
 Technologie-Peripheriegeräte
KI
Was ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?
Technologie-Peripheriegeräte
KI
Was ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?
Was ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?

Warum funktioniert der Transformator so gut? Woher kommt die In-Context-Learning-Fähigkeit, die es vielen großen Sprachmodellen bietet? Im Bereich der künstlichen Intelligenz hat sich der Transformer zum dominierenden Modell des Deep Learning entwickelt, die theoretischen Grundlagen für seine hervorragende Leistung sind jedoch nur unzureichend untersucht.
Kürzlich haben Forscher von Google AI, der ETH Zürich und Google DeepMind eine neue Studie durchgeführt, um zu versuchen, die Geheimnisse einiger Optimierungsalgorithmen in Google AI aufzudecken. In dieser Studie haben sie den Transformator rückentwickelt und einige Optimierungsmethoden gefunden. Dieses Papier heißt „Revealing the Mesa Optimization Algorithm in Transformer“
Link zum Papier: https://arxiv.org/abs/2309.05858
Der Autor beweist, dass die Minimierung des universellen autoregressiven Verlusts An erzeugt Hilfs-Gradienten-basierter Optimierungsalgorithmus, der im Vorwärtsdurchlauf des Transformers ausgeführt wird. Dieses Phänomen wurde kürzlich als „Mesa-Optimierung“ bezeichnet. Darüber hinaus stellten die Forscher fest, dass