
 Technologie-Peripheriegeräte
KI
Deine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln
Technologie-Peripheriegeräte
KI
Deine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln
Deine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln

Ein Buch aufzuschlagen ist wohltuend, das haben wir schon immer verstanden. Lesen kann Menschen helfen, ihre Sprachkenntnisse zu verbessern und neue Fähigkeiten zu erlernen....
Lesen kann auch die Stimmung verbessern und die psychische Gesundheit verbessern. Wer regelmäßig liest, verfügt über ein größeres Allgemeinwissen und ein tieferes Verständnis für andere Kulturen.
Darüber hinaus haben Studien bewiesen, dass Freude am Lesen mit dem akademischen Erfolg zusammenhängt.
Aber im Zeitalter der Informationsexplosion gibt es zahlreiche Online- und Offline-Leseressourcen. Was zu lesen ist, wird zu einer schwierigen Herausforderung.
Insbesondere die Leseinhalte müssen zu verschiedenen Altersgruppen passen und ansprechend sein.
Und Empfehlungssysteme sind die Lösung für diese Herausforderung. Es präsentiert den Lesern relevantes Lesematerial und hilft ihnen, ihr Interesse aufrechtzuerhalten.
Der Kern des Empfehlungssystems ist maschinelles Lernen (ML), das häufig beim Aufbau verschiedener Arten von Empfehlungssystemen eingesetzt wird: von Videos über Bücher bis hin zu E-Commerce-Plattformen.
Das trainierte ML-Modell kann jedem Benutzer individuell Empfehlungen auf der Grundlage von Benutzerpräferenzen, Benutzerengagement und empfohlenen Elementen geben und so die Benutzererfahrung verbessern.
Googles neueste Forschung schlägt ein Empfehlungssystem für Hörbuchinhalte vor, das die soziale Natur des Lesens (z. B. Bildungsumgebungen) berücksichtigt: den STUDY-Algorithmus.
Da das, was die Kollegen einer Person gerade lesen, einen erheblichen Einfluss darauf haben kann, was sie lesen möchten, ist Google eine Partnerschaft mit Learning Ally eingegangen.
Learning Ally ist eine gemeinnützige Bildungsorganisation mit einer großen digitalen Bibliothek kuratierter Hörbücher für Studenten, die sich perfekt für den Aufbau sozialer Empfehlungsmodelle eignet.
Dadurch kann das Modell von Echtzeitinformationen über die lokalisierten sozialen Gruppen der Schüler (z. B. Klassenzimmer) profitieren.
STUDY-Algorithmus
STUDY-Algorithmus verwendet eine Methode zur Modellierung des Problems des empfohlenen Inhalts als Problem der Vorhersage der Klickrate.
wobei die Interaktionswahrscheinlichkeit des simulierten Benutzers mit jedem spezifischen Element abhängt von:
1) Benutzer- und Elementeigenschaften
2) Der Interaktionsverlaufssequenz des Elements des Benutzers.
Frühere Arbeiten haben gezeigt, dass das Transformer-Modell gut zur Modellierung dieses Problems geeignet ist.
Wenn man jeden Benutzer individuell behandelt, wird die Simulation der Interaktion zu einem Problem der autoregressiven Sequenzmodellierung. Der
STUDY-Algorithmus ist das Endprodukt der Modellierung von Daten mithilfe dieses konzeptionellen Rahmens und der anschließenden Erweiterung dieses Rahmens.
Das Problem der Vorhersage der Klickrate kann die Abhängigkeiten zwischen früheren und zukünftigen Artikelpräferenzen einzelner Benutzer modellieren und während des Trainings Ähnlichkeitsmuster zwischen Benutzern lernen.
Aber ein Problem besteht darin, dass die Methode zur Vorhersage der Klickrate die Abhängigkeiten zwischen verschiedenen Benutzern nicht abbilden kann.
Zu diesem Zweck hat Google das STUDY-Modell entwickelt, das die Mängel der autoregressiven Sequenzmodellierung beheben kann, die die soziale Natur des Lesens nicht modellieren kann.
