
 Technologie-Peripheriegeräte
KI
Baidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis
Technologie-Peripheriegeräte
KI
Baidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis
Baidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis


1. Verständnis multimodaler Rich-Media-Inhalte
Lassen Sie uns zunächst unsere Wahrnehmung multimodaler Inhalte vorstellen.
1. Multimodales Verständnis
Verbesserung der Inhaltsverständnisfähigkeiten, sodass das Werbesystem Inhalte in segmentierten Szenarien besser verstehen kann.

Bei der Verbesserung der Inhaltsverständnisfähigkeiten werden Sie auf viele praktische Probleme stoßen:
- Es gibt viele kommerzielle Geschäftsszenarien und Branchen, unabhängige Modellierung ist überflüssig und führt zu einer Überanpassung und einer Verteilung zwischen Szenarien Wie man Gemeinsamkeit und Spezifität bei der einheitlichen Modellierung in Einklang bringt.
- Schlechter Text rund um kommerzielle Bildmaterialien kann leicht zu schlechten Fallillustrationen führen.
- Das System ist voller bedeutungsloser ID-Funktionen und weist eine schlechte Verallgemeinerung auf.
- Im Zeitalter von Rich Media müssen wir eine Lösung finden, wie wir die visuelle Semantik effektiv nutzen und diese Inhaltsfunktionen, Videofunktionen und andere Funktionen integrieren können, um die Wahrnehmung von Rich Media-Inhalten im System zu verbessern.
Was ist eine gute multimodale Basisdarstellung?
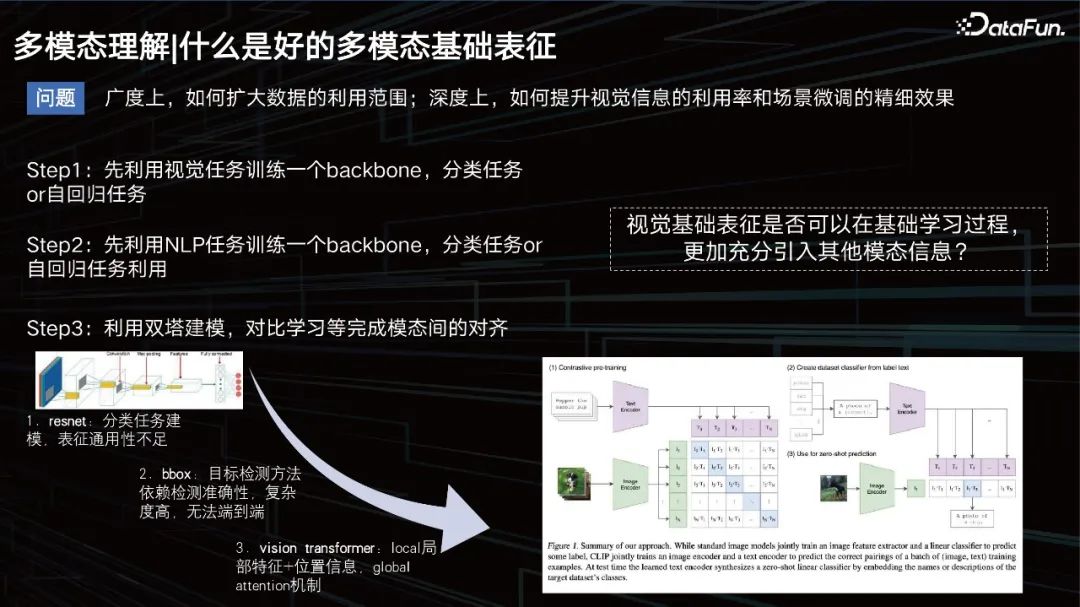
Was ist eine gute multimodale Darstellung?
In der Breite muss der Umfang der Datenanwendung erweitert werden, in der Tiefe müssen die visuellen Effekte verbessert und gleichzeitig die Datenfeinabstimmung der Szene sichergestellt werden.
