
 Technologie-Peripheriegeräte
KI
Apache IoTDB: eine innovative Datenbank, die Speicher-, Abfrage- und Nutzungsprobleme in industriellen IoT-Szenarien löst
Technologie-Peripheriegeräte
KI
Apache IoTDB: eine innovative Datenbank, die Speicher-, Abfrage- und Nutzungsprobleme in industriellen IoT-Szenarien löst
Apache IoTDB: eine innovative Datenbank, die Speicher-, Abfrage- und Nutzungsprobleme in industriellen IoT-Szenarien löst

Mit dem Eintritt in die Industrie 4.0-Ära und der Einführung von Digitalisierung und Automatisierung wird die Produktionsumgebung effizienter. Gleichzeitig beginnen die Menschen, auf den potenziellen Wert der riesigen Datenmengen zu achten, die von intelligenten Geräten bereitgestellt werden. Allerdings ist es zu einem Problem geworden, die von intelligenten Geräten generierten Daten effizient zu speichern und die riesigen Datenmengen besser zu analysieren. Herkömmliche Datenbankmodelle und Speichermethoden können diese Anforderungen nicht mehr erfüllen. Daher entstand die Zeitreihendatenbank entsprechend den Anforderungen der Zeit mit dem Ziel, eine effiziente Datenspeicherung und -abfrage zu erreichen und dabei zu helfen, den potenziellen Wert von Daten besser zu erkunden.
Angesichts dieser Situation startete die Tsinghua-Universität 2015 die Entwicklung von IoTDB. Am 23. September 2020 schloss Apache IoTDB ab und wurde zum Apache Top-Level-Projekt. Es ist derzeit das einzige Top-Level-Projekt der Apache Foundation, das von chinesischen Universitäten initiiert wurde, und auch das einzige Open-Source-Projekt im Bereich der Datenverwaltung im Internet der Dinge unter der Apache Foundation. Im Oktober 2021 gründete das Kernteam von Apache IoTDB Tianmou Technology und betreibt IoTDB weiterhin, um Industrieanwendern dabei zu helfen, die Probleme des „Speicherns, Überprüfens und Verwendens“ von Daten zu lösen. Bezüglich der von Apache IoTDB entwickelten Kerntechnologie haben mehrere Teilnehmer gemeinsam ein Review-Paper veröffentlicht, in dem das Design von IoTDB ausführlich und vollständig erläutert wird. Der Artikel nimmt als Beispiel ein Industrieunternehmen, das zehntausende Bagger verwalten muss, und beschreibt die Anforderungen: „Die Daten werden zunächst in das Gerät gepackt und dann über das 5G-Mobilfunknetz an den Server gesendet. Im Server werden die Daten werden für OLTP-Abfragen in die Zeitreihendatenbank geschrieben. Schließlich können Datenwissenschaftler Daten aus der Datenbank für komplexe Analysen und Vorhersagen laden, d. h. für OLAP-Aufgaben
Projektadresse: https://github.com/apache/iotdb

- Der Schwerpunkt des Papiers umfasst die folgenden Teile:
- 1. Design des Datenmodells: Organisation von Zeitreihen auf logischer Ebene und Speicherung im physischen Modus; usw.;
3. IoTDB-Engine:
Beinhaltet hauptsächlich Speicher-Engine, Abfrage-Engine usw.;
Die verteilte Lösung bezieht sich auf die Zerlegung einer Aufgabe oder eines Problems Unteraufgaben erstellen und diese Unteraufgaben mehreren Computern oder Knoten zur Verarbeitung zuweisen. Diese Lösung verbessert die Systemzuverlässigkeit, Skalierbarkeit und Leistung. Durch die Verteilung von Aufgaben auf mehrere Computer kann die Belastung eines einzelnen Computers verringert und die gleichzeitige Verarbeitungsfähigkeit des Systems verbessert werden. Gleichzeitig können verteilte Lösungen durch redundantes Backup und Failover auch die Fehlertoleranz des Systems erhöhen. Selbst wenn ein Knoten ausfällt, kann das System weiterlaufen. In der heutigen Big-Data- und Cloud-Computing-Umgebung sind verteilte Lösungen zu einem gängigen Architekturmuster geworden und werden häufig in verschiedenen Bereichen eingesetzt, beispielsweise in verteilten Datenbanken, verteilten Speichersystemen und verteilten Computerplattformen usw.Für das Folgende Inhaltlich werden wir eine detailliertere Interpretation dieser Schlüsselteile geben.
