
 Technologie-Peripheriegeräte
KI
Jia Qianghuai: Konstruktion und Anwendung eines groß angelegten Wissensgraphen von Ameisen
Technologie-Peripheriegeräte
KI
Jia Qianghuai: Konstruktion und Anwendung eines groß angelegten Wissensgraphen von Ameisen
Jia Qianghuai: Konstruktion und Anwendung eines groß angelegten Wissensgraphen von Ameisen


1. Überblick über den Graphen
Stellen Sie zunächst einige grundlegende Konzepte des Wissensgraphen vor.
1. Was ist ein Wissensgraph?
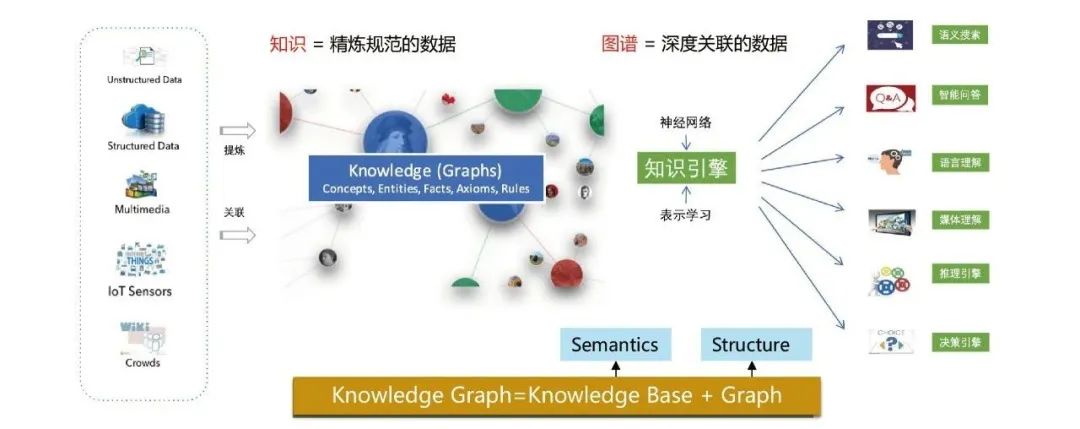
Der Wissensgraph zielt darauf ab, komplexe Beziehungen zwischen Dingen zu modellieren, zu identifizieren und abzuleiten. Er ist ein wichtiger Eckpfeiler für die Verwirklichung kognitiver Intelligenz hat Es wird häufig in Suchmaschinen, intelligenter Beantwortung von Fragen, sprachsemantischem Verständnis, Big-Data-Entscheidungsanalyse und vielen anderen Bereichen verwendet.
Knowledge Graph modelliert sowohl die semantische Beziehung als auch die strukturelle Beziehung zwischen Daten. In Kombination mit Deep-Learning-Technologie können die beiden Beziehungen besser integriert und dargestellt werden.
2. Warum sollten wir einen Wissensgraphen erstellen? Andererseits, welche Vorteile der Wissensgraph bringen kann.
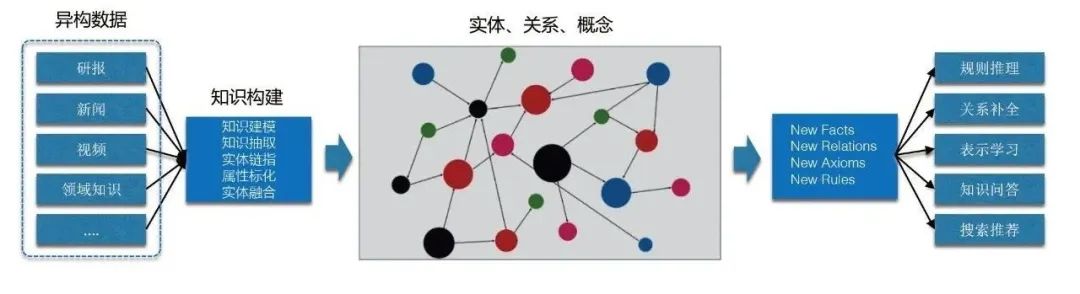
[2] Wissensgraphen können mehrere Vorteile bringen, darunter:
Semantische Standardisierung: Verwenden Sie Graphkonstruktionstechnologie, um den Standardisierungs- und Normalisierungsgrad von Entitäten, Beziehungen, Konzepten usw. zu verbessern.
- Ansammlung von Domänenwissen: Realisieren Sie die Wissensdarstellung und -verbindung basierend auf Semantik und Diagrammstruktur und akkumulieren Sie so umfangreiches Domänenwissen.
- Wiederverwendung von Wissen: Erstellen Sie einen hochwertigen Ant-Wissensgraphen, senken Sie die Geschäftskosten und verbessern Sie die Effizienz durch Integration, Verknüpfung und andere Dienste.
- Entdeckung von Wissensbegründung: Entdecken Sie mehr Long-Tail-Wissen basierend auf der Technologie des Graphenbeschlusses, das Szenarien wie Risikokontrolle, Kredit, Ansprüche, Händlerbetrieb, Marketingempfehlungen usw. bedient. 3. Überblick über die Erstellung von Wissensgraphen Folgende fünf Teile:
- Beginnen Sie mit Geschäftsdaten als wichtiger Datenquelle für den Diagrammkaltstart. Der Wissensgraph anderer Domänen wird in den vorhandenen Graphen integriert, was durch Entity-Alignment-Technologie erreicht wird.
Die Integration der strukturierten Wissensbasis in der Geschäftsdomäne und des vorhandenen Wissensgraphen wird auch durch Entity-Alignment-Technologie erreicht. 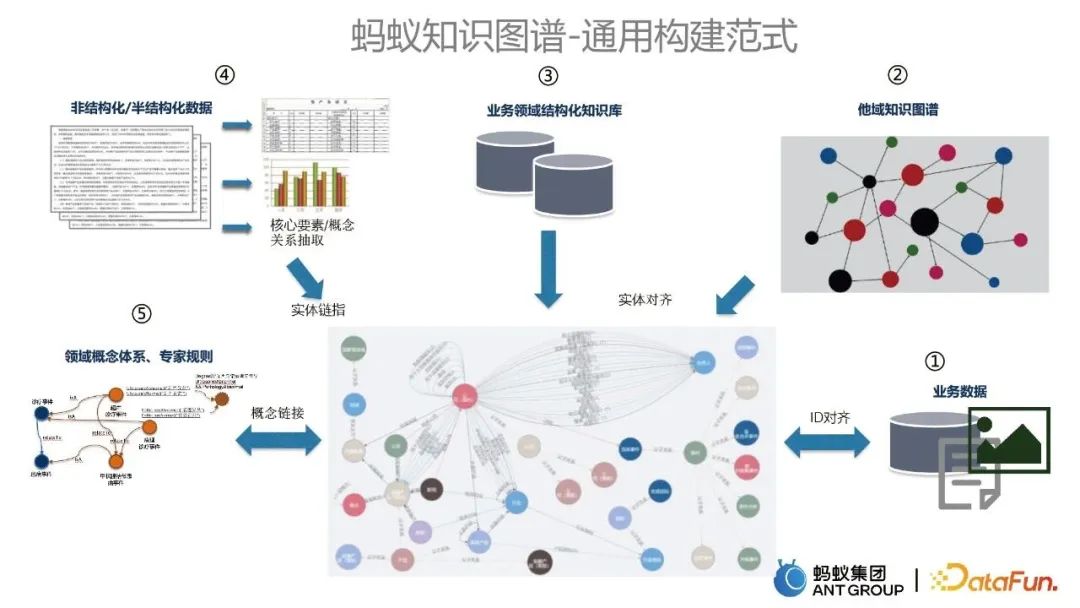
Unstrukturierte und halbstrukturierte Daten, wie z. B. Text, werden verwendet, um Informationen zu extrahieren und die vorhandene Karte durch Entity-Link-Technologie zu aktualisieren.
