
 Technologie-Peripheriegeräte
KI
Lao Huang gibt H100 einen Schub: Nvidia bringt großes Modellbeschleunigungspaket auf den Markt, das die Inferenzgeschwindigkeit von Llama2 verdoppelt
Technologie-Peripheriegeräte
KI
Lao Huang gibt H100 einen Schub: Nvidia bringt großes Modellbeschleunigungspaket auf den Markt, das die Inferenzgeschwindigkeit von Llama2 verdoppelt
Lao Huang gibt H100 einen Schub: Nvidia bringt großes Modellbeschleunigungspaket auf den Markt, das die Inferenzgeschwindigkeit von Llama2 verdoppelt

Die Inferenzgeschwindigkeit großer Modelle hat sich in nur einem Monat verdoppelt!
NVIDIA hat kürzlich die Einführung eines speziell für H100 entwickelten „Hühnerblutpakets“ angekündigt, das den LLM-Inferenzprozess beschleunigen soll
Vielleicht müssen Sie jetzt nicht mehr auf die Auslieferung des GH200 im nächsten Jahr warten .
.
Die Rechenleistung der GPU hat sich schon immer auf die Leistung großer Modelle ausgewirkt. Sowohl Hardwarelieferanten als auch Benutzer hoffen auf schnellere Rechengeschwindigkeiten.
Als größter Hardwarelieferant hinter großen Modellen habe ich mich mit der Hardware befasst Beschleunigen Sie große Modelle.
Durch die Zusammenarbeit mit einer Reihe von KI-Unternehmen hat NVIDIA schließlich das große Modellinferenzoptimierungsprogramm TensorRT-LLM (vorläufig als TensorRT bezeichnet) auf den Markt gebracht.
TensorRT kann nicht nur die Inferenzgeschwindigkeit großer Modelle verdoppeln, sondern ist auch sehr bequem zu verwenden.
Sie benötigen keine fundierten Kenntnisse in C++ und CUDA, Sie können Optimierungsstrategien schnell anpassen und große Modelle schneller auf H100 ausführen.
