
 Technologie-Peripheriegeräte
KI
DeepMind hat herausgefunden, dass die schnelle Methode, großen Modellen „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen' zu vermitteln, äußerst effektiv ist.
Technologie-Peripheriegeräte
KI
DeepMind hat herausgefunden, dass die schnelle Methode, großen Modellen „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen' zu vermitteln, äußerst effektiv ist.
DeepMind hat herausgefunden, dass die schnelle Methode, großen Modellen „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen' zu vermitteln, äußerst effektiv ist.

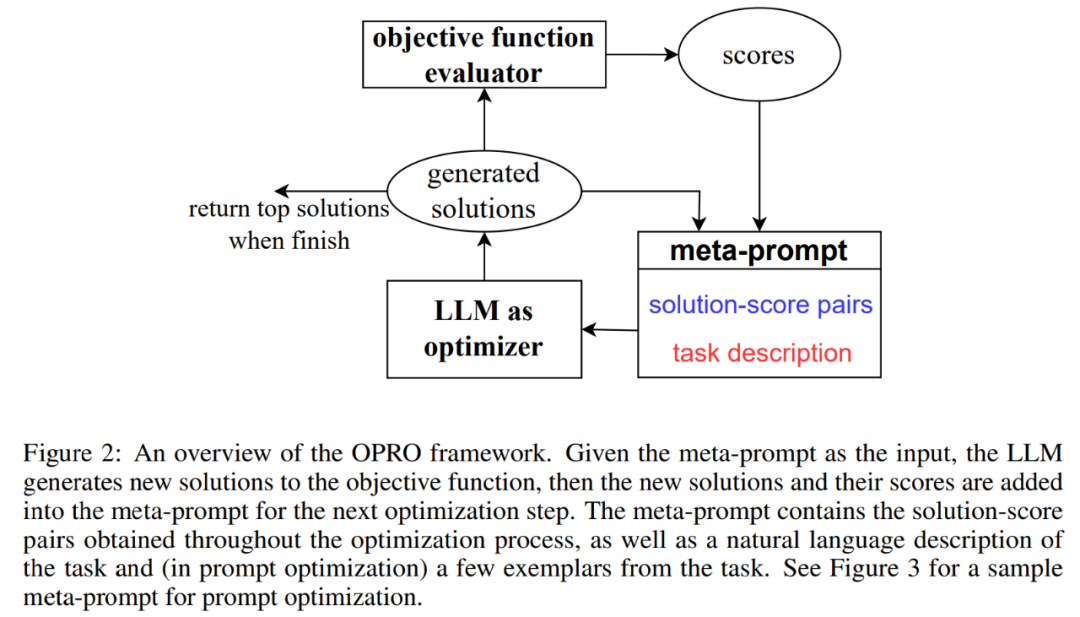
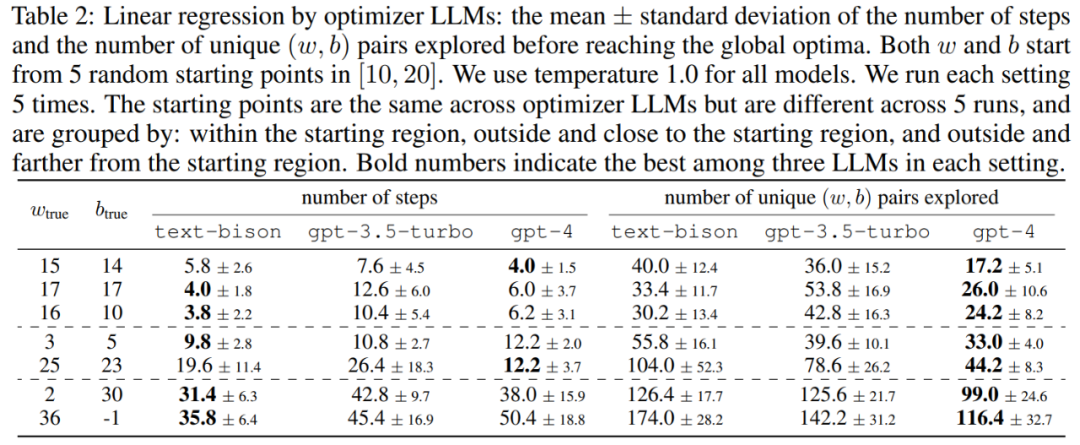
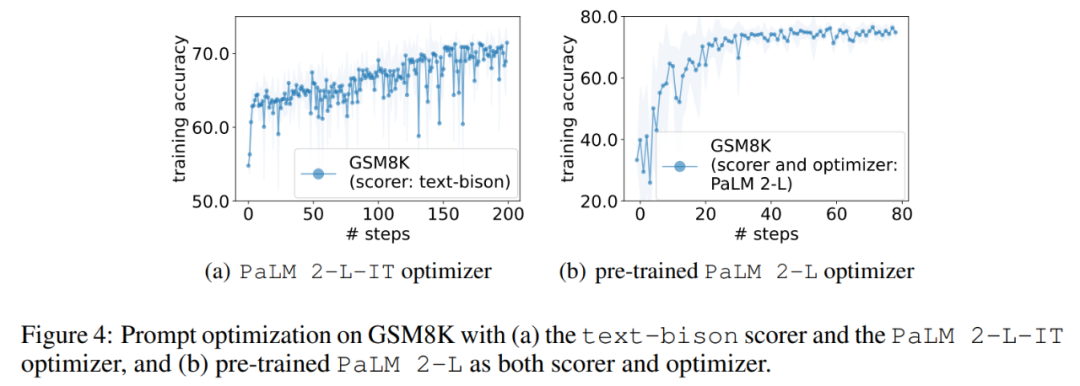
Dieser Artikel schlägt eine einfache und effektive Methode OPRO vor, die ein großes Sprachmodell als Optimierer verwendet. Die Optimierungsaufgabe kann in natürlicher Sprache beschrieben werden, was besser ist als die von Menschen entworfenen Eingabeaufforderungen.

