

VLDB 2023 International Conference wurde erfolgreich in Vancouver, Kanada, abgehalten. Die VLDB-Konferenz ist eine der drei Top-Konferenzen mit einer langen Geschichte im Datenbankbereich. Ihr vollständiger Name ist „International Large-Scale Database Conference“. Der Schwerpunkt jeder Konferenz liegt auf der Darstellung der aktuellen Spitzenrichtungen der Datenbankforschung, der neuesten Technologien in der Branche sowie des F&E-Niveaus verschiedener Länder und zieht Einreichungen von weltweit führenden Forschungseinrichtungen an

Die Konferenz konzentriert sich auf Systeminnovation, Vollständigkeit und experimentelles Design In anderen Aspekten werden äußerst hohe Anforderungen gestellt. Die Annahmequote von VLDB ist im Allgemeinen niedrig und liegt bei etwa 18 %. Es ist wahrscheinlich, dass nur Arbeiten mit großartigen Beiträgen angenommen werden. Der Wettbewerb ist dieses Jahr noch härter. Nach offiziellen Angaben gewannen in diesem Jahr insgesamt 9 VLDB-Artikel den Best Paper Award, darunter solche von der Stanford University, der Carnegie Mellon University, Microsoft Research, VMware Research, Meta und anderen weltbekannten Universitäten, Forschungseinrichtungen und Technologiegiganten Für sie gewann das von 4Paradigm, der Tsinghua University und der National University of Singapore gemeinsam erstellte Papier „FEBench: A Benchmark for Real-Time Relational Data Feature Extraction“ den zweiten Preis für das beste Industriepapier.
 Dieses Papier ist eine Zusammenarbeit zwischen 4Paradigm, der Tsinghua University und der National University of Singapore. Das Papier schlägt einen Benchmark für Echtzeit-Funktionsberechnungstests vor, der auf der Anhäufung realer Szenarien in der Branche basiert und zur Bewertung von Echtzeit-Entscheidungssystemen basierend auf maschinellem Lernen verwendet wird. Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https ://github.com/decis -bench/febench/blob/main/report/febench.pdf