der resultierende Mesa-Optimierungsalgorithmus unabhängig von der Modellgröße kontextbezogene Small-Shot-Lernfähigkeiten aufwies. Die neuen Ergebnisse ergänzen daher die Prinzipien des Small-Shot-Lernens, die zuvor in großen Sprachmodellen zum Vorschein kamen.
Die Forscher glauben, dass der Erfolg von Transformers auf der architektonischen Ausrichtung des Mesa-Optimierungsalgorithmus basiert, den es im Vorwärtsdurchlauf implementiert: (i) Definition interner Lernziele und (ii) Optimierung dieser
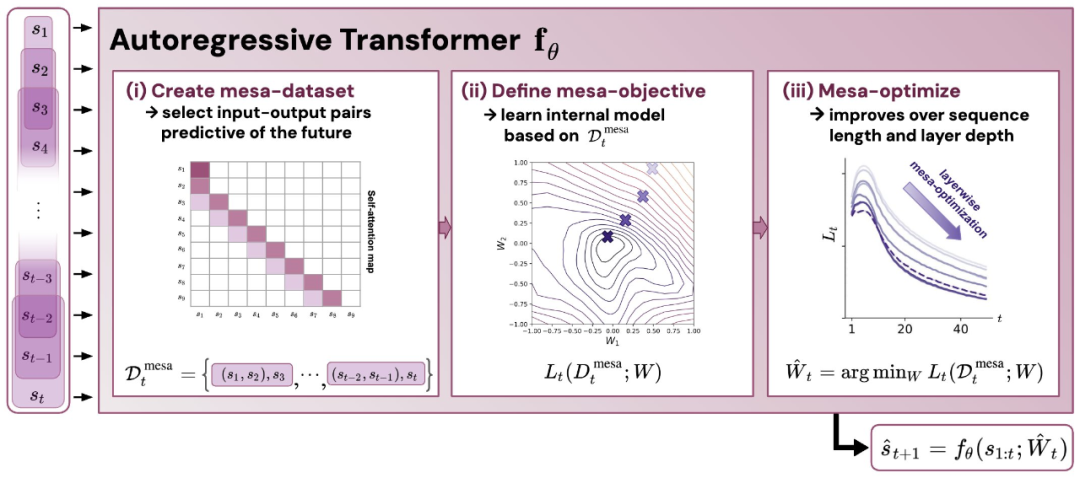
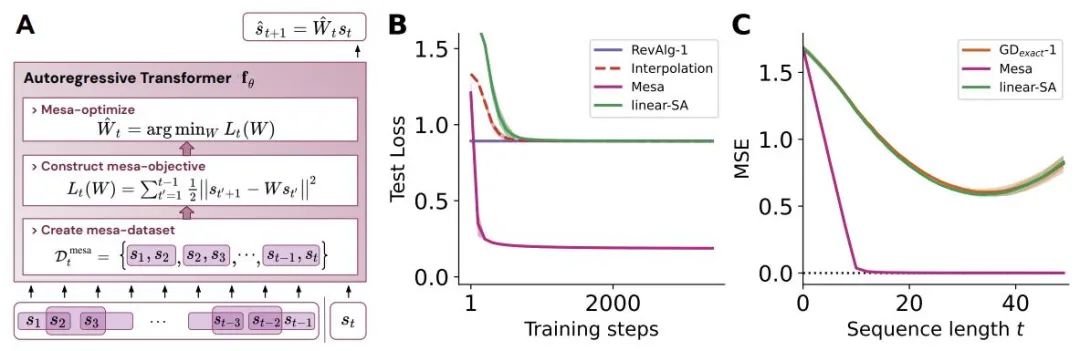
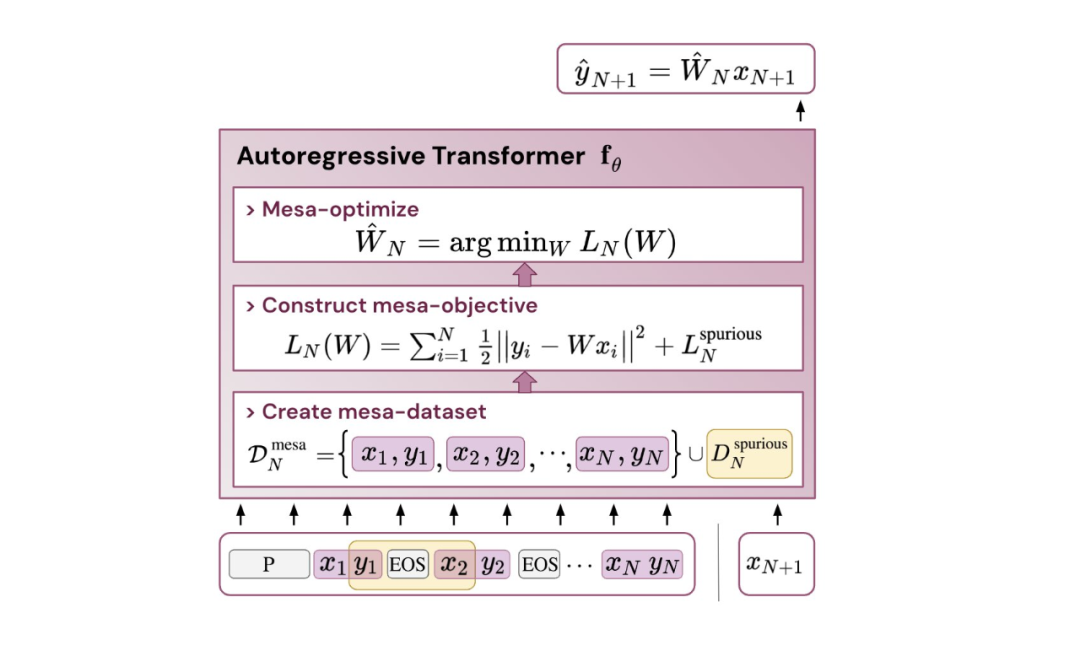
Abbildung 1: Illustration der neuen Hypothese: Die Optimierung der Gewichte θ des autoregressiven Transformators fθ führt zu einem Mesa-Optimierungsalgorithmus, der in der Vorwärtsausbreitung des Modells implementiert ist. Als Eingabesequenz s_1, . . , s_t wird bis zum Zeitschritt t verarbeitet, Transformer (i) erstellt einen internen Trainingssatz bestehend aus Eingabe-Ziel-Assoziationspaaren, (ii) definiert eine interne Zielfunktion über den Ergebnisdatensatz, die zur Messung der Leistung des internen Modells verwendet wird unter Verwendung der Gewichte W, (iii) Optimieren Sie dieses Ziel und verwenden Sie das erlernte Modell, um zukünftige Vorhersagen zu generieren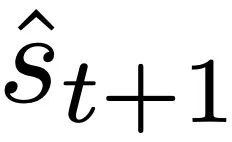 .