STUDY kann die Sequenzen von Büchern, die von mehreren Schülern in einer Klasse gelesen werden, zu einer Sequenz zusammenfassen und so Daten von mehreren Schülern in einem Modell sammeln.
Allerdings muss diese Datendarstellung bei der Modellierung mit einem Transformer sorgfältig untersucht werden.
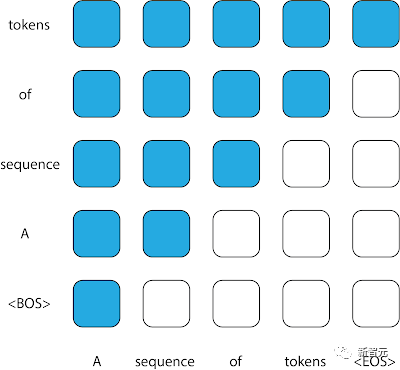
In Transformer ist die Aufmerksamkeitsmaske die Matrix, die steuert, welche Eingaben zur Vorhersage welcher Ausgaben verwendet werden können.
Das Muster, alle vorherigen Token in der Sequenz zu verwenden, um die Vorhersage der Ausgabe zu informieren, führt zu einer oberen dreieckigen Aufmerksamkeitsmatrix, die typischerweise in Kausaldekodierern zu finden ist.
Da jedoch die Sequenzeingabe in das STUDY-Modell nicht in chronologischer Reihenfolge erfolgt, obwohl jede ihrer Teilsequenzen in chronologischer Reihenfolge vorliegt, ist der herkömmliche Kausaldecoder für diese Sequenz nicht mehr geeignet.
Beim Versuch, jeden Token vorherzusagen, lässt das Modell nicht zu, dass sich die Aufmerksamkeit auf jeden Token richtet, der in der Sequenz davor erscheint. Einige dieser Token können spätere Zeitstempel haben und Informationen enthalten, die zum Zeitpunkt der Bereitstellung nicht verfügbar sind .
 Bilder
Bilder
Aufmerksamkeitsmasken, die häufig in Kausaldecodern verwendet werden. Jede Spalte stellt eine Ausgabe dar, und jede Spalte stellt eine Ausgabe dar. Ein Matrixeintrag mit dem Wert 1 (blau dargestellt) an einer bestimmten Position zeigt an, dass das Modell die Eingabe für diese Zeile beobachten kann, wenn es die Ausgabe der entsprechenden Spalte vorhersagt, während ein Wert von 0 (weiß dargestellt) das Gegenteil anzeigt . Das