Dieses Papier ist eine Zusammenarbeit zwischen 4Paradigm, der Tsinghua University und der National University of Singapore. Das Papier schlägt einen Benchmark für Echtzeit-Funktionsberechnungstests vor, der auf der Anhäufung realer Szenarien in der Branche basiert und zur Bewertung von Echtzeit-Entscheidungssystemen basierend auf maschinellem Lernen verwendet wird. Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https ://github.com/decis -bench/febench/blob/main/report/febench.pdf
Projektadresse: https://github.com/decis-bench/febench
Der Inhalt, der neu geschrieben werden muss, lautet: Die Projektadresse lautet https://github.com/decis-bench/febench
Projekthintergrund
Umgeschriebener Inhalt: Abbildung 1. Anwendung der Echtzeit-Feature-Berechnung in Anti-Betrugs-Anwendungen
Im Allgemeinen muss eine Echtzeit-Feature-Berechnungsplattform die folgenden zwei Grundanforderungen erfüllen:
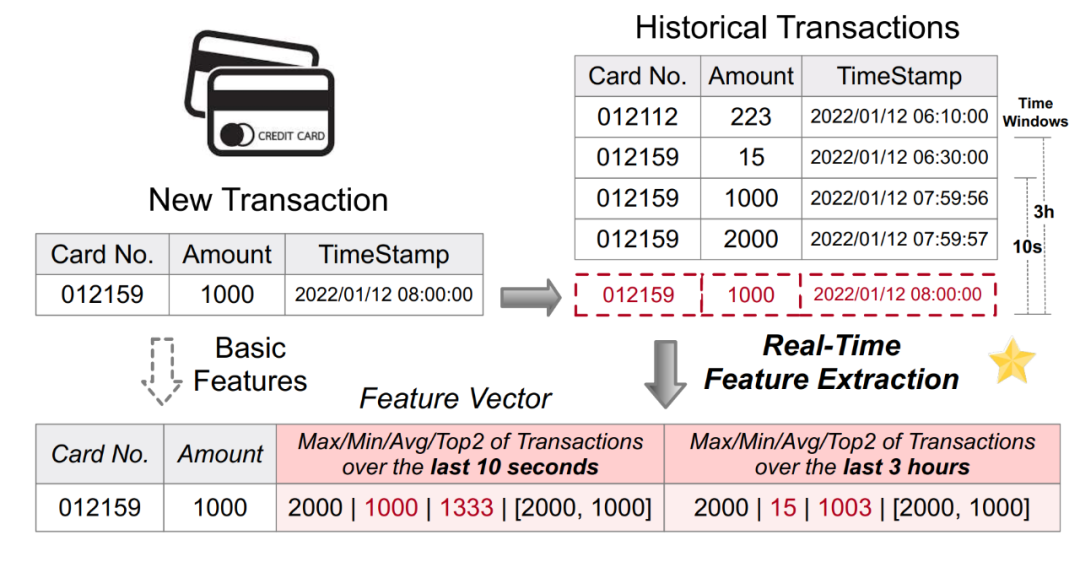
Effizienz von Onlinediensten: Onlinedienste zielen auf Echtzeitdaten und -berechnungen ab und erfüllen die Anforderungen an geringe Latenz, hohe Parallelität und hohe Verfügbarkeit.
 Technisches Prinzip
Technisches Prinzip
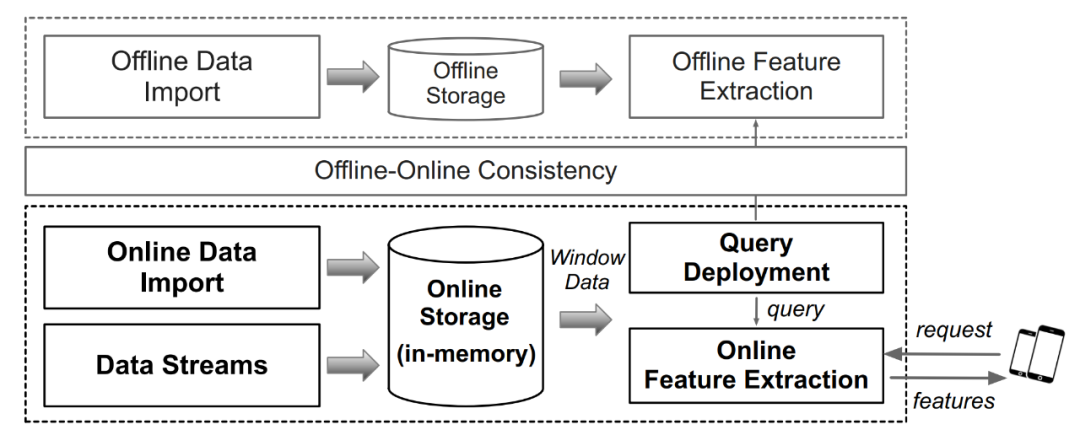
Die Benchmark-Konstruktion von FEBench umfasst hauptsächlich drei Aspekte der Arbeit: Datensatzerfassung, durch Abfrage generierte Inhalte müssen neu geschrieben werden, und wenn der Inhalt neu geschrieben wird, müssen geeignete Vorlagen ausgewählt werden
Datensatzsammlung
Das Forschungsteam hat insgesamt 118 Datensätze gesammelt, die in Echtzeit-Feature-Berechnungsszenarien verwendet werden können. Diese Datensätze stammen von öffentlichen Daten-Websites wie Kaggle, Tianchi, UCI ML, KiltHub und interne öffentliche Daten innerhalb des vierten Paradigmas, die typische Nutzungsszenarien in der Industriewelt abdecken, wie z. B. Finanz-, Einzelhandels-, Medizin-, Fertigungs-, Transport- und andere Branchenszenarien. Das Forschungsteam klassifizierte die gesammelten Datensätze weiter nach der Anzahl der Tabellen und der Datensatzgröße, wie in Abbildung 3 unten dargestellt.
