
 Technologie-Peripheriegeräte
KI
Entdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen
Technologie-Peripheriegeräte
KI
Entdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen
Entdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen

Die Verbesserung der Generalisierungsfähigkeit des Modells ist eine wichtige Grundlage für die Förderung der Implementierung visionsbasierter Wahrnehmungsmethoden. Testzeit-Training/Anpassung verallgemeinert das Modell auf unbekannte Zieldomänen, indem es die Modellparametergewichte im Datenverteilungssegment des Testabschnitts anpasst . Bestehende TTT/TTA-Methoden konzentrieren sich normalerweise auf die Verbesserung der Testsegment-Trainingsleistung unter Zieldomänendaten in der Welt mit geschlossenem Regelkreis.
In vielen Anwendungsszenarien wird die Zieldomäne jedoch leicht durch starke Daten außerhalb der Domäne (Strong OOD) kontaminiert, z. B. Daten, die keinen Bezug zu semantischen Kategorien haben. Dieses Szenario wird auch als Open World Test Segment Training (OWTTT) bezeichnet. In diesem Fall erzwingt das bestehende TTT/TTA normalerweise die Klassifizierung starker Daten außerhalb der Domäne in bekannte Kategorien, wodurch letztendlich die Fähigkeit beeinträchtigt wird, schwache Daten außerhalb der Domäne (Weak OOD) aufzulösen, wie z. B. Bilder, die gestört werden durch Lärm
Kürzlich haben die South China University of Technology und das A*STAR-Team zum ersten Mal die Einrichtung eines Open-World-Testsegmenttrainings vorgeschlagen und die entsprechende Trainingsmethode eingeführt

- Papier: https ://arxiv.org/abs/2308.09942
- Code: https://github.com/Yushu-Li/OWTTT
Dieses Papier schlägt zunächst eine starke Methode zum Filtern von Datenproben außerhalb der Domäne vor Adaptive Schwelle zur Verbesserung der selbstlernenden TTT-Methode in der offenen Welt der Robustheit. Diese Methode schlägt außerdem eine Methode zur Charakterisierung starker Stichproben außerhalb der Domäne basierend auf dynamisch erweiterten Prototypen vor, um den schwachen/starken Datentrennungseffekt außerhalb der Domäne zu verbessern. Schließlich wird das Selbsttraining durch die Verteilungsausrichtung eingeschränkt
Die Methode in dieser Studie erzielte die beste Leistung bei 5 verschiedenen OWTTT-Benchmarks und eröffnete eine neue Richtung für robustere TTT-Methoden für die nachfolgende Forschung zu TTT. Diese Forschungsarbeit wurde als mündlicher Präsentationsbeitrag beim ICCV 2023 angenommen Testdaten. Der Erfolg von TTT wurde an einer Reihe künstlich ausgewählter, synthetisch beschädigter Zieldomänendaten nachgewiesen. Allerdings sind die Leistungsgrenzen bestehender TTT-Methoden noch nicht vollständig erforscht.
Um TTT-Anwendungen in offenen Szenarien zu fördern, hat sich der Schwerpunkt der Forschung auf die Untersuchung von Szenarien verlagert, in denen TTT-Methoden möglicherweise versagen. Es wurden viele Anstrengungen unternommen, um stabile und robuste TTT-Methoden in realistischeren Open-World-Umgebungen zu entwickeln. In dieser Arbeit befassen wir uns mit einem häufigen, aber übersehenen Open-World-Szenario, bei dem die Zieldomäne möglicherweise Testdatenverteilungen enthält, die aus deutlich unterschiedlichen Umgebungen stammen, z. B. andere semantische Kategorien als die Quelldomäne oder einfach zufälliges Rauschen.
Wir nennen die oben genannten Testdaten starke Out-of-Distribution-Daten (starke OOD). Was in dieser Arbeit als schwache OOD-Daten bezeichnet wird, sind Testdaten mit Verteilungsverschiebungen, wie beispielsweise häufigen synthetischen Schäden. Daher motiviert uns der Mangel an vorhandener Arbeit zu dieser realistischen Umgebung, die Verbesserung der Robustheit des Open World Test Segment Training (OWTTT) zu untersuchen, bei dem die Testdaten durch starke OOD-Proben verunreinigt werden.
