

Es wurde ein großes Modellentwicklungs-Toolset erstellt!

Der Inhalt, der neu geschrieben werden muss, ist: Autor Richard MacManus Technologie-Stack.
Schnelle Ingenieure können möglicherweise nicht die Nerven von Entwicklern berühren, die zu großen Modellen eilen, aber ein Satz eines Produktmanagers oder einer Führungskraft: Kann ein „Agent“ entwickelt werden, kann eine „Kette“ implementiert werden und „Welcher Vektor?“ Datenbank zu verwenden?“ sind derzeit zu großen Mainstream-Unternehmen für große Modellanwendungen geworden, die Technologiestudenten dazu gebracht haben, die Schwierigkeiten bei der Generierung von KI-Entwicklung zu überwinden.
Was sind die Schichten des neuen Technologie-Stacks? Wo ist der schwierigste Teil? Dieser Artikel wird Sie dazu bringen, es herauszufinden
1. Der Technologie-Stack muss aktualisiert werden. Entwickler läuten die Ära der KI-Ingenieure ein
Im vergangenen Jahr sind einige Tools entstanden, die dies ermöglicht haben Entwickler von KI-Anwendungen Das Ökosystem beginnt zu reifen. Für diejenigen, die sich auf die Entwicklung künstlicher Intelligenz konzentrieren, gibt es inzwischen sogar einen Begriff, nämlich „KI-Ingenieur“. Laut Shawn @swyx Wang ist dies der nächste Schritt für „prompte Ingenieure“. Er hat außerdem ein Koordinatendiagramm erstellt, das die Position von KI-Ingenieuren im breiteren Ökosystem der künstlichen Intelligenz visuell veranschaulicht. Quelle: swyx
Große Sprachmodelle (LLM) sind die Kerntechnologie von KI-Ingenieuren. Es ist kein Zufall, dass sowohl LangChain als auch LlamaIndex Tools sind, die LLM erweitern und ergänzen. Aber welche anderen Tools stehen dieser neuen Generation von Entwicklern zur Verfügung? Das bisher beste Diagramm, das ich zum LLM-Stack gesehen habe, stammt von der Risikokapitalgesellschaft Andreessen Horowitz (a16z). Das Folgende ist seine Sicht auf den „LLM-App-Stack“: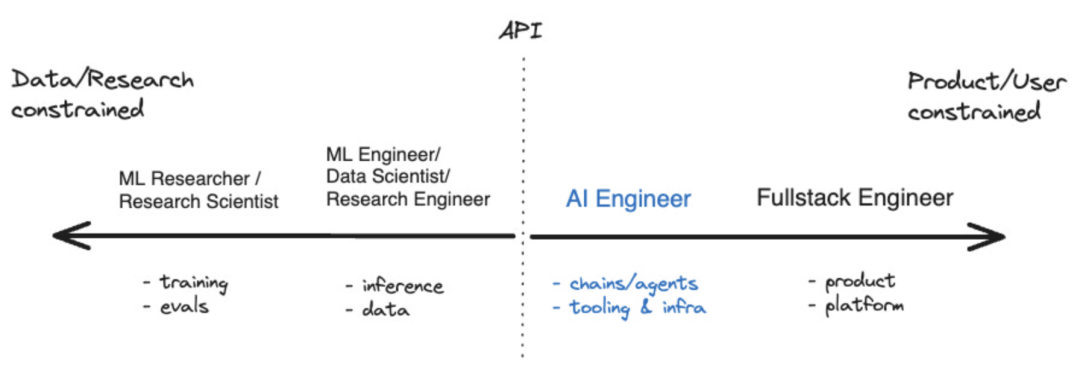 Bildquelle: a16z
Bildquelle: a16z
2 Ja, die oberste Ebene sind Daten
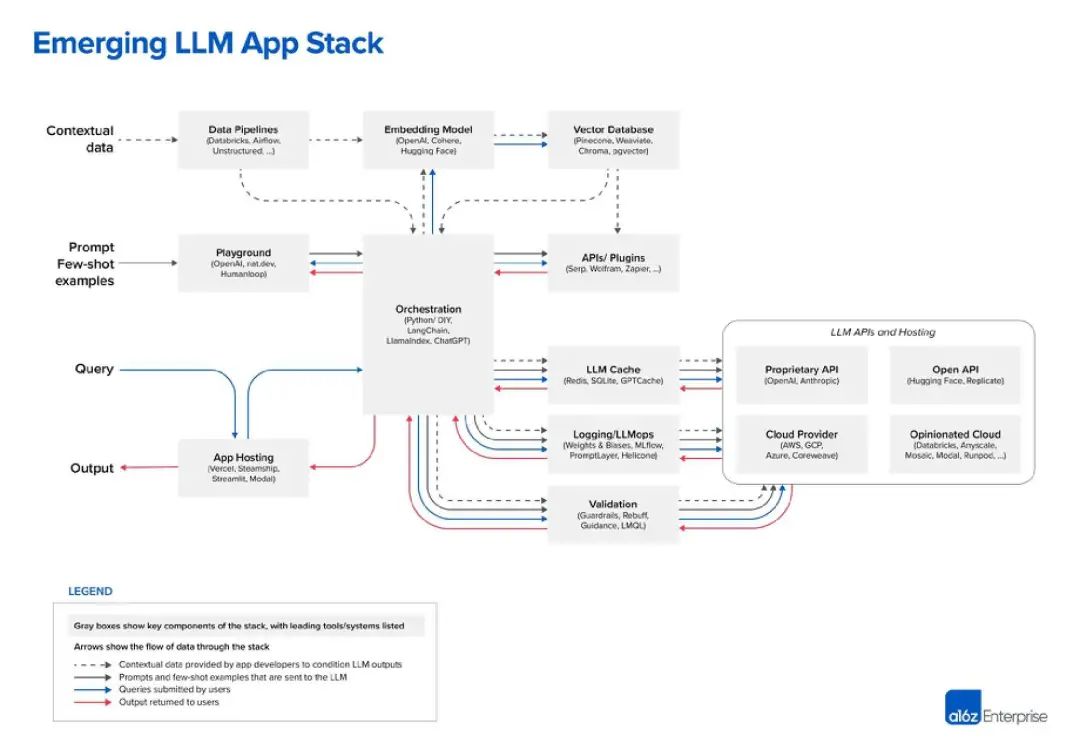 Im LLM-Technologie-Stack sind Daten die wichtigste Komponente. das ist sehr offensichtlich. Laut der Grafik von a16z liegen die Daten oben. In LLM ist das „eingebettete Modell“ ein sehr kritischer Bereich. Sie können zwischen OpenAI, Cohere, Hugging Face oder Dutzenden anderen LLM-Optionen wählen, einschließlich des immer beliebter