
 Backend-Entwicklung
C++
C++-Programm zum Vergleich der lexikografischen Reihenfolge zweier Zeichenfolgen
Backend-Entwicklung
C++
C++-Programm zum Vergleich der lexikografischen Reihenfolge zweier Zeichenfolgen
C++-Programm zum Vergleich der lexikografischen Reihenfolge zweier Zeichenfolgen


Wörterbuchzeichenfolgenvergleich bedeutet, dass Zeichenfolgen in Wörterbuchreihenfolge verglichen werden. Wenn beispielsweise zwei Zeichenfolgen „apple“ und „appeal“ vorhanden sind, steht die erste Zeichenfolge an letzter Stelle, da die ersten drei Zeichen von „app“ identisch sind. Dann ist das Zeichen für die erste Zeichenfolge „l“ und in der zweiten Zeichenfolge ist das vierte Zeichen „e“. Da „e“ kürzer als „l“ ist, steht es an erster Stelle, wenn wir lexikografisch sortieren.
Zeichenfolgen werden vor dem Anordnen lexikografisch verglichen. In diesem Artikel werden wir sehen Verschiedene Techniken zum lexikografischen Vergleich zweier Zeichenfolgen mit C++.
Verwenden der Funktion „compare()“ in C++-Strings
Das C++-String-Objekt verfügt über eine Funktion „compare()“, die einen anderen String als Eingabe akzeptiert und vergleicht.
Vergleicht die aktuelle Zeichenfolge mit der zweiten Zeichenfolge. Diese Funktion gibt 0 zurück, wenn zwei Zeichenfolgen gleich sind Wenn die Zeichenfolgen gleich sind, wird eine negative Zahl (-1) zurückgegeben, wenn die erste Zeichenfolge größer ist Wenn die erste Zeichenfolge kleiner ist, übersetzen Sie sie ins Chinesische:Wenn die erste Zeichenfolge kleiner ist, handelt es sich um eine positive Zahl (+1).
Grammatik
<first string>.compare( <second string> )
Werfen wir einen Blick auf den Algorithmus und die entsprechende Implementierung in C++.
Algorithmus
- Nehmen Sie zwei Zeichenfolgen s und t als Eingabe
- cmp := Verwenden Sie die Funktion s.compare() mit Parameter t
- Wenn cmp gleich 0 ist, dann
- Diese beiden sind gleich
- Ansonsten, wenn cmp positiv ist, dann
- s ist größer als t
- Ansonsten, wenn cmp negativ ist, dann
- s ist kleiner als t
- end if
Beispiel
#include <iostream>
using namespace std;
string solve( string s, string t ){
int ret;
ret = s.compare( t );
if( ret == 0 ) {
return s + " and " + t + " are the same";
} else if( ret > 0 ) {
return s + " is larger than " + t;
} else {
return s + " is smaller than " + t;
}
}
int main(){
string s = "apple";
string t = "appeal";
cout << "The result of comparison: " << solve( s, t ) << endl;
s = "popular";
t = "popular";
cout << "The result of comparison: " << solve( s, t ) << endl;
s = "Hello";
t = "hello";
cout << "The result of comparison: " << solve( s, t ) << endl;
}
Ausgabe
The result of comparison: apple is larger than appeal The result of comparison: popular and popular are the same The result of comparison: Hello is smaller than hello
Verwenden der Funktion strcmp() mit Zeichenfolgen im C-Stil
In C++ können wir auch traditionelle C-Funktionen verwenden. C verwendet Zeichenarrays anstelle von Zeichenfolgentypen.
