
 Technologie-Peripheriegeräte
KI
Neuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |
Technologie-Peripheriegeräte
KI
Neuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |
Neuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |

Die Erzeugung natürlicher und kontrollierbarer Human Scene Interaction (HSI) spielt in vielen Bereichen wie der Erstellung von Virtual Reality/Augmented Reality (VR/AR)-Inhalten und der auf den Menschen ausgerichteten künstlichen Intelligenz eine wichtige Rolle.
Bestehende Methoden weisen jedoch eine begrenzte Steuerbarkeit, begrenzte Interaktionstypen und unnatürlich erzeugte Ergebnisse auf, was ihre Anwendungsszenarien im wirklichen Leben erheblich einschränkt.
In der Forschung von ICCV 2023 haben die Universitäten Tianjin und Tsinghua ein Team gebildet mit einer Lösung namens Narrator, um dieses Problem zu untersuchen. Diese Lösung konzentriert sich auf die herausfordernde Aufgabe, auf natürliche und kontrollierte Weise realistische und vielfältige Interaktionen zwischen Mensch und Szene aus Textbeschreibungen zu generieren. likun/projects/Narrator
Der umgeschriebene Inhalt lautet: Code-Link: https://github.com/HaibiaoXuan/Narrator
 Aus der Perspektive der menschlichen Kognition sollte das generative Modell idealerweise in der Lage sein, räumliche Beziehungen richtig zu beurteilen und erkunden Sie die Freiheitsgrade von Interaktionen.
Aus der Perspektive der menschlichen Kognition sollte das generative Modell idealerweise in der Lage sein, räumliche Beziehungen richtig zu beurteilen und erkunden Sie die Freiheitsgrade von Interaktionen.
Der umgeschriebene Inhalt lautet wie folgt: Gemäß Abbildung 1 kann der Erzähler auf natürliche und kontrollierte Weise semantisch konsistente und physikalisch sinnvolle Mensch-Szenen-Interaktionen erzeugen, die auf die folgenden Situationen anwendbar sind: (a) durch Raumbeziehung -Geführte Interaktion, (b) Interaktion, die durch mehrere Aktionen gesteuert wird, (c) Interaktion zwischen mehreren Personen und (d) Interaktion zwischen Person und Szene, die die oben genannten Interaktionstypen kombiniert
Konkret können räumliche Beziehungen verwendet werden, um die Wechselbeziehungen zwischen zu beschreiben verschiedene Objekte in einer Szene oder einem lokalen Bereich. Interaktive Aktionen werden durch den Zustand atomarer Körperteile spezifiziert, wie z. B. die Füße einer Person auf dem Boden, sich auf den Oberkörper stützen, mit der rechten Hand klopfen, den Kopf senken usw.
Mit diesem Ausgangspunkt wird die Der Autor verwendet Szenendiagramme, um räumliche Beziehungen darzustellen, und schlägt vor, dass er einen JGLSG-Mechanismus (Joint Global and Local Scene Graph) verwendet, um eine globale Positionserkennung für die nachfolgende Generation bereitzustellen. 
Abbildung 2 Übersicht über das Narrator-Framework
Wie in Abbildung 2 gezeigt, verwendet diese Methode einen auf Transformer basierenden Conditional Variational Autoencoder (cVAE), der hauptsächlich die folgenden Mehrere umfasst Teile:
Im Vergleich zu bestehenden Forschungsergebnissen entwerfen wir einen gemeinsamen Mechanismus für globale und lokale Szenendiagramme, um über komplexe räumliche Beziehungen nachzudenken und ein globales Positionierungsbewusstsein zu erreichen. 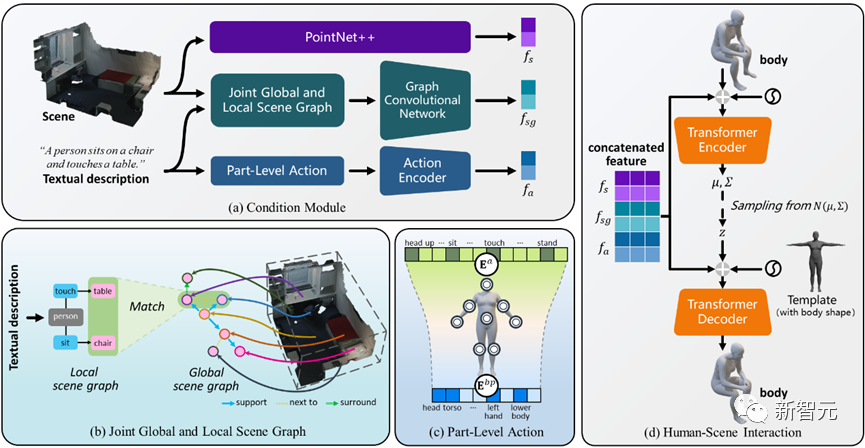
4) Erweitert sich weiter auf die Generierung von Mehrpersonen-Interaktionen und fördert letztendlich den ersten Schritt in der Mehrpersonen-Szeneninteraktion.