- Die Integration von Domänenkonzeptsystemen und Expertenregeln verknüpft relevante Konzepte und Regeln mit vorhandenen Wissensgraphen.
- Nachdem ein gemeinsames Konstruktionsparadigma vorliegt, ist es notwendig, eine systematische Konstruktion durchzuführen. Betrachten Sie den systematischen Aufbau des Ant Knowledge Graph aus zwei Perspektiven. Aus algorithmischer Sicht gibt es zunächst verschiedene algorithmische Fähigkeiten, wie z. B. Wissensbegründung, Wissensabgleich usw. Aus der Perspektive der Implementierung umfassen die niedrigsten grundlegenden Abhängigkeiten die Graph-Computing-Engine und die darüber liegende kognitive Basis-Computing-Technologie, einschließlich der NLP- und multimodalen Plattform sowie der darüber liegenden Graph-Konstruktionstechnologien. Auf dieser Grundlage können wir den Wissensgraphen erstellen. Auf der Grundlage des Wissensgraphen können wir weiter oben einige allgemeine Algorithmusfunktionen bereitstellen. 2. Graphkonstruktion
- Als nächstes werden wir einige der Kernkompetenzen der Ant Group bei der Erstellung von Wissensgraphen vorstellen, einschließlich Graphkonstruktion, Graphfusion und Graphkognition.
-
1. Kartenkonstruktion

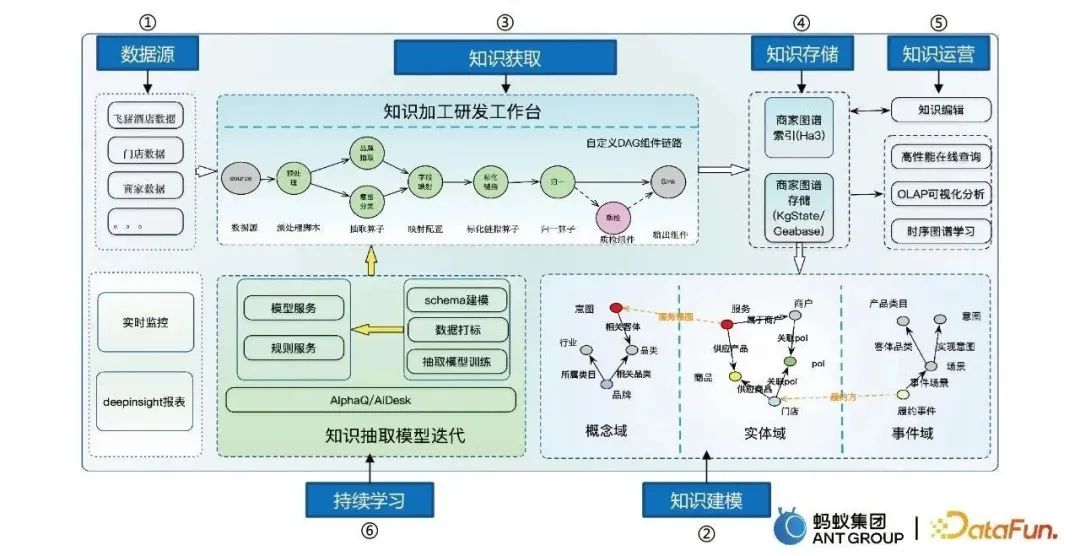
Der Prozess der Kartenkonstruktion umfasst hauptsächlich sechs Schritte:
- Datenquellen zum Erhalten multivariater Daten.
- Wissensmodellierung wandelt massive Daten in strukturierte Daten um und modelliert dabei drei Bereiche: Konzepte, Entitäten und Ereignisse.
- Wissenserwerb und Aufbau einer wissensverarbeitenden F&E-Plattform.
- Wissensspeicher, einschließlich Ha3-Speicher und Diagrammspeicher usw.
- Wissensoperationen, einschließlich Wissensbearbeitung, Online-Abfrage, Extraktion usw.
- Kontinuierliches Lernen, sodass das Modell automatisch und iterativ lernen kann.
Drei Erfahrungen und Fähigkeiten im Konstruktionsprozess
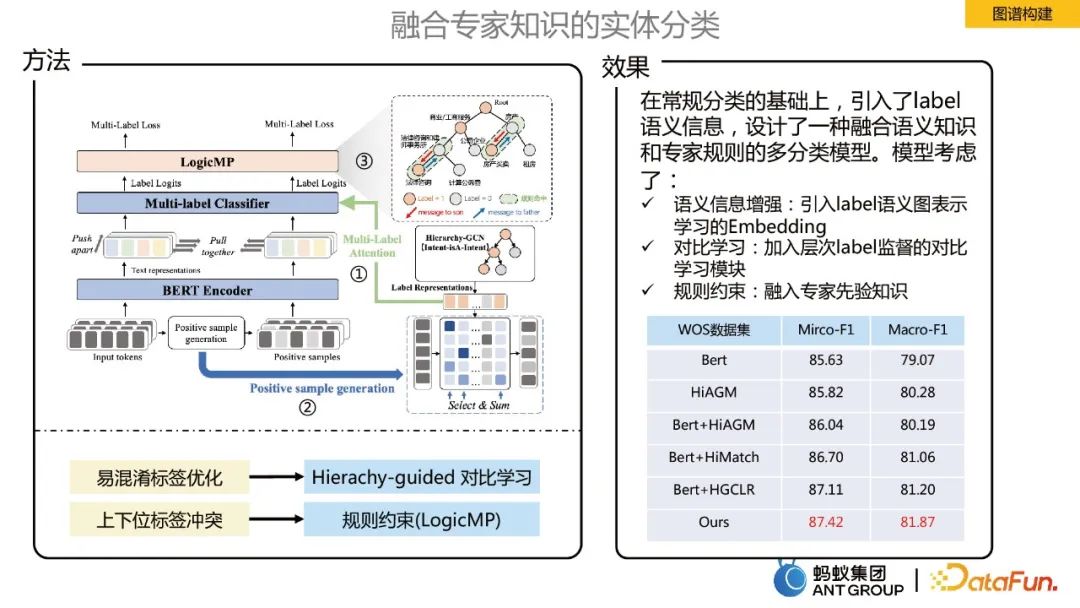
Entitätsklassifizierung unter Einbeziehung von Expertenwissen
Beim Aufbau eines Wissensgraphen ist es notwendig, die Eingabeentitäten zu klassifizieren, was in der Ameise ein großes Problem darstellt Szenario Etikettenklassifizierungsaufgabe. Um Expertenwissen für die Entitätsklassifizierung zu integrieren, werden die folgenden drei Hauptoptimierungspunkte festgelegt:
- Semantische Informationsverbesserung: Einführung der Einbettung des Lernens der semantischen Graphdarstellung von Etiketten.
- Kontrastlernen: Fügen Sie zum Vergleich eine hierarchische Etikettenüberwachung hinzu.
- Logische Regelbeschränkungen: Beziehen Sie das Vorwissen von Experten ein.
