
 Technologie-Peripheriegeräte
KI
Trainieren Sie schnell kleine professionelle Models: Nur 1 Befehl, 5 $ und 20 Minuten, probieren Sie Prompt2Model aus!
Technologie-Peripheriegeräte
KI
Trainieren Sie schnell kleine professionelle Models: Nur 1 Befehl, 5 $ und 20 Minuten, probieren Sie Prompt2Model aus!
Trainieren Sie schnell kleine professionelle Models: Nur 1 Befehl, 5 $ und 20 Minuten, probieren Sie Prompt2Model aus!

Large-Scale Language Models (LLM) ermöglichen Benutzern den Aufbau leistungsstarker Systeme zur Verarbeitung natürlicher Sprache durch Hinweise und kontextbezogenes Lernen. Aus einer anderen Perspektive zeigt LLM jedoch gewisse Rückschritte bei einigen spezifischen Aufgaben der Verarbeitung natürlicher Sprache: Die Bereitstellung dieser Modelle erfordert viele Rechenressourcen, und die Interaktion mit den Modellen über APIs kann potenzielle Datenschutzprobleme aufwerfen Um diese Probleme zu lösen, haben Forscher der Carnegie Mellon University (CMU) und der Tsinghua University gemeinsam das Prompt2Model-Framework ins Leben gerufen. Das Ziel dieses Frameworks besteht darin, LLM-basierte Methoden zur Datengenerierung und -abfrage zu kombinieren, um die oben genannten Herausforderungen zu bewältigen. Mithilfe des Prompt2Model-Frameworks müssen Benutzer nur die gleichen Eingabeaufforderungen wie bei LLM bereitstellen, um automatisch Daten zu sammeln und kleine Spezialmodelle, die für bestimmte Aufgaben geeignet sind, effizient zu trainieren. Sie nutzten eine kleine Anzahl von Beispielaufforderungen als Eingabe und gaben nur 5 US-Dollar für die Datenerfassung und 20 Minuten Training aus. Die Leistung des über das Prompt2Model-Framework generierten Modells ist 20 % höher als die des leistungsstarken LLM-Modells gpt-3.5-turbo. Gleichzeitig ist die Größe des Modells um das 700-fache geschrumpft. Die Forscher überprüften außerdem die Auswirkungen dieser Daten auf die Modellleistung in realen Szenarien und ermöglichten es Modellentwicklern, die Zuverlässigkeit des Modells vor der Bereitstellung abzuschätzen. Das Framework wurde in Open-Source-Form bereitgestellt:
GitHub-Repository-Adresse des Frameworks: https://github.com/neulab/prompt2model 
Video-Link zur Framework-Demonstration: youtu. be/LYYQ_EhGd -Q
- Link zum Framework-bezogenen Papier: https://arxiv.org/abs/2308.12261
- Hintergrund
- Der Aufbau eines Systems für eine bestimmte Aufgabe der Verarbeitung natürlicher Sprache ist normalerweise recht komplex. Der Ersteller des Systems muss den Umfang der Aufgabe klar definieren, einen bestimmten Datensatz erhalten, eine geeignete Modellarchitektur auswählen, das Modell trainieren und bewerten und es dann für die praktische Anwendung bereitstellen
Large-Scale Language Model ( LLM) wie GPT-3 bietet eine einfachere Lösung für diesen Prozess. Benutzer müssen lediglich Aufgabenanweisungen und einige Beispiele bereitstellen, und LLM kann eine entsprechende Textausgabe generieren. Das Generieren von Text aus Hinweisen kann jedoch rechenintensiv sein und die Verwendung von Hinweisen ist weniger stabil als ein speziell trainiertes Modell. Darüber hinaus wird die Benutzerfreundlichkeit von LLM auch durch Kosten, Geschwindigkeit und Datenschutz eingeschränkt. Um diese Probleme zu lösen, haben Forscher das Prompt2Model-Framework entwickelt. Dieses Framework kombiniert LLM-basierte Datengenerierungs- und -abruftechniken, um die oben genannten Einschränkungen zu überwinden. Das System extrahiert zunächst wichtige Informationen aus den Eingabeaufforderungsinformationen, generiert und ruft dann Trainingsdaten ab und generiert schließlich ein spezielles Modell, das zur Bereitstellung bereit ist. Das Prompt2Model-Framework führt automatisch die folgenden Kernschritte aus: 1. Datenvorverarbeitung: Bereinigen und standardisieren Sie die Eingabedaten, um sicherzustellen, dass sie für das Modelltraining geeignet sind. 2. Modellauswahl: Wählen Sie die geeignete Modellarchitektur und Parameter entsprechend den Anforderungen der Aufgabe aus. 3. Modelltraining: Verwenden Sie die vorverarbeiteten Daten, um das ausgewählte Modell zu trainieren und die Leistung des Modells zu optimieren. 4. Modellbewertung: Leistungsbewertung des trainierten Modells anhand von Bewertungsindikatoren, um seine Leistung bei bestimmten Aufgaben zu bestimmen. 5. Modelloptimierung: Optimieren Sie das Modell basierend auf den Bewertungsergebnissen, um seine Leistung weiter zu verbessern. 6. Modellbereitstellung: Stellen Sie das trainierte Modell in der tatsächlichen Anwendungsumgebung bereit, um Vorhersage- oder Inferenzfunktionen zu erreichen. Durch die Automatisierung dieser Kernschritte kann das Prompt2Model-Framework Benutzern dabei helfen, schnell leistungsstarke Modelle zur Verarbeitung natürlicher Sprache zu erstellen und bereitzustellen.