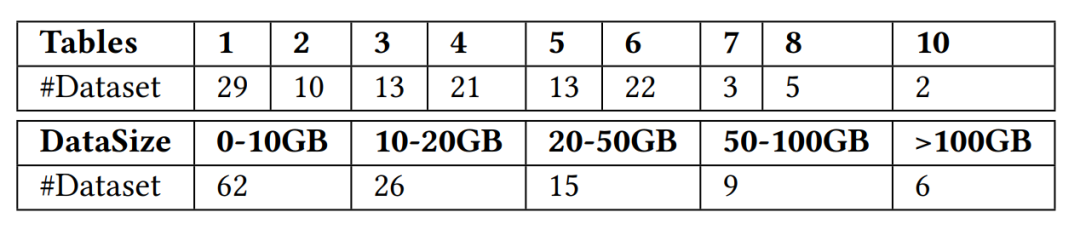
Umgeschriebener Inhalt: Das Diagramm der Anzahl der Tabellen und der Größe des Datensatzes in FEBench sieht wie folgt aus:
Der durch die Abfrage generierte Inhalt muss neu geschrieben werden
Aufgrund der Größe Anzahl der Datensätze für jede Datenmenge. Der Rechenaufwand für die Berechnungslogik der manuell generierten Merkmalsextraktion ist sehr groß, daher verwendeten die Forscher automatische maschinelle Lerntechnologien wie AutoCross (Referenzpapier: AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications). Um die gesammelten Daten mit Set bereitzustellen, werden automatisch Abfragen generiert. Die Funktionsauswahl und der durch Abfragen generierte Inhalt von FEBench müssen neu geschrieben werden. Der Prozess umfasst die folgenden vier Schritte (wie in Abbildung 4 unten dargestellt):
Durch Identifizieren der Haupttabelle (Speichern von Streaming-Daten) und Hilfstabellen (z. B. statisch). /Append/Snapshot-Tabelle) kann initialisiert werden. Anschließend werden Spalten mit ähnlichen Namen oder Schlüsselbeziehungen in der Primär- und Sekundärtabelle analysiert und Eins-zu-eins/Eins-zu-viele-Beziehungen zwischen Spalten aufgezählt, die unterschiedlichen Funktionsbetriebsmodi entsprechen.
Spaltenbeziehungen Feature-Operatoren zuordnen.
Nachdem alle Kandidatenfunktionen extrahiert wurden, wird der Beam-Suchalgorithmus verwendet, um iterativ einen effektiven Funktionssatz zu generieren.
Ausgewählte Features werden in semantisch äquivalente SQL-Abfragen umgewandelt. Abbildung 4: Prozess der Abfragegenerierung in FEBench Wählen Sie repräsentative Abfragen als Abfragevorlagen aus, um wiederholte Tests ähnlicher Aufgaben zu reduzieren. Verwenden Sie für die gesammelten 118 Datensätze und Feature-Abfragen den DBSCAN-Algorithmus, um diese Abfragen zu gruppieren. Die spezifischen Schritte lauten wie folgt:
