
 Technologie-Peripheriegeräte
IT Industrie
Anomalieerkennung: Minimieren Sie Fehlalarme mit der Rules Engine
Technologie-Peripheriegeräte
IT Industrie
Anomalieerkennung: Minimieren Sie Fehlalarme mit der Rules Engine
Anomalieerkennung: Minimieren Sie Fehlalarme mit der Rules Engine

Anomalien sind Abweichungen von erwarteten Mustern und können in verschiedenen Umgebungen auftreten – sei es bei Bankgeschäften, Industriebetrieben, der Marketingbranche oder der Gesundheitsüberwachung. Herkömmliche Erkennungsmethoden führen häufig zu hohen Fehlalarmraten. Ein falsch positives Ergebnis liegt vor, wenn ein System ein Routineereignis fälschlicherweise als Anomalie identifiziert, was zu unnötigem Untersuchungsaufwand und Betriebsverzögerungen führt. Diese Ineffizienz ist ein dringendes Problem, da sie Ressourcen verschlingt und die Aufmerksamkeit von den wirklichen Problemen ablenkt, die gelöst werden müssen. Dieses Dokument befasst sich eingehend mit einem speziellen Ansatz zur Anomalieerkennung, der in großem Umfang regelbasierte Engines nutzt. Dieser Ansatz verbessert die Genauigkeit der Identifizierung von Verstößen durch Querverweise mehrerer wichtiger Leistungsindikatoren (KPIs). Dieser Ansatz kann nicht nur das Vorhandensein einer Anomalie effektiver überprüfen oder widerlegen, sondern manchmal auch die Grundursache des Problems isolieren und identifizieren.
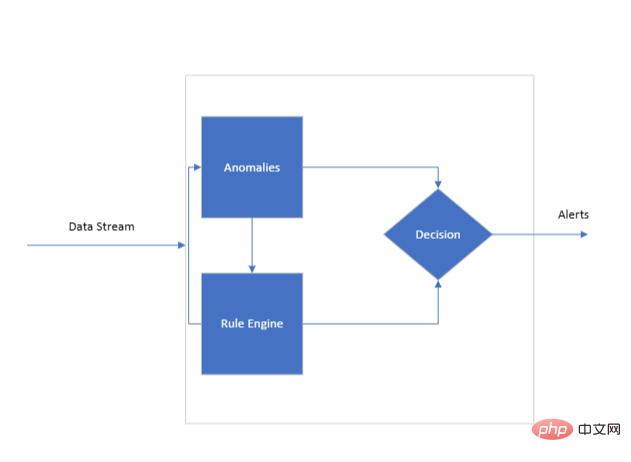
Überblick über die Systemarchitektur
Datenfluss
Dies ist ein kontinuierlicher Datenfluss für die Motorüberprüfung. Jeder Punkt im Ablauf kann mit einem oder mehreren KPIs verknüpft sein, die von der Regel-Engine zur Bewertung anhand ihres Trainingsregelsatzes verwendet werden. Für die Echtzeitüberwachung ist ein kontinuierlicher Datenfluss unerlässlich, der den Motor mit den für den Betrieb notwendigen Informationen versorgt.
Architektur der Regel-Engine
Das Herzstück des Systems ist die Regel-Engine, die trainiert werden muss, um die Nuancen der zu überwachenden KPIs zu verstehen. Hier kommt eine Reihe von KPI-Regeln ins Spiel. Diese Regeln dienen als algorithmische Grundlage der Engine und sollen zwei oder mehr KPIs miteinander korrelieren.
Arten von KPI-Regeln:
- Datenqualität: Regeln, die sich auf die Konsistenz, Genauigkeit und Zuverlässigkeit des Datenflusses konzentrieren.
- KPI-Korrelation: Regeln, die sich auf die Korrelation bestimmter KPIs konzentrieren.