Um zwei Zeichenfolgen zu vergleichen, werden die Funktionen strcmp() verwendet Nehmen Sie einen String als Parameter. Gibt 0 zurück, wenn sie gleich sind. Gibt einen positiven Wert zurück, wenn die erste Zeichenfolge kleiner als die zweite Zeichenfolge ist Wenn der zweite Wert größer ist, ist er der größere und negative Wert.Grammatik
strcmp( <first string>, <second string> )
Beispiel
#include <iostream>
#include <cstring>
using namespace std;
string solve( const char* s, const char* t ){
int ret;
ret = strcmp( s, t );
if( ret == 0 ) {
return string(s) + " and " + string(t) + " are the same";
} else if( ret > 0 ) {
return string(s) + " is larger than " + string(t);
} else {
return string(s) + " is smaller than " + string(t);
}
}
int main(){
string s = "apple";
string t = "appeal";
cout << "The result of comparison: " << solve( s.c_str() , t.c_str()) << endl;
s = "popular";
t = "popular";
cout << "The result of comparison: " << solve( s.c_str() , t.c_str()) << endl;
s = "Hello";
t = "hello";
cout << "The result of comparison: " << solve( s.c_str() , t.c_str()) << endl;
}
Ausgabe
The result of comparison: apple is larger than appeal The result of comparison: popular and popular are the same The result of comparison: Hello is smaller than hello
Verwenden Sie Vergleichsoperatoren
Wie numerische Daten können auch Zeichenfolgen mithilfe von Vergleichsoperatoren verglichen werden. wenn-sonst Bedingungen können direkt für Strings in C++ verwendet werden.
Grammatik
strcmp( <first string>, <second string> )
Beispiel
#include <iostream>
using namespace std;
string solve( string s, string t ){
int ret;
if( s == t ) {
return s + " and " + t + " are the same";
} else if( s > t ) {
return s + " is larger than " + t;
} else {
return s + " is smaller than " + t;
}
}
int main(){
string s = "apple";
string t = "appeal";
cout << "The result of comparison: " << solve( s, t ) << endl;
s = "popular";
t = "popular";
cout << "The result of comparison: " << solve( s, t ) << endl;
s = "Hello";
t = "hello";
cout << "The result of comparison: " << solve( s, t ) << endl;
}
Ausgabe
The result of comparison: apple is larger than appeal The result of comparison: popular and popular are the same The result of comparison: Hello is smaller than hello
Fazit
Der String-Vergleich ist eine wichtige Aufgabe, die wir in mehreren Anwendungen durchführen. In C++, Es gibt verschiedene Möglichkeiten, Zeichenfolgen zu vergleichen. Die erste besteht darin, die Methode „compare()“ zu verwenden Der Inhalt, der übersetzt werden muss, ist: Der einen String als Eingabe nimmt und den Vergleich mit dem aktuellen String prüft Für den String-Vergleich können Operatoren wie (==), (>), (=) verwendet werden. auf der anderen Seite, C-ähnliche Strings können mit der Funktion strcmp() verglichen werden. Diese Funktion akzeptiert Konstanten Zeichenzeiger. Die Methode „compare()“ und die Methode „strcmp()“ geben 0 zurück, wenn beide Wenn die erste Zeichenfolge größer ist, wird eine positive Zahl zurückgegeben; wenn die beiden Zeichenfolgen gleich sind, wird 0 zurückgegeben. Der erste Wert ist kleiner und gibt eine positive Zahl zurück.
Das obige ist der detaillierte Inhalt vonC++-Programm zum Vergleich der lexikografischen Reihenfolge zweier Zeichenfolgen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Übersetzen Sie Folgendes ins Chinesische: C-Programm zur Konvertierung römischer Ziffern in Dezimalzahlen
Sep 05, 2023 pm 09:53 PM
Übersetzen Sie Folgendes ins Chinesische: C-Programm zur Konvertierung römischer Ziffern in Dezimalzahlen
Sep 05, 2023 pm 09:53 PM