Kombinierter globaler und lokaler Szenendiagrammmechanismus
Die Begründung räumlicher Beziehungen kann dem Modell szenenspezifische Hinweise liefern, was eine wichtige Rolle bei der Erzielung einer natürlichen Steuerbarkeit der Interaktion zwischen Mensch und Szene spielt.
Um dieses Ziel zu erreichen, schlägt der Autor einen gemeinsamen Mechanismus für globale und lokale Szenendiagramme vor, der durch die folgenden drei Schritte implementiert wird:
1. Globale Szenendiagrammgenerierung: Verwenden Sie bei gegebener Szene vorab das Training Das Szenendiagrammmodell generiert ein globales Szenendiagramm, d. h. 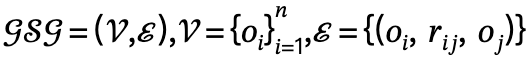 , wobei
, wobei 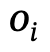 ,
, 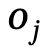 Objekte mit Kategoriebezeichnungen sind,
Objekte mit Kategoriebezeichnungen sind, 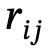 die Beziehung zwischen
die Beziehung zwischen 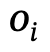 und
und 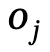 ist, n die Anzahl der Objekte ist, m die Anzahl der Beziehungen ist;
ist, n die Anzahl der Objekte ist, m die Anzahl der Beziehungen ist;
, wobei
das Triplett von Subjekt-Prädikat-Objekt definiert;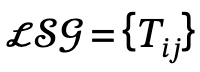
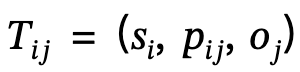
Der Autor nutzt geometrische und physikalische Einschränkungen für die szenenbezogene Optimierung, um die Generierungsergebnisse zu verbessern. Während des gesamten Optimierungsprozesses stellt diese Methode sicher, dass die generierte Pose nicht abweicht, während sie gleichzeitig den Kontakt mit der Szene fördert und den Körper einschränkt, um eine gegenseitige Durchdringung mit der Szene zu vermeiden
Angesichts der dreidimensionalen Szene S und der generierten SMPL-X-Parameter , der Optimierungsverlust beträgt:
Dazu gehört 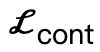 , dass Körperscheitelpunkte mit der Szene in Kontakt kommen;
, dass Körperscheitelpunkte mit der Szene in Kontakt kommen; 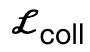 ist ein Kollisionsbegriff, der auf der vorzeichenbehafteten Distanz basiert; Szene und abgetasteter menschlicher Körper.
ist ein Kollisionsbegriff, der auf der vorzeichenbehafteten Distanz basiert; Szene und abgetasteter menschlicher Körper. 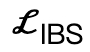 ist ein Regularisierungsfaktor, der verwendet wird, um Parameter zu bestrafen, die von der Initialisierung abweichen.
ist ein Regularisierungsfaktor, der verwendet wird, um Parameter zu bestrafen, die von der Initialisierung abweichen. 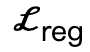
und interaktive Aktionen 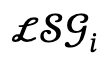 und definiert den Kandidatensatz als
und definiert den Kandidatensatz als 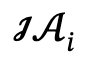 , wobei l die Anzahl der Personen ist.
, wobei l die Anzahl der Personen ist. 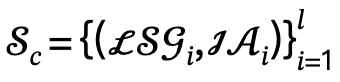
und dem entsprechenden globalen Szenendiagramm 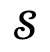 in Narrator eingegeben und dann der Optimierungsprozess durchgeführt.
in Narrator eingegeben und dann der Optimierungsprozess durchgeführt. 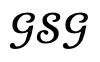
eingeführt, wobei 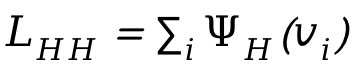 der vorzeichenbehaftete Abstand zwischen Personen ist.
der vorzeichenbehaftete Abstand zwischen Personen ist. 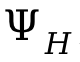
durch Hinzufügen menschlicher Knoten; andernfalls wird das generierte Ergebnis als nicht vertrauenswürdig betrachtet und aktualisiert  durch Abschirmung des entsprechenden Objektknotens.
durch Abschirmung des entsprechenden Objektknotens. 