Abruf von Datensätzen und Modellen: Sammeln Sie relevante Datensätze und vorab trainierte Modelle.
Datensatzgenerierung: Verwenden Sie LLM, um pseudogekennzeichnete Datensätze zu erstellen.
Modell-Feinabstimmung: Feinabstimmung des Modells durch Mischen abgerufener und generierter Daten.
Modelltests: Testen Sie das Modell anhand eines Testdatensatzes und eines vom Benutzer bereitgestellten realen Datensatzes.
- Durch empirische Auswertungen zu mehreren verschiedenen Aufgaben haben wir festgestellt, dass die Kosten von Prompt2Model erheblich reduziert werden und die Größe des Modells ebenfalls erheblich reduziert wird, die Leistung jedoch die von gpt-3.5-turbo übertrifft. Das Prompt2Model-Framework kann nicht nur als Werkzeug zum effizienten Aufbau natürlicher Sprachverarbeitungssysteme verwendet werden, sondern auch als Plattform zur Erforschung der Modellintegrationstrainingstechnologie
Framework

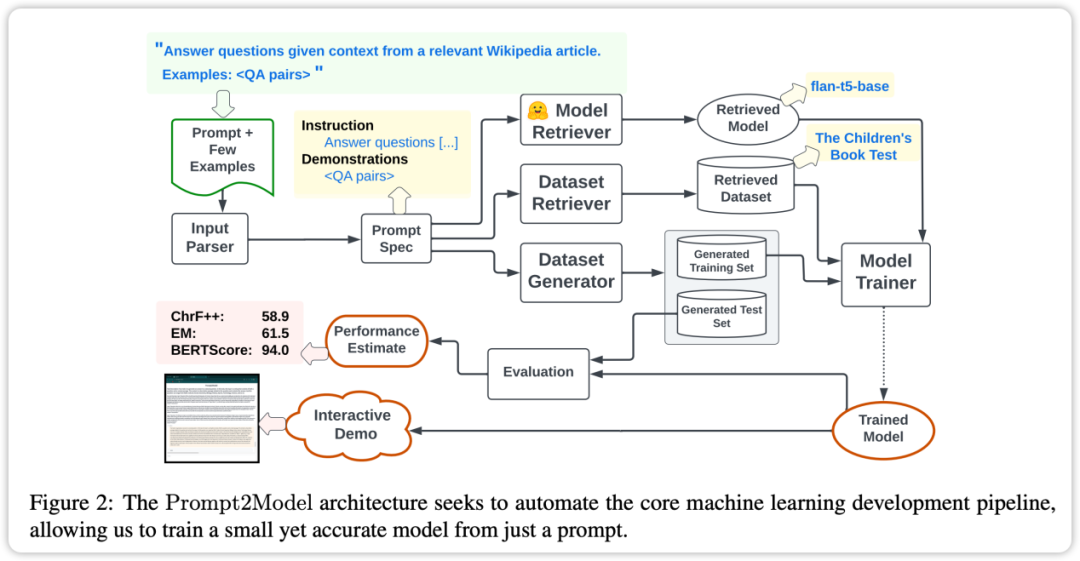
Das Kernmerkmal des Promt2Model-Frameworks ist ein hoher Automatisierungsgrad. Der Prozess umfasst die Datenerfassung, das Modelltraining, die Bewertung und den Einsatz, wie in der Abbildung oben dargestellt. Unter diesen spielt das automatisierte Datenerfassungssystem eine Schlüsselrolle, indem es durch Datensatzabruf und LLM-basierte Datengenerierung Daten erhält, die eng mit den Benutzeranforderungen verknüpft sind. Als nächstes wird das vorab trainierte Modell abgerufen und anhand des erfassten Datensatzes verfeinert. Abschließend wird das trainierte Modell anhand des Testsatzes ausgewertet und eine Web-Benutzeroberfläche (UI) für die Interaktion mit dem Modell erstellt Der Vorteil besteht darin, dass Benutzer mithilfe der Eingabeaufforderung als Treiber die erforderlichen Aufgaben direkt beschreiben können, ohne auf die spezifischen Implementierungsdetails des maschinellen Lernens einzugehen.