Regelanwendungsprozess. Nach Erhalt der Daten sucht die Engine sofort nach Abweichungen oder Anomalien in den eingehenden KPIs. Eine Anomalie bezieht sich hier auf jede Metrik, die außerhalb eines vorgegebenen akzeptablen Bereichs liegt. Die Engine markiert diese Anomalien zur weiteren Untersuchung, die in drei Hauptvorgänge unterteilt werden kann: Akzeptieren, Ablehnen und Eingrenzen. Dies kann die Korrelation eines KPI mit einem anderen beinhalten, um eine erkannte Anomalie zu validieren oder zu negieren.
Methode
Regelbildung
Die grundlegenden Schritte umfassen die Erstellung einer Reihe von Regeln, die mehrere KPIs miteinander in Beziehung setzen. Beispielsweise könnte eine Regel Produktqualitätsmetriken mit der Produktionsgeschwindigkeit in einer Fabrikumgebung in Beziehung setzen. Zum Beispiel:
- Direkte Beziehung zwischen KPIs: Eine „direkte Beziehung“ zwischen zwei KPIs bedeutet, dass wenn ein KPI steigt, auch der andere KPI steigt, oder wenn ein KPI sinkt, auch der andere sinkt. Beispielsweise kann in einem Einzelhandelsunternehmen ein Anstieg der Werbeausgaben (KPI1) in direktem Zusammenhang mit einem Anstieg des Umsatzes (KPI2) stehen. In diesem Fall wirkt sich eine Steigerung eines Aspekts positiv auf den anderen aus. Dieses Wissen ist für Unternehmen von unschätzbarem Wert, da es bei der strategischen Planung und Ressourcenzuweisung hilft.
- Inverse Beziehung zwischen KPIs: Andererseits bedeutet eine „inverse Beziehung“, dass wenn ein KPI steigt, der andere KPI sinkt und umgekehrt. Beispielsweise kann in einer Fertigungsumgebung die Zeit, die zur Herstellung eines Produkts benötigt wird (KPI1), in einem umgekehrten Verhältnis zur Produktivität (KPI2) stehen. Wenn die Produktionszeit verkürzt wird, kann die Produktivität steigen. Das Verständnis der umgekehrten Beziehung ist auch für die Geschäftsoptimierung von entscheidender Bedeutung, da möglicherweise Ausgleichsmaßnahmen zur Optimierung beider KPIs erforderlich sind.
- Kombinieren Sie KPIs, um neue Regeln zu erstellen: Manchmal kann es von Vorteil sein, zwei oder mehr KPIs zu kombinieren, um eine neue Metrik zu erstellen, die wertvolle Einblicke in die Geschäftsleistung liefern kann. Beispielsweise ergibt die Kombination von Customer Lifetime Value (KPI1) und Customer Acquisition Cost (KPI2) einen dritten KPI: Customer Value to Cost Ratio. Dieser neue KPI bietet ein umfassenderes Verständnis dafür, ob die Kosten für die Akquise eines neuen Kunden im Verhältnis zum Wert stehen, den er im Laufe der Zeit liefert.
Trainingsregel-Engine
Die Regel-Engine ist vollständig darauf trainiert, diese Regeln effektiv in Echtzeit anzuwenden.
Überprüfung in Echtzeit
Die Regel-Engine überwacht proaktiv eingehende Daten und wendet ihre trainierten Regeln an, um Anomalien oder potenzielle Anomalien zu identifizieren.
Entscheidungsfindung
Bei der Identifizierung potenzieller Anomalien ist der Motor:
- Akzeptieren von Ausnahmen: Bestätigungsphase: Sobald eine Ausnahme gekennzeichnet ist, vergleicht die Engine sie mithilfe ihrer vorab trainierten KPI-Regeln mit anderen zugehörigen KPIs. Hier geht es darum, festzustellen, ob es sich bei der Anomalie tatsächlich um ein Problem oder nur um einen Ausreißer handelt. Diese Bestätigung erfolgt auf Grundlage der Korrelation zwischen primären und sekundären KPIs.