NVIDIA-Wissenschaftler Jim Fan hat retweetet und kommentiert, dass NVIDIAs „weiterer Vorteil“ die unterstützende Software ist, die die Nutzung der GPU-Leistung maximieren kann.
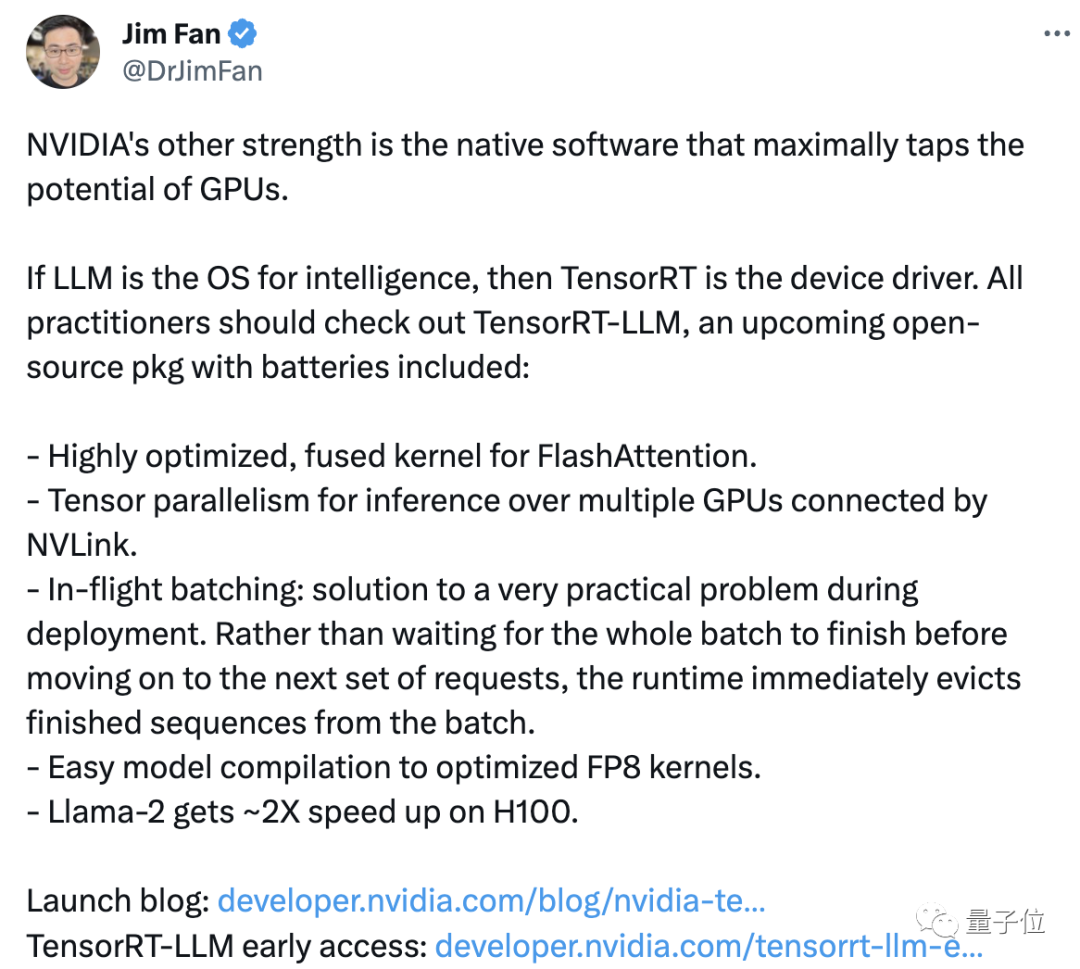
NVIDIA verleiht seinen Produkten durch Software neue Vitalität, genau wie es Lao Huangs Sprichwort „Je mehr Sie kaufen, desto mehr sparen Sie“ umsetzt. Dies hält jedoch einige Leute nicht davon ab, zu denken, dass der Preis des Produkts zu hoch ist (in der Öffentlichkeit), aber wenn ich Llama 2 selbst ausführe, kann ich immer noch nur Dutzende Token pro Sekunde verarbeiten.
Für TensorRT benötigen wir weitere Tests, um festzustellen, ob es wirklich effektiv ist. Werfen wir zunächst einen genaueren Blick auf TensorRT
Verdoppeln Sie die Inferenzgeschwindigkeit großer Modelle
TensorRT-LLM-optimiertes H100. Wie schnell ist es für die Ausführung großer Modelle? 
.
TensorRT bietet außerdem eine modulare Open-Source-Python-API, mit der Optimierungslösungen schnell an unterschiedliche LLM-Anforderungen angepasst werden können. Diese API integriert Deep-Learning-Compiler, Kerneloptimierung, Vor-/Nachbearbeitung und Multi-Node-Kommunikationsfunktionen .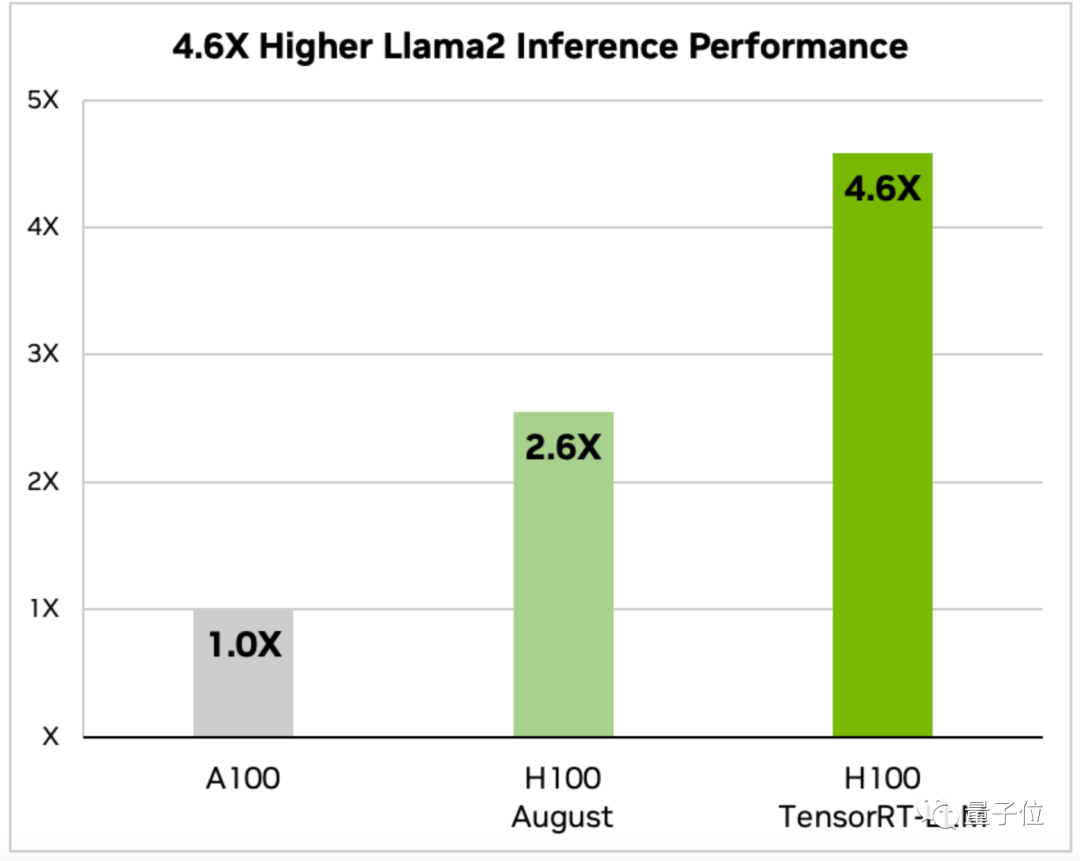 Es gibt auch angepasste Versionen für gängige Modelle wie GPT(2/3) und Llama, die
Es gibt auch angepasste Versionen für gängige Modelle wie GPT(2/3) und Llama, die
verwendet werden können. Durch den neuesten Open-Source-KI-Kernel in TensorRT können Entwickler auch das Modell selbst optimieren, einschließlich des Aufmerksamkeitsalgorithmus FlashAttention, der Transformer erheblich beschleunigt.
