
 Technologie-Peripheriegeräte
KI
Die H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt
Technologie-Peripheriegeräte
KI
Die H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt
Die H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt

Die „GPU-Armen“ sind dabei, sich aus ihrer misslichen Lage zu verabschieden!
Gerade hat NVIDIA eine Open-Source-Software namens TensorRT-LLM veröffentlicht, die den Inferenzprozess großer Sprachmodelle, die auf H100 laufen, beschleunigen kann

Also, wie oft kann es verbessert werden?
Nachdem TensorRT-LLM und seine Reihe von Optimierungsfunktionen (einschließlich In-Flight-Stapelverarbeitung) hinzugefügt wurden, erhöhte sich der Gesamtdurchsatz des Modells um das Achtfache.
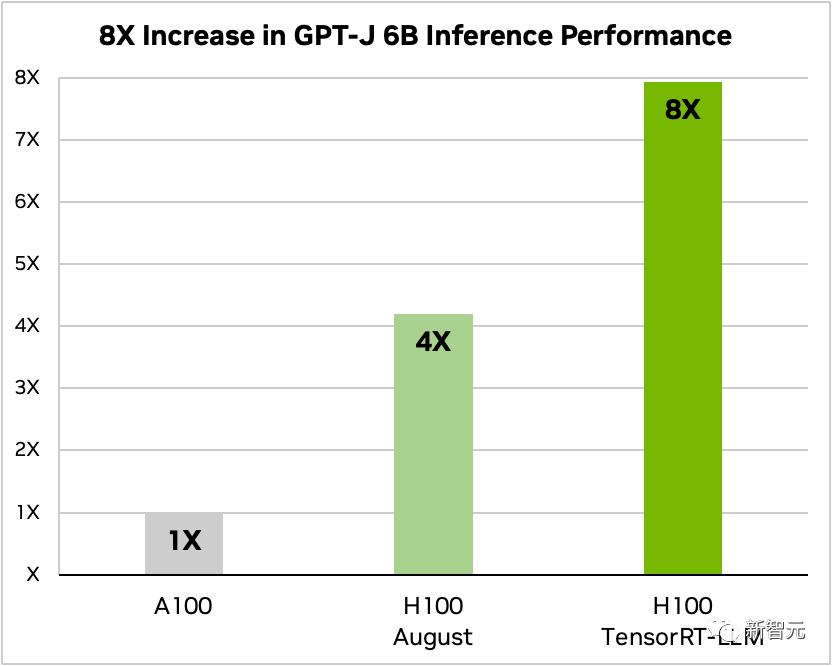
Vergleich von GPT-J-6B A100 und H100 mit und ohne TensorRT-LLM
Am Beispiel von Llama 2 kann TensorRT-LLM außerdem die Inferenzleistung im Vergleich zur unabhängigen Verwendung von A100 verbessern 4,6-fache Verbesserung
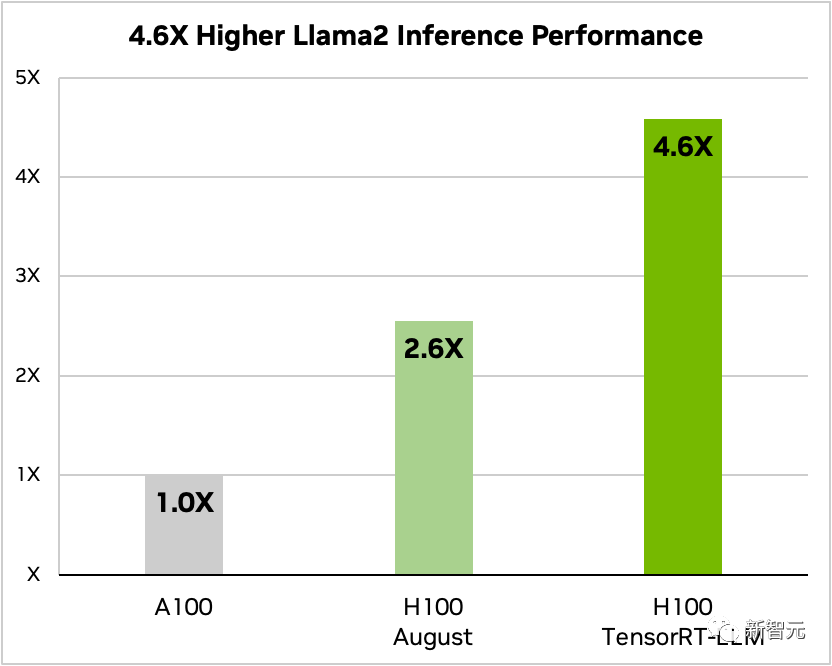
Vergleich von Llama 2 70B, A100 und H100 mit und ohne TensorRT-LLM
Netizens sagten, dass der Super-H100 in Kombination mit TensorRT-LLM zweifellos ist Es wird den Strom komplett verändern Situation der Inferenz großer Sprachmodelle!