- Abgelehnte Ausnahmen: Falsch positive Phase: Nicht alle Ausnahmen weisen auf ein Problem hin; einige können statistische Ausreißer oder Datenfehler sein. In diesem Fall nutzt die Engine ihr Training, um die Anomalie abzulehnen und sie im Wesentlichen als falsch positiv zu identifizieren. Dies ist entscheidend, um unnötige Alarmmüdigkeit zu vermeiden und die Ressourcen auf das eigentliche Problem zu konzentrieren.
- Eingrenzen des Umfangs der Anomalie: Verfeinerungsphase: Manchmal kann eine Anomalie Teil eines größeren Problems sein, das mehrere Komponenten betrifft. Hier ermittelt die Engine die genaue Art des Problems weiter, indem sie es auf bestimmte KPI-Komponenten eingrenzt. Diese erweiterte Filterung hilft, Probleme schnell zu identifizieren und Grundursachen zu beheben.
Vorteile
- Reduzieren Sie Fehlalarme: Durch die Verwendung einer Regel-Engine, die mehrere KPIs vergleicht, reduziert das System die Häufigkeit von Fehlalarmen erheblich.
- Zeit- und Kosteneffizienz: Anomalien werden schneller erkannt und behoben, wodurch die Betriebszeit und die damit verbundenen Kosten reduziert werden.
- Verbesserte Genauigkeit: Die Möglichkeit, mehrere KPIs zu vergleichen und gegenüberzustellen, ermöglicht eine detailliertere und genauere Darstellung abnormaler Ereignisse.
Fazit
Dieser Artikel beschreibt einen Ansatz zur Anomalieerkennung mithilfe einer Regel-Engine, die auf verschiedenen KPI-Regelsätzen trainiert wurde. Im Gegensatz zu herkömmlichen Anomalieerkennungssystemen, die häufig ausschließlich auf statistischen Algorithmen oder Modellen des maschinellen Lernens basieren, basiert dieser Ansatz auf einer speziellen Regel-Engine. Durch eine tiefere Untersuchung der Beziehungen und Interaktionen zwischen verschiedenen KPIs können Unternehmen detailliertere Erkenntnisse gewinnen, die einfache, eigenständige Metriken nicht liefern können. Dies ermöglicht eine robustere strategische Planung, ein besseres Risikomanagement und einen insgesamt effektiveren Ansatz zur Erreichung der Geschäftsziele. Sobald eine Anomalie gemeldet wird, vergleicht die Engine sie mithilfe ihrer vorab trainierten KPI-Regeln mit anderen zugehörigen KPIs. Hier geht es darum, festzustellen, ob es sich bei der Anomalie tatsächlich um ein Problem oder nur um einen Ausreißer handelt.
Das obige ist der detaillierte Inhalt vonAnomalieerkennung: Minimieren Sie Fehlalarme mit der Rules Engine. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verwendung von PHP zur Implementierung der Anomalieerkennung und Betrugsanalyse
Jul 30, 2023 am 09:42 AM
Verwendung von PHP zur Implementierung der Anomalieerkennung und Betrugsanalyse
Jul 30, 2023 am 09:42 AM
Verwendung von PHP zur Implementierung der Anomalieerkennung und Betrugsanalyse Zusammenfassung: Mit der Entwicklung des E-Commerce ist Betrug zu einem Problem geworden, das nicht ignoriert werden kann. In diesem Artikel wird erläutert, wie Sie PHP zur Implementierung der Anomalieerkennung und Betrugsanalyse verwenden. Durch die Erfassung von Benutzertransaktionsdaten und Verhaltensdaten, kombiniert mit Algorithmen des maschinellen Lernens, wird das Benutzerverhalten in Echtzeit im System überwacht und analysiert, potenzieller Betrug identifiziert und entsprechende Maßnahmen zur Bekämpfung ergriffen. Schlüsselwörter: PHP, Anomalieerkennung, Betrugsanalyse, maschinelles Lernen 1. Einleitung Mit der rasanten Entwicklung des E-Commerce steigt die Zahl der Transaktionen, die Menschen im Internet durchführen