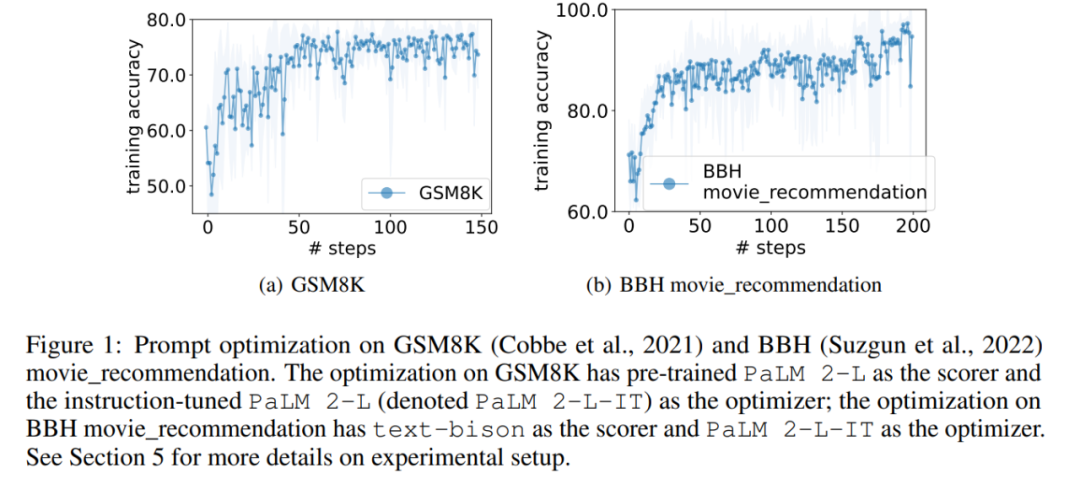
Einige Forscher sagten jedoch: „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen.“ Dieser Tipp ist auf Googles PaLM-2 (Genauigkeitsrate 80,2) sehr effektiv. Wir können jedoch nicht garantieren, dass es bei allen Modellen und in allen Situationen funktioniert, daher sollten wir es nicht überall blind verwenden. 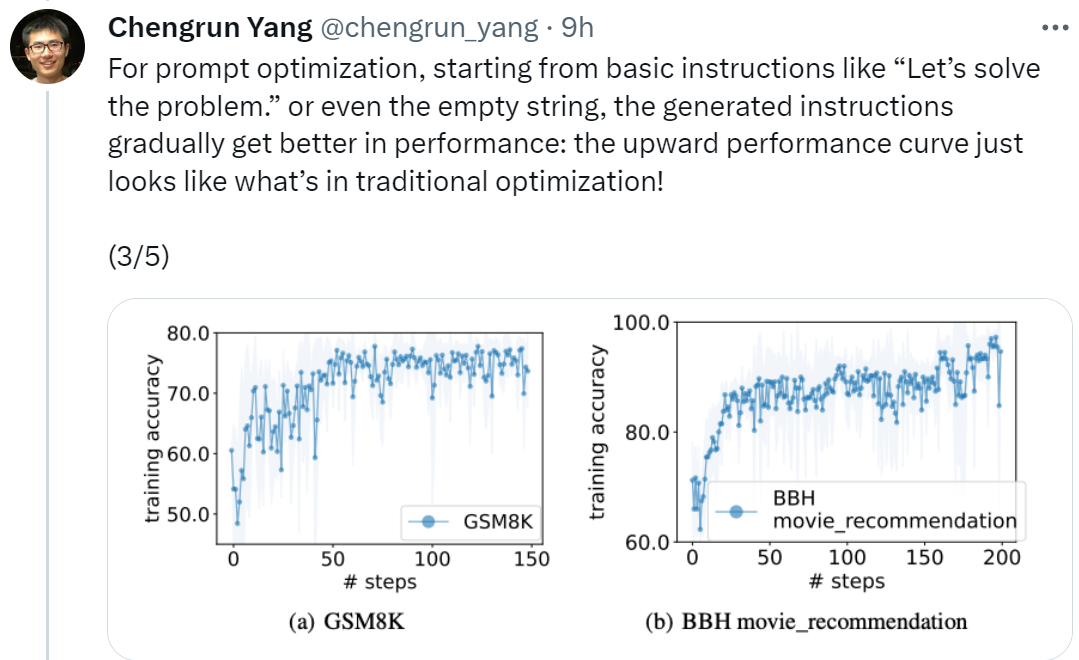


Das obige ist der detaillierte Inhalt vonDeepMind hat herausgefunden, dass die schnelle Methode, großen Modellen „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen' zu vermitteln, äußerst effektiv ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Herausgeber | ScienceAI Basierend auf begrenzten klinischen Daten wurden Hunderte medizinischer Algorithmen genehmigt. Wissenschaftler diskutieren darüber, wer die Werkzeuge testen soll und wie dies am besten geschieht. Devin Singh wurde Zeuge, wie ein pädiatrischer Patient in der Notaufnahme einen Herzstillstand erlitt, während er lange auf eine Behandlung wartete, was ihn dazu veranlasste, den Einsatz von KI zu erforschen, um Wartezeiten zu verkürzen. Mithilfe von Triage-Daten aus den Notaufnahmen von SickKids erstellten Singh und Kollegen eine Reihe von KI-Modellen, um mögliche Diagnosen zu stellen und Tests zu empfehlen. Eine Studie zeigte, dass diese Modelle die Zahl der Arztbesuche um 22,3 % verkürzen können und die Verarbeitung der Ergebnisse pro Patient, der einen medizinischen Test benötigt, um fast drei Stunden beschleunigt. Der Erfolg von Algorithmen der künstlichen Intelligenz in der Forschung bestätigt dies jedoch nur