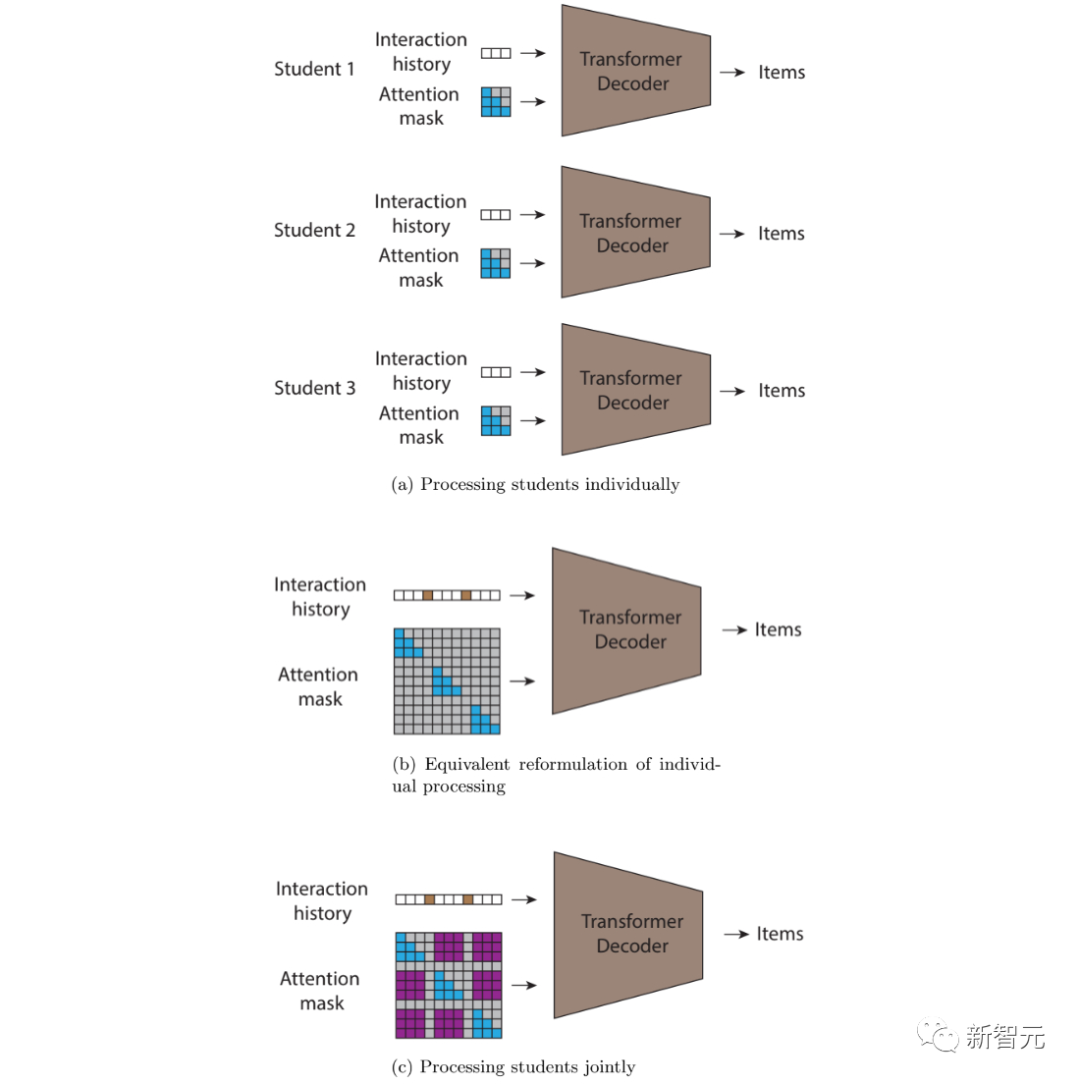
STUDY-Modell basiert auf einem Kausaltransformator, der die Dreiecksmatrix-Aufmerksamkeitsmaske durch eine zeitstempelbasierte flexible Aufmerksamkeitsmaske ersetzt und so Aufmerksamkeit über verschiedene Teilsequenzen hinweg ermöglicht.
Im Vergleich zu gewöhnlichen Konvertern verwaltet das STUDY-Modell eine kausale Dreiecksaufmerksamkeitsmatrix in einer Sequenz und verfügt über flexible Werte in verschiedenen Sequenzen, die vom Zeitstempel abhängen.
Daher beziehen sich Vorhersagen für jeden Ausgabepunkt in der Sequenz auf alle Eingabepunkte, die in der Vergangenheit relativ zum aktuellen Zeitpunkt aufgetreten sind, unabhängig davon, ob sie vor oder nach dem aktuellen Eingabepunkt in der Sequenz aufgetreten sind.
Diese kausale Einschränkung ist wichtig, denn wenn diese Einschränkung während des Trainings nicht durchgesetzt wird, lernt das Modell möglicherweise, zukünftige Informationen zu verwenden, um Vorhersagen zu treffen, was in realen Einsätzen nicht möglich ist.
 Bilder
Bilder
(a) Ein sequentieller autoregressiver Transformator, der jeden Benutzer individuell behandeln kann; (b) Ein äquivalenter gemeinsamer Vorwärtsdurchlauf, der dasselbe berechnet wie (a) (c) Durch Einführung Neue Nicht-Null-Werte in der Aufmerksamkeitsmaske (in Lila dargestellt) ermöglichen den Informationsfluss zwischen Benutzern. Zu diesem Zweck haben wir zugelassen, dass Vorhersagen von allen Interaktionen mit früheren Zeitstempeln abhängig gemacht werden, unabhängig davon, ob die Interaktionen vom selben Benutzer stammten Mehrere Baselines. Machen Sie einen Vergleich.