.
Die Beiträge dieser Studie umfassen Folgendes:
- Verallgemeinert die Theorie von Oswald et al. und zeigt, wie Transformer theoretisch intern konstruierte Ziele aus der Regression mithilfe von Gradienten-basierten Methoden optimieren und das nächste Element vorhersagen können Sequenz.
- Experimentell rückentwickelte Transformer trainierten einfache Sequenzmodellierungsaufgaben und fanden starke Beweise dafür, dass ihr Vorwärtsdurchlauf einen zweistufigen Algorithmus implementiert: (i) Frühe Selbstaufmerksamkeitsschicht über Gruppierungs- und Kopiermarkierungen baut den internen Trainingsdatensatz auf Der interne Trainingsdatensatz wird implizit erstellt. Definieren Sie interne Zielfunktionen und (ii) optimieren Sie diese Ziele auf einer tieferen Ebene, um Vorhersagen zu generieren.
- Ähnlich wie bei LLM zeigen Experimente, dass auch einfache autoregressive Trainingsmodelle zu Kontextlernern werden können, und spontane Anpassungen sind entscheidend für die Verbesserung des Kontextlernens von LLM und können auch die Leistung in bestimmten Umgebungen verbessern.
- Inspiriert durch die Entdeckung, dass Aufmerksamkeitsschichten versuchen, die interne Zielfunktion implizit zu optimieren, stellt der Autor die Mesa-Schicht vor, eine neue Art von Aufmerksamkeitsschicht, die das Optimierungsproblem der kleinsten Quadrate effektiv lösen kann, anstatt nur einzelne Gradientenschritte durchzuführen Optimalität zu erreichen. Experimente zeigen, dass eine einzelne Mesa-Schicht Deep-Linear- und Softmax-Selbstaufmerksamkeitstransformatoren bei einfachen sequentiellen Aufgaben übertrifft und gleichzeitig eine bessere Interpretierbarkeit bietet.

- Nach vorläufigen Sprachmodellierungsexperimenten wurde festgestellt, dass das Ersetzen der Standard-Selbstaufmerksamkeitsschicht durch die Mesa-Schicht vielversprechende Ergebnisse erzielte, was beweist, dass diese Schicht über starke kontextbezogene Lernfähigkeiten verfügt.