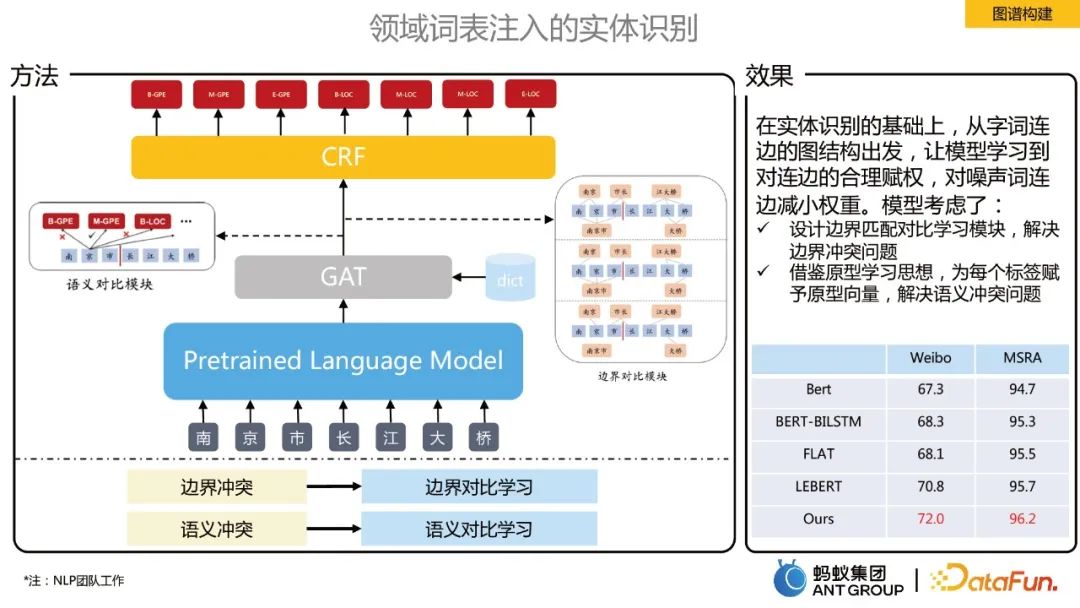
In das Domänenvokabular eingefügte Entitätserkennung
Auf der Grundlage der Entitätserkennung lernt das Modell, ausgehend von der Diagrammstruktur der Wortkanten, eine angemessene Gewichtung von Kanten und verrauschten Wortverbindungen. Reduzieren Sie das Gewicht der Kante . Es werden zwei Module vorgeschlagen: grenzkontrastives Lernen und semantisch-kontrastives Lernen:
- Grenzkontrastives Lernen zur Lösung von Grenzkonfliktproblemen. Nachdem das Vokabular eingefügt wurde, wird ein vollständig verbundener Graph erstellt und GAT wird verwendet, um die Darstellung jedes Tokens zu lernen. Der richtige Teil der Grenzklassifizierung erstellt einen positiven Beispielgraphen und der falsche Teil erstellt einen negativen Beispielgraphen , lernt das Modell die einzelnen Grenzinformationen eines Tokens.
- Semantisches kontrastives Lernen wird zur Lösung semantischer Konfliktprobleme eingesetzt. Basierend auf der Idee des Prototyp-Lernens wird die semantische Darstellung des Etiketts hinzugefügt, um die Assoziation zwischen jedem Token und der Semantik des Etiketts zu stärken.
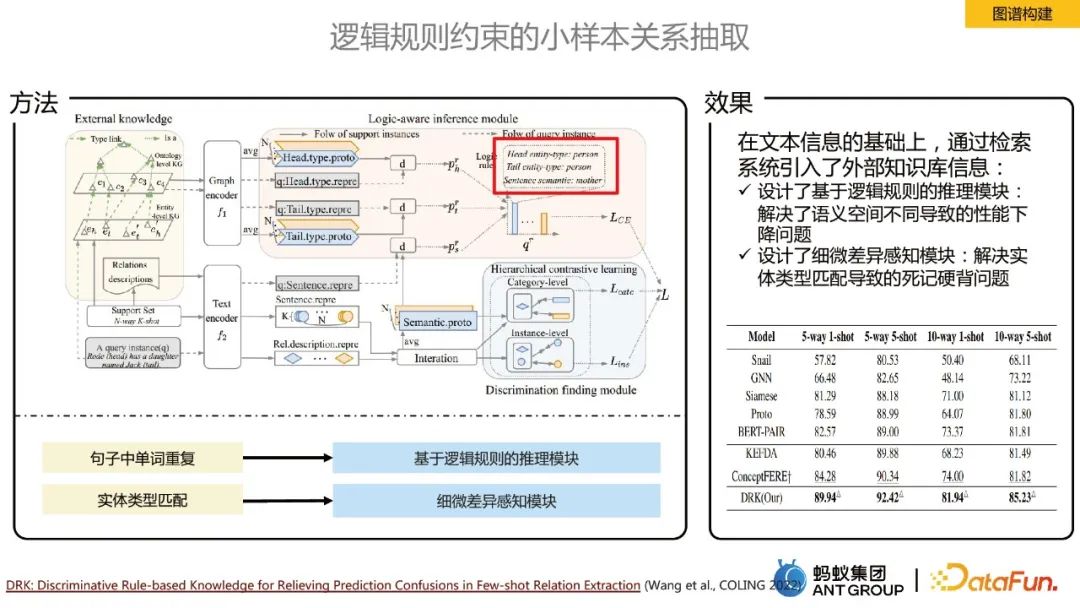
Beziehungsextraktion bei kleinen Stichproben, eingeschränkt durch logische Regeln
Bei Domänenproblemen haben wir nur sehr wenige beschriftete Stichproben und werden mit Szenarien mit wenigen oder null Schüssen konfrontiert. In diesem Fall führen wir eine Beziehungsextraktion durch Die Kernidee besteht darin, eine externe Wissensbasis einzuführen, um das durch verschiedene semantische Räume verursachte Leistungsverschlechterungsproblem zu lösen Es wurde ein Modul zur Wahrnehmung subtiler Unterschiede entwickelt.
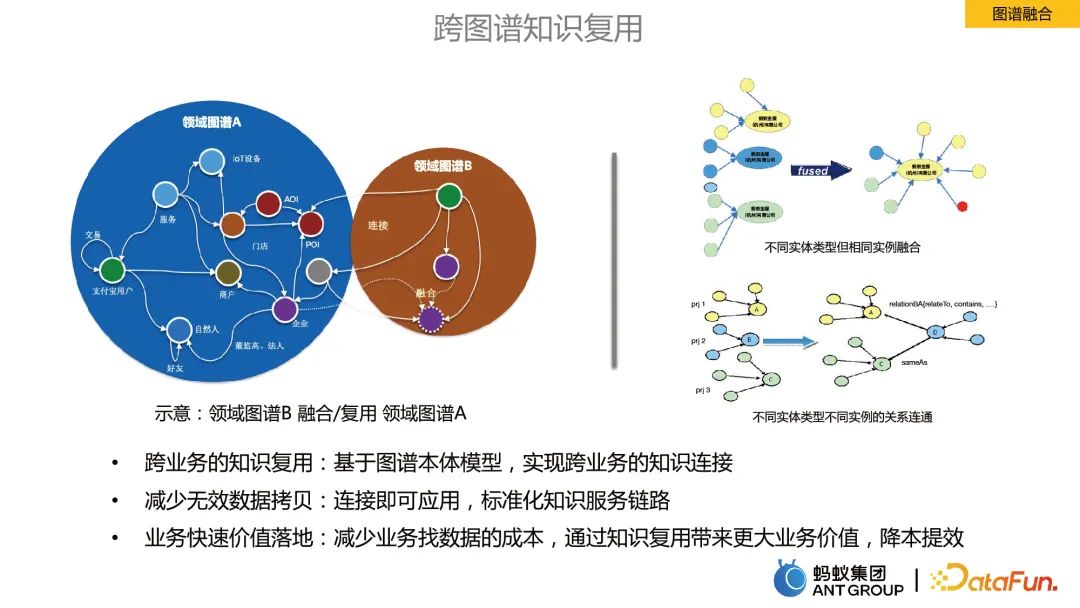
2. Graphfusion
Graphfusion bezeichnet die Zusammenführung von Informationen zwischen Graphen in verschiedenen Geschäftsfeldern.