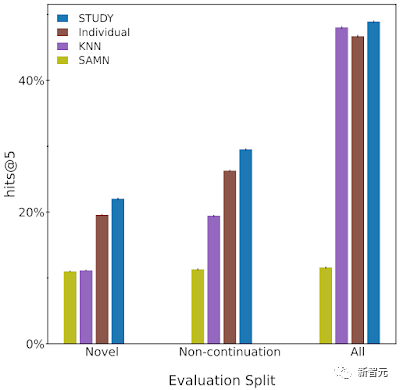
Das Team verwendete einen autoregressiven CTR-Decoder (genannt „individuell“), eine K-Nearest-Neighbor-Baseline (KNN) und eine vergleichbare soziale Baseline – das Social Attention Memory Network (SAMN).
Sie nutzten Daten aus dem ersten Studienjahr für die Ausbildung und Daten aus dem zweiten Studienjahr für Validierung und Tests.
Das Team bewertet diese Modelle, indem es den Prozentsatz der Zeit misst, mit der der nächste Artikel, mit dem der Benutzer tatsächlich interagiert, zu den Top-n-Vorschlägen des Modells gehört.
Zusätzlich zur Bewertung des Modells anhand des gesamten Testsatzes meldet das Team auch die Modellergebnisse für zwei Teilsätze des Testsatzes, die anspruchsvoller sind als der gesamte Datensatz.
Es ist zu beobachten, dass Schüler in der Regel mehrmals mit Hörbüchern interagieren, daher ist es trivial, einfach das letzte Buch zu empfehlen, das ein Benutzer gelesen hat.
Daher bezeichnen die Forscher die erste Testteilmenge als „Nicht-Fortsetzung“. In dieser Teilmenge untersuchen wir nur die Empfehlungsleistung jedes Modells, wenn Schüler mit Büchern interagieren, die sich von der vorherigen Interaktion unterscheiden.
Darüber hinaus hat das Team auch beobachtet, dass die Schüler die Bücher, die sie in der Vergangenheit gelesen haben, noch einmal durchgehen, sodass die empfohlenen Bücher für jeden Schüler auf die Bücher beschränkt sind, die er in der Vergangenheit gelesen hat, was bei der Prüfung möglich ist set Erzielen Sie großartige Leistungen.
Während es durchaus sinnvoll sein kann, Schülern ihre Lieblingsbücher aus der Vergangenheit zu empfehlen, liegt der Wert von Empfehlungssystemen zum großen Teil darin, Benutzern neue, unbekannte Inhalte zu empfehlen.
Um dies zu messen, evaluierte das Team das Modell anhand einer Teilmenge des Testsatzes, bei dem die Schüler zum ersten Mal mit der Bibliographie interagierten. Wir nennen diese Bewertungsteilmenge „neue Teilmenge“.
Es lässt sich feststellen, dass „STUDY“ in fast allen Bewertungen besser als andere Modelle abschneidet.
Bilder
Die Bedeutung der richtigen Gruppierung
 Der Kern des STUDY-Algorithmus besteht darin, Benutzer zu gruppieren und gemeinsame Schlussfolgerungen für mehrere Benutzer derselben Gruppe in einem einzigen Vorwärtsdurchlauf des Modells durchzuführen.
Der Kern des STUDY-Algorithmus besteht darin, Benutzer zu gruppieren und gemeinsame Schlussfolgerungen für mehrere Benutzer derselben Gruppe in einem einzigen Vorwärtsdurchlauf des Modells durchzuführen.
Die Forscher untersuchten anhand einer Ablationsstudie, wie wichtig die praktische Gruppierung für die Modellleistung ist.
In dem vorgeschlagenen Modell gruppierten die Forscher alle Schüler derselben Klasse und Schule.