werdenden Open-Source-LLM Vor der Verwendung von LLM ist außerdem eine „Datenpipeline“ erforderlich gegründet werden. Betrachten Sie beispielsweise Databricks und Airflow als zwei Beispiele, oder die Daten können „unstrukturiert“ verarbeitet werden. Dies gilt auch für die Periodizität von Daten und kann Unternehmen dabei helfen, die Daten zu „bereinigen“ oder einfach zu organisieren, bevor sie in ein benutzerdefiniertes LLM eingegeben werden. „Data Intelligence“-Unternehmen wie Alation bieten diese Art von Diensten an, was ein wenig nach Tools wie „Business Intelligence“ klingt, die im IT-Technologie-Stack besser bekannt sind
Im LLM-Technologie-Stack sind Daten die wichtigste Komponente. das ist sehr offensichtlich. Laut der Grafik von a16z liegen die Daten oben. In LLM ist das „eingebettete Modell“ ein sehr kritischer Bereich. Sie können zwischen OpenAI, Cohere, Hugging Face oder Dutzenden anderen LLM-Optionen wählen, einschließlich des immer beliebter werdenden Open-Source-LLM Vor der Verwendung von LLM ist außerdem eine „Datenpipeline“ erforderlich gegründet werden. Betrachten Sie beispielsweise Databricks und Airflow als zwei Beispiele, oder die Daten können „unstrukturiert“ verarbeitet werden. Dies gilt auch für die Periodizität von Daten und kann Unternehmen dabei helfen, die Daten zu „bereinigen“ oder einfach zu organisieren, bevor sie in ein benutzerdefiniertes LLM eingegeben werden. „Data Intelligence“-Unternehmen wie Alation bieten diese Art von Diensten an, was ein wenig nach Tools wie „Business Intelligence“ klingt, die im IT-Technologie-Stack besser bekannt sind
Der letzte Teil der Datenschicht ist die Vektordatenbank, die entstanden ist in letzter Zeit sehr beliebt, zum Speichern und Verarbeiten von LLM-Daten. Nach der Definition von Microsoft handelt es sich hierbei um eine Datenbank, die Daten als hochdimensionale Vektoren speichert, bei denen es sich um mathematische Darstellungen von Merkmalen oder Attributen handelt. Daten werden mithilfe der Einbettungstechnologie als Vektoren gespeichert. In einem Medienchat wies der führende Vektordatenbankanbieter Pinecone darauf hin, dass seine Tools häufig mit Datenpipeline-Tools wie Databricks verwendet werden. In diesem Fall werden die Daten typischerweise an anderer Stelle gespeichert (z. B. in einem Data Lake) und dann über ein maschinelles Lernmodell in eingebettete Daten umgewandelt. Nach der Verarbeitung und Aufteilung werden die resultierenden Vektoren an Pinecone gesendet