 Überwachung der Nginx-Sicherheitsleistung und Anomalieerkennung
Jun 10, 2023 pm 04:15 PM
Überwachung der Nginx-Sicherheitsleistung und Anomalieerkennung
Jun 10, 2023 pm 04:15 PM
Nginx ist eine kostenlose, leistungsstarke und leichte Open-Source-HTTP-Serversoftware, die im Internet weit verbreitet ist. Da Nginx jedoch häufig mit dem öffentlichen Netzwerk verbunden ist und für wichtige Webdienste verantwortlich ist, muss es regelmäßig eine Überwachung der Sicherheitsleistung und eine Anomalieerkennung durchführen und rechtzeitig wirksame Sicherheitsmaßnahmen ergreifen, um den normalen Betrieb der Website und die Sicherheit von zu gewährleisten Daten. 1. Nginx-Sicherheitsleistungsüberwachung Die Nginx-Sicherheitsleistungsüberwachung umfasst hauptsächlich die folgenden Aspekte: (1) Nginx-Zugriffsprotokollüberwachung Ngin
 MySQL-Protokollüberwachung: So erkennen und analysieren Sie MySQL-Fehler und -Ausnahmen schnell
Jun 15, 2023 pm 09:42 PM
MySQL-Protokollüberwachung: So erkennen und analysieren Sie MySQL-Fehler und -Ausnahmen schnell
Jun 15, 2023 pm 09:42 PM
Mit dem Aufkommen des Internets und des Big-Data-Zeitalters wird die MySQL-Datenbank als häufig verwendetes Open-Source-Datenbankverwaltungssystem von immer mehr Unternehmen und Organisationen übernommen. Im eigentlichen Anwendungsprozess können jedoch verschiedene Fehler und Ausnahmen in der MySQL-Datenbank auftreten, z. B. Systemabstürze, Abfragezeitüberschreitungen, Deadlocks usw. Diese Anomalien haben schwerwiegende Auswirkungen auf die Systemstabilität und Datenintegrität. Daher ist die schnelle Erkennung und Analyse von MySQL-Fehlern und -Anomalien eine sehr wichtige Aufgabe. Die Protokollüberwachung ist eine wichtige Funktion von MySQL
 Beispiele zur Anomalieerkennung in Python
Jun 09, 2023 pm 09:33 PM
Beispiele zur Anomalieerkennung in Python
Jun 09, 2023 pm 09:33 PM
Python ist eine High-Level-Programmiersprache, die leicht zu erlernen und leistungsstark ist. Aufgrund ihrer guten Lesbarkeit, ihres geringen Codeumfangs und ihrer einfachen Wartung wird sie häufig in den Bereichen wissenschaftliches Rechnen, Datenanalyse, künstliche Intelligenz und anderen Bereichen eingesetzt. Da jedoch jede Programmiersprache auf Fehler und Ausnahmen stößt, bietet Python auch einen Ausnahmemechanismus, damit Entwickler diese Situationen besser bewältigen können. In diesem Artikel wird die Verwendung des Anomalieerkennungsmechanismus in Python vorgestellt und einige Beispiele gegeben. 1. Ausnahmetypen in Python in Py
 Best Practices und Algorithmenauswahl für die Datenzuverlässigkeitsvalidierung und Modellbewertung in Python
Oct 27, 2023 pm 12:01 PM
Best Practices und Algorithmenauswahl für die Datenzuverlässigkeitsvalidierung und Modellbewertung in Python
Oct 27, 2023 pm 12:01 PM
So führen Sie Best Practices und Algorithmenauswahl zur Überprüfung der Datenzuverlässigkeit und Modellbewertung in Python durch. Einführung: Im Bereich des maschinellen Lernens und der Datenanalyse sind die Überprüfung der Zuverlässigkeit von Daten und die Bewertung der Leistung des Modells sehr wichtige Aufgaben. Durch die Überprüfung der Zuverlässigkeit der Daten können Qualität und Genauigkeit der Daten garantiert und so die Vorhersagekraft des Modells verbessert werden. Die Modellbewertung hilft uns, die besten Modelle auszuwählen und ihre Leistung zu bestimmen. In diesem Artikel werden Best Practices und Algorithmusoptionen für die Überprüfung der Datenzuverlässigkeit und die Modellbewertung in Python vorgestellt