Wir haben dann mit Gruppierungen experimentiert, die von allen Schülern derselben Klasse und desselben Bezirks definiert wurden, sowie mit der Gruppierung aller Schüler in einer Gruppe und der Verwendung einer zufälligen Teilmenge bei jedem Vorwärtsdurchlauf.
Die Forscher verglichen diese Modelle auch mit „persönlichen“ Modellen als Referenz.
Studien haben ergeben, dass die Verwendung stärker lokalisierter Gruppen effektiver ist, d. h. Schul- und Klassengruppierungen sind besser als Schulbezirks- und Klassengruppierungen.
Dies unterstützt die Hypothese, dass das Forschungsmodell erfolgreich ist, weil Aktivitäten wie Lesen sozial sind: Die Leseentscheidungen der Menschen korrelieren wahrscheinlich mit den Leseentscheidungen ihrer Mitmenschen.
Beide Modi übertreffen die beiden anderen Modi (Einzelgruppenmodus und Einzelmodus), ohne Klassenstufen zur Gruppierung von Schülern zu verwenden.
Dies zeigt, dass Daten von Benutzern mit ähnlichen Leseniveaus und Interessen zur Verbesserung der Leistung des Modells beitragen.
Schließlich beschränkte sich diese Google-Studie auf die Modellierung einer Nutzergruppe unter der Annahme, dass soziale Beziehungen homogen sind.
Referenz:
https://www.php.cn/link/0b32f1a9efe5edf3dd2f38b0c0052bfe
Das obige ist der detaillierte Inhalt vonDeine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 So entfernen Sie Informationen zum Autor und zur letzten Änderung in Microsoft Word
Apr 15, 2023 am 11:43 AM
So entfernen Sie Informationen zum Autor und zur letzten Änderung in Microsoft Word
Apr 15, 2023 am 11:43 AM
Microsoft Word-Dokumente enthalten beim Speichern einige Metadaten. Diese Details werden zur Identifizierung des Dokuments verwendet, z. B. wann es erstellt wurde, wer der Autor war, Datum der Änderung usw. Es enthält auch andere Informationen wie die Anzahl der Zeichen, die Anzahl der Wörter, die Anzahl der Absätze und mehr. Wenn Sie den Autor oder die zuletzt geänderten Informationen oder andere Informationen entfernen möchten, damit andere Personen die Werte nicht kennen, gibt es eine Möglichkeit. In diesem Artikel erfahren Sie, wie Sie Informationen zum Autor und zur letzten Änderung aus einem Dokument entfernen. Entfernen Sie den Autor und die zuletzt geänderten Informationen aus dem Microsoft Word-Dokument. Schritt 1 – Gehen Sie zu
 So erhalten Sie die GPU in Windows 11 und überprüfen die Grafikkartendetails
Nov 07, 2023 am 11:21 AM
So erhalten Sie die GPU in Windows 11 und überprüfen die Grafikkartendetails
Nov 07, 2023 am 11:21 AM
Systeminformationen verwenden Klicken Sie auf Start und geben Sie Systeminformationen ein. Klicken Sie einfach auf das Programm, wie im Bild unten gezeigt. Hier finden Sie die meisten Systeminformationen und unter anderem Informationen zur Grafikkarte. Erweitern Sie im Systeminformationsprogramm Komponenten und klicken Sie dann auf Anzeigen. Lassen Sie das Programm alle notwendigen Informationen sammeln und sobald es fertig ist, können Sie den grafikkartenspezifischen Namen und andere Informationen auf Ihrem System finden. Auch wenn Sie über mehrere Grafikkarten verfügen, finden Sie hier die meisten Inhalte zu dedizierten und integrierten Grafikkarten, die an Ihren Computer angeschlossen sind. Verwenden des Geräte-Managers von Windows 11 Wie bei den meisten anderen Windows-Versionen können Sie auch die Grafikkarte auf Ihrem Computer über den Geräte-Manager finden. Klicken Sie auf Start und dann
