

Vor kurzem haben wir damit begonnen, kurze kostenlose Kurse für diejenigen zu erstellen, die nur wenig Zeit und Budget haben. Die Idee ist, dass Sie in einer Reihe kurzer Videos mit einer Gesamtschauzeit von etwa einer Stunde einige nützliche neue Fähigkeiten erlernen können, ohne einen Cent zu bezahlen.
In unserem neuesten kostenlosen Kurs „Crawling the Web with Python“ lernen Sie die Grundlagen zum Erstellen einfacher Webcrawler und Scraper mit Python.
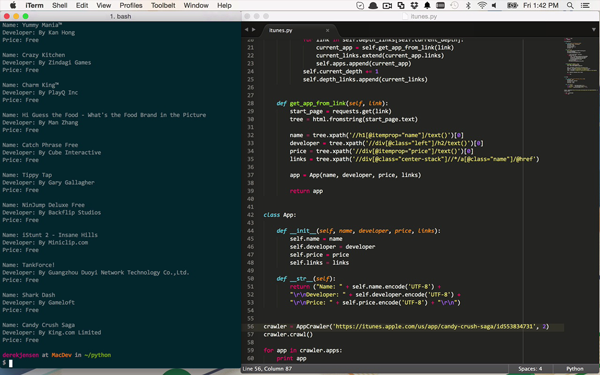
Bei einem kürzlich durchgeführten Geschäftsvorhaben entdeckte Tuts+-Lehrer Derek Jensen die Notwendigkeit, große Datenmengen aus unterschiedlichen Online-Quellen zu sammeln, um die Daten zu zentralisieren und sie für die Menschen leichter auffindbar und verständlich zu machen.
Keine dieser Websites stellte eine öffentliche API zur Verfügung, daher beschloss er, Web-Crawling und Scraping durchzuführen, um an diese Metadaten zu gelangen. Nach einigem Suchen stellte er fest, dass sich viele Leute an Python wandten, wenn sie auf das gleiche Problem stießen.
In diesem Kurs teilt er einige seiner Erkenntnisse und zeigt Ihnen, wie Sie Ihren eigenen einfachen Webcrawler und Scraper erstellen.
Um an diesem kostenlosen Kurs teilzunehmen, gehen Sie einfach auf die Kursseite und befolgen Sie die Schritte zum Erstellen eines kostenlosen Kontos. Wenn Sie bereits ein Konto haben, melden Sie sich einfach an, um sofort loszulegen.
Das obige ist der detaillierte Inhalt vonKostenloses und offenes Python-Tutorial: Verwenden Sie Python zum Crawlen von Netzwerkdaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