3. Hinweise und Abfragen
Die nächsten beiden Ebenen können als Hinweise und Abfragen zusammengefasst werden – Dies ist die KI-Anwendung mit LLM und (optional) Interaktionspunkt für andere Datentool-Schnittstellen. A16z positioniert LangChain und LlamaIndex als „Orchestrierungs-Frameworks“, was bedeutet, dass Entwickler diese Tools nutzen können, sobald sie verstehen, welches LLM sie verwenden des „Linkings“, also der Abfrage und Verwaltung von Daten zwischen der Anwendung und dem LLM. Dieser Orchestrierungsprozess umfasst die Interaktion mit externen API-Schnittstellen, das Abrufen von Kontextdaten aus der Vektordatenbank und die Verwaltung des Speichers über mehrere LLM-Aufrufe hinweg. Das interessanteste Kästchen im Diagramm von a16z ist „Playground“, das OpenAI, nat.dev und Humanloop umfasst
A16z ist im Blogbeitrag nicht genau definiert, aber wir können daraus schließen, dass „Playground“-Tools Entwicklern dabei helfen können, A16z so genannt „ Stichwort Jiu-Jitsu". An diesen Stellen können Entwickler mit verschiedenen Aufforderungstechniken experimentieren.
Humanloop ist ein britisches Unternehmen und ein Feature seiner Plattform ist der „Collaborative Prompt Workspace“. Darüber hinaus beschreibt es sich selbst als „vollständiges Entwicklungs-Toolkit für Produktions-LLM-Funktionalität“. Im Grunde ermöglicht es Ihnen also, LLM-Sachen auszuprobieren und sie dann in Ihrer Anwendung bereitzustellen, wenn es funktioniert
4. Fließbandbetrieb: LLMOps
Derzeit wird der Aufbau großer Produktionslinien allmählich klarer. Auf der rechten Seite der Orchestrierungsbox befinden sich viele Operationsboxen, einschließlich LLM-Caching und -Überprüfung. Darüber hinaus gibt es eine Reihe von LLM-bezogenen Cloud-Diensten und API-Diensten, darunter offene API-Repositories wie Hugging Face und proprietäre API-Anbieter wie OpenAI
Dies ist möglicherweise die Entwicklung, die wir vom „Cloud Native“ gewohnt sind. Die ähnlichste Sache im People-Technology-Stack ist, dass viele DevOps-Unternehmen künstliche Intelligenz zu ihrer Produktliste hinzugefügt haben, was kein Zufall ist. Im Mai sprach ich mit Jyoti Bansal, CEO von Harness. Harness betreibt eine „Software-Delivery-Plattform“, die sich auf den „CD“-Teil des CI/CD-Prozesses konzentriert.