Teilen Sie die Features jeder Abfrage in fünf Teile: die Anzahl der Ausgabespalten, die Gesamtzahl der Abfrageoperatoren, die Häufigkeit des Auftretens komplexer Operatoren, die Anzahl der verschachtelten Unterabfrageebenen und die Anzahl der maximalen Tupel im Zeitfenster. Da Feature-Engineering-Abfragen in der Regel Zeitfenster umfassen und die Komplexität der Abfragen nicht durch die Batch-Datengröße beeinflusst wird, wird die Datensatzgröße nicht als eines der Clustering-Features berücksichtigt. 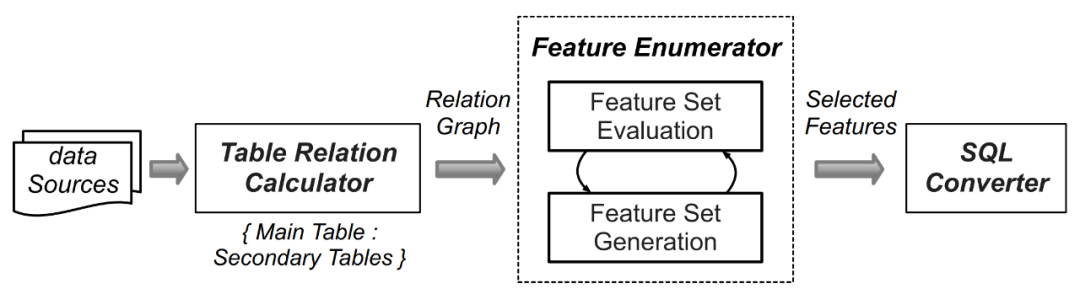
Verwenden Sie ein logistisches Regressionsmodell, um die Beziehung zwischen Abfragemerkmalen und Abfrageausführungsmerkmalen zu bewerten, indem Sie die Merkmale als Eingabe des Modells und die Ausführungszeit der Merkmalsabfrage als Ausgabe des Modells verwenden. Die Bedeutung verschiedener Merkmale für die Clustering-Ergebnisse wird berücksichtigt, indem das Regressionsgewicht jedes Features als Clustering-Gewicht verwendet wird.
Basierend auf den gewichteten Abfragemerkmalen wird der DBSCAN-Algorithmus verwendet, um die Merkmalsabfrage in mehrere Cluster aufzuteilen.
Das folgende Diagramm zeigt die Verteilung von 118 Datensätzen unter verschiedenen Betrachtungsindikatoren. Abbildung (a) zeigt die Indikatoren statistischer Natur, einschließlich der Anzahl der Ausgabespalten, der Gesamtzahl der Abfrageoperatoren und der Anzahl der verschachtelten Unterabfrageebenen. Abbildung (b) zeigt die Indikatoren mit der höchsten Korrelation zur Abfrageausführungszeit, einschließlich der Anzahl der Aggregationsvorgänge, Anzahl der verschachtelten Unterabfrageebenen und Anzahl der Zeitfenster Zu den Clustering-Ergebnissen wurden die 118 Funktionsabfragen in 6 Cluster unterteilt. Für jeden Cluster werden Abfragen in der Nähe des Schwerpunkts als Kandidatenvorlagen ausgewählt. Angesichts der Tatsache, dass Anwendungen für künstliche Intelligenz in verschiedenen Anwendungsszenarien möglicherweise unterschiedliche Anforderungen an das Feature-Engineering haben, versuchen Sie außerdem, Abfragen aus verschiedenen Szenarien rund um den Schwerpunkt jedes Clusters auszuwählen, um unterschiedliche