Abbildung 1: Bewertungsergebnisse der vorhandenen TTT-Methode unter der OWTTT-Einstellung
Wie in Abbildung 1 gezeigt, haben wir zunächst die vorhandene TTT-Methode unter der OWTTT-Einstellung bewertet und festgestellt, dass beide TTT-Methoden durch sich selbst erfolgen -Training und Verteilungsausrichtung werden durch starke OOD-Proben beeinflusst. Diese Ergebnisse zeigen, dass durch die Anwendung vorhandener TTT-Techniken kein sicheres Testzeittraining in der offenen Welt erreicht werden kann. Wir führen ihr Scheitern auf die folgenden zwei Gründe zurück. 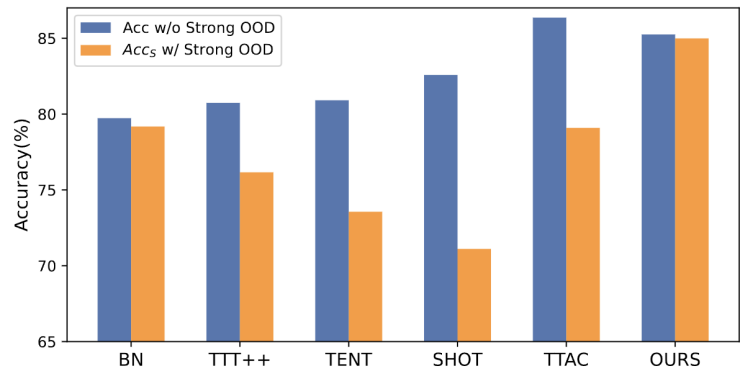
Das auf Selbsttraining basierende TTT hat Schwierigkeiten mit starken OOD-Proben, da es Testproben bekannten Kategorien zuordnen muss. Obwohl einige Stichproben mit geringer Konfidenz durch Anwendung des beim halbüberwachten Lernen verwendeten Schwellenwerts herausgefiltert werden können, gibt es immer noch keine Garantie dafür, dass alle starken OOD-Stichproben herausgefiltert werden.
Methoden, die auf der Verteilungsausrichtung basieren, sind betroffen, wenn starke OOD-Stichproben berechnet werden, um die Zieldomänenverteilung abzuschätzen. Sowohl die globale Verteilungsausrichtung [1] als auch die Klassenverteilungsausrichtung [2] können beeinträchtigt werden und zu einer ungenauen Ausrichtung der Merkmalsverteilung führen.
- Um die möglichen Gründe für das Scheitern bestehender TTT-Methoden zu lösen, schlagen wir eine Methode vor, die zwei Technologien kombiniert, um die Robustheit von Open-World-TTT im Rahmen eines Selbsttrainings-Frameworks zu verbessern
-
Zunächst bauen wir die Basislinie von TTT auf der selbst trainierten Variante auf, d. h. Clustering in der Zieldomäne mit dem Quelldomänen-Prototyp als Clusterzentrum. Um die Auswirkungen des Selbsttrainings auf starke OOD mit falschen Pseudo-Labels abzuschwächen, entwickeln wir eine hyperparameterfreie Methode zum Zurückweisen starker OOD-Proben.
Um die Eigenschaften schwacher OOD-Proben und starker OOD-Proben weiter zu trennen, ermöglichen wir die Erweiterung des Prototypenpools durch Auswahl isolierter starker OOD-Proben. Daher ermöglicht das Selbsttraining, dass starke OOD-Proben enge Cluster um den neu erweiterten starken OOD-Prototyp bilden. Dies erleichtert die Verteilungsausrichtung zwischen Quell- und Zieldomänen. Wir schlagen außerdem vor, das Selbsttraining durch eine globale Verteilungsausrichtung zu regulieren, um das Risiko einer Bestätigungsverzerrung zu verringern.
Um schließlich TTT-Szenarien in der offenen Welt zu synthetisieren, verwenden wir die Datensätze CIFAR10-C, CIFAR100-C, ImageNet-C, VisDA-C, ImageNet-R, Tiny-ImageNet, MNIST und SVHN und verwenden die Daten Der Satz ist ein schwacher OOD und die anderen sind ein starker OOD, um einen Benchmark-Datensatz zu erstellen. Wir bezeichnen diesen Benchmark als „Open World Test Segment Training Benchmark“ und hoffen, dass dies dazu anregt, dass sich künftig mehr Arbeiten auf die Robustheit des Testsegmenttrainings in realistischeren Szenarien konzentrieren.