Bansai sagte mir, dass KI die mühsamen und sich wiederholenden Aufgaben im Softwarebereitstellungslebenszyklus erleichtern kann, von der Generierung von Spezifikationen auf der Grundlage vorhandener Funktionalität bis hin zum Schreiben von Code. Darüber hinaus könne KI Codeüberprüfungen, Schwachstellentests und Fehlerbehebungen automatisieren und sogar CI/CD-Pipelines für Builds und Bereitstellungen erstellen, sagte er. Laut einem anderen Gespräch, das ich im Mai geführt habe, verändert KI auch die Entwicklerproduktivität. Trisha Gee vom Build-Automatisierungstool Gradle sagte mir, dass KI die Entwicklung beschleunigen kann, indem sie die Zeit für sich wiederholende Aufgaben wie das Schreiben von Standardcode verkürzt und es Entwicklern ermöglicht, sich auf das Gesamtbild zu konzentrieren, beispielsweise sicherzustellen, dass der Code den Geschäftsanforderungen entspricht.
5. Web3 ist draußen, der große Modellentwicklungs-Stack ist da
Im aufstrebenden LLM-Entwicklungstechnologie-Stack können wir eine Reihe neuer Produkttypen beobachten, wie zum Beispiel Orchestrierungs-Frameworks (wie LangChain und LlamaIndex), Vektordatenbanken und Humanloop Warten auf die Plattform „Spielplatz“. Alle diese Produkte erweitern und/oder ergänzen die Kerntechnologie der aktuellen Ära: große Sprachmodelle
Genauso wie der Aufstieg von Tools der Cloud-nativen Ära wie Spring Cloud und Kubernetes in den vergangenen Jahren. Aber jetzt versuchen fast alle großen, kleinen und erstklassigen Unternehmen im Cloud-nativen Zeitalter ihr Bestes, ihre Tools an die KI-Technik anzupassen, was für die zukünftige Entwicklung des LLM-Technologie-Stacks von großem Nutzen sein wird.
Ja, dieses Mal ist das große Modell wie „auf den Schultern von Riesen stehen“. Die besten Innovationen in der Computertechnologie bauen immer auf dem vorherigen Fundament auf. Vielleicht ist die „Web3“-Revolution deshalb gescheitert – sie baute nicht so sehr auf der vorherigen Generation auf, sondern versuchte, sie an sich zu reißen.