 Bilder
Bilder
Abbildung 3 Qualitative Vergleichsergebnisse verschiedener Methoden
Abbildung 3 zeigt die qualitativen Vergleichsergebnisse von Narrator und drei Basislinien. Aufgrund der Darstellungsbeschränkungen von PiGraph-Text treten schwerwiegendere Penetrationsprobleme auf.
POSA-Text fällt während des Optimierungsprozesses häufig in lokale Minima, was zu schlechten interaktiven Kontakten führt. COINS-Text bindet Aktionen an bestimmte Objekte, es mangelt ihm an globalem Bewusstsein für die Szene, er führt zu einer Durchdringung mit nicht spezifizierten Objekten und es ist schwierig, mit komplexen räumlichen Beziehungen umzugehen.
Im Gegensatz dazu kann der Erzähler auf der Grundlage verschiedener Ebenen von Textbeschreibungen korrekte Überlegungen zu räumlichen Beziehungen anstellen und Körperzustände bei mehreren Aktionen analysieren, wodurch bessere Generierungsergebnisse erzielt werden.
In Bezug auf den quantitativen Vergleich übertrifft Narrator, wie in Tabelle 1 gezeigt, andere Methoden in fünf Indikatoren, was zeigt, dass die mit dieser Methode generierten Ergebnisse eine genauere Textkonsistenz und eine bessere physische Plausibilität aufweisen.
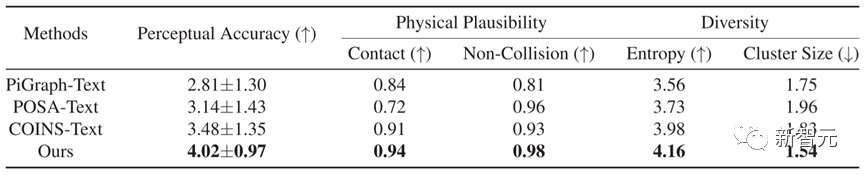 Tabelle 1 Quantitative Vergleichsergebnisse verschiedener Methoden
Tabelle 1 Quantitative Vergleichsergebnisse verschiedener Methoden
Darüber hinaus bietet der Autor detaillierte Vergleiche und Analysen, um die Wirksamkeit der vorgeschlagenen MHSI-Strategie besser zu verstehen.
Angesichts der Tatsache, dass es derzeit keine Arbeit an MHSI gibt, wählten sie einen unkomplizierten Ansatz als Basis, nämlich sequentielle Generierung und Optimierung mit COINS.
Um einen fairen Vergleich zu ermöglichen, wird auch ein künstlicher Kollisionsverlust eingeführt. Abbildung 4 und Tabelle 2 zeigen die qualitativen bzw. quantitativen Ergebnisse, die beide deutlich beweisen, dass die vom Autor vorgeschlagene Strategie auf MHSI semantisch konsistent und physikalisch sinnvoll ist.
 Abbildung 4 Qualitativer Vergleich mit MHSI unter Verwendung der sequentiellen Generierungs- und Optimierungsmethode von COINS
Abbildung 4 Qualitativer Vergleich mit MHSI unter Verwendung der sequentiellen Generierungs- und Optimierungsmethode von COINS

Über den Autor

Die Hauptrichtungen der Forschung umfassen drei -dimensionales Sehen, Computer Vision und Erzeugung von Interaktionen zwischen Mensch und Szene

Hauptforschungsrichtungen: dreidimensionales Sehen, Computer Vision, Rekonstruktion des menschlichen Körpers und der Kleidung

Die Forschungsrichtungen umfassen hauptsächlich dreidimensionales Sehen Vision, Computer Vision und Bilderzeugung. Die Forschungsrichtung konzentriert sich hauptsächlich auf menschzentrierte Computer Vision und Grafik. Hauptforschungsrichtungen: Computergrafik, dreidimensionales Sehen und Computerfotografie
Persönlicher Homepage-Link: https://liuyebin.com/
[ 1] Savva M, Chang A M, Ghosh P, Tesch J, et al. 14718.
 [3] Zhao K, Wang S, Zhang Y, et al. Kompositionelle Mensch-Szenen-Interaktionssynthese mit semantischer Kontrolle[C].
