre Dateiumbenennung fehlschlägt?
 Was tun, wenn Avast falsch positive Ergebnisse meldet?
Was tun, wenn Avast falsch positive Ergebnisse meldet?
 Der Unterschied zwischen get und post
Der Unterschied zwischen get und post
 Telekommunikations-CDMA
Telekommunikations-CDMA
 Was soll ich tun, wenn das CAD-Bild nicht verschoben werden kann?
Was soll ich tun, wenn das CAD-Bild nicht verschoben werden kann?
 Fakepath-Pfadlösung
Fakepath-Pfadlösung
 Überprüfen Sie, ob der Port unter Linux geöffnet ist
Überprüfen Sie, ob der Port unter Linux geöffnet ist








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