Früher bestand die herkömmliche Idee darin, ein Modell zu trainieren, um die Modalität von Bildern zu erlernen, eine autoregressive Aufgabe, dann die Textaufgabe auszuführen und dann einige Twin-Tower-Muster anzuwenden, um die modale Beziehung zwischen den beiden zu schließen. Zu dieser Zeit war die Textmodellierung relativ einfach und jeder beschäftigte sich mehr damit, wie man Visionen modelliert. Es begann mit CNN und umfasste später einige auf der Zielerkennung basierende Methoden, um die visuelle Darstellung zu verbessern, wie beispielsweise die Bbox-Methode. Diese Methode verfügt jedoch über begrenzte Erkennungsfähigkeiten und ist zu umfangreich, was für ein umfangreiches Datentraining nicht förderlich ist.
Um 2020 und 2021 ist die VIT-Methode zum Mainstream geworden. Eines der bekannteren Modelle, das ich hier erwähnen muss, ist CLIP, ein 2020 von OpenAI veröffentlichtes Modell, das auf der Twin-Tower-Architektur für Text und visuelle Darstellung basiert. Verwenden Sie dann den Kosinus, um den Abstand zwischen den beiden zu schließen. Dieses Modell eignet sich sehr gut zum Abrufen, ist jedoch bei einigen Aufgaben, die logisches Denken erfordern, wie z. B. VQA-Aufgaben, etwas weniger leistungsfähig.
Darstellung lernen: Verbessern Sie die grundlegende Wahrnehmungsfähigkeit der natürlichen Sprache zum Sehen.
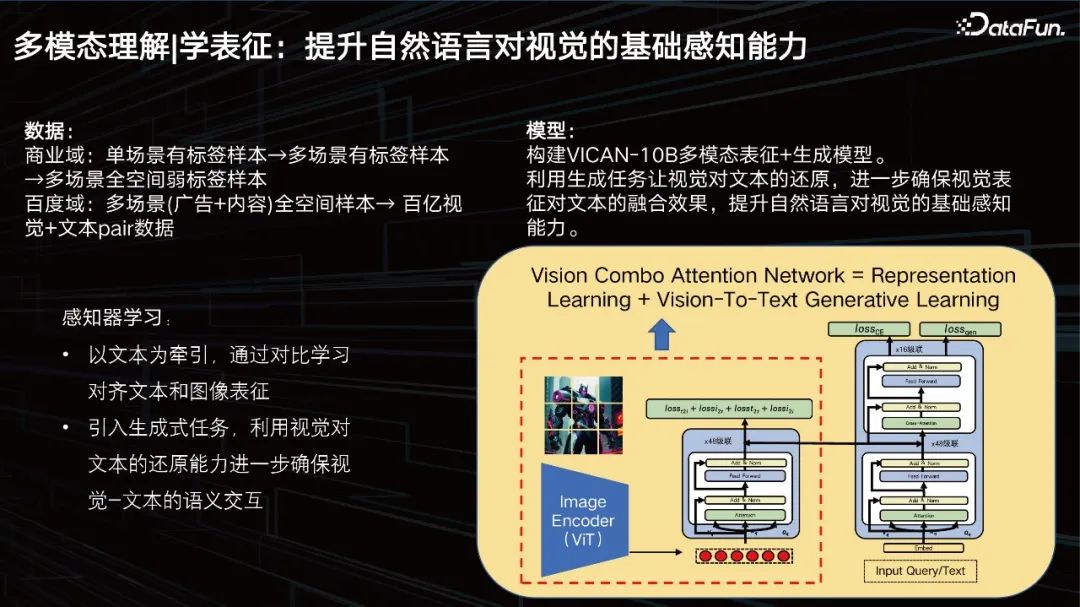
Unser Ziel ist es, die grundlegende Wahrnehmung visueller Sprache durch natürliche Sprache zu verbessern. In Bezug auf die Daten verfügt unser Geschäftsbereich über Milliarden von Daten, aber das reicht immer noch nicht aus. Wir müssen weiter expandieren, frühere Daten aus dem Geschäftsbereich einführen und sie bereinigen und sortieren. Es wurde ein Trainingssatz im Dutzend-Milliarden-Bereich erstellt.