TensorRT-LLM: Großes Modellinferenzbeschleunigungsartefakt
Aufgrund der großen Parameterskala großer Modelle sind derzeit die Schwierigkeit und die Kosten für „Bereitstellung und Inferenz“ immer hoch.
Das von NVIDIA entwickelte TensorRT-LLM zielt darauf ab, den Durchsatz von LLM deutlich zu verbessern und die Kosten durch die GPU zu senken.

Konkret optimiert TensorRT-LLM den Deep-Learning-Compiler und den FasterTransformer-Kernel von TensorRT sowie die Vor- und Nachverarbeitung , und Multi-GPU/Multi-Node-Kommunikation sind in einer einfachen Open-Source-Python-API gekapselt
NVIDIA hat FasterTransformer weiter verbessert, um es zu einer Produktionslösung zu machen.
Es ist ersichtlich, dass TensorRT-LLM eine benutzerfreundliche, quelloffene und modulare Python-Anwendungsprogrammierschnittstelle bietet.
Programmierer, die keine tiefgreifenden Kenntnisse in C++ oder CUDA benötigen, können verschiedene umfangreiche Sprachmodelle bereitstellen, ausführen und debuggen und profitieren von hervorragender Leistung und schneller Anpassung

Laut dem offiziellen Blog von NVIDIA TensorRT-LLM verwendet vier Methoden, um die LLM-Inferenzleistung auf Nvidia-GPUs zu verbessern.
Zunächst wird TensorRT-LLM für die aktuellen über 10 großen Modelle eingeführt, sodass Entwickler es sofort ausführen können.
Zweitens ermöglicht TensorRT-LLM als Open-Source-Softwarebibliothek LLM, Inferenzen auf mehreren GPUs und mehreren GPU-Servern gleichzeitig durchzuführen.
Diese Server sind über die NVLink- bzw. InfiniBand-Verbindungen von NVIDIA verbunden.
Der dritte Punkt betrifft die „In-Machine-Batch-Verarbeitung“, eine neue Planungstechnologie, die es Aufgaben verschiedener Modelle ermöglicht, unabhängig von anderen Aufgaben in die GPU einzutreten und diese zu verlassen.
Schließlich wurde TensorRT-LLM verwendet Optimiert können Sie die H100 Transformer Engine verwenden, um die Speichernutzung und Latenz während der Modellinferenz zu reduzieren.
Lassen Sie uns einen detaillierten Blick darauf werfen, wie TensorRT-LLM die Modellleistung verbessert.
Unterstützt ein reichhaltiges LLM-Ökosystem : Die größten und fortschrittlichsten Sprachmodelle, wie z. B. Llama 2-70B von Meta, erfordern die Zusammenarbeit mehrerer GPUs, um Antworten in Echtzeit bereitzustellen KI-Modell erstellen und in mehrere Teile zerlegen, dann die Ausführung zwischen GPUs koordinieren