 So teilen Sie Kontaktdaten mit NameDrop: Anleitung für iOS 17
Sep 16, 2023 pm 06:09 PM
So teilen Sie Kontaktdaten mit NameDrop: Anleitung für iOS 17
Sep 16, 2023 pm 06:09 PM
In iOS 17 gibt es eine neue AirDrop-Funktion, mit der Sie Kontaktinformationen mit jemandem austauschen können, indem Sie zwei iPhones berühren. Es heißt NameDrop und so funktioniert es. Anstatt die Nummer einer neuen Person einzugeben, um sie anzurufen oder ihr eine SMS zu schicken, können Sie mit NameDrop Ihr iPhone einfach in die Nähe der Person halten, um Kontaktdaten auszutauschen, damit sie Ihre Nummer hat. Wenn Sie die beiden Geräte zusammenfügen, wird automatisch die Schnittstelle zum Teilen von Kontakten angezeigt. Wenn Sie auf das Popup klicken, werden die Kontaktinformationen einer Person und ihr Kontaktposter angezeigt (Sie können Ihre eigenen Fotos anpassen und bearbeiten, ebenfalls eine neue Funktion von iOS17). Dieser Bildschirm enthält auch Optionen zum „Nur Empfangen“ oder zum Teilen Ihrer eigenen Kontaktinformationen als Antwort.
 Der Single-View-NeRF-Algorithmus S^3-NeRF verwendet Multi-Beleuchtungsinformationen, um Szenengeometrie und Materialinformationen wiederherzustellen.
Apr 13, 2023 am 10:58 AM
Der Single-View-NeRF-Algorithmus S^3-NeRF verwendet Multi-Beleuchtungsinformationen, um Szenengeometrie und Materialinformationen wiederherzustellen.
Apr 13, 2023 am 10:58 AM
Aktuelle 3D-Bildrekonstruktionsarbeiten verwenden normalerweise eine Multi-View-Stereo-Rekonstruktionsmethode (Multi-View-Stereo), die die Zielszene aus mehreren Blickwinkeln (Multi-View) unter konstanten natürlichen Lichtbedingungen erfasst. Diese Methoden gehen jedoch normalerweise von Lambertschen Oberflächen aus und haben Schwierigkeiten, hochfrequente Details wiederherzustellen. Ein weiterer Ansatz zur Szenenrekonstruktion besteht darin, Bilder zu verwenden, die von einem festen Standpunkt, aber mit unterschiedlichen Punktlichtern aufgenommen wurden. Photometrische Stereomethoden nutzen beispielsweise diesen Aufbau und nutzen seine Schattierungsinformationen, um die Oberflächendetails von Nicht-Lambertschen Objekten zu rekonstruieren. Bestehende Einzelansichtsmethoden verwenden jedoch normalerweise Normalkarten oder Tiefenkarten, um das Sichtbare darzustellen
 Das Yuanverse Virtual Reality Application Education Summit Forum fand in Zhengzhou statt
Nov 30, 2023 pm 08:33 PM
Das Yuanverse Virtual Reality Application Education Summit Forum fand in Zhengzhou statt
Nov 30, 2023 pm 08:33 PM
In Zhengzhou fand ein Metaverse Virtual Reality Application Education Summit Forum statt. Beim Metaverse Virtual Reality Application Education Summit Forum wurde der Tanz „Floating Light“ von Dong Yushan, einem Lehrer am Henan Art Vocational College, gezeigt. Gleichzeitig tanzten auch virtuelle Menschen synchron im Yuanverse-Raum. Ihre sanften und anmutigen Tanzhaltungen verblüfften viele Gäste. Am 24. November fand in Zhengzhou das Yuanverse Virtual Reality Application Education Summit Forum statt on Vertreter von wissenschaftlichen Forschungsinstituten, Universitäten, Industrieverbänden und bekannten Unternehmen kamen zusammen, um die Entwicklungstrends des Yuanverse zu diskutieren. „Das Metaversum war in den letzten Jahren ein häufig diskutiertes Thema und es hat der Animationsbranche unbegrenzte Möglichkeiten eröffnet.“ Wang Xudong, stellvertretender Vorsitzender der Henan Animation Industry Association, sagte in seiner Rede, dass China dies in den letzten Jahren getan habe