Vorteile der Graphfusion:
- Geschäftsübergreifende Wiederverwendung von Wissen: Basierend auf dem Graph-Ontologie-Modell wird eine geschäftsübergreifende Wissensverbindung realisiert.
- Reduzieren Sie ungültige Datenkopien: Verbinden und anwenden, standardisierte Wissensservice-Links.
- Schnelle Umsetzung des Geschäftswerts: Reduzieren Sie die Kosten für die Suche nach Daten für Unternehmen, steigern Sie den Geschäftswert durch die Wiederverwendung von Wissen, senken Sie die Kosten und verbessern Sie die Effizienz.
Entitätsausrichtung in der Graphfusion
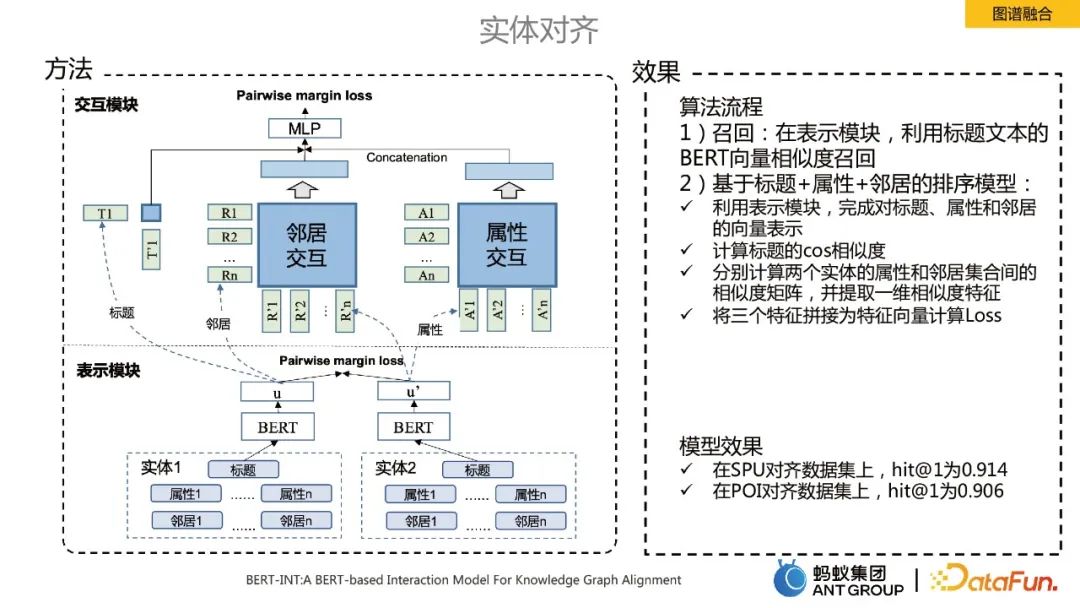
Ein zentraler technischer Punkt im Knowledge-Graph-Fusion-Prozess ist die Entitätsausrichtung. Hier verwenden wir den SOTA-Algorithmus BERT-INT, der hauptsächlich zwei Module umfasst, eines ist das Präsentationsmodul und das andere ist das Interaktionsmodul.
Der Implementierungsprozess des Algorithmus umfasst hauptsächlich Rückruf und Sortierung:
Rückruf: Im Darstellungsmodul wird der BERT-Vektorähnlichkeitsrückruf des Titeltextes verwendet.
Ranking-Modell basierend auf Titel + Attribut + Nachbar: ü Verwenden Sie das Darstellungsmodul, um die Vektordarstellung von Titel, Attribut und Nachbar zu vervollständigen:
- Berechnen Sie die Cos-Ähnlichkeit des Titels.
- Berechnen Sie die Ähnlichkeitsmatrix zwischen den Attributen und Nachbarmengen zweier Entitäten und extrahieren Sie eindimensionale Ähnlichkeitsmerkmale.
- Fügen Sie drei Features zu einem Feature-Vektor zusammen, um den Verlust zu berechnen.
3. Diagrammkognition
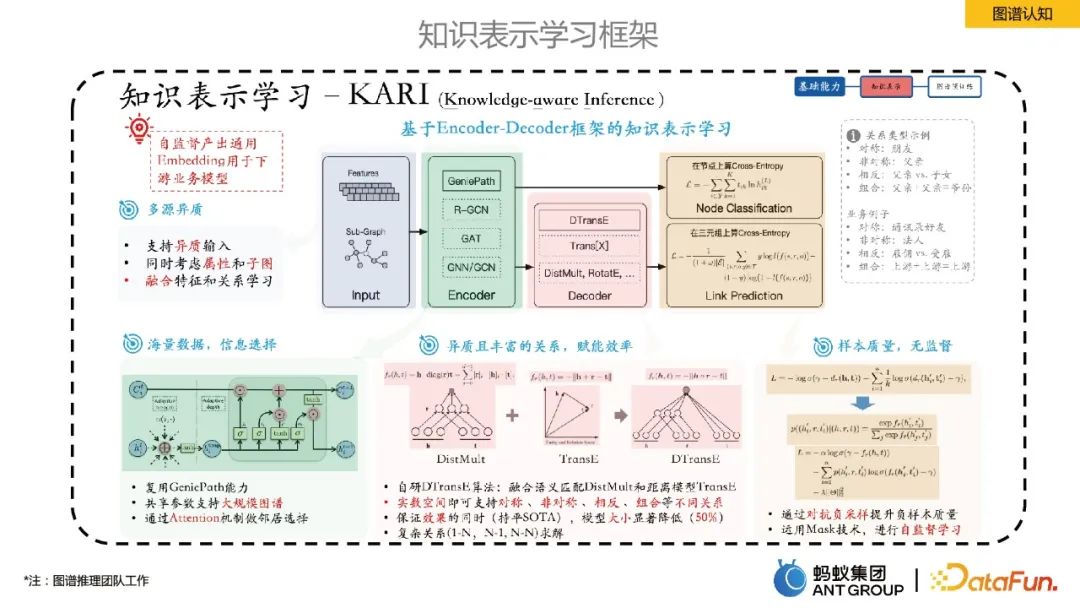
In diesem Teil wird hauptsächlich das interne Wissensrepräsentations-Lernframework von Ant vorgestellt.
Ant schlug ein Wissensrepräsentationslernen basierend auf dem Encoder-Decoder-Framework vor. Unter diesen handelt es sich bei Encoder um einige graphische neuronale Lernmethoden und Decoder um einige Methoden zum Wissensrepräsentationslernen, wie z. B. Linkvorhersage. Dieses Repräsentationslern-Framework kann die Produktion universeller Entitäts-/Beziehungseinbettungen selbst überwachen, was mehrere Vorteile hat: 1) Die Einbettungsgröße ist viel kleiner als der ursprüngliche Merkmalsraum, wodurch die Speicherkosten gesenkt werden das Problem der Datenspärlichkeit; 3) Das Lernen im selben Vektorraum macht die Fusion heterogener Daten aus mehreren Quellen natürlicher. 4) Die Einbettung hat eine gewisse Universalität und ist praktisch für die nachgelagerte Geschäftsnutzung.
3. Graph-Anwendung
Als nächstes werde ich einige typische Anwendungsfälle von Wissensgraphen in der Ant Group vorstellen.