TensorRT-LLM verwendet Tensor-Parallel-Technologie, um die Gewichtsmatrix auf jedes Gerät zu verteilen, wodurch der Prozess vereinfacht und eine effiziente Inferenz im Maßstab ermöglicht wird.
Jedes Modell kann auf mehreren Geräten ausgeführt werden, die über NVLink verbunden sind. Läuft parallel auf mehrere GPUs und mehrere Server ohne Entwicklereingriff oder Modelländerungen.
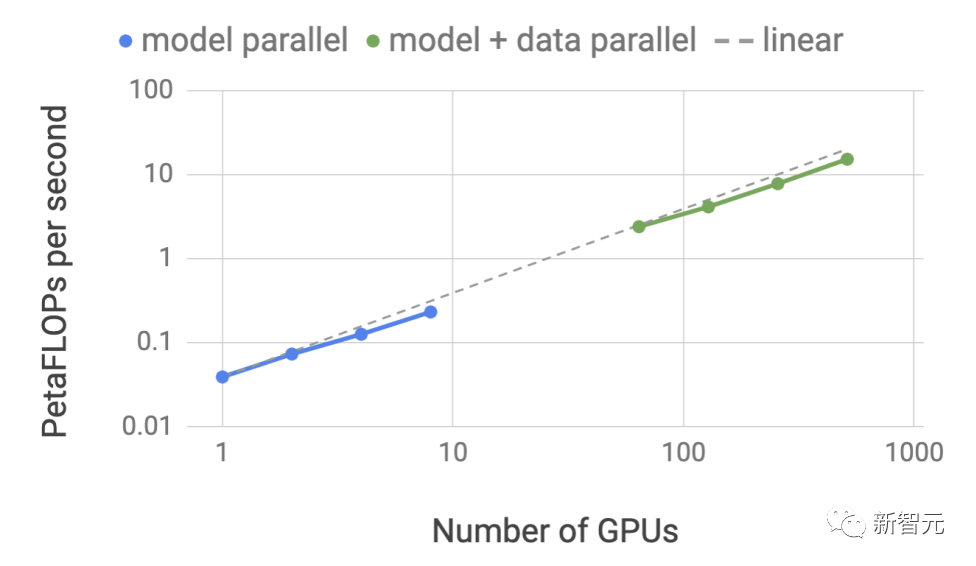
Mit der Einführung neuer Modelle und Modellarchitekturen können Entwickler den neuesten NVIDIA AI-Kernel (Kernal) Open Source in TensorRT-LLM verwenden, um Modelle zu optimieren
Was neu geschrieben werden muss, ist: Unterstützter Kernal Fusion umfasst die neueste FlashAttention-Implementierung sowie maskierte Multi-Head-Aufmerksamkeit für die Kontext- und Generierungsphasen der GPT-Modellausführung usw.
Darüber hinaus enthält TensorRT-LLM auch viele der derzeit beliebten großen Sprachmodelle Fully optimierte, betriebsbereite Version.
Zu diesen Modellen gehören Meta Llama 2, OpenAI GPT-2 und GPT-3, Falcon, Mosaic MPT, BLOOM und mehr als zehn weitere. Alle diese Modelle können über die benutzerfreundliche TensorRT-LLM-Python-API aufgerufen werden
Diese Funktionen können Entwicklern dabei helfen, benutzerdefinierte große Sprachmodelle schneller und genauer zu erstellen, um den unterschiedlichen Anforderungen verschiedener Branchen gerecht zu werden.
Stapelverarbeitung während des Flugs
Heutzutage sind große Sprachmodelle äußerst vielseitig.
Ein Modell kann gleichzeitig für mehrere scheinbar unterschiedliche Aufgaben verwendet werden – von einfachen Fragen und Antworten in einem Chatbot über die Zusammenfassung von Dokumenten bis hin zur Generierung langer Codeblöcke. Die Arbeitslasten sind hochdynamisch und die Ausgabegrößen müssen den Anforderungen für Aufgaben von erfüllt werden verschiedene Größenordnungen.
Die Vielfalt der Aufgaben kann es schwierig machen, Anfragen effektiv zu stapeln und eine effiziente parallele Ausführung durchzuführen, was möglicherweise dazu führt, dass einige Anfragen früher abgeschlossen werden als andere.

Um diese dynamischen Belastungen zu bewältigen, enthält TensorRT-LLM eine optimierte Planungstechnologie namens „In-flight Batching“.
Das Kernprinzip großer Sprachmodelle besteht darin, dass der gesamte Textgenerierungsprozess durch mehrere Iterationen des Modells erreicht werden kann.
Bei der Stapelverarbeitung während des Flugs wird die TensorRT-LLM-Laufzeit sofort aus dem Stapel freigegeben, wenn Es wird nicht darauf gewartet, dass der gesamte Stapel abgeschlossen ist, bevor mit dem nächsten Satz von Anforderungen fortgefahren wird, sondern die abgeschlossene Sequenz.
Während der Ausführung einer neuen Anfrage werden andere Anfragen aus dem vorherigen Stapel, die noch nicht abgeschlossen wurden, noch verarbeitet.
Verbesserte GPU-Auslastung durch Batching in der Maschine und zusätzliche Optimierungen auf Kernel-Ebene, was zu mindestens dem doppelten Durchsatz realer Anforderungsbenchmarks für LLM auf H100 führt
Verwendung der H100-Transformer-Engine von FP 8
TensorRT- LLM bietet außerdem eine Funktion namens H100 Transformer Engine, die den Speicherverbrauch und die Latenz während großer Modellinferenzen effektiv reduzieren kann.
Da LLM Milliarden von Modellgewichten und Aktivierungsfunktionen enthält, wird es normalerweise mit FP16- oder BF16-Werten trainiert und dargestellt, die jeweils 16 Bit Speicher belegen.
Zur Inferenzzeit können die meisten Modelle jedoch mithilfe von Quantisierungstechniken, wie z. B. 8-Bit- oder sogar 4-Bit-Ganzzahlen (INT8 oder INT4), effizient und mit geringerer Präzision dargestellt werden.
Quantisierung ist der Prozess der Reduzierung von Modellgewichten und Aktivierungsgenauigkeit ohne Einbußen bei der Genauigkeit. Die Verwendung einer geringeren Präzision bedeutet, dass jeder Parameter kleiner ist und das Modell weniger Platz im GPU-Speicher beansprucht.