Wir haben das multimodale Darstellungs- und Generierungsmodell VICAN-12B erstellt und dabei die Generierungsaufgabe verwendet, um dem Sehvermögen die Wiederherstellung von Text zu ermöglichen, den Fusionseffekt der visuellen Darstellung auf dem Text weiter sicherzustellen und die grundlegende Wahrnehmung natürlicher Sprache beim Sehen zu verbessern . Das Bild oben zeigt die Gesamtstruktur des Modells. Sie können sehen, dass es sich um eine Verbundstruktur aus Zwillingstürmen und einem einzelnen Turm handelt. Denn das erste, was gelöst werden muss, ist eine groß angelegte Bildabrufaufgabe. Der Teil im Kasten links ist das, was wir das visuelle Perzeptron nennen, eine ViT-Struktur mit einer Skala von 2 Milliarden Parametern. Die rechte Seite kann in zwei Ebenen angezeigt werden. Der untere Teil ist ein Stapel von Texttransformatoren zum Abrufen und der obere Teil dient der Generierung. Das Modell ist in drei Aufgaben unterteilt: Eine ist eine Generierungsaufgabe, eine ist eine Klassifizierungsaufgabe und die andere ist eine Bildvergleichsaufgabe. Das Modell wird auf der Grundlage dieser drei unterschiedlichen Ziele trainiert und hat daher relativ gute Ergebnisse erzielt werde es weiter optimieren.
Eine Reihe effizienter, einheitlicher und übertragbarer globaler Darstellungsschemata für mehrere Szenarien.

In Kombination mit Geschäftsszenariodaten wird das LLM-Modell eingeführt, um die Fähigkeiten zum Modellverständnis zu verbessern. Das CV-Modell ist das Perzeptron und das LLM-Modell ist der Versteher. Unser Ansatz besteht darin, die visuellen Merkmale entsprechend zu übertragen, da die Darstellung, wie gerade erwähnt, multimodal ist und das große Modell auf Text basiert. Wir müssen es nur an das große Modell unseres Wenxin LLM anpassen, also müssen wir Combo-Aufmerksamkeit verwenden, um die entsprechende Feature-Fusion durchzuführen. Wir müssen die logischen Argumentationsfunktionen des großen Modells beibehalten, daher versuchen wir, das große Modell nicht allein zu lassen und nur Feedbackdaten zum Geschäftsszenario hinzuzufügen, um die Integration visueller Funktionen in das große Modell zu fördern. Zur Unterstützung der Aufgabe können wir wenige Schüsse gebrauchen. Zu den Hauptaufgaben gehören:
- Die Beschreibung des Bildes ist tatsächlich nicht nur eine Beschreibung, sondern ein schnelles Reverse Engineering, das als bessere Datenquelle für uns verwendet werden kann Vincent-Diagramme später.
- Bild- und Textkorrelationskontrolle, da Unternehmen die Konfiguration und das Verständnis von Bildinformationen benötigen, müssen die Suchbegriffe und die Bildsemantik unserer Werbebilder tatsächlich kontrolliert werden. Dies ist natürlich eine sehr allgemeine Methode, die Sie erstellen können relevante Urteile zu Bildern und Eingabeaufforderungen.
- Bildrisiko- und Erfahrungskontrolle: Wir konnten den Inhalt des Bildes relativ gut beschreiben, dann müssen wir nur eine kleine Beispieldatenmigration der Risikokontrolle verwenden, um klar zu wissen, ob es sich um einige Risikoprobleme handelt .
Konzentrieren wir uns nun auf die szenenbasierte Feinabstimmung.
2. Szenariobasierte Feinabstimmung
Visuelle Abrufszene, Zwillingsturm-Feinabstimmung basierend auf der Grunddarstellung.