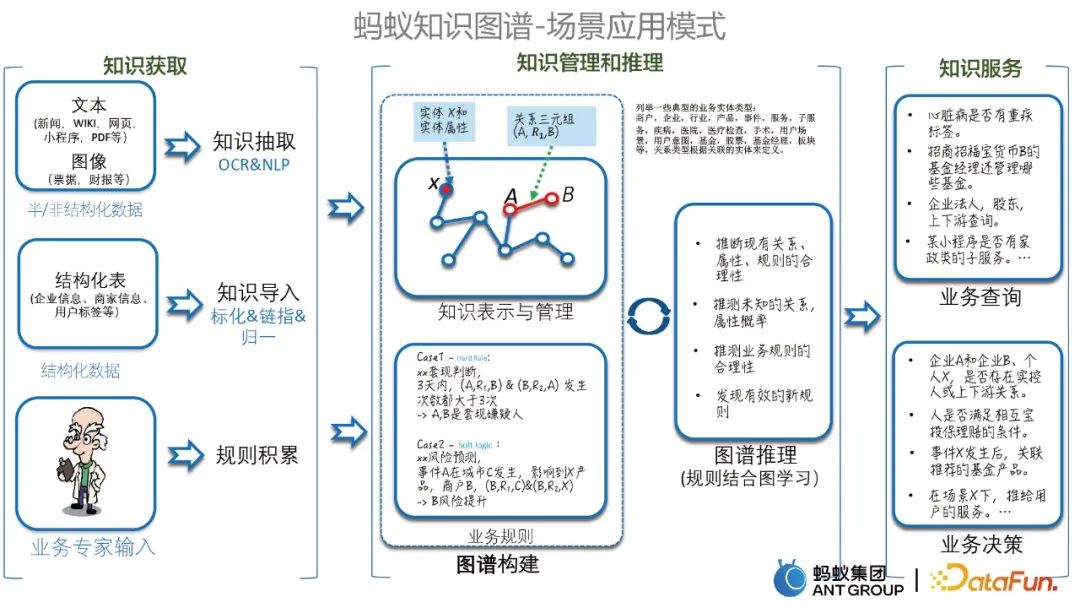
1. Szenarioanwendungsmodi des Diagramms
Bevor wir spezifische Fälle vorstellen, stellen wir zunächst verschiedene Modi der Szenarioanwendung des Ant Knowledge Graph vor, die hauptsächlich Wissenserwerb, Wissensmanagement und -schlussfolgerung sowie Wissensdienste umfassen. Wie unten gezeigt. 2. Einige typische Fälle Die Schwachstellen sind:
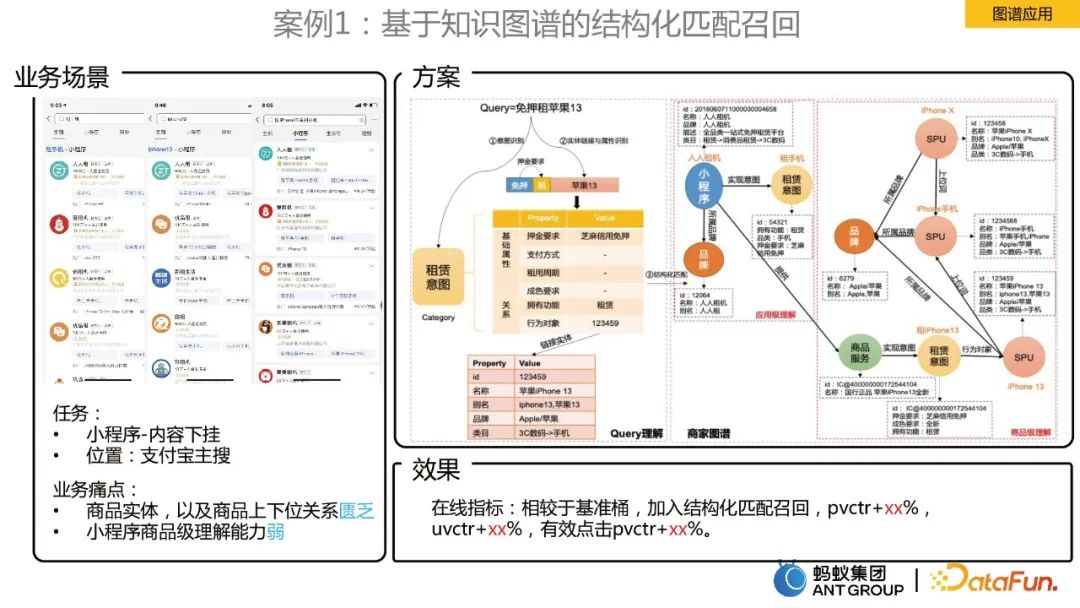
Das Fehlen von Produkteinheiten und die Beziehung zwischen der oberen und unteren Ebene der Produkte.
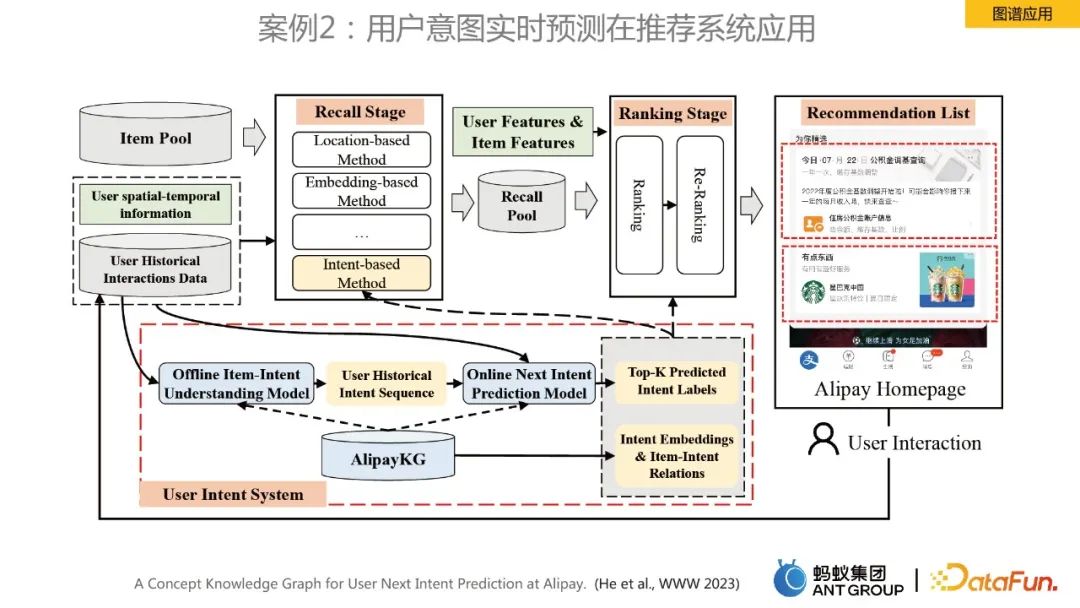
Schwaches Verständnis für kleine Programme auf Produktebene.- Die Lösung besteht darin, einen Händlerwissensgraphen zu erstellen. In Kombination mit der Produktbeziehung der Händlerkarte wird ein strukturiertes Verständnis der Produktebene der Benutzerabfrage erreicht. Fall 2: Anwendung der Echtzeitvorhersage der Benutzerabsicht im Empfehlungssystem
- In diesem Fall geht es um die Echtzeitvorhersage der Benutzerabsicht für Homepage-Empfehlungen. Das Framework wurde in AlipayKG erstellt die Abbildung oben. Verwandte Arbeiten wurden auch auf der Top-Konferenz www 2023 veröffentlicht. Zum weiteren Verständnis können Sie sich auf das Papier beziehen.
Dieses Szenario ist ein Szenario für Verbraucher-Coupon-Empfehlungen, mit denen das Unternehmen konfrontiert ist:
- Erhebliche Wirkung auf den Kopf.
- Benutzerüberprüfung und Erfassungsverhalten sind spärlich.
- Es gibt viele Kaltstartnutzer und Gutscheine, aber die entsprechenden Footprint-Daten fehlen.
