
 Technologie-Peripheriegeräte
KI
UniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!
Technologie-Peripheriegeräte
KI
UniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!
UniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!

Originaltitel: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/pdf/2306.09117.pdf

Papier Idee:
In diesem technischen Bericht schlagen wir eine Lösung namens UniOCC für visionszentrierte 3D-Belegungsvorhersagetrajektorien in der CVPR 2023 nuScenes Open Dataset Challenge vor. Bestehende Belegungsvorhersagemethoden konzentrieren sich hauptsächlich auf die Verwendung von 3D-Belegungsetiketten, um die projizierten Eigenschaften des 3D-Volumenraums zu optimieren. Der Generierungsprozess dieser Etiketten ist jedoch sehr komplex und teuer (basierend auf semantischer 3D-Annotation), ist durch die Voxelauflösung begrenzt und kann keine feinkörnige räumliche Semantik liefern. Um diese Einschränkung zu beheben, schlagen wir eine neue Methode zur Vorhersage der einheitlichen Belegung (UniOcc) vor, die explizit räumliche geometrische Einschränkungen auferlegt und die feinkörnige semantische Überwachung durch Volumenstrahl-Rendering ergänzt. Unsere Methode verbessert die Modellleistung erheblich und zeigt ein gutes Potenzial zur Reduzierung der manuellen Annotationskosten. Angesichts der mühsamen Kommentierung von 3D-Belegungen schlagen wir außerdem das tiefenbewusste Teacher Student (DTS)-Framework vor, um die Vorhersagegenauigkeit mithilfe unbeschrifteter Daten zu verbessern. Unsere Lösung erreichte 51,27 % mIoU im offiziellen Einzelmodell-Ranking und belegte in dieser Herausforderung den dritten Platz von 2D- und 3D-Darstellungen, wodurch Modelle zur Vorhersage der Belegung mit mehreren Kameras verbessert werden. In diesem Artikel wird keine neue Modellarchitektur entworfen, sondern der Schwerpunkt liegt auf der vielseitigen Plug-and-Play-Verbesserung vorhandener Modelle [3, 18, 20].
Wie folgt umgeschrieben: In diesem Artikel wird die Funktion zum Generieren von 2D-Semantik- und Tiefenkarten mithilfe von Volumenrendering implementiert, indem die Darstellung auf eine Darstellung im NeRF-Stil aktualisiert wird [1, 15, 21]. Dies ermöglicht eine feinkörnige Überwachung auf 2D-Pixelebene. Durch Strahlenabtastung dreidimensionaler Voxel können die gerenderten zweidimensionalen