Der LLM-Technologie-Stack scheint es geschafft zu haben, er ist zu einer Brücke von der Ära der Cloud-Entwicklung zu einem neueren, auf künstlicher Intelligenz basierenden Entwickler-Ökosystem geworden
Referenzlink: https://www.php.cn/link/ c589c3a8f99401b24b9380e86d939842
Das obige ist der detaillierte Inhalt vonEs wurde ein großes Modellentwicklungs-Toolset erstellt!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte schließt sich zusammen! Ein großes Modell von Xiao Ais Zugang zu Doubao: bereits auf Mobiltelefonen und SU7 installiert
Jun 13, 2024 pm 05:11 PM
Laut Nachrichten vom 13. Juni hat Xiaomis Assistent für künstliche Intelligenz „Xiao Ai“ laut Bytes öffentlichem Bericht „Volcano Engine“ eine Zusammenarbeit mit Volcano Engine erzielt. Die beiden Parteien werden ein intelligenteres interaktives KI-Erlebnis auf der Grundlage des großen Beanbao-Modells erzielen . Berichten zufolge kann das von ByteDance erstellte groß angelegte Beanbao-Modell bis zu 120 Milliarden Text-Tokens effizient verarbeiten und täglich 30 Millionen Inhalte generieren. Xiaomi nutzte das große Doubao-Modell, um die Lern- und Denkfähigkeiten seines eigenen Modells zu verbessern und einen neuen „Xiao Ai Classmate“ zu schaffen, der nicht nur die Benutzerbedürfnisse genauer erfasst, sondern auch eine schnellere Reaktionsgeschwindigkeit und umfassendere Inhaltsdienste bietet. Wenn ein Benutzer beispielsweise nach einem komplexen wissenschaftlichen Konzept fragt, &ldq
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 KI-Hardware fügt ein weiteres Mitglied hinzu! Kann NotePin länger halten, als Mobiltelefone zu ersetzen?
Sep 02, 2024 pm 01:40 PM
KI-Hardware fügt ein weiteres Mitglied hinzu! Kann NotePin länger halten, als Mobiltelefone zu ersetzen?
Sep 02, 2024 pm 01:40 PM
Bisher hat kein Produkt im Bereich der tragbaren KI-Geräte besonders gute Ergebnisse erzielt. AIPin, das Anfang dieses Jahres auf dem MWC24 vorgestellt wurde, begann nach der Auslieferung des Evaluierungsprototyps mit dem „KI-Mythos“, der zum Zeitpunkt seiner Veröffentlichung hochgejubelt wurde, zu zerplatzen, und es erlebte innerhalb von nur wenigen Tagen große Erfolge Das RabbitR1, das sich anfangs ebenfalls gut verkaufte, war relativ gut, erhielt aber auch negative Bewertungen, ähnlich wie „Android-Hüllen“, als es in großen Mengen ausgeliefert wurde. Jetzt ist ein anderes Unternehmen in die Branche der tragbaren KI-Geräte eingestiegen. Das Technologiemedium TheVerge hat gestern einen Blogbeitrag veröffentlicht, in dem es heißt, dass das KI-Startup Plaud ein Produkt namens NotePin auf den Markt gebracht hat. Im Gegensatz zu AIFriend, das sich noch in der „Malerei“-Phase befindet, ist NotePin jetzt gestartet
 So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
So bewerten Sie die Kosteneffizienz der kommerziellen Unterstützung für Java-Frameworks
Jun 05, 2024 pm 05:25 PM
Die Bewertung des Kosten-/Leistungsverhältnisses des kommerziellen Supports für ein Java-Framework umfasst die folgenden Schritte: Bestimmen Sie das erforderliche Maß an Sicherheit und Service-Level-Agreement-Garantien (SLA). Die Erfahrung und das Fachwissen des Forschungsunterstützungsteams. Erwägen Sie zusätzliche Services wie Upgrades, Fehlerbehebung und Leistungsoptimierung. Wägen Sie die Kosten für die Geschäftsunterstützung gegen Risikominderung und Effizienzsteigerung ab.
 Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Wie ist die Lernkurve von PHP-Frameworks im Vergleich zu anderen Sprach-Frameworks?
Jun 06, 2024 pm 12:41 PM
Die Lernkurve eines PHP-Frameworks hängt von Sprachkenntnissen, Framework-Komplexität, Dokumentationsqualität und Community-Unterstützung ab. Die Lernkurve von PHP-Frameworks ist im Vergleich zu Python-Frameworks höher und im Vergleich zu Ruby-Frameworks niedriger. Im Vergleich zu Java-Frameworks haben PHP-Frameworks eine moderate Lernkurve, aber eine kürzere Einstiegszeit.
