

Datenbankverwaltung in Python: SQLite und Redis

Im Informationszeitalter, in dem wir leben, können wir sehen, wie viele Daten die Welt austauscht. Grundsätzlich erstellen, speichern und rufen wir Daten im großen Stil ab! Es sollte doch eine Möglichkeit geben, mit all dem umzugehen – es gibt keine Möglichkeit, dass es sich ohne jegliches Management überall ausbreitet, oder? Dies ist ein Datenbankverwaltungssystem (DBMS).
Ein DBMS ist ein Softwaresystem, mit dem Sie Daten in einer Datenbank erstellen, speichern, ändern, abrufen und anderweitig bearbeiten können. Solche Systeme variieren auch in ihrer Größe, von kleinen Systemen, die nur auf Personalcomputern laufen, bis hin zu großen Systemen, die auf Großrechnern laufen.
Dieses Tutorial konzentriert sich auf Python, nicht auf Datenbankdesign. Ja, Python ist sehr gut in der Lage, mit Datenbanken zu interagieren, und das werde ich Ihnen in diesem Tutorial zeigen. Sie erfahren, wie Sie mit Python mit SQLite- und Redis-Datenbanken arbeiten.
Lass uns anfangen!
Python-Datenbank-API
Wie oben erwähnt, ist Python in der Lage, mit Datenbanken zu interagieren. Aber wie kann es das tun? Python verwendet die sogenannte Python-Datenbank-API, um mit Datenbanken zu interagieren. Mit dieser API können wir verschiedene Datenbankverwaltungssysteme (DBMS) programmieren. Der auf Codeebene befolgte Prozess ist jedoch für verschiedene DBMS wie folgt derselbe:
- Stellen Sie eine Verbindung zur Datenbank Ihrer Wahl her.
- Erstellen Sie einen Cursor, um mit Daten zu kommunizieren.
- Verwenden Sie SQL, um Daten zu bearbeiten (interaktiv).
- Weist die Verbindung an, SQL-Vorgänge auf die Daten anzuwenden und sie dauerhaft zu machen (Commit) oder sie anzuweisen, diese Vorgänge abzubrechen (Rollback), wodurch die Daten in den Zustand zurückversetzt werden, in dem sie sich vor der Interaktion befanden.
- Schließendie Verbindung zur Datenbank.
SQLite
SQLite ist eine Open-Source-Lösung mit vollem Funktionsumfang, eigenständig (benötigt nur wenig Unterstützung durch externe Bibliotheken), serverlos (kein Server ist zum Ausführen der Datenbank-Engine erforderlich und es handelt sich um eine lokal gespeicherte Datenbank) und ohne Konfiguration (keine Installation oder Konfiguration erforderlich). ), SQL-basiert. Ein leichtes Datenbankverwaltungssystem (das SQL-Abfragen für SQLite-Tabellen ausführen kann) und eine Datendatei zum Speichern von Daten verwendet.
Es ist erwähnenswert, dass SQLite von großen Unternehmen wie Google, Apple, Microsoft usw. verwendet wird, was es sehr zuverlässig macht. In diesem Tutorial verwenden wir SQLite für die Interaktion mit einer Datenbank, genauer gesagt verwenden wir das Modul sqlite3 in Python.
Python und SQLite
Wie oben erwähnt umfasst die Verwendung einer Datenbank fünfHauptschritte. Sehen wir uns diese Schritte in Aktion an.
1. Stellen Sie eine Verbindung zur Datenbank Ihrer Wahl her
Dieser Schritt wird wie folgt umgesetzt:
conn = sqlite3.connect('company.db')
Wie in der sqlite3 Dokumentation angegeben:
Um dieses Modul verwenden zu können, müssen Sie zunächst ein Connection-Objekt erstellen, das die Datenbank darstellt.
Bitte beachten Sie im obigen Code, dass die Daten in der Datei gespeichert werden company.db.
2. Erstellen Sie einen Cursor zur Kommunikation mit Daten
Der nächste Schritt bei der Arbeit mit der Datenbank besteht darin, einen Cursor zu erstellen, wie unten gezeigt:
curs = conn.cursor()
3. Verwenden Sie SQL, um Daten zu manipulieren
Nachdem wir eine Verbindung zur Datenbank hergestellt und den Cursor erstellt haben, können wir nun die Daten verarbeiten (mit ihnen interagieren). Mit anderen Worten: Wir können jetzt SQL-Befehle auf der Datenbank ausführen company.db.