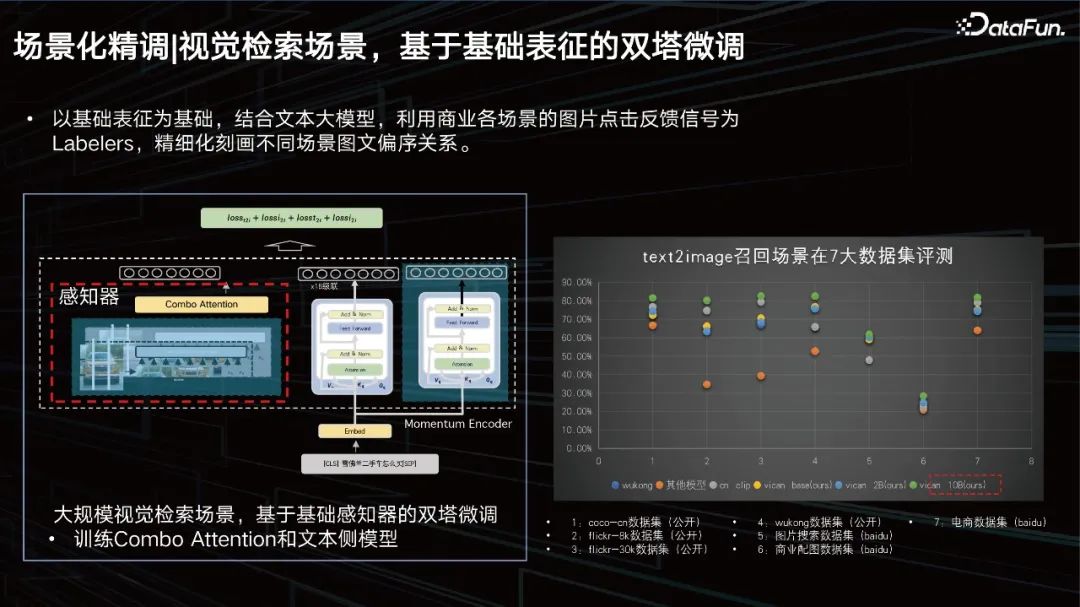
Basierend auf der Grunddarstellung werden in Kombination mit dem großen Textmodell die Bildklick-Feedbacksignale verschiedener Geschäftsszenen als Beschriftungsgeräte verwendet, um die Teilordnungsbeziehung zwischen Bildern und Texten in verschiedenen Szenen zu verfeinern. Wir haben Auswertungen für 7 große Datensätze durchgeführt und alle können SOTA-Ergebnisse erzielen.
Sortierungsszenario, inspiriert von der Textsegmentierung, quantifiziert die Semantik multimodaler Merkmale.
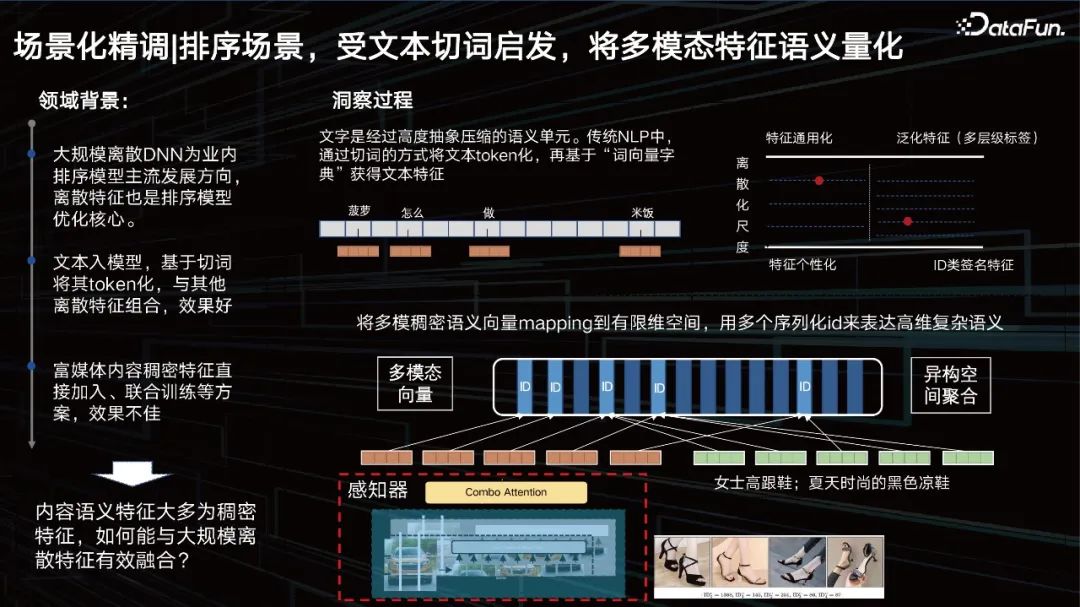
Neben der Darstellung besteht ein weiteres Problem darin, den visuellen Effekt in der Sortierszene zu verbessern. Schauen wir uns zunächst den Hintergrund des Feldes an. Diskretes DNN im großen Maßstab ist die gängige Entwicklungsrichtung von Ranking-Modellen in der Branche, und diskrete Merkmale sind auch der Kern der Optimierung von Ranking-Modellen. Der Text wird in das Modell eingegeben, anhand der Wortsegmentierung tokenisiert und mit anderen diskreten Funktionen kombiniert, um gute Ergebnisse zu erzielen. Was die Vision betrifft, hoffen wir, sie ebenfalls zu tokenisieren.