Feature-Engineering-Szenarien besser abzudecken. Schließlich wurden aus 118 Funktionsabfragen 6 Abfragevorlagen ausgewählt, die für verschiedene Szenarien geeignet sind, darunter Transport, Gesundheitswesen, Energie, Vertrieb und Finanztransaktionen. Diese sechs Abfragevorlagen bilden letztendlich die Kerndatensätze und Abfragen von FEBench, die für Leistungstests der Echtzeit-Feature-Berechnungsplattform verwendet werden.Was neu geschrieben werden muss, ist: Benchmark-Bewertung (OpenMLDB und Flink)
In der Studie testeten die Forscher mit FEBench zwei typische Industriesysteme, nämlich Flink und OpenMLDB. Flink ist eine allgemeine Batch- und Stream-Verarbeitungs-Konsistenz-Computing-Plattform, während OpenMLDB eine dedizierte Echtzeit-Feature-Computing-Plattform ist. Durch Tests und Analysen entdeckten die Forscher die Vor- und Nachteile jedes Systems und die Gründe dafür. Experimentelle Ergebnisse zeigen, dass es aufgrund unterschiedlicher Architekturdesigns Leistungsunterschiede zwischen Flink und OpenMLDB gibt. Gleichzeitig verdeutlicht dies auch die Bedeutung von FEBench bei der Analyse der Fähigkeiten des Zielsystems. Zusammenfassend lauten die wichtigsten Schlussfolgerungen der Studie:
Flink ist in der Latenz zwei Größenordnungen langsamer als OpenMLDB (Abbildung 6). Die Forscher analysierten, dass der Hauptgrund für die Lücke in den unterschiedlichen Implementierungsmethoden der beiden Systemarchitekturen liegt, da OpenMLDB als dediziertes System zur Echtzeit-Feature-Berechnung speicherbasierte Doppelschicht-Sprungtabellen und andere zeitoptimierte Datenstrukturen umfasst Letztendlich bietet es im Vergleich zu Flink offensichtliche Leistungsvorteile in Feature-Berechnungsszenarien. Als Allzwecksystem verfügt Flink natürlich über ein breiteres Spektrum an anwendbaren Szenarien als OpenMLDB.
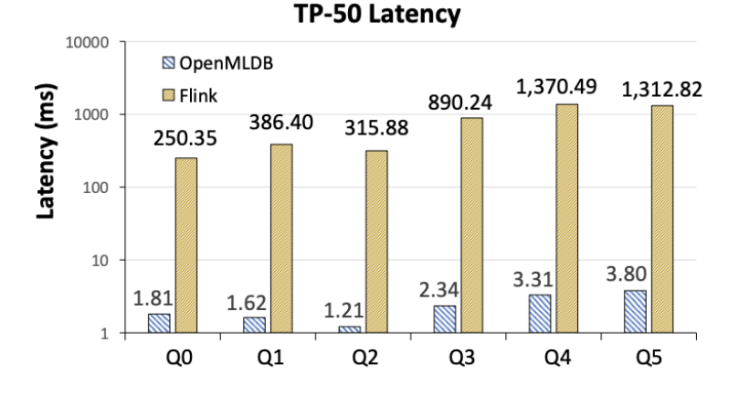
Abbildung 6. TP-50-Latenzvergleich zwischen OpenMLDB und Flink
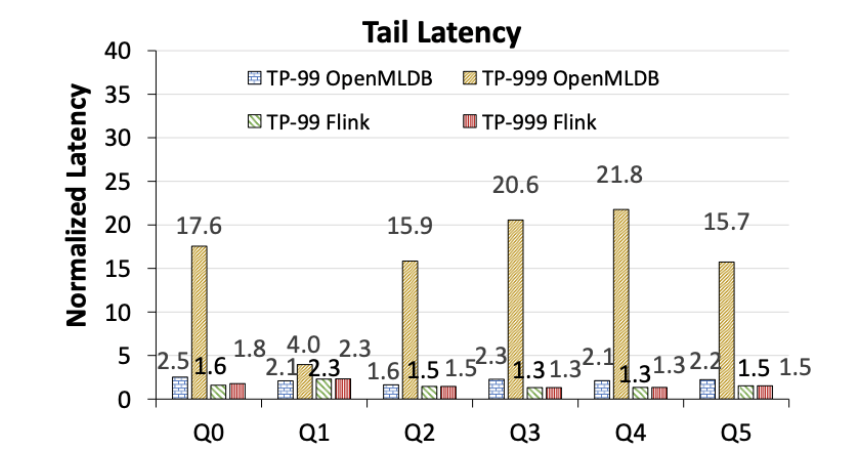