Angenommen, wir möchten eine neue Tabelle Mitarbeiter in der Datenbank Firma erstellen. In diesem Fall müssen wir einen SQL-Befehl ausführen. Dazu verwenden wir die Methode execute() des company 中创建一个新表 employee。在这种情况下,我们需要运行 SQL 命令。为此,我们将使用 sqlite3 模块的 execute()-Moduls. Daher sieht die Python-Anweisung so aus:
curs.execute('创建表员工(姓名,年龄)')
Diese Anweisung führt einen SQL-Befehl aus, der eine Datei mit dem Namen employee 的表,其中包含两列(字段)name 和 age erstellt.
Wir können jetzt einen neuen SQL-Befehl ausführen, um Daten wie unten gezeigt in die Tabelle einzufügen:
curs.execute("插入员工值('Ali', 28)")
Sie können auch mehrere Werte gleichzeitig eingeben, wie unten gezeigt:
值 = [('Brad',54), ('Ross', 34), ('Muhammad', 28), ('Bilal', 44)]
In diesem Fall verwenden wir die Methode execute(),而不是使用方法executemany(), um die oben genannten Mehrfachwerte auszuführen.
curs.executemany('插入员工值(?,?)', value)
4. Änderungen einreichen
In diesem Schritt möchten wir die Änderungen übernehmen (festschreiben), die wir im vorherigen Schritt vorgenommen haben. Es ist ganz einfach und sieht so aus:
conn.commit()
5. Schließen Sie die Verbindung zur Datenbank
Nachdem Sie die Aktion ausgeführt und die Änderungen übernommen haben, besteht der letzte Schritt darin, die Verbindung zu schließen:
conn.close()
Lassen Sie uns alle Schritte in einem Skript zusammenfassen. Das Programm sieht folgendermaßen aus (beachten Sie, dass wir zuerst das Modul importieren müssen):
import sqlite3
conn = sqlite3.connect('company.db')
curs = conn.cursor()
curs.execute('create table employee (name, age)')
curs.execute("insert into employee values ('Ali', 28)")
values = [('Brad',54), ('Ross', 34), ('Muhammad', 28), ('Bilal', 44)]
curs.executemany('insert into employee values(?,?)', values)
conn.commit()
conn.close()
sqlite3Wenn Sie das Skript ausführen, sollten Sie eine Datei mit dem Namen im aktuellen Verzeichnis erhalten. Laden Sie diese Datei herunter, da wir sie im nächsten Schritt verwenden werden.
company.db6. Lass uns die Datenbank durchsuchen
Nachdem wir die Datenbank und die Tabellen erstellt und einige Daten hinzugefügt haben, sehen wir uns an, was sich darin befindet
(die Datei, die Sie im vorherigen Abschnitt heruntergeladen haben). Hierfür verwenden wir ein großartiges Tool: DB Browser für SQLite. Fahren Sie fort und laden Sie das Tool auf Ihren Computer herunter. Nach dem Öffnen des Programms sollte ein Bildschirm wie dieser angezeigt werden:
company.db
 Öffnen Sie die Datenbank über die Schaltfläche
Öffnen Sie die Datenbank über die Schaltfläche
oben. In diesem Fall sollten Sie die Datenbankstruktur wie unten gezeigt erhalten:
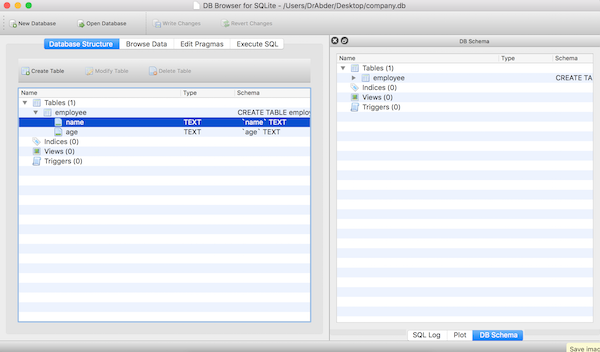 Bitte beachten Sie, dass wir Tische aufgelistet haben
Bitte beachten Sie, dass wir Tische aufgelistet haben
employee,其中包含两个字段:name 和 ageUm zu bestätigen, dass der obige Code funktioniert und die Daten zur Tabelle hinzugefügt wurden, klicken Sie auf die Registerkarte