 Anomalieerkennungsproblem basierend auf Zeitreihen
Oct 09, 2023 pm 04:33 PM
Anomalieerkennungsproblem basierend auf Zeitreihen
Oct 09, 2023 pm 04:33 PM
Das Problem der Anomalieerkennung auf der Grundlage von Zeitreihen erfordert spezifische Codebeispiele. Zeitreihendaten sind Daten, die in einer bestimmten Reihenfolge über einen Zeitraum hinweg aufgezeichnet werden, z. B. Aktienkurse, Temperaturänderungen, Verkehrsfluss usw. In praktischen Anwendungen ist die Anomalieerkennung von Zeitreihendaten von großer Bedeutung. Ein Ausreißer kann ein Extremwert sein, der nicht mit normalen Daten übereinstimmt, Rauschen, fehlerhafte Daten oder ein unerwartetes Ereignis in einer bestimmten Situation. Die Anomalieerkennung kann uns helfen, diese Anomalien zu entdecken und geeignete Maßnahmen zu ergreifen. Wird häufig für Probleme bei der Erkennung von Zeitreihenanomalien verwendet
 Python für die Zeitreihenanalyse: Prognose und Anomalieerkennung
Aug 31, 2023 pm 08:09 PM
Python für die Zeitreihenanalyse: Prognose und Anomalieerkennung
Aug 31, 2023 pm 08:09 PM
Python ist zur Sprache der Wahl für Datenwissenschaftler und -analysten geworden und bietet umfassende Datenanalysebibliotheken und -tools. Python zeichnet sich insbesondere durch Zeitreihenanalysen sowie Prognosen und Anomalieerkennung aus. Mit seiner Einfachheit, Vielseitigkeit und starken Unterstützung für statistische und maschinelle Lerntechniken bietet Python eine ideale Plattform zum Extrahieren wertvoller Erkenntnisse aus zeitabhängigen Daten. In diesem Artikel werden die bemerkenswerten Fähigkeiten von Python für die Zeitreihenanalyse untersucht, wobei der Schwerpunkt auf Prognosen und Anomalieerkennung liegt. Indem wir uns mit den praktischen Aspekten dieser Aufgaben befassen, verdeutlichen wir, wie die Bibliotheken und Tools von Python eine genaue Vorhersage und Identifizierung von Anomalien in Zeitreihendaten ermöglichen. Durch Beispiele aus der Praxis und anschaulichen Input
 So implementieren Sie einen Anomalieerkennungsalgorithmus in C#
Sep 19, 2023 am 08:09 AM
So implementieren Sie einen Anomalieerkennungsalgorithmus in C#
Sep 19, 2023 am 08:09 AM
Für die Implementierung des Anomalieerkennungsalgorithmus in C# sind spezifische Codebeispiele erforderlich. Einführung: Bei der C#-Programmierung ist die Ausnahmebehandlung ein sehr wichtiger Teil. Wenn im Programm Fehler oder unerwartete Situationen auftreten, kann uns der Ausnahmebehandlungsmechanismus dabei helfen, diese Fehler ordnungsgemäß zu behandeln und die Stabilität und Zuverlässigkeit des Programms sicherzustellen. In diesem Artikel wird detailliert beschrieben, wie Anomalieerkennungsalgorithmen in C# implementiert werden, und es werden spezifische Codebeispiele gegeben. 1. Grundkenntnisse der Ausnahmebehandlung Definition und Klassifizierung von Ausnahmen Ausnahmen sind Fehler oder unerwartete Situationen, die während der Ausführung eines Programms auftreten und den normalen Ausführungsfluss des Programms stören.