Methode
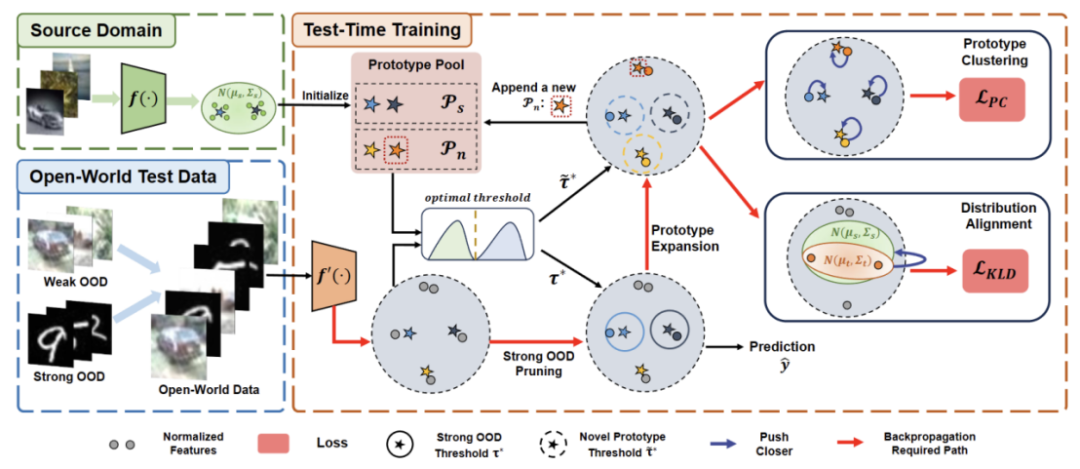
Das Papier unterteilt die vorgeschlagene Methode in vier Teile, um
1) Überblick über die Einstellung des Testsegments Trainingsaufgabe in der offenen Welt vorzustellen.
2) Beschreibt, wie TTT über Umschreiben des Inhalts als: Clusteranalyse implementiert wird und wie der Prototyp für Open-World-Testzeittraining erweitert wird.
3) Einführung in die Verwendung von Zieldomänendaten für die dynamische Prototypenerweiterung.
4) Einführung von Distribution Alignment in Kombination mit neu geschriebenen Inhalten: Clusteranalyse, um ein leistungsstarkes Open-World-Testzeittraining zu erreichen. Abbildung 2: Übersicht über die Methode relativ zur Verteilungsmigration der Quelldomäne. Im standardmäßigen Closed-World-TTT sind die Beschriftungsräume der Quell- und Zieldomänen gleich. Im Open-World-TTT enthält der Beschriftungsraum der Zieldomäne jedoch den Zielraum der Quelldomäne, was bedeutet, dass die Zieldomäne über bisher unbekannte neue semantische Kategorien verfügt
 Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist).
Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist). Umgeschriebener Inhalt als: Clusteranalyse
Inspiriert durch die Arbeit mit Clustering in Domänenanpassungsaufgaben [3,4] behandeln wir das Testsegmenttraining als Entdeckung von Clusterstrukturen in Zieldomänendaten. Durch die Identifizierung repräsentativer Prototypen als Clusterzentren werden Clusterstrukturen in der Zieldomäne identifiziert und Testproben werden dazu ermutigt, in der Nähe eines der Prototypen einzubetten. Der umgeschriebene Inhalt lautet: Das Ziel der Clusteranalyse besteht darin, den negativen Log-Likelihood-Verlust der Kosinusähnlichkeit zwischen der Stichprobe und dem Clusterzentrum zu minimieren, wie in der folgenden Formel dargestellt.
Wir entwickeln eine hyperparameterfreie Methode zum Herausfiltern starker OOD-Proben, um die negativen Auswirkungen der Anpassung der Modellgewichte zu vermeiden. Konkret definieren wir für jede Testprobe einen starken OOD-Score als höchste Ähnlichkeit zum Quelldomänen-Prototyp, wie in der folgenden Gleichung dargestellt.