. Sie sollten etwa Folgendes sehen:
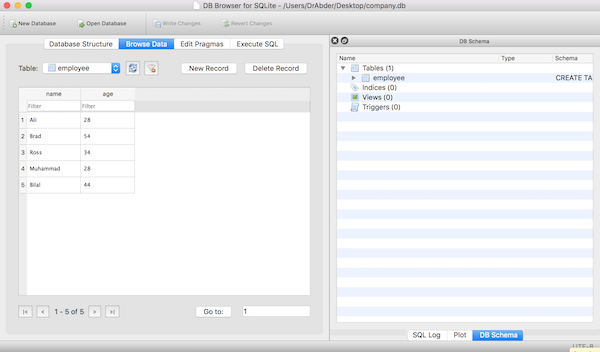 Sie können sehen, dass die Datenbank (
Sie können sehen, dass die Datenbank (
company)和表(employeeRedis
Redis genannt, ist eine leistungsstarke NoSQL-Datenbank, die auch als In-Memory-Cache fungieren kann. Redis wurde von Salvatore Sanfilippo entwickelt und wird derzeit von Redis Labs gepflegt. Die Software ist in der Programmiersprache C geschrieben und Open Source (BSD-Lizenz).
Eines der bemerkenswertesten Merkmale von Redis ist der Speichermechanismus für die Datenstruktur. Sie können Daten in Redis mit denselben Datentypen wie in Python speichern (Strings, Mengen, Ganzzahlen, Listen, Wörterbücher usw.).Das macht Redis zu einer beliebten Wahl unter Python-Entwicklern.
Redis und PythonZusätzlich zum Speichermechanismus für die Datenstruktur bevorzugen Python-Entwickler Redis gegenüber anderen NoSQL-Datenbanken auch aufgrund der großen Anzahl von Python-Clients, von denen die beliebteste Wahl wahrscheinlich redis-py ist. Redis-py bietet integrierte Befehle zum Speichern verschiedener Daten auf einem Redis-Server.
Da wir nun ein grundlegendes Verständnis von Redis haben, lernen wir, wie man Daten darin speichert. Bevor Sie fortfahren, stellen Sie sicher, dass auf Ihrem Computer ein Redis-Server installiert ist.
1. Installieren Sie den Redis.py-Client
Erstellen Sie zunächst einen neuen Ordner mit dem Namen
redis-python für Ihr Python-Skript. Wechseln Sie als Nächstes mit dem Befehlsterminal in den Ordner und führen Sie den folgenden Befehl aus, um den Redis-Client zu installieren:
pip install redis
app.py in redis-python und öffnen Sie sie mit einem Texteditor. Der nächste Schritt besteht darin, ein Python-Skript zu erstellen, um Daten zur Datenbank hinzuzufügen.
2. Verbinden Sie den Redis-Client mit dem Redis-ServerZuerst importieren Sie in
app.py und legen die Variablen für den Redis-Server-Host und die Portadresse fest: redis
import redis
redis_host = 'localhost'
redis_port = 6379
user = {
'ID': 1,
'name': 'Kingsley Ubah',
'email': 'ubahthebuilder@gmail.com',
'role': 'Tech Writing',
}
-Block, um das Fehlerobjekt zu drucken. Im letzten Teil wird die Funktion ausgeführt: try... except 定义 add_to_db 函数。在 try 块中,我们连接到本地 Redis 服务器并将上述字典存储在数据库中,然后在控制台上输出值。如果代码失败,我们会在 except
def add_to_db():
try:
r = redis.StrictRedis(host = redis_host, port = redis_port, decode_responses=True)
r.hmset("newUserOne", user)
msg = r.hgetall("newUserOne")
print(msg)
except Exception as e:
print(f"Something went wrong {e}")
# Runs the function:
if __name__ == "__main__":
add_to_db()
redis-cli
python app.py
如果一切顺利,包含用户配置文件的字典将使用 newUserOne 键添加到 Redis。此外,您应该在终端控制台上看到以下输出:
{
'ID': '1',
'name': 'Kingsley Ubah',
'email': 'ubahthebuilder@gmail.com',
'role': 'Tech Writing',
}
这就是 Redis 的全部内容!