Nachfolgend finden Sie einen C-Sprachalgorithmus zum Konvertieren römischer Ziffern in Dezimalzahlen: Algorithmus Schritt 1 – Start Schritt 2 – Römische Ziffern zur Laufzeit lesen Schritt 3 – Länge: = strlen(roman) Schritt 4 – Für i=0 bis Länge-1 Schritt 4.1-switch(roman[i]) Schritt 4.1.1-case'm': &nbs
 C++-Programm zum Vergleich der lexikografischen Reihenfolge zweier Zeichenfolgen
Sep 04, 2023 pm 05:13 PM
C++-Programm zum Vergleich der lexikografischen Reihenfolge zweier Zeichenfolgen
Sep 04, 2023 pm 05:13 PM
Der lexikografische Zeichenfolgenvergleich bedeutet, dass Zeichenfolgen in Wörterbuchreihenfolge verglichen werden. Wenn beispielsweise zwei Zeichenfolgen „apple“ und „appeal“ vorhanden sind, steht die erste Zeichenfolge an letzter Stelle, da die ersten drei Zeichen von „app“ identisch sind. Dann ist das Zeichen für die erste Zeichenfolge „l“ und in der zweiten Zeichenfolge ist das vierte Zeichen „e“. Da „e“ kürzer als „l“ ist, steht es an erster Stelle, wenn wir lexikografisch sortieren. Zeichenfolgen werden vor der Anordnung lexikografisch verglichen. In diesem Artikel werden wir verschiedene Techniken zum lexikografischen Vergleich zweier Zeichenfolgen mit C++ kennenlernen. Verwendung der Funktion „compare()“ in C++-Strings Das C++-String-Objekt verfügt über eine Funktion „compare()“
 In C/C++ wird die Funktion strcmp() zum Vergleichen zweier Zeichenfolgen verwendet
Sep 10, 2023 am 11:41 AM
In C/C++ wird die Funktion strcmp() zum Vergleichen zweier Zeichenfolgen verwendet
Sep 10, 2023 am 11:41 AM
Die Funktion strcmp() ist eine integrierte Bibliotheksfunktion und wird in der Headerdatei „string.h“ deklariert. Diese Funktion wird zum Vergleichen der Zeichenfolgenargumente verwendet. Sie vergleicht Zeichenfolgen lexikografisch, was bedeutet, dass sie beide Zeichenfolgen Zeichen für Zeichen vergleicht. Sie startet comp
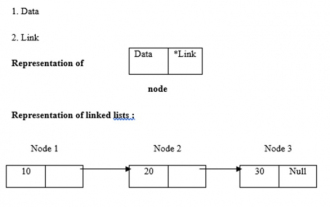 C-Programm zum Ermitteln der Länge einer verknüpften Liste
Sep 07, 2023 pm 07:33 PM
C-Programm zum Ermitteln der Länge einer verknüpften Liste
Sep 07, 2023 pm 07:33 PM
Verknüpfte Listen verwenden eine dynamische Speicherzuweisung, d. h. sie wachsen und schrumpfen entsprechend. Sie werden als Ansammlungen von Knoten definiert. Hier besteht ein Knoten aus zwei Teilen: Daten und Links. Die Darstellung von Daten, Links und verknüpften Listen ist wie folgt: - Arten von verknüpften Listen Es gibt vier Arten von verknüpften Listen: - Einfach verknüpfte Liste / Einfach verknüpfte Liste Doppelt / Doppelt verknüpfte Liste Zirkuläre einfach verknüpfte Liste Zirkuläre doppelt verknüpfte Liste Wir Verwenden Sie die rekursive Methode, um die Länge der verknüpften Liste zu ermitteln. Die Logik lautet -intlength(node *temp){ if(temp==NULL) returnl;
 Das C-Programm verwendet die Funktion rename(), um den Dateinamen zu ändern
Sep 21, 2023 pm 10:01 PM
Das C-Programm verwendet die Funktion rename(), um den Dateinamen zu ändern
Sep 21, 2023 pm 10:01 PM
Die Umbenennungsfunktion ändert den alten Namen einer Datei oder eines Verzeichnisses in den neuen Namen. Dieser Vorgang ähnelt dem Verschiebevorgang. Wir können diese Umbenennungsfunktion also auch zum Verschieben von Dateien verwenden. Diese Funktion ist in der Headerdatei der stdio.h-Bibliothek vorhanden. Die Syntax der Umbenennungsfunktion lautet wie folgt: intrename(constchar*oldname,constchar*newname); Die Funktion der rename()-Funktion akzeptiert zwei Parameter. Einer ist alter Name und der andere ist neuer Name. Beide Parameter sind Zeiger auf konstante Zeichen, die den alten und neuen Namen der Datei definieren. Gibt Null zurück, wenn die Datei erfolgreich umbenannt wurde; andernfalls wird eine Ganzzahl ungleich Null zurückgegeben. Während eines Umbenennungsvorgangs