Um die oben genannten Probleme zu lösen, haben wir einen Deep-Vector-Recall-Algorithmus entwickelt, der die dynamische Diagrammdarstellung verschmilzt. Da wir festgestellt haben, dass das Verhalten von Benutzerverbrauchsgutscheinen zyklisch ist, kann eine statische Einzelkante dieses zyklische Verhalten nicht modellieren. Zu diesem Zweck haben wir zunächst ein dynamisches Diagramm erstellt und dann den vom Team selbst entwickelten dynamischen Diagrammalgorithmus verwendet, um die Einbettungsdarstellung zu erlernen. Nachdem wir die Darstellung erhalten haben, haben wir sie zum Vektorabruf in das Zwillingsturmmodell eingefügt.
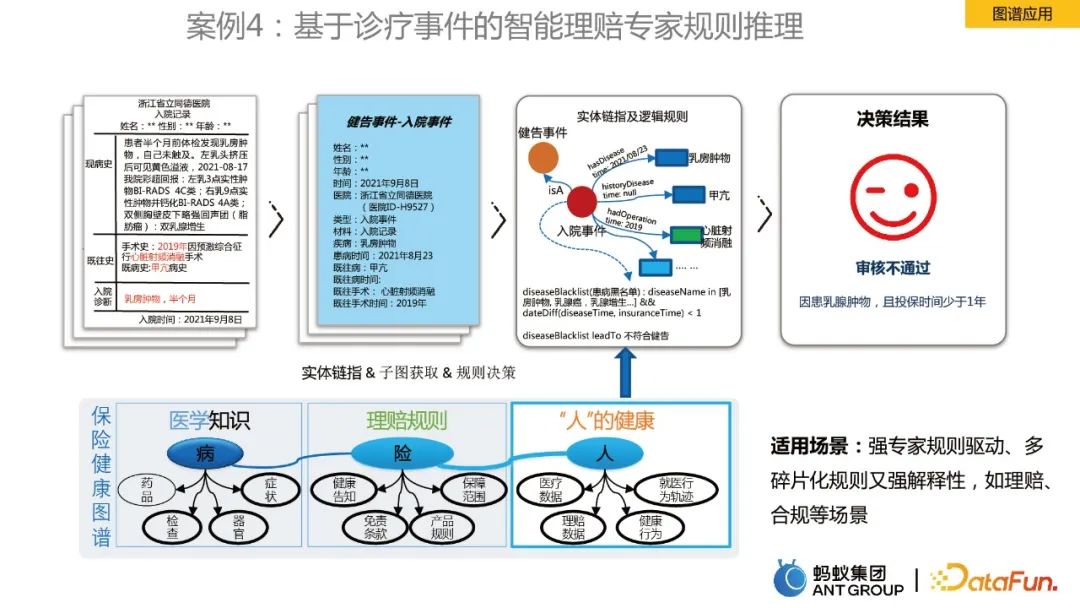
Fall 4: Intelligente Argumentation von Schadensexpertenregeln auf der Grundlage von Diagnose- und Behandlungsereignissen
Im letzten Fall geht es um die Argumentation von Diagrammregeln. Am Beispiel der Krankenversicherungs-Gesundheitskarte umfasst sie medizinisches Wissen, Schadensregeln und „Personen“-Gesundheitsinformationen, die mit Entitäten verknüpft und mit logischen Regeln als Entscheidungsgrundlage gekoppelt sind. Durch die Karte wurde die Effizienz der Schadenregulierung durch Sachverständige verbessert.
4. Diagramme und große Modelle
Lassen Sie uns abschließend kurz die Möglichkeiten von Wissensdiagrammen im Kontext der aktuellen rasanten Entwicklung großer Modelle diskutieren.
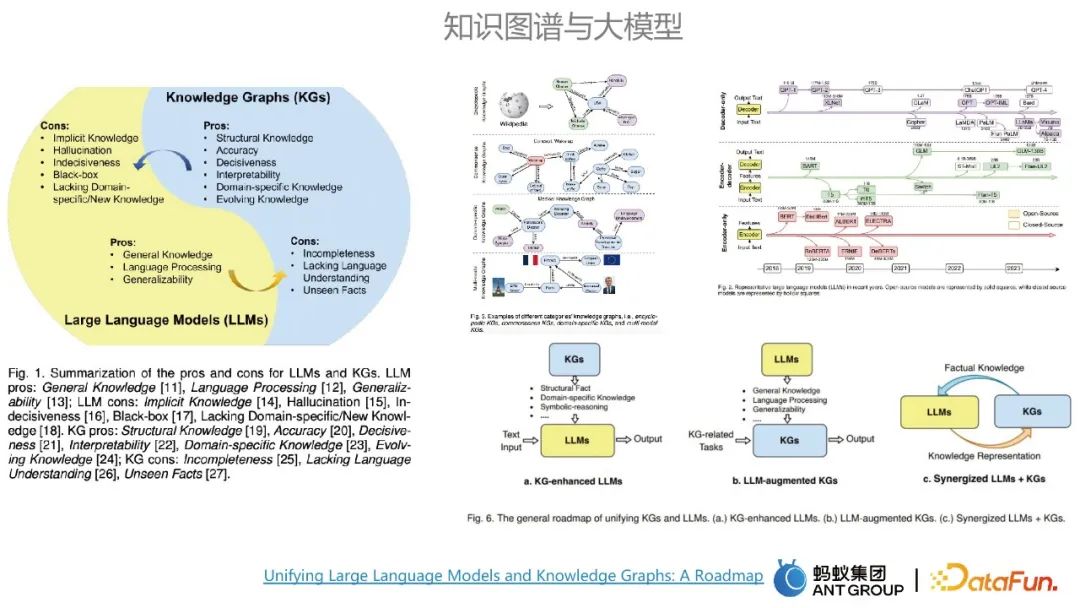
1. Die Beziehung zwischen Wissensgraphen und großen Modellen
Wissensgraphen und große Modelle haben jeweils ihre eigenen Vor- und Nachteile. Die Hauptvorteile großer Modelle sind allgemeine Wissensmodellierung und Universalität, während die Nachteile großer Modelle sind Modelle sind genau richtig. Dies kann durch die Vorteile des Wissensgraphen ausgeglichen werden. Zu den Vorteilen der Karte gehören eine hohe Genauigkeit und eine gute Interpretierbarkeit. Große Modelle und Wissensgraphen können sich gegenseitig beeinflussen.
Es gibt normalerweise drei Wege zur Integration von Diagrammen und großen Modellen. Der eine besteht darin, Wissensgraphen zu verwenden, um große Modelle zu verbessern. Der dritte besteht darin, mit großen Modellen zusammenzuarbeiten und Wissensgraphen, ergänzende Vorteile, das große Modell kann als parametrisierte Wissensbasis betrachtet werden, und der Wissensgraph kann als angezeigte Wissensbasis betrachtet werden. 2. Anwendungsfälle von großen Modellen und Wissensgraphen Relationales Denken.