Pixelsemantiken und Tiefeninformationen erhalten werden. Durch die explizite Integration geometrischer Okklusionsbeziehungen und semantischer Konsistenzbeschränkungen bietet dieses Papier eine explizite Anleitung für das Modell und stellt die Einhaltung dieser Einschränkungen sicher. Es ist erwähnenswert, dass UniOcc das Potenzial hat, die Abhängigkeit von teuren semantischen 3D-Anmerkungen zu verringern. Da es keine 3D-Belegungsbezeichnungen gibt, schneiden Modelle, die nur mit unserer Volumenrendering-Überwachung trainiert wurden, sogar besser ab als Modelle, die mit der 3D-Belegungsüberwachung trainiert wurden. Dies unterstreicht das spannende Potenzial, die Abhängigkeit von teuren semantischen 3D-Annotationen zu reduzieren, da Szenendarstellungen direkt aus kostengünstigen 2D-Segmentierungsetiketten gelernt werden können. Darüber hinaus können durch den Einsatz fortschrittlicher Technologien wie SAM [6] und [14,19] die Kosten für die 2D-Segmentierungsannotation weiter gesenkt werden. In diesem Artikel wird auch das DTS-Framework (Depth Sensing Teacher-Student) vorgestellt, eine selbstüberwachte Trainingsmethode. Im Gegensatz zum klassischen Mean Teacher verbessert DTS die tiefe Vorhersage des Lehrermodells und ermöglicht so ein stabiles und effektives Training unter Verwendung unbeschrifteter Daten. Darüber hinaus werden in diesem Artikel einige einfache, aber effektive Techniken angewendet, um die Leistung des Modells zu verbessern. Dazu gehört die Verwendung sichtbarer Masken im Training, die Verwendung eines stärkeren vorab trainierten Backbone-Netzwerks, die Erhöhung der Voxelauflösung und die Implementierung von Test-Time Data Augmentation (TTA)
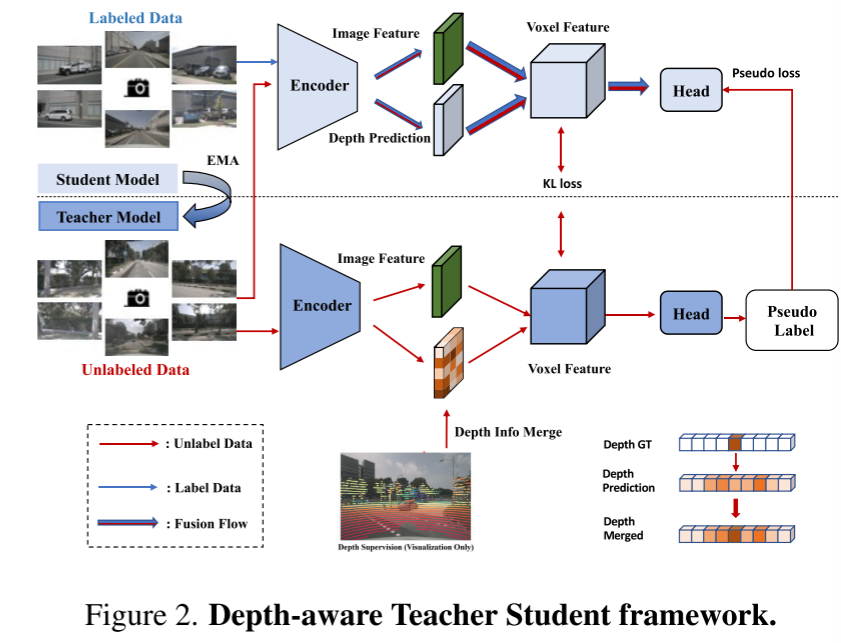
Hier ist eine Übersicht über das UniOcc-Framework: Bild 1Bild 2. Tiefenbewusstes Lehrer-Schüler-Framework. 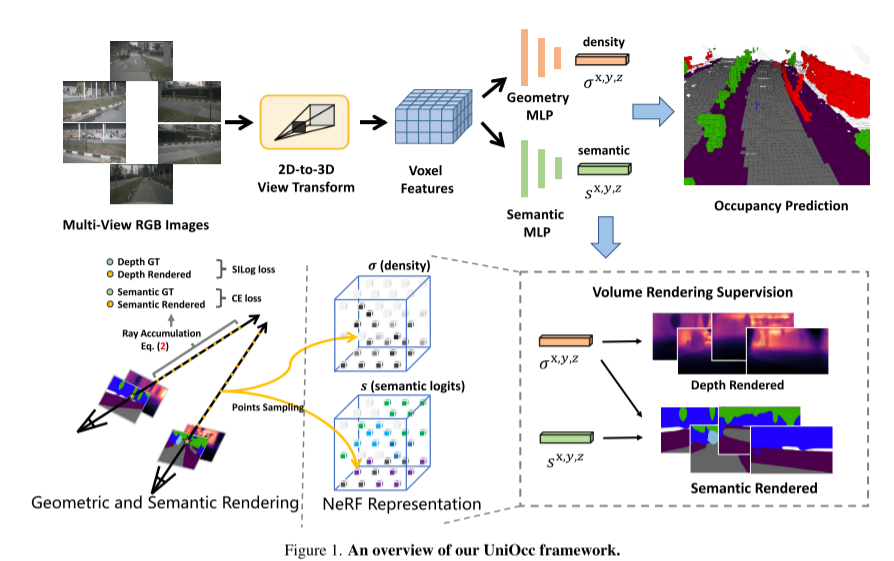
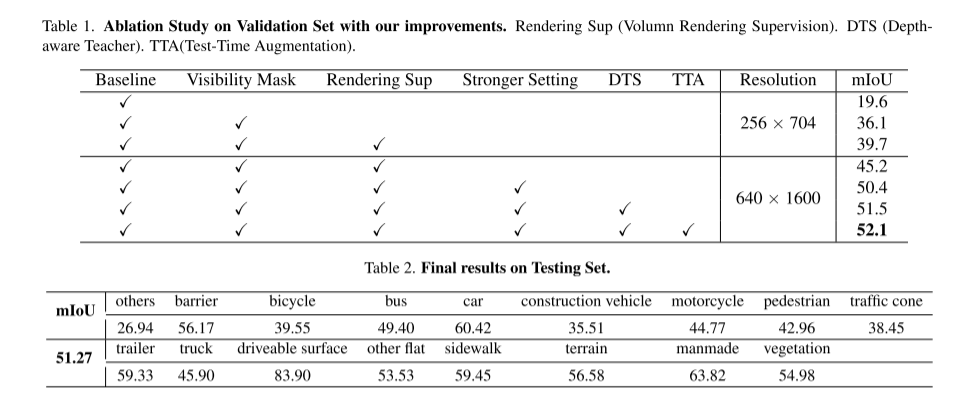
Experimentelle Ergebnisse:
Zitat:

Originallink: https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
Das obige ist der detaillierte Inhalt vonUniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Smart App Control unter Windows 11: So aktivieren oder deaktivieren Sie es
Jun 06, 2023 pm 11:10 PM
Smart App Control unter Windows 11: So aktivieren oder deaktivieren Sie es
Jun 06, 2023 pm 11:10 PM