[3] Zhao K, Wang S, Zhang Y, et al. Kompositionelle Mensch-Szenen-Interaktionssynthese mit semantischer Kontrolle[C].
Das obige ist der detaillierte Inhalt vonNeuer Durchbruch in der „interaktiven Generierung von Personen und Szenen'! Tianda University und Tsinghua University veröffentlichen Narrator: textgesteuert, natürlich kontrollierbar |. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Der perfekte Leitfaden für Tsinghua Mirror Source: Machen Sie Ihre Softwareinstallation reibungsloser
Jan 16, 2024 am 10:08 AM
Der perfekte Leitfaden für Tsinghua Mirror Source: Machen Sie Ihre Softwareinstallation reibungsloser
Jan 16, 2024 am 10:08 AM
Tsinghua Image Source-Nutzungsleitfaden: Um Ihre Softwareinstallation reibungsloser zu gestalten, sind spezifische Codebeispiele erforderlich. Im täglichen Gebrauch von Computern müssen wir häufig verschiedene Software installieren, um unterschiedliche Anforderungen zu erfüllen. Allerdings stoßen wir bei der Installation von Software häufig auf Probleme wie eine langsame Download-Geschwindigkeit und die fehlende Verbindungsfähigkeit, insbesondere bei der Verwendung ausländischer Spiegelquellen. Um dieses Problem zu lösen, stellt die Tsinghua-Universität eine Spiegelquelle bereit, die umfangreiche Softwareressourcen bereitstellt und eine sehr schnelle Download-Geschwindigkeit aufweist. Lassen Sie uns als Nächstes etwas über die Nutzungsstrategie der Tsinghua-Spiegelquelle erfahren. Erste,
 In welchen Szenarien tritt ClassCastException in Java auf?
Jun 25, 2023 pm 09:19 PM
In welchen Szenarien tritt ClassCastException in Java auf?
Jun 25, 2023 pm 09:19 PM
Java ist eine stark typisierte Sprache, die zur Laufzeit einen Datentypabgleich erfordert. Aufgrund des strikten Typkonvertierungsmechanismus von Java tritt bei einer Nichtübereinstimmung des Datentyps im Code eine ClassCastException auf. ClassCastException ist eine der häufigsten Ausnahmen in der Java-Sprache. In diesem Artikel werden die Ursachen von ClassCastException und deren Vermeidung vorgestellt. Was ist ClassCastException?
 Haben Sie diese Stresstest-Tools für Linux-Systeme verwendet?
Mar 21, 2024 pm 04:12 PM
Haben Sie diese Stresstest-Tools für Linux-Systeme verwendet?
Mar 21, 2024 pm 04:12 PM
Sind Sie als Betriebs- und Wartungspersonal schon einmal auf dieses Szenario gestoßen? Sie müssen Tools verwenden, um eine hohe CPU- oder Speicherauslastung des Systems zu testen, um Alarme auszulösen, oder die Parallelitätsfähigkeiten des Dienstes durch Stresstests testen. Als Betriebs- und Wartungsingenieur können Sie mit diesen Befehlen auch Fehlerszenarien nachbilden. Dann kann Ihnen dieser Artikel dabei helfen, häufig verwendete Testbefehle und -tools zu beherrschen. 1. Einleitung Um Probleme im Projekt zu lokalisieren und zu reproduzieren, müssen in manchen Fällen Tools zur Durchführung systematischer Stresstests zur Simulation und Wiederherstellung von Fehlerszenarien eingesetzt werden. Zu diesem Zeitpunkt sind Test- oder Stresstest-Tools besonders wichtig. Als Nächstes werden wir die Verwendung dieser Tools in verschiedenen Szenarien untersuchen. 2. Testtools 2.1 Tool zur Netzwerkgeschwindigkeitsbegrenzung tctc ist ein Befehlszeilentool zum Anpassen von Netzwerkparametern unter Linux. Es kann zur Simulation verschiedener Netzwerke verwendet werden.
 In zwei Sätzen: Lassen Sie die KI VR-Szenen generieren! Oder eine Art 3D- oder HDR-Panorama?
Apr 12, 2023 am 09:46 AM
In zwei Sätzen: Lassen Sie die KI VR-Szenen generieren! Oder eine Art 3D- oder HDR-Panorama?