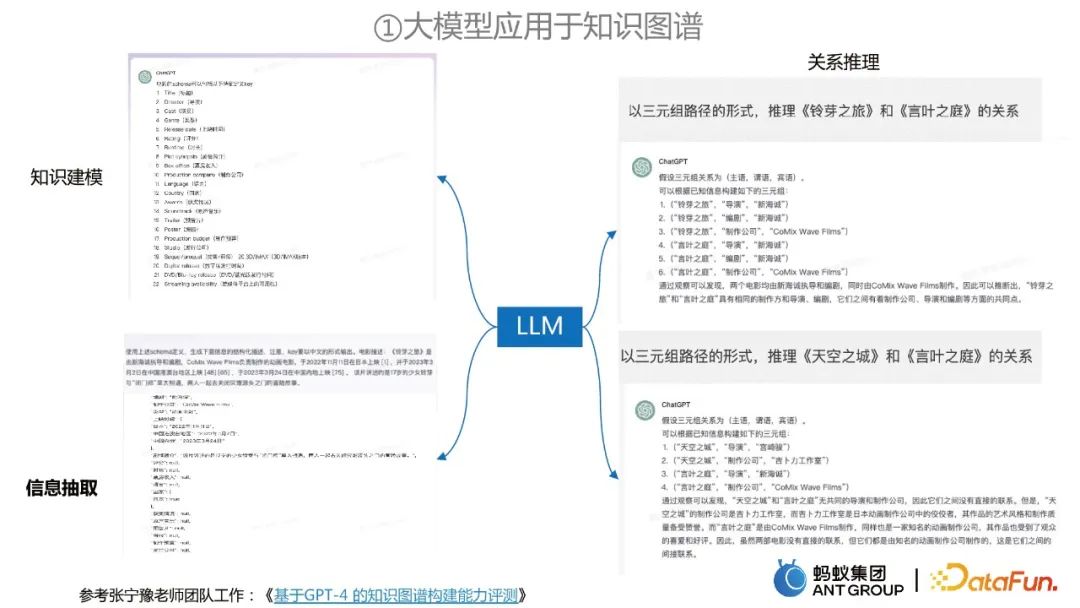
Wie man große Modelle zur Informationsextraktion aus Wissensgraphen verwendet
Diese Arbeit der DAMO Academy zerlegt das Problem der Informationsextraktion in zwei Phasen:In der ersten Phase wollen wir Finden Sie die im Text vorhandenen Entitäten, Beziehungen oder Ereignistypen, um den Suchraum und die Rechenkomplexität zu reduzieren.
In der zweiten Stufe extrahieren wir weitere relevante Informationen basierend auf den zuvor extrahierten Typen und der gegebenen entsprechenden Liste.
- Anwenden von Wissensgraphen auf große Modelle
- Die Anwendung von Wissensgraphen auf große Modelle umfasst hauptsächlich drei Aspekte:
Integrieren Sie den Wissensgraphen in das Training großer Modelle. Beispielsweise können zwei Aufgaben gleichzeitig trainiert werden. Der Wissensgraph kann für Wissensdarstellungsaufgaben verwendet werden, und das große Modell kann für das Vortraining von MLM verwendet werden, und beide werden gemeinsam modelliert. Injizieren Sie einen Wissensgraphen in die Argumentation großer Modelle. Erstens können zwei Probleme mit großen Modellen gelöst werden. Das eine besteht darin, den Wissensgraphen als a priori-Einschränkungen zu verwenden, um den „Unsinn“ großer Modelle zu vermeiden. Andererseits können basierend auf Wissensgraphen interpretierbare Lösungen für die Generierung großer Modelle bereitgestellt werden.
Wissensgestütztes Q&A-System
Die eine ist das wissensgraphengestützte Q&A-System, das ein großes Modell zur Optimierung des KBQA-Modells verwendet; die andere ist die Verbesserung des Informationsabrufs, ähnlich wie LangChain, GopherCite , und New Bing Verwenden Sie große Modelle, um Wissensdatenbankfragen und -antworten zu formulieren.
Das wissensgestützte generative Such-Frage- und Antwortsystem bietet folgende Vorteile:
- Lösen Sie das Aktualitätsproblem, indem Sie auf das Suchsystem zugreifen.
- Durch die Bereitstellung eines Referenzlinks kann eine manuelle Überprüfung durchgeführt werden, um sachliche Fehler zu beheben.
- Führt Suchergebnisse ein, bereichert den Kontext und verbessert die Effekte bei der Generierung großer Modelle.
3. Zusammenfassung und Ausblick
Wie Wissensgraphen und große Modelle besser interagieren und zusammenarbeiten können, einschließlich der folgenden drei Richtungen:
- Wissensgraphen und große Modelle in NLP fördern, In -Tiefgreifende Anwendungen in Bereichen wie Frage-Antwort-Systemen.
- Verwendung von Wissensgraphen zur Halluzinationserkennung und Entgiftung großer Modelle.
- Entwicklung großer Domänenmodelle kombiniert mit Wissensgraphen.

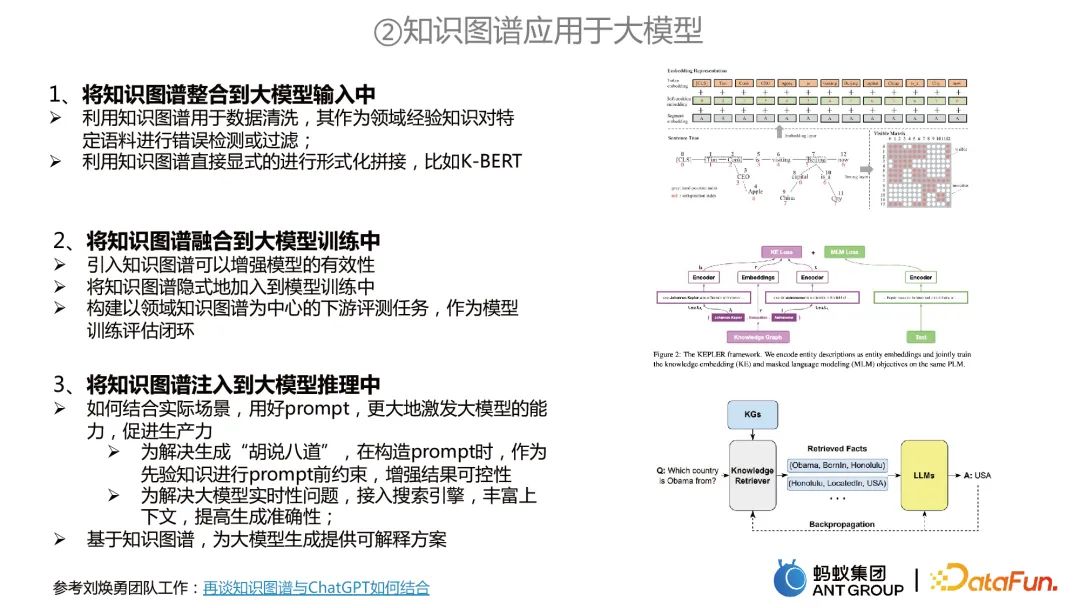 Integrieren Sie den Wissensgraphen in das Training großer Modelle. Beispielsweise können zwei Aufgaben gleichzeitig trainiert werden. Der Wissensgraph kann für Wissensdarstellungsaufgaben verwendet werden, und das große Modell kann für das Vortraining von MLM verwendet werden, und beide werden gemeinsam modelliert.