TensorRT ist eine leistungsstarke Inferenz-Engine zur Optimierung von Deep-Learning-Inferenzen. Es optimiert die LLM-Inferenzgeschwindigkeit durch den Einsatz von Technologien wie Mixed-Precision-Computing, dynamischer Graphoptimierung und Layer-Fusion. Insbesondere verbessert TensorRT die Inferenzgeschwindigkeit, indem es den Rechenaufwand und den Bedarf an Speicherbandbreite reduziert, indem Gleitkommaberechnungen in Gleitkommaberechnungen mit halber Genauigkeit umgewandelt werden. Darüber hinaus nutzt TensorRT auch die Technologie zur dynamischen Graphenoptimierung, um dynamisch die optimale Netzwerkstruktur basierend auf den Eigenschaften der Eingabedaten auszuwählen und so die Inferenzgeschwindigkeit weiter zu verbessern. Darüber hinaus nutzt TensorRT auch die Layer-Fusion-Technologie, um mehrere Rechenschichten zu einer effizienteren Rechenschicht zusammenzuführen, wodurch der Rechen- und Speicherzugriffsaufwand reduziert und die Inferenzgeschwindigkeit weiter verbessert wird. Kurz gesagt, TensorRT hat die Geschwindigkeit und Effizienz der LLM-Inferenz durch eine Vielzahl von Optimierungstechnologien erheblich verbessert. Zunächst einmal profitiert es von TensorRT, indem es die kollaborative Arbeitsmethode mit mehreren Knoten optimiert. 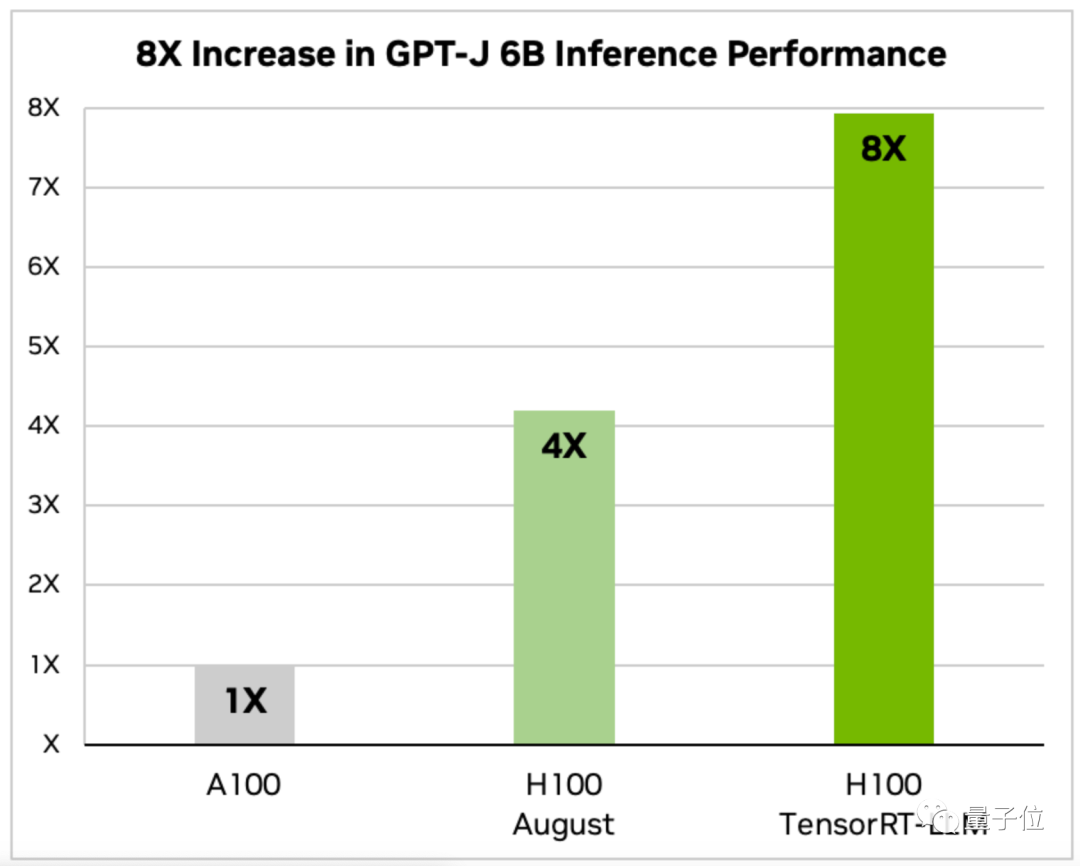
In der Vergangenheit erforderte diese Arbeit, dass Menschen das Modell manuell zerlegen mussten, um dies zu erreichen.