Basierend auf aktuellen Arbeiten, die zeigen, dass Transformatoren, die explizit darauf trainiert sind, kleine Aufgaben im Kontext zu lösen, Gradientenabstiegsalgorithmen (GD) implementieren können. Hier zeigen die Autoren, dass sich diese Ergebnisse auf die autoregressive Sequenzmodellierung übertragen lassen – einen typischen Ansatz zum Training von LLMs.
Analysieren Sie zunächst den auf einfache lineare Dynamik trainierten Transformer. In diesem Fall wird jede Sequenz von einem anderen W* generiert, um eine sequenzübergreifende Speicherung zu verhindern. In diesem einfachen Aufbau zeigen die Forscher, wie Transformer einen Mesa-Datensatz erstellt und vorverarbeitete GD verwendet, um das Mesa-Ziel zu optimieren
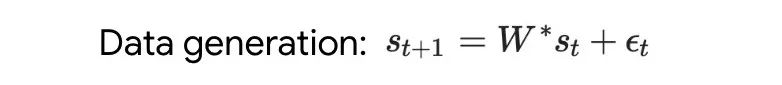
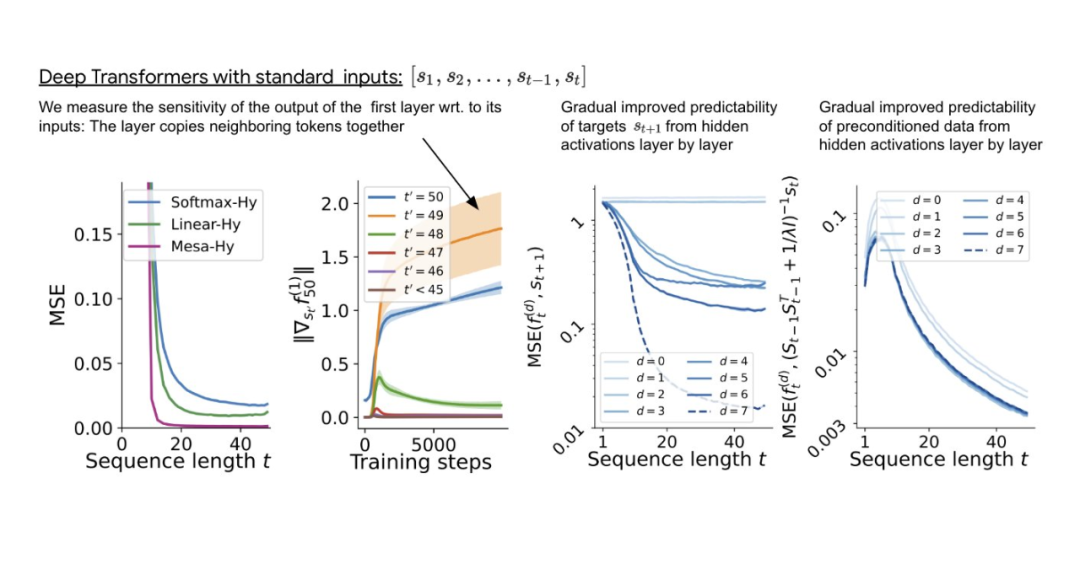
Der umgeschriebene Inhalt lautet: Wir können die Token-Struktur benachbarter Sequenzelemente aggregieren, indem wir einen Tiefentransformator trainieren. Interessanterweise führt diese einfache Vorverarbeitungsmethode zu einer sehr spärlichen Gewichtsmatrix (weniger als 1 % der Gewichte sind ungleich Null), was zu einem Reverse-Engineering-Algorithmus führt Gewichte Entspricht einem Gradientenabstiegsschritt. Für tiefe Transformer wird die Interpretierbarkeit schwierig. Die Studie basiert auf linearem Sondieren und untersucht, ob versteckte Aktivierungen in der Lage sind, autoregressive Ziele oder vorverarbeitete Eingaben vorherzusagen.
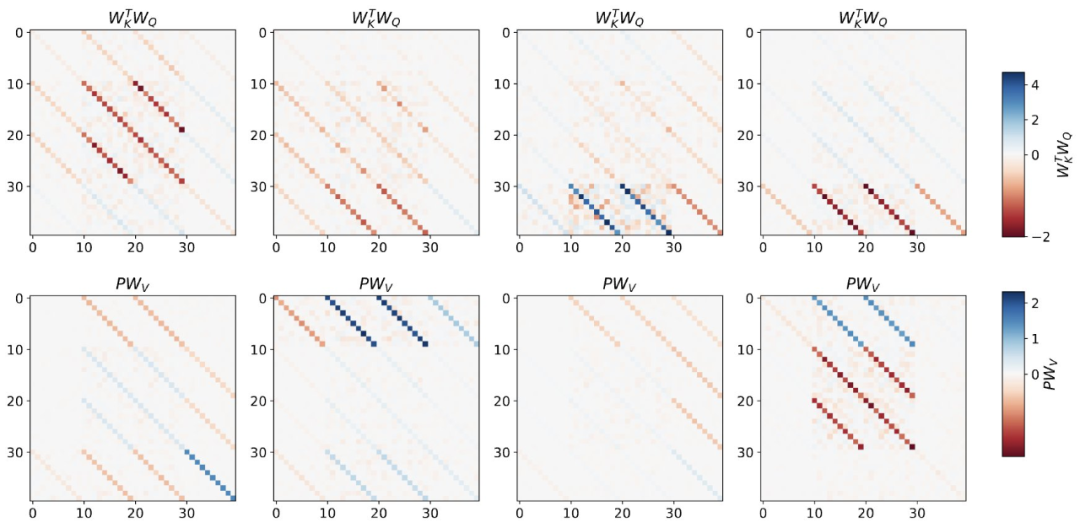 Interessanterweise verbessert sich die Vorhersagbarkeit beider Sondierungsmethoden mit zunehmender Netzwerktiefe allmählich. Dieser Befund legt nahe, dass vorverarbeitete GD im Modell verborgen ist.