Integrieren Sie den Wissensgraphen in das Training großer Modelle. Beispielsweise können zwei Aufgaben gleichzeitig trainiert werden. Der Wissensgraph kann für Wissensdarstellungsaufgaben verwendet werden, und das große Modell kann für das Vortraining von MLM verwendet werden, und beide werden gemeinsam modelliert. 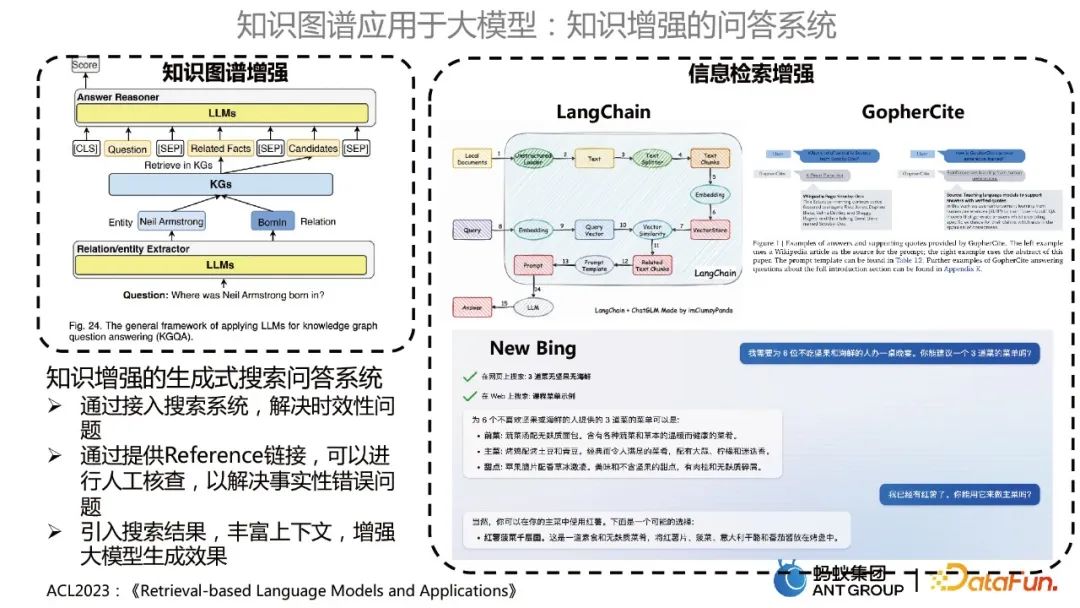

Das obige ist der detaillierte Inhalt vonJia Qianghuai: Konstruktion und Anwendung eines groß angelegten Wissensgraphen von Ameisen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
BERT ist ein vorab trainiertes Deep-Learning-Sprachmodell, das 2018 von Google vorgeschlagen wurde. Der vollständige Name lautet BidirektionalEncoderRepresentationsfromTransformers, der auf der Transformer-Architektur basiert und die Eigenschaften einer bidirektionalen Codierung aufweist. Im Vergleich zu herkömmlichen Einweg-Codierungsmodellen kann BERT bei der Textverarbeitung gleichzeitig Kontextinformationen berücksichtigen, sodass es bei Verarbeitungsaufgaben in natürlicher Sprache eine gute Leistung erbringt. Seine Bidirektionalität ermöglicht es BERT, die semantischen Beziehungen in Sätzen besser zu verstehen und dadurch die Ausdrucksfähigkeit des Modells zu verbessern. Durch Vorschulungs- und Feinabstimmungsmethoden kann BERT für verschiedene Aufgaben der Verarbeitung natürlicher Sprache verwendet werden, wie z. B. Stimmungsanalyse und Benennung
 Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Aktivierungsfunktionen spielen beim Deep Learning eine entscheidende Rolle. Sie können nichtlineare Eigenschaften in neuronale Netze einführen und es dem Netz ermöglichen, komplexe Eingabe-Ausgabe-Beziehungen besser zu lernen und zu simulieren. Die richtige Auswahl und Verwendung von Aktivierungsfunktionen hat einen wichtigen Einfluss auf die Leistung und Trainingsergebnisse neuronaler Netze. In diesem Artikel werden vier häufig verwendete Aktivierungsfunktionen vorgestellt: Sigmoid, Tanh, ReLU und Softmax. Beginnend mit der Einführung, den Verwendungsszenarien und den Vorteilen. Nachteile und Optimierungslösungen werden besprochen, um Ihnen ein umfassendes Verständnis der Aktivierungsfunktionen zu vermitteln. 1. Sigmoid-Funktion Einführung in die Sigmoid-Funktionsformel: Die Sigmoid-Funktion ist eine häufig verwendete nichtlineare Funktion, die jede reelle Zahl auf Werte zwischen 0 und 1 abbilden kann. Es wird normalerweise verwendet, um das zu vereinheitlichen
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latent Space Embedding (LatentSpaceEmbedding) ist der Prozess der Abbildung hochdimensionaler Daten auf niedrigdimensionalen Raum. Im Bereich des maschinellen Lernens und des tiefen Lernens handelt es sich bei der Einbettung latenter Räume normalerweise um ein neuronales Netzwerkmodell, das hochdimensionale Eingabedaten in einen Satz niedrigdimensionaler Vektordarstellungen abbildet. Dieser Satz von Vektoren wird oft als „latente Vektoren“ oder „latent“ bezeichnet Kodierungen". Der Zweck der Einbettung latenter Räume besteht darin, wichtige Merkmale in den Daten zu erfassen und sie in einer prägnanteren und verständlicheren Form darzustellen. Durch die Einbettung latenter Räume können wir Vorgänge wie das Visualisieren, Klassifizieren und Clustern von Daten im niedrigdimensionalen Raum durchführen, um die Daten besser zu verstehen und zu nutzen. Die Einbettung latenter Räume findet in vielen Bereichen breite Anwendung, z. B. bei der Bilderzeugung, der Merkmalsextraktion, der Dimensionsreduzierung usw. Die Einbettung des latenten Raums ist das Wichtigste
 Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
In der heutigen Welle rasanter technologischer Veränderungen sind künstliche Intelligenz (KI), maschinelles Lernen (ML) und Deep Learning (DL) wie helle Sterne und führen die neue Welle der Informationstechnologie an. Diese drei Wörter tauchen häufig in verschiedenen hochaktuellen Diskussionen und praktischen Anwendungen auf, aber für viele Entdecker, die neu auf diesem Gebiet sind, sind ihre spezifische Bedeutung und ihre internen Zusammenhänge möglicherweise noch immer rätselhaft. Schauen wir uns also zunächst dieses Bild an. Es ist ersichtlich, dass zwischen Deep Learning, maschinellem Lernen und künstlicher Intelligenz ein enger Zusammenhang und eine fortschreitende Beziehung besteht. Deep Learning ist ein spezifischer Bereich des maschinellen Lernens und des maschinellen Lernens
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Fast 20 Jahre sind vergangen, seit das Konzept des Deep Learning im Jahr 2006 vorgeschlagen wurde. Deep Learning hat als Revolution auf dem Gebiet der künstlichen Intelligenz viele einflussreiche Algorithmen hervorgebracht. Was sind Ihrer Meinung nach die zehn besten Algorithmen für Deep Learning? Im Folgenden sind meiner Meinung nach die besten Algorithmen für Deep Learning aufgeführt. Sie alle nehmen hinsichtlich Innovation, Anwendungswert und Einfluss eine wichtige Position ein. 1. Hintergrund des Deep Neural Network (DNN): Deep Neural Network (DNN), auch Multi-Layer-Perceptron genannt, ist der am weitesten verbreitete Deep-Learning-Algorithmus. Als er erstmals erfunden wurde, wurde er aufgrund des Engpasses bei der Rechenleistung in Frage gestellt Jahre, Rechenleistung, Der Durchbruch kam mit der Datenexplosion. DNN ist ein neuronales Netzwerkmodell, das mehrere verborgene Schichten enthält. In diesem Modell übergibt jede Schicht Eingaben an die nächste Schicht und
 Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Oct 23, 2023 pm 05:17 PM
Sehen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs an
Oct 23, 2023 pm 05:17 PM
1. Einleitung Die Vektorabfrage ist zu einem Kernbestandteil moderner Such- und Empfehlungssysteme geworden. Es ermöglicht einen effizienten Abfrageabgleich und Empfehlungen, indem es komplexe Objekte (wie Text, Bilder oder Töne) in numerische Vektoren umwandelt und Ähnlichkeitssuchen in mehrdimensionalen Räumen durchführt. Schauen Sie sich von den Grundlagen bis zur Praxis die Entwicklungsgeschichte von Elasticsearch Vector Retrieval_elasticsearch an. Als beliebte Open-Source-Suchmaschine hat die Entwicklung von Elasticsearch im Bereich Vektor Retrieval schon immer große Aufmerksamkeit erregt. In diesem Artikel wird die Entwicklungsgeschichte des Elasticsearch-Vektorabrufs untersucht, wobei der Schwerpunkt auf den Merkmalen und dem Fortschritt jeder Phase liegt. Wenn Sie sich an der Geschichte orientieren, ist es für jeden praktisch, eine umfassende Palette zum Abrufen von Elasticsearch-Vektoren einzurichten.