Detaillierte Interpretation. Erfordert Datenmodelldesign. Intensitätsschreibvorgänge und können das häufige Problem der verzögerten Datenankunft in IoT-Szenarien effektiv bewältigen. In der Baumstruktur stellt jeder Blattknoten einen Sensor dar, und jeder Blattknoten stellt einen Sensor dar. Jeder Sensor verfügt über ein entsprechendes Gerät. Wie in den unteren beiden Ebenen der Abbildung dargestellt, gilt das Gleiche auch für die oberen Ebenen
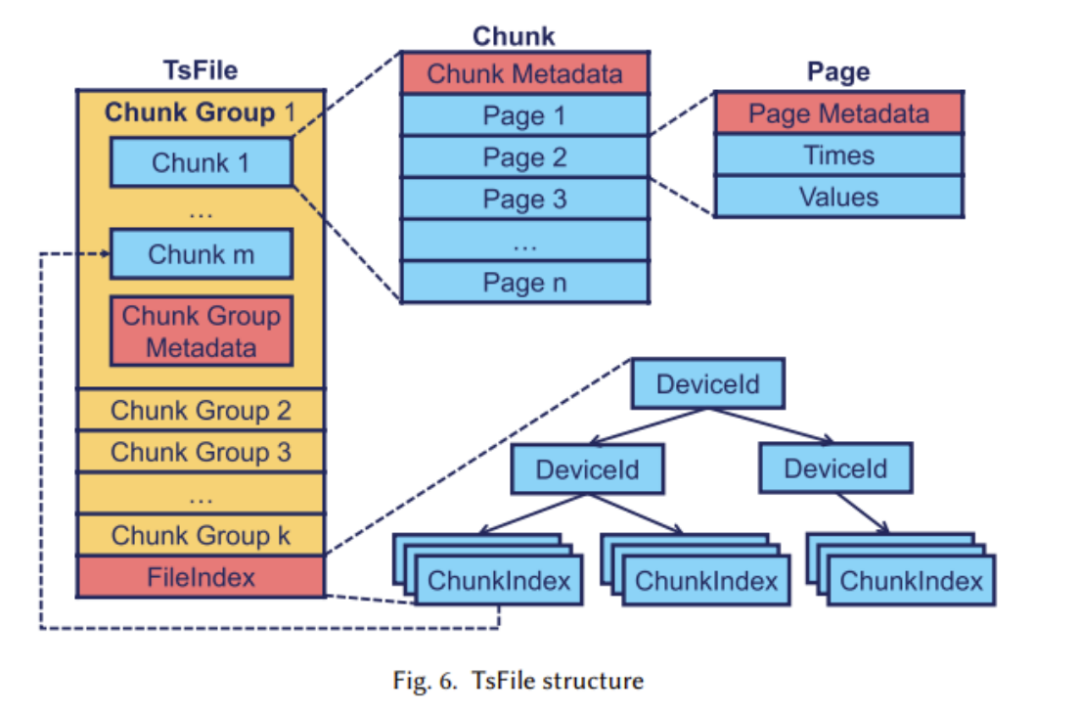
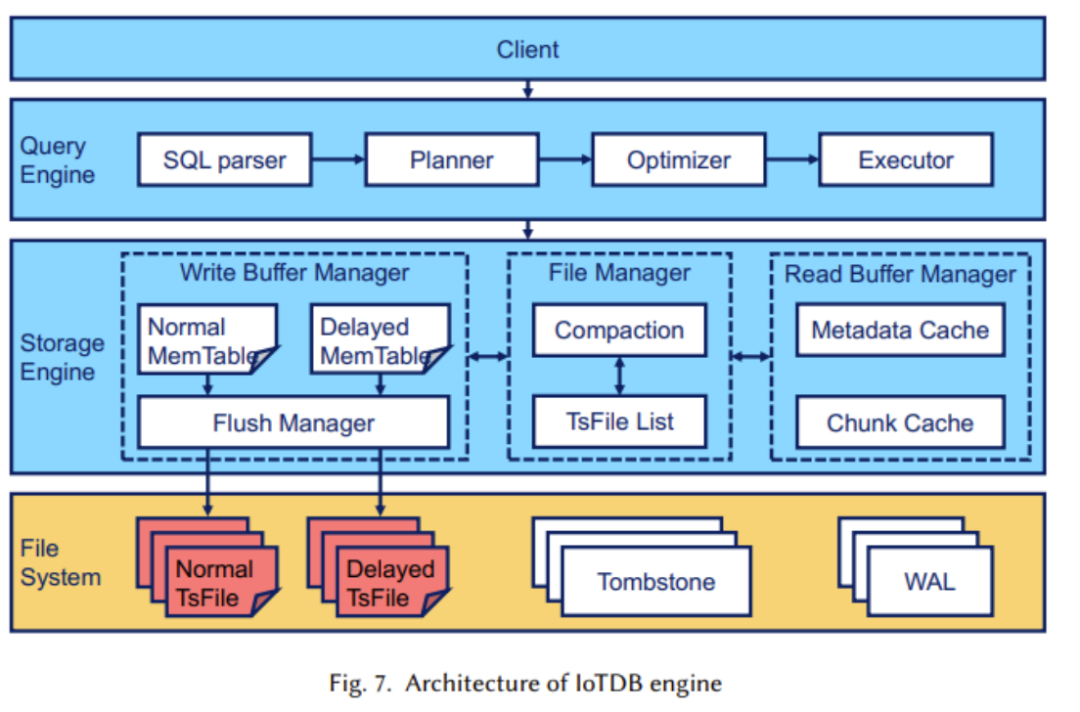
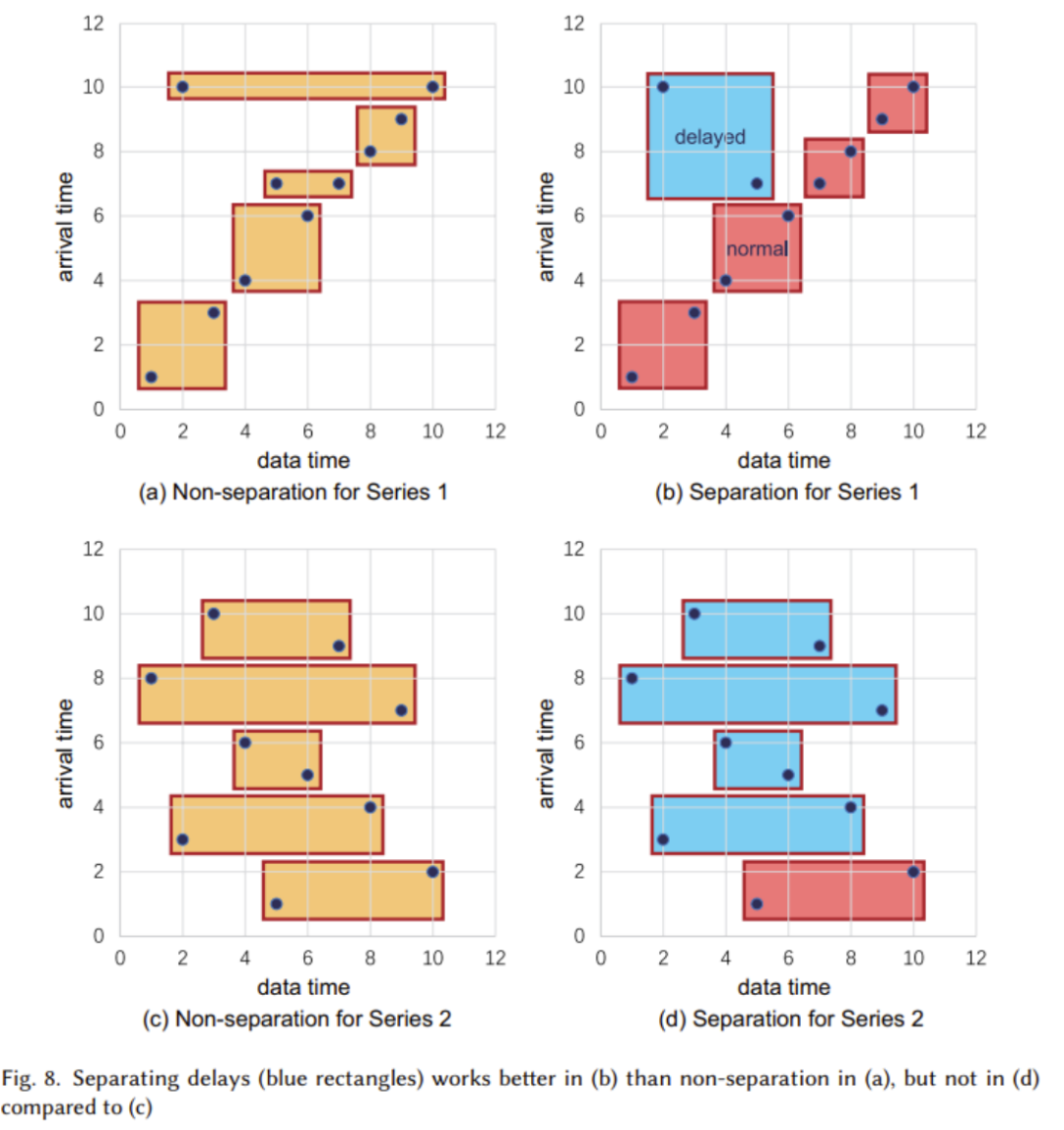
(2) Die logische Struktur wurde im vorherigen Artikel erläutert. Nun betrachten wir die Umsetzung der physischen Struktur , hauptsächlich einschließlich Zeitreihen (Zeitreihen) und Sequenzfamilien (Serienfamilien). Die folgende Abbildung zeigt, dass jede Zeitreihe aus zwei Attributen besteht: Zeit und Wert. Die Zeitreihe verläuft über den gesamten Pfad vom Wurzelknoten bis zum Blattknoten. Das Bild oben zeigt das Konzept eines Sequenzclusters. Ein Sequenzcluster kann mehrere Geräte enthalten, und ihre Daten werden zusammen in TsFile (einer Dateistruktur, die später erläutert wird) gespeichert Der Inhalt, der neu