 Wie NameDrop auf dem iPhone funktioniert (und wie man es deaktiviert)
Nov 30, 2023 am 11:53 AM
Wie NameDrop auf dem iPhone funktioniert (und wie man es deaktiviert)
Nov 30, 2023 am 11:53 AM
In iOS17 gibt es eine neue AirDrop-Funktion, die es Ihnen ermöglicht, Kontaktinformationen mit jemandem auszutauschen, indem Sie zwei iPhones gleichzeitig berühren. Es heißt NameDrop und hier erfahren Sie, wie es tatsächlich funktioniert. NameDrop macht es überflüssig, die Nummer einer neuen Person einzugeben, um sie anzurufen oder ihr eine SMS zu schicken, damit sie Ihre Nummer hat. Sie können Ihr iPhone einfach in die Nähe der Person halten, um Kontaktinformationen auszutauschen. Wenn Sie die beiden Geräte zusammenfügen, wird automatisch die Schnittstelle zum Teilen von Kontakten angezeigt. Wenn Sie auf das Popup klicken, werden die Kontaktinformationen einer Person und ihr Kontaktposter angezeigt (ein eigenes Foto, das Sie anpassen und bearbeiten können, ebenfalls neu in iOS 17). Dieser Bildschirm enthält auch die Option „Nur Empfangen“ oder das Teilen Ihrer eigenen Kontaktinformationen als Antwort
 Was ist der Grund für die Verzögerung beim Empfang von Nachrichten auf WeChat?
Sep 19, 2023 pm 03:02 PM
Was ist der Grund für die Verzögerung beim Empfang von Nachrichten auf WeChat?
Sep 19, 2023 pm 03:02 PM
Der Grund für die Verzögerung beim Empfang von Informationen durch WeChat können Netzwerkprobleme, Serverlast, Versionsprobleme, Geräteprobleme, Probleme beim Senden von Nachrichten oder andere Faktoren sein. Detaillierte Einführung: 1. Netzwerkprobleme können mit der Netzwerkverbindung zusammenhängen. Wenn die Netzwerkverbindung instabil ist oder das Signal schwach ist, kann es zu Verzögerungen bei der Informationsübertragung kommen mit einem stabilen Netzwerk verbunden und die Netzwerksignalstärke ist gut. 2. Wenn die Auslastung des WeChat-Servers hoch ist, kann es zu Verzögerungen bei der Informationsübertragung kommen, insbesondere wenn eine große Anzahl von Benutzern WeChat verwendet gleichzeitig usw.
 Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
1. Hintergrund der Ursache-Wirkungs-Korrektur 1. Abweichungen treten im Empfehlungssystem auf. Das Empfehlungsmodell wird durch das Sammeln von Daten trainiert, um Benutzern geeignete Elemente zu empfehlen. Wenn Benutzer mit empfohlenen Elementen interagieren, werden die gesammelten Daten verwendet, um das Modell weiter zu trainieren und so einen geschlossenen Regelkreis zu bilden. Allerdings kann es in diesem geschlossenen Kreislauf verschiedene Einflussfaktoren geben, die zu Fehlern führen. Der Hauptgrund für den Fehler besteht darin, dass es sich bei den meisten zum Trainieren des Modells verwendeten Daten um Beobachtungsdaten und nicht um ideale Trainingsdaten handelt, die von Faktoren wie der Expositionsstrategie und der Benutzerauswahl beeinflusst werden. Der Kern dieser Verzerrung liegt im Unterschied zwischen den Erwartungen empirischer Risikoschätzungen und den Erwartungen echter idealer Risikoschätzungen. 2. Häufige Vorurteile Es gibt drei Haupttypen häufiger Vorurteile in Empfehlungsmarketingsystemen: Selektive Voreingenommenheit: Sie ist auf die Herkunft des Benutzers zurückzuführen