Interessanterweise verbessert sich die Vorhersagbarkeit beider Sondierungsmethoden mit zunehmender Netzwerktiefe allmählich. Dieser Befund legt nahe, dass vorverarbeitete GD im Modell verborgen ist.
Abbildung 2: Reverse Engineering einer trainierten linearen Selbstaufmerksamkeitsschicht.
 Die Studie ergab, dass die Trainingsschicht perfekt angepasst werden kann, wenn alle Freiheitsgrade in der Konstruktion genutzt werden, einschließlich nicht nur der erlernten Lernrate η, sondern auch einer Reihe erlernter Anfangsgewichte W_0. Wichtig ist, dass der erlernte einstufige Algorithmus, wie in Abbildung 2 dargestellt, immer noch eine weitaus bessere Leistung erbringt als eine einzelne Mesa-Schicht.
Die Studie ergab, dass die Trainingsschicht perfekt angepasst werden kann, wenn alle Freiheitsgrade in der Konstruktion genutzt werden, einschließlich nicht nur der erlernten Lernrate η, sondern auch einer Reihe erlernter Anfangsgewichte W_0. Wichtig ist, dass der erlernte einstufige Algorithmus, wie in Abbildung 2 dargestellt, immer noch eine weitaus bessere Leistung erbringt als eine einzelne Mesa-Schicht.
Mit einer einfachen Gewichtseinstellung können wir feststellen, dass es durch grundlegende Optimierung leicht ist, herauszufinden, dass diese Ebene diese Forschungsaufgabe optimal lösen kann. Dieses Ergebnis beweist, dass eine hartcodierte induktive Vorspannung für die Mesa-Optimierung von Vorteil ist
Mit theoretischen Einblicken in den Mehrschichtfall analysieren Sie zunächst Deep Linear und Softmax und achten Sie nur auf Transformer. Die Autoren formatieren die Eingabe gemäß einer 4-Kanal-Struktur,
, was der Wahl von W_0 = 0 entspricht.
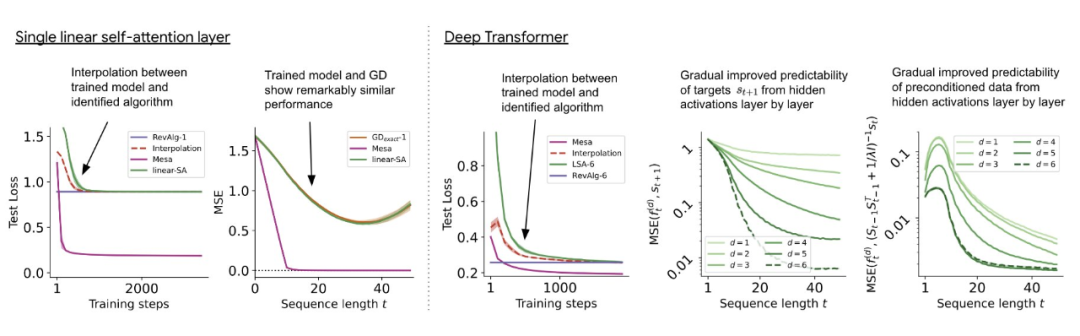
Wie beim einschichtigen Modell sehen die Autoren eine klare Struktur in den Gewichten des trainierten Modells. Als erste Reverse-Engineering-Analyse nutzt diese Studie diese Struktur und erstellt einen Algorithmus (RevAlg-d, wobei d die Anzahl der Schichten darstellt), der 16 Parameter pro Schichtkopf (anstelle von 3200) enthält. Die Autoren fanden heraus, dass dieser komprimierte, aber komplexe Ausdruck das trainierte Modell beschreiben kann. Insbesondere ermöglicht es eine nahezu verlustfreie Interpolation zwischen den tatsächlichen Transformer- und RevAlg-d-Gewichten  Während der RevAlg-d-Ausdruck einen trainierten mehrschichtigen Transformer mit einer kleinen Anzahl freier Parameter erklärt, ist die Konvertierung schwierig Seine Erklärung ist der Mesa-Optimierungsalgorithmus. Daher verwendeten die Autoren eine lineare Regressionsuntersuchungsanalyse (Alain & Bengio, 2017; Akyürek et al., 2023), um die Eigenschaften des hypothetischen Mesa-Optimierungsalgorithmus zu ermitteln.