geschrieben werden muss, ist: 2. Design des TsFile-Dateiformats TsFile ist ein von Apache IoTDB selbst entwickeltes spaltenorientiertes Speicherdateiformat. Seine Struktur ist in der folgenden Abbildung dargestellt: Beim Entwurf von TsFile konzentrierte sich das Forschungsteam hauptsächlich auf die Lösung der Probleme: Die wichtigsten bereitgestellten Lösungen sind: Der Inhalt, der neu geschrieben werden muss, ist: 3. IoTDB-Engine In diesem Teil konzentrieren sich die Forscher hauptsächlich auf verzögerte Ankunft, effiziente Abfrageverarbeitung und ähnliche SQL-Abfragen im Szenario des Internet der Dinge Design. Die Struktur der IoTDB-Engine ist in der folgenden Abbildung dargestellt: In der Abbildung können wir sehen, dass der Speicher-Engine-Teil hauptsächlich zum Schreiben, Lesen und Verwalten von TsFile verwendet wird. In diesem Teil wird die Technologie der automatischen verzögerten Trennung übernommen (wie in der Abbildung unten dargestellt). In den meisten Fällen, wenn sich die Zeitbereiche in TsFile nicht überschneiden, wird die Verwendung der verzögerten Datentrennung empfohlen. In Fällen, in denen die meisten Daten jedoch ungeordnet sind, wird eine verzögerte Datentrennung