Auf diese Weise können Sie dieselbe Hardware verwenden, um größere Modelle abzuleiten, und gleichzeitig den Zeitverbrauch für Speicheroperationen während des Ausführungsprozesses reduzieren
Durch die H100 Transformer Engine-Technologie in Kombination mit TensorRT-LLM The H100 GPU ermöglicht es Benutzern, Modellgewichte einfach in das neue FP8-Format zu konvertieren und Modelle automatisch zu kompilieren, um die Vorteile optimierter FP8-Kerne zu nutzen.
Und dieser Vorgang erfordert keine Codierung! Das von H100 eingeführte FP8-Datenformat ermöglicht Entwicklern die Quantifizierung ihrer Modelle und eine drastische Reduzierung des Speicherverbrauchs, ohne die Modellgenauigkeit zu beeinträchtigen.
Im Vergleich zu anderen Datenformaten wie INT8 oder INT4 behält die FP8-Quantisierung eine höhere Präzision bei, erzielt gleichzeitig die schnellste Leistung und ist am bequemsten zu implementieren. Im Vergleich zu anderen Datenformaten wie INT8 oder INT4 behält die FP8-Quantisierung eine höhere Genauigkeit bei, erzielt gleichzeitig die schnellste Leistung und ist am bequemsten zu implementieren
So erhalten Sie TensorRT-LLM
Obwohl TensorRT-LLM noch nicht offiziell veröffentlicht ist, aber Benutzer können es jetzt im Voraus erleben. Der Anwendungslink lautet wie folgt: TensorRT-LLM wurde schnell in das NVIDIA NeMo-Framework integriert.
Dieses Framework ist Teil des kürzlich von NVIDIA eingeführten AI Enterprise und bietet Unternehmenskunden eine sichere, stabile und hochverwaltbare KI-Softwareplattform auf Unternehmensebene.
Entwickler und Forscher können das NeMo-Framework auf NVIDIA NGC nutzen oder Projekt auf GitHub, um auf TensorRT-LLM zuzugreifen
Es ist jedoch zu beachten, dass sich Benutzer für das NVIDIA Developer Program registrieren müssen, um sich für die Early-Access-Version zu bewerben.
Heiße Diskussion unter Internetnutzern
Benutzer auf Reddit hatten eine hitzige Diskussion über die Veröffentlichung von TensorRT-LLMMan kann sich kaum vorstellen, wie sehr sich der Effekt nach der Optimierung der Hardware speziell für LLM verbessern wird.
Aber einige Internetnutzer glauben, dass der Sinn dieser Sache darin besteht, Lao Huang dabei zu helfen, mehr H100 zu verkaufen.
Einige Internetnutzer haben unterschiedliche Meinungen dazu. Sie glauben, dass Tensor RT auch für Benutzer hilfreich ist, die Deep Learning lokal einsetzen. Solange Sie über eine RTX-GPU verfügen, können Sie in Zukunft möglicherweise auch von ähnlichen Produkten profitieren. und vielleicht ist sogar Hardware entstanden, die speziell für LLM entwickelt wurde, um dessen Leistung zu verbessern. Diese Situation ist in vielen gängigen Anwendungen aufgetreten, und LLM ist keine Ausnahme

Das obige ist der detaillierte Inhalt vonDie H100-Argumentation ist um das Achtfache gestiegen! NVIDIA hat offiziell Open-Source-TensorRT-LLM angekündigt, das mehr als 10 Modelle unterstützt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 „AI Factory' wird die Neugestaltung des gesamten Software-Stacks vorantreiben, und NVIDIA stellt Llama3-NIM-Container für die Bereitstellung durch Benutzer bereit
Jun 08, 2024 pm 07:25 PM
„AI Factory' wird die Neugestaltung des gesamten Software-Stacks vorantreiben, und NVIDIA stellt Llama3-NIM-Container für die Bereitstellung durch Benutzer bereit
Jun 08, 2024 pm 07:25 PM
Laut Nachrichten dieser Website vom 2. Juni stellte Huang Renxun bei der laufenden Keynote-Rede von Huang Renxun 2024 Taipei Computex vor, dass generative künstliche Intelligenz die Neugestaltung des gesamten Software-Stacks fördern wird, und demonstrierte seine cloudnativen Mikrodienste NIM (Nvidia Inference Microservices). . Nvidia glaubt, dass die „KI-Fabrik“ eine neue industrielle Revolution auslösen wird: Am Beispiel der von Microsoft vorangetriebenen Softwareindustrie glaubt Huang Renxun, dass generative künstliche Intelligenz deren Umgestaltung im gesamten Stack vorantreiben wird. Um die Bereitstellung von KI-Diensten durch Unternehmen jeder Größe zu erleichtern, hat NVIDIA im März dieses Jahres die cloudnativen Mikrodienste NIM (Nvidia Inference Microservices) eingeführt. NIM+ ist eine Suite cloudnativer Mikroservices, die darauf optimiert sind, die Markteinführungszeit zu verkürzen
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