Während der RevAlg-d-Ausdruck einen trainierten mehrschichtigen Transformer mit einer kleinen Anzahl freier Parameter erklärt, ist die Konvertierung schwierig Seine Erklärung ist der Mesa-Optimierungsalgorithmus. Daher verwendeten die Autoren eine lineare Regressionsuntersuchungsanalyse (Alain & Bengio, 2017; Akyürek et al., 2023), um die Eigenschaften des hypothetischen Mesa-Optimierungsalgorithmus zu ermitteln.
Auf dem in Abbildung 3 gezeigten tiefen linearen Selbstaufmerksamkeitstransformator können wir beobachten, dass beide Sonden zur linearen Dekodierung fähig sind und mit zunehmender Sequenzlänge und Netzwerktiefe auch die Dekodierungsleistung zunimmt. Daher haben wir einen grundlegenden Optimierungsalgorithmus entdeckt, der basierend auf dem ursprünglichen Mesa-Ziel Lt (W) Schicht für Schicht absteigt und gleichzeitig die Bedingungszahl des Mesa-Optimierungsproblems verbessert. Dies führt zu einem raschen Rückgang des Mesa-Ziel-Lt (W). Darüber hinaus können wir auch beobachten, dass sich die Leistung mit zunehmender Tiefe deutlich verbessert
Mit einer besseren Vorverarbeitung der Daten kann die autoregressive Zielfunktion Lt (W) schrittweise (über Schichten hinweg) optimiert werden, sodass ein schneller Rückgang berücksichtigt werden kann Dies wird durch diese Optimierung erreicht
Abbildung 3: Mehrschichtiges Transformer-Training für Reverse Engineering der konstruierten Token-Eingabe.
 Dies zeigt, dass der Transformator, wenn er auf dem erstellten Token trainiert wird, mit Mesa-Optimierung Vorhersagen trifft. Wenn Sequenzelemente direkt angegeben werden, erstellt der Transformator interessanterweise das Token selbst, indem er die Elemente gruppiert, was das Forschungsteam als „Erstellen des Mesa-Datensatzes“ bezeichnet.
Dies zeigt, dass der Transformator, wenn er auf dem erstellten Token trainiert wird, mit Mesa-Optimierung Vorhersagen trifft. Wenn Sequenzelemente direkt angegeben werden, erstellt der Transformator interessanterweise das Token selbst, indem er die Elemente gruppiert, was das Forschungsteam als „Erstellen des Mesa-Datensatzes“ bezeichnet.
Schlussfolgerung
Das Ergebnis dieser Studie ist, dass Gradienten-basierte Inferenzalgorithmen entwickelt werden können, wenn sie mit dem Transformer-Modell für Sequenzvorhersageaufgaben unter standardmäßigen autoregressiven Zielen trainiert werden. Daher können die neuesten Multitasking- und Meta-Learning-Ergebnisse auch auf traditionelle selbstüberwachte LLM-Trainingseinstellungen angewendet werden