nicht empfohlen Nach dem Umschreiben: Eine weitere wichtige Komponente ist die Abfrage-Engine, die für die Umwandlung von SQL-Abfragen in solche verantwortlich ist, die im Datenbankoperator ausgeführt werden können . Gleichzeitig hat Apache IoTDB zur Anpassung an industrielle IoT-Szenarien auch umfangreiche Abfragefunktionen für Zeitreihendaten entwickelt. Der Inhalt, der neu geschrieben werden muss, ist: 4. Dezentrale Lösung TsFile ist unter „Distributed on HDFS“ zu finden und wird von Spark betrieben. Darüber hinaus bietet es auch native Lösungen für eine bessere Handhabung der Datenverteilung und Abfrageverarbeitung, einschließlich Partitionsreplikation, NB-Raft-Replikation und dynamische Lesekonsistenz VergleichsergebnisseIn dem Artikel vergleichen wir TsFile und IoTDB, zwei hochmoderne Dateiformate und in der Industrie weit verbreitete Timing-Datenbanken. Anhand der folgenden Abbildung zeigen wir die Vorteile von Apache IoTDB in vielerlei Hinsicht
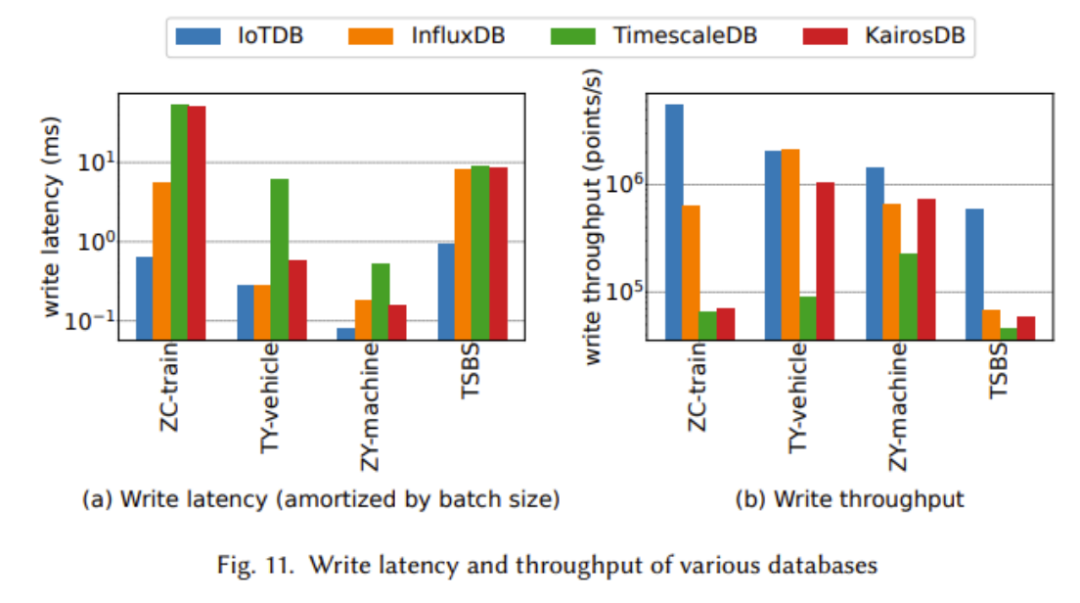
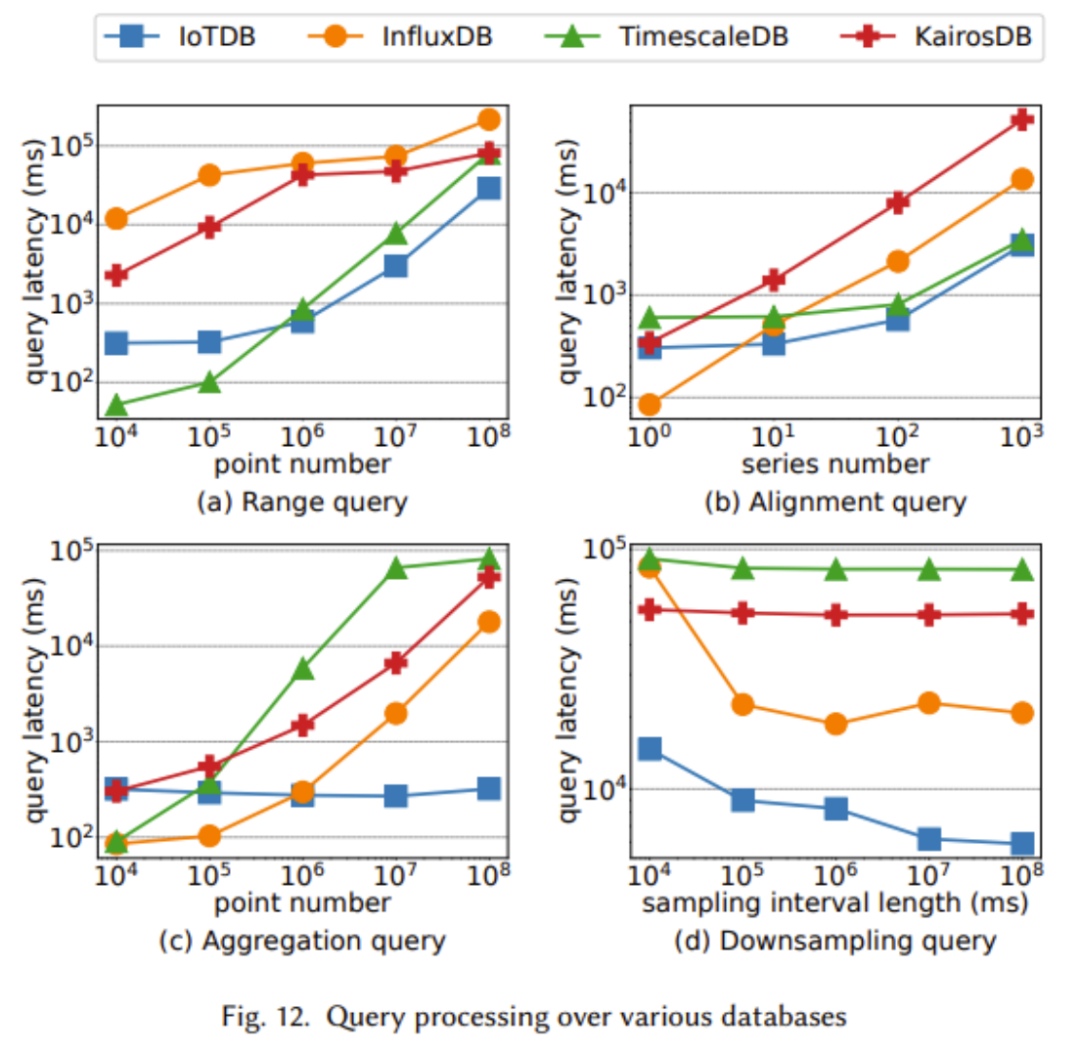