Automatische Datenerfassung: Das Framework verwendet Technologie zum Abrufen und Generieren von Datensätzen, um Daten zu erhalten, die den Aufgaben des Benutzers in hohem Maße entsprechen, und erstellt so den für das Training erforderlichen Datensatz.
- Vorab trainierte Modelle: Das Framework nutzt vorab trainierte Modelle und optimiert diese, wodurch eine Menge Trainingskosten und Zeit gespart werden.
- Effektbewertung: Prompt2Model unterstützt Modelltests und -bewertungen anhand tatsächlicher Datensätze und ermöglicht so vorläufige Vorhersagen und Leistungsbewertungen vor der Bereitstellung des Modells, wodurch die Zuverlässigkeit des Modells verbessert wird.
- Das Prompt2Model-Framework verfügt über die folgenden Eigenschaften und ist damit ein leistungsstarkes Tool, das den Konstruktionsprozess von Systemen zur Verarbeitung natürlicher Sprache effizient abschließen kann und erweiterte Funktionen wie automatische Datenerfassung, Modellbewertung und Benutzerinteraktionsschnittstellenerstellung bietet
- Experimente und Ergebnisse
Um die Leistung des Prompt2Model-Systems zu bewerten, wählte der Forscher im experimentellen Design drei verschiedene Aufgaben aus:
Machine Reading QA: Verwendung von SQuAD als praktischer Bewertungsdatensatz.
Japanischer NL-to-Code: Verwendung von MCoNaLa als eigentlichem Bewertungsdatensatz.
- Normalisierung des zeitlichen Ausdrucks: Verwenden Sie den zeitlichen Datensatz als eigentlichen Bewertungsdatensatz.
- Darüber hinaus verwendeten die Forscher zum Vergleich auch GPT-3.5-Turbo als Basismodell. Die experimentellen Ergebnisse führen zu folgenden Schlussfolgerungen:
- Bei allen Aufgaben außer der Codegenerierungsaufgabe ist das vom Prompt2Model-System generierte Modell deutlich besser als das Benchmark-Modell GPT-3.5-turbo, obwohl die generierte Modellparameterskala dies ist viel kleiner als GPT-3.5-turbo.
Durch Mischen des Abrufdatensatzes mit dem generierten Datensatz für das Training können Sie Ergebnisse erzielen, die mit denen direkt beim tatsächlichen Datensatztraining vergleichbar sind. Dies bestätigt, dass das Prompt2Model-Framework die Kosten für manuelle Anmerkungen erheblich reduzieren kann.
- Der vom Datengenerator generierte Testdatensatz kann die Leistung verschiedener Modelle anhand tatsächlicher Datensätze effektiv unterscheiden. Dies weist darauf hin, dass die generierten Daten von hoher Qualität sind und beim Modelltraining eine ausreichende Wirksamkeit aufweisen.
- Bei der Konvertierungsaufgabe von Japanisch in Code schneidet das Prompt2Model-System schlechter ab als GPT-3.5-turbo.