Apr 12, 2023 am 09:46 AM
Big Data Digest Produziert von: Caleb In letzter Zeit kann man sagen, dass ChatGPT äußerst beliebt ist. Am 30. November veröffentlichte OpenAI den Chat-Roboter ChatGPT und stellte ihn der Öffentlichkeit kostenlos zum Testen zur Verfügung. Seitdem ist er in China weit verbreitet. Mit einem Roboter zu sprechen bedeutet, den Roboter aufzufordern, eine bestimmte Anweisung auszuführen, beispielsweise ein Schlüsselwort einzugeben und die KI das entsprechende Bild generieren zu lassen. Das scheint nicht ungewöhnlich zu sein. Hat OpenAI im April nicht auch eine neue Version von DALL-E aktualisiert? OpenAI, wie alt bist du? (Warum sind es immer Sie?) Was wäre, wenn Digest sagen würde, dass es sich bei den generierten Bildern um 3D-Bilder, HDR-Panoramen oder VR-basierte Bildinhalte handelt? Kürzlich Singapur
 Tsinghua Optics AI erscheint in der Natur! Physisches neuronales Netzwerk, Backpropagation ist nicht mehr erforderlich
Aug 10, 2024 pm 10:15 PM
Tsinghua Optics AI erscheint in der Natur! Physisches neuronales Netzwerk, Backpropagation ist nicht mehr erforderlich
Aug 10, 2024 pm 10:15 PM
Die Ergebnisse der Tsinghua-Universität mithilfe von Licht zum Trainieren neuronaler Netze wurden kürzlich in Nature veröffentlicht! Was soll ich tun, wenn ich den Backpropagation-Algorithmus nicht anwenden kann? Sie schlugen eine Trainingsmethode im Fully Forward Mode (FFM) vor, die den Trainingsprozess direkt im physischen optischen System durchführt und so die Einschränkungen herkömmlicher digitaler Computersimulationen überwindet. Vereinfacht ausgedrückt war es früher notwendig, das physikalische System im Detail zu modellieren und diese Modelle dann auf einem Computer zu simulieren, um das Netzwerk zu trainieren. Die FFM-Methode eliminiert den Modellierungsprozess und ermöglicht es dem System, experimentelle Daten direkt zum Lernen und zur Optimierung zu nutzen. Dies bedeutet auch, dass beim Training nicht mehr jede Schicht von hinten nach vorne überprüft werden muss (Backpropagation), sondern die Parameter des Netzwerks direkt von vorne nach hinten aktualisiert werden können. Um eine Analogie wie ein Puzzle zu verwenden: Backpropagation
 Lernen Sie, gängige Kafka-Befehle zu verwenden und flexibel auf verschiedene Szenarien zu reagieren.
Jan 31, 2024 pm 09:22 PM
Lernen Sie, gängige Kafka-Befehle zu verwenden und flexibel auf verschiedene Szenarien zu reagieren.
Jan 31, 2024 pm 09:22 PM
Grundlagen zum Erlernen von Kafka: Beherrschen Sie allgemeine Befehle und bewältigen Sie problemlos verschiedene Szenarien. 1. Erstellen Sie Topicbin/kafka-topics.sh--create--topicmy-topic--partitions3--replication-factor22. -list3. Themendetails anzeigen bin/kafka-to
 Lassen Sie uns über die Modellfusionsmethode großer Modelle sprechen
Mar 11, 2024 pm 01:10 PM
Lassen Sie uns über die Modellfusionsmethode großer Modelle sprechen
Mar 11, 2024 pm 01:10 PM
In früheren Praktiken wurde die Modellfusion häufig verwendet, insbesondere in Diskriminanzmodellen, wo sie als eine Methode angesehen wird, die die Leistung stabil verbessern kann. Allerdings ist die Funktionsweise generativer Sprachmodelle aufgrund des damit verbundenen Decodierungsprozesses nicht so einfach wie bei diskriminativen Modellen. Darüber hinaus sind aufgrund der zunehmenden Anzahl von Parametern großer Modelle in Szenarien mit größeren Parameterskalen die Methoden, die beim einfachen Ensemble-Lernen berücksichtigt werden können, eingeschränkter als beim maschinellen Lernen mit niedrigen Parametern, wie z. B. klassisches Stapeln, Boosten usw Andere Methoden, weil Stapelmodelle Das Parameterproblem kann nicht einfach erweitert werden. Daher erfordert das Ensemble-Lernen für große Modelle sorgfältige Überlegungen. Im Folgenden erläutern wir fünf grundlegende Integrationsmethoden, nämlich Modellintegration, probabilistische Integration, Grafting Learning, Crowdsourcing-Voting und MOE