Die beiden Bilder oben zeigen die Vorteile von TsFile in Bezug auf Schreibdurchsatz, Lesezeitkosten und Synchronisationsleistung. Dies ist hauptsächlich auf das IoT-fähige Strukturdesign von TsFile zurückzuführen, das die Speicherung redundanter Informationen wie Geräte-IDs vermeidet. Obwohl die Festplattennutzung von TsFile keinen offensichtlichen Vorteil bietet, liegt dies daran, dass ein detaillierterer Index erstellt wird, was zu einem höheren Speicherplatzbedarf führt. Dieses Opfer kann jedoch zu außergewöhnlichen Verbesserungen der Abfragezeit führen, da wir einen klaren Vorteil bei den Lesezeitkosten erkennen können Wie in der obigen Tabelle deutlich zu sehen ist, schneidet IoTDB in fast allen Tests besser ab und weist eine bessere Leistung auf. einschließlich höherem Schreibdurchsatz und geringerer Schreiblatenz In den obigen Experimenten haben wir beobachtet, dass IoTDB eine bessere Leistung aufweist, wenn die Abfragedatengröße größer ist. Insbesondere bei der Datenaggregation in großem Maßstab liegen die Vorteile von IoTDB besonders auf der Hand Echtzeitabfrage und Big-Data-Analyse für IoT-Anwendungen. Das System enthält ein neues Zeitreihendateiformat namens TsFile, das Spaltenspeicher zum Speichern von Zeiten und Werten verwendet, um Nullwerte zu vermeiden und eine effektive Komprimierung zu erreichen. Basierend