Abbildung 3 Ausreißer zeigen eine bimodale Verteilung
Wir beobachten, dass die Ausreißer einer bimodalen Verteilung folgen, wie in Abbildung 3 dargestellt. Anstatt also einen festen Schwellenwert anzugeben, definieren wir den optimalen Schwellenwert als den besten Wert, der die beiden Verteilungen trennt. Konkret kann das Problem so formuliert werden, dass die Ausreißer in zwei Cluster aufgeteilt werden und der optimale Schwellenwert die Varianz innerhalb des Clusters minimiert. Die Optimierung der folgenden Gleichung kann effizient erreicht werden, indem alle möglichen Schwellenwerte von 0 bis 1 in Schritten von 0,01 umfassend durchsucht werden.
Dynamische Prototypenerweiterung
Die Erweiterung des Pools starker OOD-Prototypen erfordert die Berücksichtigung sowohl der Quelldomäne als auch des starken OOD-Prototyps zur Bewertung der Testbeispiele. Um die Anzahl der Cluster anhand von Daten dynamisch abzuschätzen, wurden in früheren Studien ähnliche Probleme untersucht. Der deterministische Hard-Clustering-Algorithmus DP-means [5] wurde entwickelt, indem der Abstand von Datenpunkten zu bekannten Clusterzentren gemessen wurde. Ein neuer Cluster wird initialisiert, wenn der Abstand über einem Schwellenwert liegt. DP-Means entspricht nachweislich der Optimierung des K-Means-Ziels, allerdings mit einem zusätzlichen Nachteil bei der Anzahl der Cluster, was eine praktikable Lösung für die dynamische Prototypenerweiterung darstellt.
Um die Schwierigkeit der Schätzung zusätzlicher Hyperparameter zu verringern, definieren wir zunächst eine Teststichprobe mit einem erweiterten starken OOD-Score als den nächsten Abstand zum vorhandenen Quelldomänen-Prototyp und dem starken OOD-Prototyp wie folgt. Daher wird durch das Testen von Proben über diesem Schwellenwert ein neuer Prototyp erstellt. Um das Hinzufügen von Testmustern in der Nähe zu vermeiden, wiederholen wir diesen Prototypenerweiterungsprozess schrittweise.
Nachdem wir weitere starke OOD-Prototypen identifiziert hatten, definierten wir die Umschreibung für das Testbeispiel wie folgt: Verlust der Clusteranalyse unter Berücksichtigung von zwei Faktoren. Erstens sollten in bekannte Klassen klassifizierte Testmuster näher an Prototypen und weiter entfernt von anderen Prototypen eingebettet werden, was die K-Klassen-Klassifizierungsaufgabe definiert. Zweitens sollten als starke OOD-Prototypen klassifizierte Testproben weit entfernt von Prototypen der Quelldomäne sein, was die K+1-Klassenklassifizierungsaufgabe definiert. Mit diesen Zielen vor Augen werden wir den Inhalt wie folgt umschreiben: Der Verlust der Clusteranalyse wird wie folgt definiert.
Einschränkungen bei der verteilten Ausrichtung bedeuten, dass in einem Design oder Layout Elemente auf eine bestimmte Weise angeordnet und ausgerichtet werden müssen. Diese Einschränkung kann auf eine Vielzahl verschiedener Szenarien angewendet werden, darunter Webdesign, Grafikdesign und Raumlayout. Durch die Verwendung verteilter Ausrichtungsbeschränkungen kann die Beziehung zwischen Elementen klarer und einheitlicher gestaltet werden, wodurch die Ästhetik und Lesbarkeit des Gesamtdesigns verbessert wird
Es ist bekannt, dass Selbsttraining anfällig für fehlerhafte Pseudobezeichnungen ist. Die Situation wird noch schlimmer, wenn die Zieldomäne aus OOD-Proben besteht. Um das Risiko eines Ausfalls zu verringern, verwenden wir außerdem die Verteilungsausrichtung [1] wie folgt als Regularisierung für das Selbsttraining.