 C++-Programm zum Ermitteln des Werts der Umkehrfunktion des hyperbolischen Sinus, wobei ein gegebener Wert als Argument verwendet wird
Sep 17, 2023 am 10:49 AM
C++-Programm zum Ermitteln des Werts der Umkehrfunktion des hyperbolischen Sinus, wobei ein gegebener Wert als Argument verwendet wird
Sep 17, 2023 am 10:49 AM
Hyperbelfunktionen werden mithilfe von Hyperbeln anstelle von Kreisen definiert und entsprechen gewöhnlichen trigonometrischen Funktionen. Es gibt den Verhältnisparameter in der hyperbolischen Sinusfunktion aus dem angegebenen Winkel im Bogenmaß zurück. Aber machen Sie das Gegenteil, oder anders gesagt. Wenn wir einen Winkel aus einem hyperbolischen Sinus berechnen wollen, benötigen wir eine umgekehrte hyperbolische trigonometrische Operation wie die hyperbolische Umkehrsinusoperation. In diesem Kurs wird gezeigt, wie Sie die hyperbolische Umkehrsinusfunktion (asinh) in C++ verwenden, um Winkel mithilfe des hyperbolischen Sinuswerts im Bogenmaß zu berechnen. Die hyperbolische Arkussinusoperation folgt der folgenden Formel -$$\mathrm{sinh^{-1}x\:=\:In(x\:+\:\sqrt{x^2\:+\:1})}, Wo\:In\:ist\:natürlicher Logarithmus\:(log_e\:k)
 C++-Programm zum Drucken eines Wörterbuchs
Sep 11, 2023 am 10:33 AM
C++-Programm zum Drucken eines Wörterbuchs
Sep 11, 2023 am 10:33 AM
Eine Karte ist ein spezieller Containertyp in C++, bei dem jedes Element ein Paar aus zwei Werten ist, nämlich einem Schlüsselwert und einem zugeordneten Wert. Der Schlüsselwert wird zum Indizieren jedes Elements verwendet, und der zugeordnete Wert ist der mit dem Schlüssel verknüpfte Wert. Unabhängig davon, ob der zugeordnete Wert eindeutig ist, ist der Schlüssel immer eindeutig. Um Kartenelemente in C++ zu drucken, müssen wir einen Iterator verwenden. Ein Element in einer Menge von Elementen wird durch ein Iteratorobjekt angegeben. Iteratoren werden hauptsächlich mit Arrays und anderen Arten von Containern (z. B. Vektoren) verwendet und verfügen über einen bestimmten Satz von Operationen, mit denen bestimmte Elemente innerhalb eines bestimmten Bereichs identifiziert werden können. Iteratoren können inkrementiert oder dekrementiert werden, um auf verschiedene Elemente in einem Bereich oder Container zu verweisen. Der Iterator zeigt auf den Speicherort eines bestimmten Elements im Bereich. Drucken einer Karte in C++ mit Iteratoren Schauen wir uns zunächst an, wie man definiert
 C++-Programm zum Überprüfen, ob ein Zeichen alphabetisch oder nicht alphabetisch ist
Sep 14, 2023 pm 03:37 PM
C++-Programm zum Überprüfen, ob ein Zeichen alphabetisch oder nicht alphabetisch ist
Sep 14, 2023 pm 03:37 PM
Die Verwendung von Zeichenfolgen oder Zeichen ist manchmal sehr nützlich, wenn man einige Probleme der Logikprogrammierung löst. Eine Zeichenfolge ist eine Sammlung von Zeichen. Dabei handelt es sich um einen 1-Byte-Datentyp, der zum Speichern von Symbolen in ASCII-Werten verwendet wird. Symbole können englische Buchstaben, Zahlen oder Sonderzeichen sein. In diesem Artikel erfahren Sie, wie Sie mit C++ überprüfen, ob ein Zeichen ein englischer Buchstabe oder ein Buchstabe des Alphabets ist. Überprüfen der Funktion isalpha() Um zu überprüfen, ob eine Zahl ein Buchstabe ist, können wir die Funktion isalpha() in der Header-Datei ctype.h verwenden. Dies nimmt ein Zeichen als Eingabe und gibt „true“ zurück, wenn es sich um ein Alphabet handelt, andernfalls „false“. Schauen wir uns die folgende C++-Implementierung an, um die Verwendung dieser Funktion zu verstehen. Die chinesische Übersetzung von Beispiel lautet: show
