
 Technologie-Peripheriegeräte
KI
Neue Impulse für KI-Upgrades; Anwendungsangst vor großen Modellen, wie löst Baidu dieses Problem? Wang Xiaochuan veröffentlicht Open-Source-Großmodelle丨AI New Retail Morning News
Technologie-Peripheriegeräte
KI
Neue Impulse für KI-Upgrades; Anwendungsangst vor großen Modellen, wie löst Baidu dieses Problem? Wang Xiaochuan veröffentlicht Open-Source-Großmodelle丨AI New Retail Morning News
Neue Impulse für KI-Upgrades; Anwendungsangst vor großen Modellen, wie löst Baidu dieses Problem? Wang Xiaochuan veröffentlicht Open-Source-Großmodelle丨AI New Retail Morning News


KI-Marketing-Beobachtung
《Speicher, die neue treibende Kraft für KI-Upgrades》
Im Zeitalter großer Modelle erfordert die Lagerung nicht nur große Mengen und hohe Qualität, sondern auch starke Leistung, gute Stabilität und Energieeinsparung. Bereitstellung von Speicherunterstützungsmaßnahmen für KI: Durch die Unterstützung aller Arten von Speicherprotokollen können wir die intelligente Anpassung und Fusion von Multiprotokolldaten in mehreren Szenarien realisieren. Durch die Realisierung des direkten Datenzugriffs durch Smart Chips können wir das Laden und Verarbeiten von Daten verbessern stellt während des Trainings die Geschwindigkeit ein. (Quelle: Offizieller WeChat-Account „Yuanchuan Technology Review“)
"Apples KI-Ambition: Interner Konflikt, Gegenangriff und Herausforderungen"
Nachdem Apple 2016 iOS 10 auf den Markt gebracht hatte, startete es einen neuen KI-Gegenangriff, der sich hauptsächlich in zwei Aspekten widerspiegelte: der vertikalen Integration und der Kombination von Software und Hardware. Apple hat in mehrere KI-Bereiche wie Spracherkennung, Gesichtserkennung usw. investiert und KI-Funktionen in seine Produkte und Dienstleistungen integriert. Maßnahmen: Es gilt, ein Gleichgewicht zwischen dem Schutz der Privatsphäre der Nutzer und der Verbesserung der Rechenleistung zu finden und gleichzeitig auf die Angriffe von Technologieriesen wie Google und Microsoft auf große KI-Modelle zu reagieren. (Quelle: öffentlicher WeChat-Account „Chuangye Bang“)
《RLHF erfordert keine menschliche Anmerkung mehr, Google schlägt eine KI-basierte Feedback-Generierung vor: Der Effekt ist vergleichbar mit menschlicher Anmerkung》
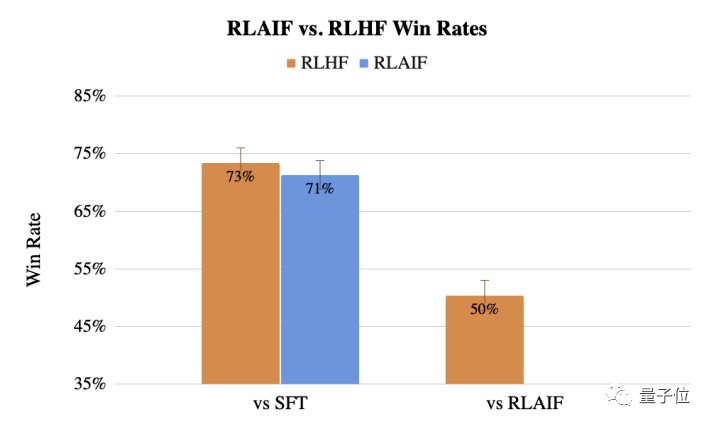
RLAIF ist eine KI-basierte Feedback-Generierungsmethode, die menschliches Feedback in RLHF ersetzen kann, sodass das Training großer Modelle nicht mehr menschlichen Einschränkungen unterliegt. RLAIF verwendet LLM, um Feedback-Daten zu generieren, und verwendet dann eine modifizierte Version des A2C-Algorithmus, um Verstärkungslernen durchzuführen und das Zielmodell zu trainieren. Die Leistung von RLAIF bei Textzusammenfassungsaufgaben ist mit der von RLHF vergleichbar und in einigen Details sogar besser. (Quelle: „Xi Xiaoyao Technology Talk“, offizieller WeChat-Account)
Beobachtung bei großer Modellanwendung
《Wie löst Baidu die Anwendungsangst großer Models? 》
Die große Modellindustrie sieht sich mit dem Mangel an Anwendungsebene und dem Verlust des Benutzerinteresses konfrontiert und muss von „Hänseleien“ zu Innovationen übergehen, die Leben und Arbeit wirklich verändern können. Baidu-Initiativen: Der Unternehmerwettbewerb „Wenxin Cup“ wurde abgehalten, um den teilnehmenden Teams die Wenxin Big Model API-Schnittstelle, Baidu Intelligent Cloud Computing-Ressourcen und Investitionsunterstützung zur Verfügung zu stellen. Das Wenxin Big Model wurde zur Rekonstruktion von Baidu Search und anderen Serien mit über 100 Millionen verwendet Benutzer. (Quelle: Offizieller WeChat-Account „Alphabet List“)