Experimente
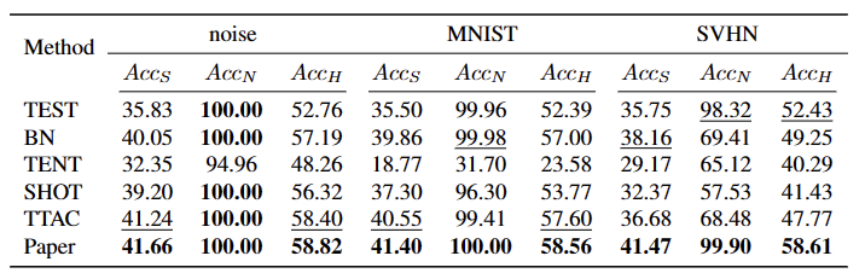
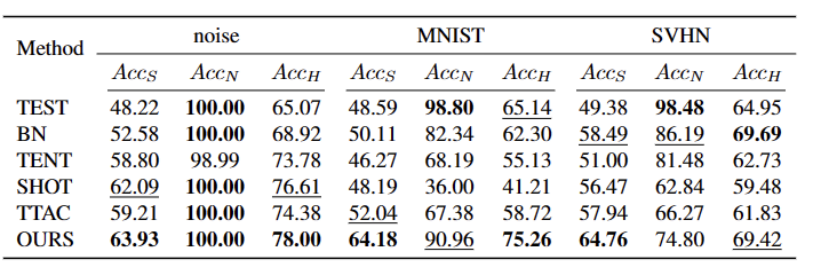
Wir haben fünf verschiedene OWTTT-Benchmark-Datensätze getestet, darunter synthetisch beschädigte Datensätze und stilvariierende Datensätze. Das Experiment verwendet hauptsächlich drei Bewertungsindikatoren: schwache OOD-Klassifizierungsgenauigkeit ACCS, starke OOD-Klassifizierungsgenauigkeit ACCN und das harmonische Mittel der beiden ACCH Die Leistung der Methode ist in der folgenden Tabelle aufgeführt. Der Inhalt, der neu geschrieben werden muss, ist: Die Leistung verschiedener Methoden im Cifar100-C-Datensatz ist in der folgenden Tabelle aufgeführt: Der Inhalt, der neu geschrieben werden muss, ist: Im ImageNet-C-Datensatz ist die Leistung verschiedener Methoden in der folgenden Tabelle dargestellt
Tabelle 4 Leistung verschiedener Methoden beim ImageNet-R-Datensatz
Tabelle 5 Leistung verschiedener Methoden beim VisDA-C-Datensatz
Unsere Methode ist bei fast allen Daten konsistent Sets Im Vergleich zu den derzeit besten Methoden gibt es erhebliche Verbesserungen, wie in der obigen Tabelle gezeigt. Es kann starke OOD-Proben effektiv identifizieren und die Auswirkungen auf die Klassifizierung schwacher OOD-Proben verringern. Daher kann unsere Methode im Open-World-Szenario eine robustere TTT erreichen Bei der Verarbeitung von Zieldomänendaten, die starke OOD-Proben enthalten, die semantische Offsets von Quelldomänenproben aufweisen, wird eine selbstlernende Methode vorgeschlagen, die auf der dynamischen Prototypenerweiterung basiert. Wir hoffen, dass diese Arbeit neue Wege für die nachfolgende TTT-Forschung bieten kann, um robustere TTT-Methoden zu erforschen
 Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist).
Um Verwechslungen zwischen TTT-Definitionen zu vermeiden, übernehmen wir diese TTAC [2 Das in vorgeschlagene sTTT-Protokoll (Sequential Test Time Training)] wird evaluiert. Im Rahmen des sTTT-Protokolls werden Testproben nacheinander getestet und Modellaktualisierungen nach Beobachtung kleiner Testprobenchargen durchgeführt. Die Vorhersage für jede Testprobe, die zum Zeitstempel t ankommt, wird nicht von jeder Testprobe beeinflusst, die zum Zeitpunkt t+k ankommt (deren k größer als 0 ist). 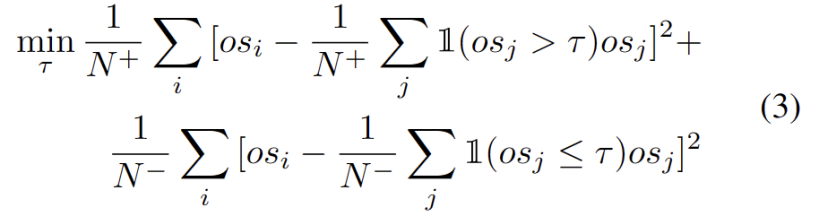
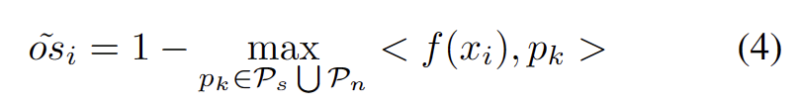
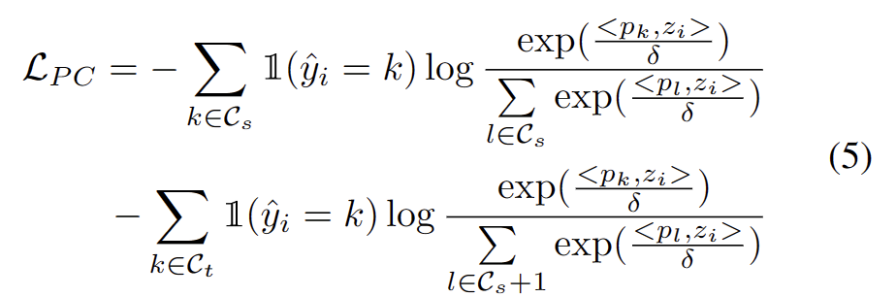
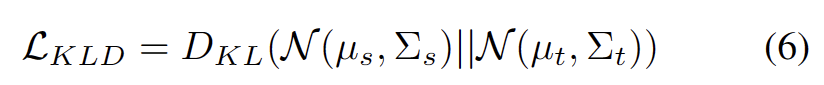