Intelligent App Control ist ein sehr nützliches Tool in Windows 11, das dabei hilft, Ihren PC vor nicht autorisierten Apps zu schützen, die Ihre Daten beschädigen können, wie z. B. Ransomware oder Spyware. In diesem Artikel wird erklärt, was Smart App Control ist, wie es funktioniert und wie man es in Windows 11 ein- oder ausschaltet. Was ist Smart App Control in Windows 11? Smart App Control (SAC) ist eine neue Sicherheitsfunktion, die mit dem Windows 1122H2-Update eingeführt wurde. Es arbeitet mit Microsoft Defender oder Antivirensoftware von Drittanbietern zusammen, um potenziell unnötige Apps zu blockieren, die Ihr Gerät verlangsamen, unerwartete Werbung anzeigen oder andere unerwartete Aktionen ausführen können. Intelligente Anwendung
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 Die herumfliegenden Gesichtszüge, das Öffnen des Mundes, das Starren und das Hochziehen der Augenbrauen können von der KI perfekt nachgeahmt werden, sodass Videobetrug nicht verhindert werden kann
Dec 14, 2023 pm 11:30 PM
Die herumfliegenden Gesichtszüge, das Öffnen des Mundes, das Starren und das Hochziehen der Augenbrauen können von der KI perfekt nachgeahmt werden, sodass Videobetrug nicht verhindert werden kann
Dec 14, 2023 pm 11:30 PM
Mit solch einer mächtigen KI-Imitationsfähigkeit ist es wirklich unmöglich, dies zu verhindern. Hat die Entwicklung der KI mittlerweile dieses Niveau erreicht? Ihr vorderer Fuß lässt Ihre Gesichtszüge fliegen, und auf Ihrem hinteren Fuß wird genau der gleiche Ausdruck reproduziert. Starren, Augenbrauen hochziehen, schmollen, egal wie übertrieben der Ausdruck ist, alles wird perfekt nachgeahmt. Erhöhen Sie den Schwierigkeitsgrad, heben Sie die Augenbrauen höher, öffnen Sie die Augen weiter, und sogar die Mundform ist schief und der Ausdruck des Avatars kann perfekt reproduziert werden. Wenn Sie die Parameter auf der linken Seite anpassen, ändert der virtuelle Avatar auf der rechten Seite auch seine Bewegungen entsprechend, um eine Nahaufnahme von Mund und Augen zu erhalten. Man kann nicht sagen, dass die Nachahmung genau gleich ist, aber der Ausdruck ist genau derselbe gleich (ganz rechts). Die Forschung stammt von Institutionen wie der Technischen Universität München, die GaussianAvatars vorschlägt
 Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
Was ist NeRF? Ist die NeRF-basierte 3D-Rekonstruktion voxelbasiert?