Darüber hinaus ergab die Studie, dass der erlernte autoregressive Inferenzalgorithmus ohne erneutes Training neu abgestimmt werden kann um überwachte kontextuelle Lernaufgaben zu lösen und so die Ergebnisse in einem einheitlichen Rahmen zu interpretieren
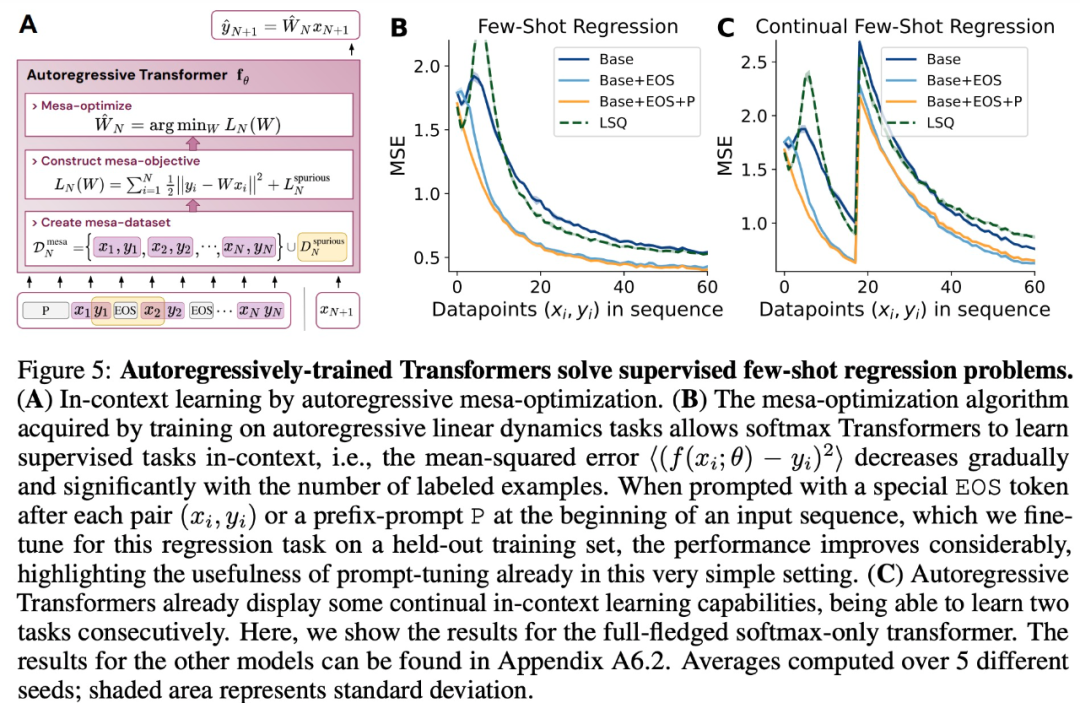
Was hat das also mit kontextuellem Lernen zu tun? Der Studie zufolge erreicht das Transformatormodell nach dem Training der autoregressiven Sequenzaufgabe eine angemessene Mesa-Optimierung und kann daher ein Kontextlernen mit wenigen Schüssen ohne Feinabstimmung durchführen. Die Studie geht davon aus, dass auch LLM existiert Mesa-Optimierung, wodurch die kontextbezogenen Lernfähigkeiten verbessert werden. Interessanterweise wurde in der Studie auch festgestellt, dass die effektive Anpassung von Eingabeaufforderungen für LLM auch zu erheblichen Verbesserungen der kontextuellen Lernfähigkeiten führen kann.
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonWas ist die Quelle der kontextuellen Lernfähigkeiten von Transformer?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Das 70B-Modell generiert 1.000 Token in Sekunden, das Umschreiben des Codes übertrifft GPT-4o, vom Cursor-Team, einem von OpenAI investierten Code-Artefakt
Jun 13, 2024 pm 03:47 PM
Das 70B-Modell generiert 1.000 Token in Sekunden, das Umschreiben des Codes übertrifft GPT-4o, vom Cursor-Team, einem von OpenAI investierten Code-Artefakt
Jun 13, 2024 pm 03:47 PM
Beim Modell 70B können 1000 Token in Sekunden generiert werden, was fast 4000 Zeichen entspricht! Die Forscher haben Llama3 verfeinert und einen Beschleunigungsalgorithmus eingeführt. Im Vergleich zur nativen Version ist die Geschwindigkeit 13-mal höher! Es ist nicht nur schnell, seine Leistung bei Code-Rewriting-Aufgaben übertrifft sogar GPT-4o. Diese Errungenschaft stammt von anysphere, dem Team hinter dem beliebten KI-Programmierartefakt Cursor, und auch OpenAI beteiligte sich an der Investition. Sie müssen wissen, dass bei Groq, einem bekannten Framework zur schnellen Inferenzbeschleunigung, die Inferenzgeschwindigkeit von 70BLlama3 nur mehr als 300 Token pro Sekunde beträgt. Aufgrund der Geschwindigkeit von Cursor kann man sagen, dass eine nahezu sofortige vollständige Bearbeitung der Codedatei möglich ist. Manche Leute nennen es einen guten Kerl, wenn man Curs sagt