OpenMLDB weist offensichtliche Long-Tail-Latenzprobleme auf, während die Tail-Latenz von Flink stabiler ist (Abbildung 7). Beachten Sie, dass die folgenden Zahlen die Latenzleistung normalisiert auf OpenMLDB und Flinks jeweiliges TP-50 zeigen und keine absoluten Leistungsvergleiche darstellen. Umgeschrieben als: OpenMLDB hat offensichtliche Probleme mit der Tail-Latenz, während die Tail-Latenz von Flink stabiler ist (siehe Abbildung 7). Es ist zu beachten, dass die folgenden Zahlen die Latenzleistung auf die Leistung von OpenMLDB bzw. Flink unter TP-50 normalisieren und keinen Vergleich der absoluten Leistung darstellen. Abbildung 7: Das Ende von OpenMLDB und Flink Latenzvergleich (normalisiert auf die jeweilige TP-50-Latenz)
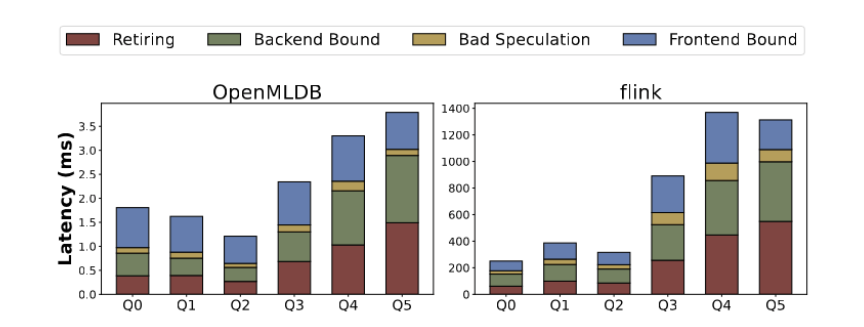
Teardown-Analyse basierend auf der Ausführungszeit, mikroarchitektonischen Indikatoren umfassen den Abschluss von Anweisungen, Fehler, Verzweigungsvorhersage usw -End-Abhängigkeiten, Front-End-Abhängigkeiten usw. Verschiedene Abfragevorlagen weisen unterschiedliche Leistungsengpässe auf Mikrostrukturebene auf. Wie in Abbildung 8 dargestellt, hängt der Leistungsengpass von Q0-Q2 hauptsächlich vom Front-End ab und macht mehr als 45 % der gesamten Laufzeit aus. In diesem Fall sind die durchgeführten Vorgänge relativ einfach und die meiste Zeit wird für die Verarbeitung von Benutzeranfragen und den Wechsel zwischen Anweisungen zur Merkmalsextraktion aufgewendet. Für Q3-Q5 werden Backend-Abhängigkeiten (z. B. Cache-Ungültigmachung) und die Befehlsausführung (einschließlich komplexerer Befehle) wichtigere Faktoren. OpenMLDB macht die Leistung durch gezielte Optimierung noch besser. Abbildung 8 zeigt die Mikroarchitektur-Indikatoranalyse von OpenMLDB und Flink Unterschiede in den Ausführungsplänen zwischen Flink und OpenMLDB. Rechenoperatoren in Flink nehmen die meiste Zeit in Anspruch, während OpenMLDB die Ausführungslatenz reduziert, indem es die Fensterung optimiert und Optimierungstechniken wie benutzerdefinierte Aggregatfunktionen verwendet.