Das obige ist der detaillierte Inhalt vonEntdecken Sie Trainingstechniken für Open-World-Testsegmente mithilfe von Selbsttrainingsmethoden mit dynamischen Prototyping-Erweiterungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Was halten Sie von Furmark? - Wie wird Furmark als qualifiziert angesehen?
Mar 19, 2024 am 09:25 AM
Was halten Sie von Furmark? - Wie wird Furmark als qualifiziert angesehen?
Mar 19, 2024 am 09:25 AM
Was halten Sie von Furmark? 1. Stellen Sie den „Ausführungsmodus“ und den „Anzeigemodus“ in der Hauptoberfläche ein, passen Sie auch den „Testmodus“ an und klicken Sie auf die Schaltfläche „Start“. 2. Nach einer Weile sehen Sie die Testergebnisse, darunter verschiedene Parameter der Grafikkarte. Wie wird Furmark qualifiziert? 1. Verwenden Sie eine Furmark-Backmaschine und überprüfen Sie das Ergebnis etwa eine halbe Stunde lang. Die Temperatur liegt im Wesentlichen bei etwa 85 Grad, mit einem Spitzenwert von 87 Grad und einer Raumtemperatur von 19 Grad. Großes Gehäuse, 5 Gehäuselüfteranschlüsse, zwei vorne, zwei oben und einer hinten, aber nur ein Lüfter ist installiert. Sämtliches Zubehör ist nicht übertaktet. 2. Unter normalen Umständen sollte die normale Temperatur der Grafikkarte zwischen „30-85℃“ liegen. 3. Auch wenn die Umgebungstemperatur im Sommer zu hoch ist, beträgt die normale Temperatur „50-85℃“
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
 Nehmen Sie an einem neuen Xianxia-Abenteuer teil! Der Vorab-Download von „Zhu Xian 2' „Wuwei Test' ist jetzt verfügbar
Apr 22, 2024 pm 12:50 PM
Nehmen Sie an einem neuen Xianxia-Abenteuer teil! Der Vorab-Download von „Zhu Xian 2' „Wuwei Test' ist jetzt verfügbar
Apr 22, 2024 pm 12:50 PM
Der „Inaction Test“ des neuen Fantasy-Märchen-MMORPG „Zhu Xian 2“ startet am 23. April. Was für eine neue Märchen-Abenteuergeschichte wird auf dem Kontinent Zhu Die Six Realm Immortal World, eine Vollzeitakademie zur Kultivierung von Unsterblichen, ein freies Leben zur Kultivierung von Unsterblichen und jede Menge Spaß in der Welt der Unsterblichen warten darauf, von den unsterblichen Freunden persönlich erkundet zu werden! Der Vorab-Download von „Wuwei Test“ ist jetzt möglich. Sie können sich zum Herunterladen auf die offizielle Website begeben. Der Aktivierungscode kann nach dem Vorab-Download und der Installation verwendet werden abgeschlossen. „Zhu Als Blaupause wird der Spielhintergrund festgelegt