ID-Typ-Feature ist eigentlich ein sehr personalisiertes Feature, aber je vielseitiger das verallgemeinerte Feature wird, desto schlechter kann seine Charakterisierungsgenauigkeit werden. Wir müssen diesen Gleichgewichtspunkt durch Daten und Aufgaben dynamisch anpassen. Das heißt, wir hoffen, einen Maßstab zu finden, der für die Daten am relevantesten ist, die Features entsprechend in eine ID zu „segmentieren“ und multimodale Features wie Text zu segmentieren. Daher haben wir eine mehrskalige und mehrstufige Lernmethode zur Inhaltsquantifizierung vorgeschlagen, um dieses Problem zu lösen.
Sortieren von Szenen, Fusion multimodaler Funktionen und Modelle MmDict.
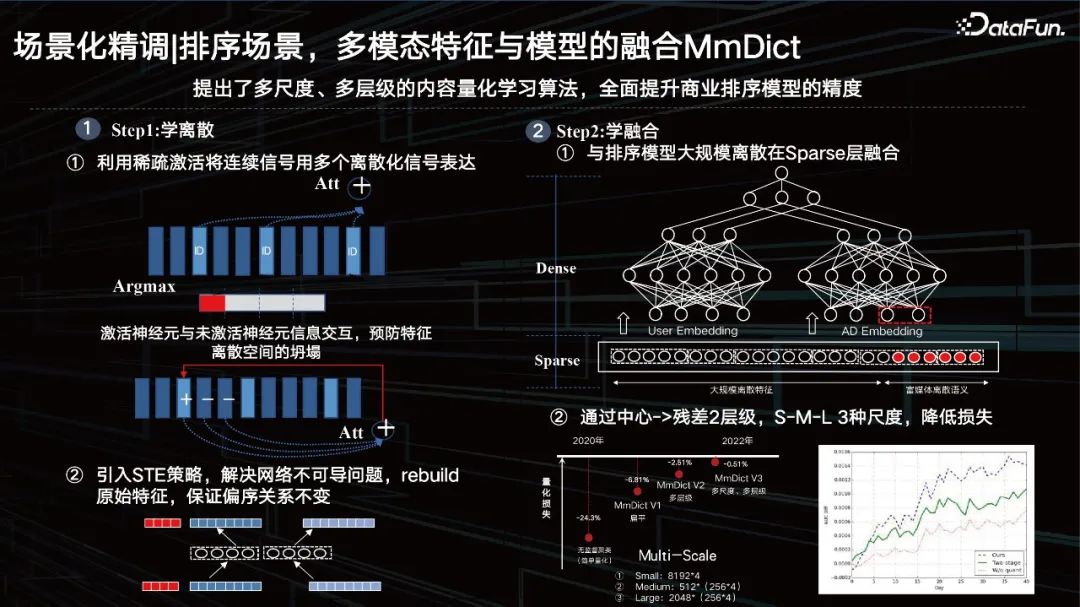
Hauptsächlich in zwei Schritte unterteilt: Der erste Schritt besteht darin, Diskretion zu lernen, und der zweite Schritt besteht darin, Fusion zu lernen.