- Dies kann durch die geringe Qualität des generierten Datensatzes und das Fehlen geeigneter vorab trainierter Modelle verursacht werden
- Zusammenfassend lässt sich sagen, dass das Prompt2Model-System bei mehreren Aufgaben erfolgreich kleine Modelle hoher Qualität generiert hat, was die Reduzierung erheblich reduziert die Notwendigkeit einer manuellen Annotation von Daten. Bei einigen Aufgaben sind jedoch noch weitere Verbesserungen erforderlich. Die Einführung dieser Technologie verringert die Schwierigkeit beim Erstellen maßgeschneiderter Modelle zur Verarbeitung natürlicher Sprache erheblich und erweitert den Anwendungsbereich der NLP-Technologie weiter
Die Ergebnisse des Verifizierungsexperiments zeigen, dass die Größe des vom Prompt2Model-Framework generierten Modells im Vergleich zum größeren Sprachmodell erheblich reduziert ist und bei mehreren Aufgaben eine bessere Leistung als GPT-3.5-turbo und andere Modelle erbringt. Gleichzeitig hat sich der von diesem Framework generierte Bewertungsdatensatz auch als wirksam bei der Bewertung der Leistung verschiedener Modelle anhand realer Datensätze erwiesen. Dies stellt einen wichtigen Wert für die Steuerung der endgültigen Bereitstellung des Modells dar. Das Prompt2Model-Framework bietet Branchen und Benutzern eine kostengünstige und benutzerfreundliche Möglichkeit, NLP-Modelle zu erhalten, die spezifische Anforderungen erfüllen. Dies ist von großer Bedeutung für die Förderung der breiten Anwendung der NLP-Technologie. Zukünftige Arbeiten werden weiterhin der weiteren Optimierung der Leistung des Frameworks gewidmet sein
In der Reihenfolge der Artikel sind die Autoren dieses Artikels wie folgt: Umgeschriebener Inhalt: Gemäß der Reihenfolge der Artikel sind die Autoren dieses Artikels wie folgt:
Vijay Viswanathan: http://www.cs.cmu.edu/~vijayv/
Zhao Chenyang: https ://zhaochenyang20.github.io/Eren_Chenyang_Zhao/
Amanda Bertsch: https://www.cs.cmu.edu/~abertsch/ Amanda Belch: https://www.cs.cmu.edu/~abertsch/
Wu Tongshuang: https://www.cs.cmu.edu/~sherryw/
Graham · Newbig: http: //www.phontron.com/
Das obige ist der detaillierte Inhalt vonTrainieren Sie schnell kleine professionelle Models: Nur 1 Befehl, 5 $ und 20 Minuten, probieren Sie Prompt2Model aus!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Ja, mit der Anweisung Löschen kann eine SQL -Tabelle gelöscht werden. TABLE_NAME ERSETZEN AUS DER NAME DER TABELLE, DIE DELDET.
 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Wie geht es mit Redis -Speicherfragmentierung um?
Apr 10, 2025 pm 02:24 PM
Redis -Gedächtnisfragmentierung bezieht sich auf die Existenz kleiner freier Bereiche in dem zugewiesenen Gedächtnis, die nicht neu zugewiesen werden können. Zu den Bewältigungsstrategien gehören: Neustart von Redis: Der Gedächtnis vollständig löschen, aber den Service unterbrechen. Datenstrukturen optimieren: Verwenden Sie eine Struktur, die für Redis besser geeignet ist, um die Anzahl der Speicherzuweisungen und -freisetzungen zu verringern. Konfigurationsparameter anpassen: Verwenden Sie die Richtlinie, um die kürzlich verwendeten Schlüsselwertpaare zu beseitigen. Verwenden Sie den Persistenzmechanismus: Daten regelmäßig sichern und Redis neu starten, um Fragmente zu beseitigen. Überwachen Sie die Speicherverwendung: Entdecken Sie die Probleme rechtzeitig und ergreifen Sie Maßnahmen.
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Eine effektive Überwachung von Redis -Datenbanken ist entscheidend für die Aufrechterhaltung einer optimalen Leistung, die Identifizierung potenzieller Engpässe und die Gewährleistung der Zuverlässigkeit des Gesamtsystems. Redis Exporteur Service ist ein leistungsstarkes Dienstprogramm zur Überwachung von Redis -Datenbanken mithilfe von Prometheus. In diesem Tutorial führt Sie die vollständige Setup und Konfiguration des Redis -Exporteur -Dienstes, um sicherzustellen, dass Sie nahtlos Überwachungslösungen erstellen. Durch das Studium dieses Tutorials erhalten Sie voll funktionsfähige Überwachungseinstellungen
 Was sind die Redis -Speicherkonfigurationsparameter?
Apr 10, 2025 pm 02:03 PM
Was sind die Redis -Speicherkonfigurationsparameter?
Apr 10, 2025 pm 02:03 PM
** Der Kernparameter der Redis -Speicherkonfiguration ist MaxMemory, der die Menge an Speicher einschränkt, die Redis verwenden kann. Wenn diese Grenze überschritten wird, führt Redis eine Eliminierungsstrategie gemäß MaxMemory-Policy durch, einschließlich: Noeviction (direkt abgelehnt), Allkeys-LRU/Volatile-LRU (eliminiert von LRU), Allkeys-Random/Volatile-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random-Random (eliminiert) und volatile TTL (eliminierte Zeit). Andere verwandte Parameter umfassen MaxMemory-Samples (LRU-Probenmenge), RDB-Kompression
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