Mit TensorRT kann das System das Modell automatisch aufteilen und über NVLink effizient auf mehreren GPUs ausführen

Zweitens nutzt TensorRT auch eine optimierte Planung namens „Dynamic Batch Processing“-Technologie. Während des Inferenzprozesses funktioniert LLM tatsächlich, indem es Modelliterationen mehrmals ausführt.
Die dynamische Stapelverarbeitungstechnologie wirft abgeschlossene Sequenzen sofort aus, anstatt auf den Abschluss des gesamten Aufgabenstapels zu warten, bevor der nächste Satz von Anforderungen verarbeitet wird.
In tatsächlichen Tests konnte die dynamische Batch-Technologie den GPU-Anforderungsdurchsatz von LLM erfolgreich um die Hälfte reduzieren und dadurch die Betriebskosten deutlich senken.
Ein weiterer wichtiger Punkt ist die
Konvertierung von Gleitkommazahlen mit 16-Bit-Präzision in 8-Bit-Genauigkeit, wodurch der Speicherverbrauch reduziert wird. Im Vergleich zu FP16 in der Trainingsphase hat FP8 einen geringeren Ressourcenverbrauch und ist genauer als INT-8. Es kann die Leistung verbessern, ohne die Genauigkeit des Modells zu beeinträchtigen.
Mit der Hopper Transformer-Engine führt das System FP16 automatisch durch zur FP8-Konvertierungskompilierung, ohne den Code im Modell manuell zu ändern
Derzeit steht die Early-Bird-Version von TensorRT-LLM zum Download zur Verfügung, und die offizielle Version wird in ein paar Wochen veröffentlicht und in das NeMo-Framework integriert
One More Ding
Immer wenn ein großes Ereignis stattfindet, ist die Figur „Leewenhoek“ unverzichtbar.
In der Ankündigung von Nvidia wurde die Zusammenarbeit mit führenden Unternehmen für künstliche Intelligenz wie Meta erwähnt, OpenAI jedoch nicht erwähnt
Aus dieser Ankündigung heraus entdeckten einige Internetnutzer diesen Punkt und veröffentlichten ihn im OpenAI-Forum:
Bitte lassen Sie mich sehen, wer wurde nicht von Lao Huang (manueller Hundekopf) angeregt Welche Art von „Überraschung“ wird uns Lao Huang Ihrer Meinung nach bringen?
Welche Art von „Überraschung“ wird uns Lao Huang Ihrer Meinung nach bringen?
Das obige ist der detaillierte Inhalt vonLao Huang gibt H100 einen Schub: Nvidia bringt großes Modellbeschleunigungspaket auf den Markt, das die Inferenzgeschwindigkeit von Llama2 verdoppelt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wie man Debian Hadoop Log Management macht
Apr 13, 2025 am 10:45 AM
Wenn Sie Hadoop-Protokolle auf Debian verwalten, können Sie die folgenden Schritte und Best Practices befolgen: Protokollaggregation Aktivieren Sie die Protokollaggregation: Set Garn.log-Aggregation-Enable in true in der Datei marn-site.xml, um die Protokollaggregation zu aktivieren. Konfigurieren von Protokoll-Retentionsrichtlinien: Setzen Sie Garn.log-Aggregation.Retain-Sekunden, um die Retentionszeit des Protokolls zu definieren, z. B. 172800 Sekunden (2 Tage). Log Speicherpfad angeben: über Garn.n