Oct 16, 2023 am 11:33 AM
1 Einleitung Neural Radiation Fields (NeRF) sind ein relativ neues Paradigma im Bereich Deep Learning und Computer Vision. Diese Technologie wurde im ECCV2020-Papier „NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis“ (das mit dem Best Paper Award ausgezeichnet wurde) vorgestellt und erfreut sich seitdem mit bisher fast 800 Zitaten äußerster Beliebtheit [1]. Der Ansatz markiert einen grundlegenden Wandel in der traditionellen Art und Weise, wie maschinelles Lernen 3D-Daten verarbeitet. Darstellung neuronaler Strahlungsfelder und differenzierbarer Rendering-Prozess: Zusammengesetzte Bilder durch Abtasten von 5D-Koordinaten (Position und Blickrichtung) entlang der Kamerastrahlen, Eingabe dieser Positionen in ein MLP, um mithilfe volumetrischer Rendering-Techniken Bilder zu erzeugen; ; Die Rendering-Funktion ist differenzierbar und kann daher übergeben werden
 MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten
Oct 13, 2023 pm 12:09 PM
MotionLM: Sprachmodellierungstechnologie für die Bewegungsvorhersage mit mehreren Agenten
Oct 13, 2023 pm 12:09 PM
Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für den Nachdruck an die Quelle. Originaltitel: MotionLM: Multi-Agent Motion Forecasting as Language Modeling Papierlink: https://arxiv.org/pdf/2309.16534.pdf Autorenzugehörigkeit: Waymo Konferenz: ICCV2023 Papieridee: Für die Sicherheitsplanung autonomer Fahrzeuge das zukünftige Verhalten zuverlässig vorhersagen der Straßenverkehrsbeamten ist von entscheidender Bedeutung. Diese Studie stellt kontinuierliche Trajektorien als Sequenzen diskreter Bewegungstokens dar und behandelt die Bewegungsvorhersage mit mehreren Agenten als eine Sprachmodellierungsaufgabe. Das von uns vorgeschlagene Modell MotionLM hat die folgenden Vorteile: Erstens
 Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Eine rein visuelle Annotationslösung nutzt hauptsächlich die visuelle Darstellung sowie einige Daten von GPS, IMU und Radgeschwindigkeitssensoren für die dynamische Annotation. Für Massenproduktionsszenarien muss es sich natürlich nicht nur um visuelle Aspekte handeln. Einige in Massenproduktion hergestellte Fahrzeuge verfügen über Sensoren wie Festkörperradar (AT128). Wenn wir aus Sicht der Massenproduktion einen geschlossenen Datenkreislauf erstellen und alle diese Sensoren verwenden, können wir das Problem der Kennzeichnung dynamischer Objekte effektiv lösen. Aber in unserem Plan gibt es kein Festkörperradar. Aus diesem Grund stellen wir diese gängigste Etikettierungslösung für die Massenproduktion vor. Der Kern einer rein visuellen Annotationslösung liegt in der hochpräzisen Posenrekonstruktion. Wir verwenden das Posenrekonstruktionsschema von Structure from Motion (SFM), um die Genauigkeit der Rekonstruktion sicherzustellen. Aber pass
 Werfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.
May 08, 2024 am 11:40 AM
Werfen Sie einen Blick auf die Vergangenheit und Gegenwart von Occ und autonomem Fahren! Die erste Rezension fasst die drei Hauptthemen Funktionserweiterung/Massenproduktionsbereitstellung/effiziente Annotation umfassend zusammen.
May 08, 2024 am 11:40 AM
Oben geschrieben und persönliches Verständnis des Autors In den letzten Jahren hat autonomes Fahren aufgrund seines Potenzials, die Belastung des Fahrers zu verringern und die Fahrsicherheit zu verbessern, zunehmende Aufmerksamkeit erhalten. Die visionsbasierte dreidimensionale Belegungsvorhersage ist eine neue Wahrnehmungsaufgabe, die sich für eine kostengünstige und umfassende Untersuchung der Sicherheit autonomen Fahrens eignet. Obwohl viele Studien die Überlegenheit von 3D-Belegungsvorhersagetools im Vergleich zu objektzentrierten Wahrnehmungsaufgaben gezeigt haben, gibt es immer noch Rezensionen, die diesem sich schnell entwickelnden Bereich gewidmet sind. In diesem Artikel wird zunächst der Hintergrund der visionsbasierten 3D-Belegungsvorhersage vorgestellt und die bei dieser Aufgabe auftretenden Herausforderungen erörtert. Als nächstes diskutieren wir umfassend den aktuellen Status und die Entwicklungstrends aktueller 3D-Belegungsvorhersagemethoden unter drei Gesichtspunkten: Funktionsverbesserung, Bereitstellungsfreundlichkeit und Kennzeichnungseffizienz. zu guter Letzt
 Wussten Sie, dass es bei Programmierern in ein paar Jahren einen Niedergang geben wird?
Nov 08, 2023 am 11:17 AM
Wussten Sie, dass es bei Programmierern in ein paar Jahren einen Niedergang geben wird?
Nov 08, 2023 am 11:17 AM
Die Zeitschrift „ComputerWorld“ schrieb einmal in einem Artikel, dass „die Programmierung bis 1960 verschwinden wird“, weil IBM eine neue Sprache FORTRAN entwickelt hat, die es Ingenieuren ermöglicht, die benötigten mathematischen Formeln zu schreiben und sie dann dem Computer zu übermitteln, damit das Programmieren endet. Ein paar Jahre später hörten wir ein neues Sprichwort: Jeder Unternehmer kann Geschäftsbegriffe verwenden, um seine Probleme zu beschreiben und dem Computer zu sagen, was er tun soll. Mit dieser Programmiersprache namens COBOL brauchen Unternehmen keine Programmierer mehr. Später soll IBM eine neue Programmiersprache namens RPG entwickelt haben, mit der Mitarbeiter Formulare ausfüllen und Berichte erstellen können, sodass die meisten Programmieranforderungen des Unternehmens damit erfüllt werden können.