auf TsFile verwendet die IoTDB-Engine eine baumartige LSM-Strategie zur Verarbeitung hochintensiver Schreibvorgänge und kann das häufige Problem der verzögerten Datenankunft in IoT-Szenarien bewältigen. Umfangreiche skalierbare Abfragefunktionen und vorberechnete statistische Informationen in TsFile ermöglichen IoTDB die effiziente Bearbeitung von OLTP- und OLAP-Aufgaben 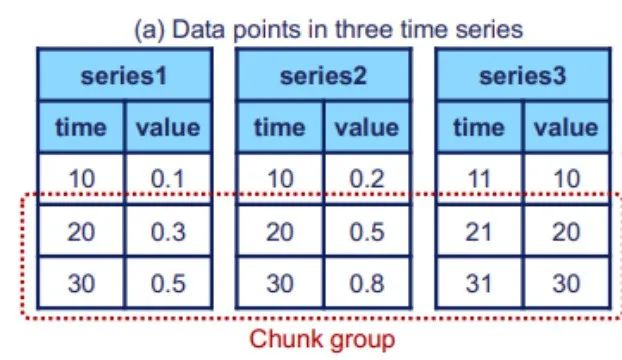
Das obige ist der detaillierte Inhalt vonApache IoTDB: eine innovative Datenbank, die Speicher-, Abfrage- und Nutzungsprobleme in industriellen IoT-Szenarien löst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
 Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wenn Sie Hadoop-Protokolle auf Debian verwalten, können Sie die folgenden Schritte und Best Practices befolgen: Protokollaggregation Aktivieren Sie die Protokollaggregation: Set Garn.log-Aggregation-Enable in true in der Datei marn-site.xml, um die Protokollaggregation zu aktivieren. Konfigurieren von Protokoll-Retentionsrichtlinien: Setzen Sie Garn.log-Aggregation.Retain-Sekunden, um die Retentionszeit des Protokolls zu definieren, z. B. 172800 Sekunden (2 Tage). Log Speicherpfad angeben: über Garn.n