《Dialog Shen Dou: Es gibt heute viele große Models auf dem Markt, aber die meisten werden schnell verschwinden》Die große Modelbranche muss auf Innovationen umsteigen, die Leben und Arbeit verändern können, und Baidu durch Wen Xinyiyan- und Qianfan-Plattform, die sowohl die Anforderungen der C-Seite als auch der B-Seite erfüllt. Baidus Vorteile bei der Forschung und Entwicklung großer Modelltechnologie: Der Modelleffekt von Wenxin Large Model 3.5 wird um 50 % erhöht, die Trainingsgeschwindigkeit wird um das Zweifache erhöht und die Inferenzgeschwindigkeit wird um das 17-fache erhöht, was die Kosten erheblich senkt von Schlussfolgerungen und ermöglicht es Baidu, eine größere Anzahl von Benutzern zu bedienen. (Quelle: Offizieller WeChat-Account „Geek Park“)
《Baichuan Intelligent veröffentlicht Baichuan2, Wang Xiaochuan: Die Ära chinesischer Unternehmen, die LLaMA2 verwenden, ist vorbei|Jiazi Discovery》
Funktionen: Unterstützt Dutzende von Sprachen, darunter Chinesisch, Englisch, Spanisch und Französisch; wählt hochwertige vertikale Branchendaten auf der Grundlage von Billionen von Internetdaten aus und erstellt ein äußerst umfangreiches Content-Clustering-System, um Hunderte von Milliarden zu vervollständigen der stündlichen Datenbereinigung und -filterung; System zur Bewertung der Inhaltsqualität mit mehreren Granularitäten. Aussichten: Ein 100-Milliarden-Level-Parametermodell zum Benchmarking von GPT-3.5 wird im vierten Quartal dieses Jahres veröffentlicht, und eine Superanwendung wird voraussichtlich im ersten Quartal nächsten Jahres veröffentlicht. (Quelle: Öffentliches WeChat-Konto „Jiazi Discovery“) [Ende]
Das Bild stammt aus dem Internet und wurde wegen Rechtsverletzung gelöscht
Das obige ist der detaillierte Inhalt vonNeue Impulse für KI-Upgrades; Anwendungsangst vor großen Modellen, wie löst Baidu dieses Problem? Wang Xiaochuan veröffentlicht Open-Source-Großmodelle丨AI New Retail Morning News. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Zehn empfohlene Open-Source-Tools für kostenlose Textanmerkungen
Mar 26, 2024 pm 08:20 PM
Bei der Textanmerkung handelt es sich um die Arbeit mit entsprechenden Beschriftungen oder Tags für bestimmte Inhalte im Text. Sein Hauptzweck besteht darin, zusätzliche Informationen zum Text für eine tiefere Analyse und Verarbeitung bereitzustellen, insbesondere im Bereich der künstlichen Intelligenz. Textanmerkungen sind für überwachte maschinelle Lernaufgaben in Anwendungen der künstlichen Intelligenz von entscheidender Bedeutung. Es wird zum Trainieren von KI-Modellen verwendet, um Textinformationen in natürlicher Sprache genauer zu verstehen und die Leistung von Aufgaben wie Textklassifizierung, Stimmungsanalyse und Sprachübersetzung zu verbessern. Durch Textanmerkungen können wir KI-Modellen beibringen, Entitäten im Text zu erkennen, den Kontext zu verstehen und genaue Vorhersagen zu treffen, wenn neue ähnliche Daten auftauchen. In diesem Artikel werden hauptsächlich einige bessere Open-Source-Textanmerkungstools empfohlen. 1.LabelStudiohttps://github.com/Hu
 15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Die Bildanmerkung hat ein breites Anwendungsspektrum und deckt viele Bereiche ab, z. B. Computer Vision, Verarbeitung natürlicher Sprache und Diagramm-Vision-Modelle. Sie verfügt über ein breites Anwendungsspektrum, z. B. zur Unterstützung von Fahrzeugen bei der Identifizierung von Hindernissen auf der Straße und bei der Erkennung und Diagnose von Krankheiten durch medizinische Bilderkennung. In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesens
 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Empfohlen: Ausgezeichnetes JS-Open-Source-Projekt zur Gesichtserkennung und -erkennung
Apr 03, 2024 am 11:55 AM
Die Technologie zur Gesichtserkennung und -erkennung ist bereits eine relativ ausgereifte und weit verbreitete Technologie. Derzeit ist JS die am weitesten verbreitete Internetanwendungssprache. Die Implementierung der Gesichtserkennung und -erkennung im Web-Frontend hat im Vergleich zur Back-End-Gesichtserkennung Vor- und Nachteile. Zu den Vorteilen gehören die Reduzierung der Netzwerkinteraktion und die Echtzeiterkennung, was die Wartezeit des Benutzers erheblich verkürzt und das Benutzererlebnis verbessert. Die Nachteile sind: Es ist durch die Größe des Modells begrenzt und auch die Genauigkeit ist begrenzt. Wie implementiert man mit js die Gesichtserkennung im Web? Um die Gesichtserkennung im Web zu implementieren, müssen Sie mit verwandten Programmiersprachen und -technologien wie JavaScript, HTML, CSS, WebRTC usw. vertraut sein. Gleichzeitig müssen Sie auch relevante Technologien für Computer Vision und künstliche Intelligenz beherrschen. Dies ist aufgrund des Designs der Webseite erwähnenswert
 Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Apr 02, 2024 am 11:31 AM
Neues SOTA für multimodale Dokumentverständnisfunktionen! Das Alibaba mPLUG-Team hat die neueste Open-Source-Arbeit mPLUG-DocOwl1.5 veröffentlicht, die eine Reihe von Lösungen zur Bewältigung der vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des allgemeinen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung externen Wissens vorschlägt. Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an. Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format: Es stehen Diagramme verschiedener Stile zur Verfügung: Auch eine detailliertere Texterkennung und -positionierung ist einfach zu handhaben: Auch ausführliche Erläuterungen zum Dokumentverständnis können gegeben werden: Sie wissen schon, „Document Understanding“. " ist derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen. Einige von ihnen verwenden hauptsächlich OCR-Systeme zur Texterkennung und arbeiten mit LLM zur Textverarbeitung zusammen.
 Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Laut Nachrichten vom 4. April hat die Cyberspace Administration of China kürzlich eine Liste registrierter großer Modelle veröffentlicht, in der das „Jiutian Natural Language Interaction Large Model“ von China Mobile enthalten ist, was darauf hinweist, dass das große Jiutian AI-Modell von China Mobile offiziell generative künstliche Intelligenz bereitstellen kann Geheimdienste nach außen. China Mobile gab an, dass dies das erste groß angelegte Modell sei, das von einem zentralen Unternehmen entwickelt wurde und sowohl die nationale Doppelregistrierung „Generative Artificial Intelligence Service Registration“ als auch die „Domestic Deep Synthetic Service Algorithm Registration“ bestanden habe. Berichten zufolge zeichnet sich Jiutians großes Modell für die Interaktion mit natürlicher Sprache durch verbesserte Branchenfähigkeiten, Sicherheit und Glaubwürdigkeit aus und unterstützt die vollständige Lokalisierung. Es hat mehrere Parameterversionen wie 9 Milliarden, 13,9 Milliarden, 57 Milliarden und 100 Milliarden gebildet. und kann flexibel in der Cloud eingesetzt werden, Edge und End sind unterschiedliche Situationen
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