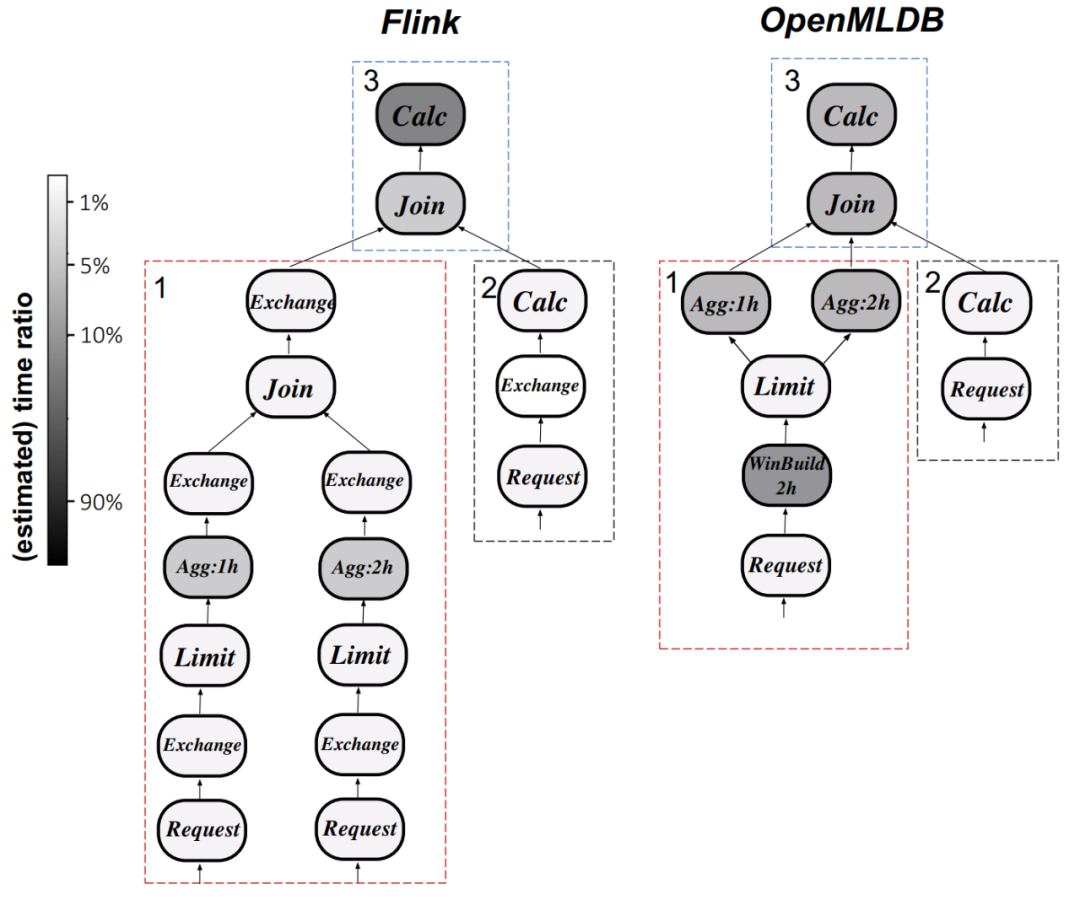
Das neunte Bild zeigt den Vergleich zwischen OpenMLDB und Flink in Bezug auf den Ausführungsplan (Q0)
FEBench-Projekt: https://github.com/decis-bench/febench
Das obige ist der detaillierte Inhalt vonBei der Bekanntgabe der VLDB 2023-Auszeichnungen gewann ein gemeinsames Papier der Tsinghua-Universität, 4Paradigm und NUS den Best Industrial Paper Award. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Spot-Trading-Software
Spot-Trading-Software
 Mindestkonfigurationsanforderungen für das Win10-System
Mindestkonfigurationsanforderungen für das Win10-System
 Oracle-Datenbank, die die SQL-Methode ausführt
Oracle-Datenbank, die die SQL-Methode ausführt
 Werden Sols-Inschriftenmünzen auf Null zurückkehren?
Werden Sols-Inschriftenmünzen auf Null zurückkehren?
 Zu den Kerntechnologien des Big-Data-Analysesystems gehören:
Zu den Kerntechnologien des Big-Data-Analysesystems gehören:
 So ändern Sie C-Sprachsoftware auf Chinesisch
So ändern Sie C-Sprachsoftware auf Chinesisch
 Was sind die Java-Texteditoren?
Was sind die Java-Texteditoren?
 So machen Sie den Hintergrund in PS transparent
So machen Sie den Hintergrund in PS transparent








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