结论
本教程仅触及使用 Python 处理数据库的皮毛。您可以从 sqlite3 模块了解更多方法,您可以在其中执行不同的数据库操作,例如更新和查询数据库。
要了解有关 redis-py 的更多信息,请立即阅读其完整文档。玩得开心!
Das obige ist der detaillierte Inhalt vonDatenbankverwaltung in Python: SQLite und Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
So sehen Sie alle Schlüssel in Redis
Apr 10, 2025 pm 07:15 PM
Um alle Schlüssel in Redis anzuzeigen, gibt es drei Möglichkeiten: Verwenden Sie den Befehl keys, um alle Schlüssel zurückzugeben, die dem angegebenen Muster übereinstimmen. Verwenden Sie den Befehl scan, um über die Schlüssel zu iterieren und eine Reihe von Schlüssel zurückzugeben. Verwenden Sie den Befehl Info, um die Gesamtzahl der Schlüssel zu erhalten.
 Was tun, wenn Redis-Server nicht gefunden werden kann
Apr 10, 2025 pm 06:54 PM
Was tun, wenn Redis-Server nicht gefunden werden kann
Apr 10, 2025 pm 06:54 PM
Schritte zur Lösung des Problems, das Redis-Server nicht finden kann: Überprüfen Sie die Installation, um sicherzustellen, dass Redis korrekt installiert ist. Setzen Sie die Umgebungsvariablen Redis_host und Redis_port; Starten Sie den Redis-Server Redis-Server; Überprüfen Sie, ob der Server Redis-Cli Ping ausführt.
 So verwenden Sie Redis Zset
Apr 10, 2025 pm 07:27 PM
So verwenden Sie Redis Zset
Apr 10, 2025 pm 07:27 PM
Redis bestellte Sets (ZSETs) werden verwendet, um bestellte Elemente und Sortieren nach zugehörigen Bewertungen zu speichern. Die Schritte zur Verwendung von ZSET umfassen: 1. Erstellen Sie ein Zset; 2. Fügen Sie ein Mitglied hinzu; 3.. Holen Sie sich eine Mitgliederbewertung; 4. Holen Sie sich eine Rangliste; 5. Holen Sie sich ein Mitglied in der Rangliste; 6. Ein Mitglied löschen; 7. Holen Sie sich die Anzahl der Elemente; 8. Holen Sie sich die Anzahl der Mitglieder im Score -Bereich.
 So verwenden Sie den Redisschalter
Apr 10, 2025 pm 07:00 PM
So verwenden Sie den Redisschalter
Apr 10, 2025 pm 07:00 PM
REDIS -Zähler bieten Datenstrukturen für das Speichern und Betriebszähler an. Zu den spezifischen Schritten gehören: Erstellen eines Zählers: Verwenden Sie den Befehl Inc Inc, um dem vorhandenen Schlüssel 1 hinzuzufügen. Holen Sie sich den Zählerwert: Verwenden Sie den Befehl GET, um den aktuellen Wert zu erhalten. Increment -Zähler: Verwenden Sie den Befehl Incby, gefolgt von der zu erhöhten Menge. Decrement -Zähler: Verwenden Sie den Befehl Decr oder Decrby, um um 1 zu verringern, oder geben Sie die Menge an. Setzen Sie den Zähler zurück: Verwenden Sie den Befehl SET, um seinen Wert auf 0 festzulegen. Darüber hinaus können Zähler verwendet werden, um die Tarife, die Sitzungsverfolgung und das Erstellen von Abstimmungssystemen zu begrenzen.
 Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Sie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Wie ist der Schlüssel für die Redis -Abfrage eindeutig
Apr 10, 2025 pm 07:03 PM
Wie ist der Schlüssel für die Redis -Abfrage eindeutig
Apr 10, 2025 pm 07:03 PM
Redis verwendet fünf Strategien, um die Einzigartigkeit von Schlüssel zu gewährleisten: 1. Namespace -Trennung; 2. Hash -Datenstruktur; 3.. Datenstruktur festlegen; 4. Sonderzeichen von Stringschlüssel; 5. Lua -Skriptüberprüfung. Die Auswahl spezifischer Strategien hängt von Datenorganisationen, Leistung und Skalierbarkeit ab.