Schritt 1: Diskret lernen
① Verwenden Sie die Sparse-Aktivierung, um kontinuierliche Signale mit mehreren diskretisierten Signalen auszudrücken. Das heißt, Sie verwenden die Sparse-Aktivierung, um dichte Features zu segmentieren, und aktivieren Sie dann die IDs im entsprechenden multimodalen Codebuch Eigentlich nur die Argmax-Operation, die zu nicht differenzierbaren Problemen führt. Gleichzeitig wird eine Informationsinteraktion zwischen aktivierten Neuronen und inaktiven Neuronen hinzugefügt, um den Zusammenbruch des Merkmalsraums zu verhindern.
② Führen Sie die STE-Strategie ein, um das Problem der Nichtdifferenzierbarkeit des Netzwerks zu lösen, die ursprünglichen Merkmale wiederherzustellen und sicherzustellen, dass die Teilordnungsbeziehung unverändert bleibt.
Verwenden Sie die Encoder-Decoder-Methode, um dichte Features nacheinander zu quantisieren, und stellen Sie die quantisierten Features dann auf die richtige Weise wieder her. Es muss sichergestellt werden, dass die Teilordnungsbeziehung vor und nach der Wiederherstellung unverändert bleibt und der quantitative Verlust von Merkmalen bei bestimmten Aufgaben nahezu auf weniger als 1 % kontrolliert werden kann. Eine solche ID kann nicht nur die aktuelle Datenverteilung personalisieren, sondern auch haben Generalisierungseigenschaften.
Schritt 2: Lernfusion
① wird in großem Maßstab auf der Sparse-Ebene mit dem Sortiermodell fusioniert.
Dann wird die gerade erwähnte Wiederverwendung versteckter Ebenen direkt darüber platziert, aber der Effekt ist eigentlich durchschnittlich. Wenn Sie es identifizieren, quantisieren und mit dem spärlichen Feature-Layer und anderen Feature-Typen verschmelzen, erzielt es eine bessere Wirkung.
② Reduzieren Sie den Verlust durch die Mitte -> Rest 2 Stufen, S-M-L 3 Skalen.
Natürlich verwenden wir auch einige Residuen und Multiskalenmethoden. Ab 2020 haben wir den Quantifizierungsverlust schrittweise gesenkt und sind letztes Jahr unter einen Punkt gesunken. Nachdem das große Modell Merkmale extrahiert hat, können wir diese erlernbare Quantifizierungsmethode verwenden, um den visuellen Inhalt mit semantischer Assoziation zu charakterisieren ID Die Eigenschaften sind tatsächlich sehr sehr Geeignet für unsere aktuellen Geschäftssysteme, einschließlich einer solchen explorativen Forschungsmethode zur ID des Empfehlungssystems.
2. Qingduo
1. Die kommerzielle AIGC ist tief in das Marketing integriert, verbessert die Produktivität von Inhalten und optimiert die Effizienz und Wirkungsverknüpfung. Die Kreativplattform Baidu Marketing AIGC bildet einen perfekten geschlossenen Kreislauf von der Inspiration über die Erstellung bis zur Lieferung . . Durch Dekonstruktion, Generierung und Feedback fördern und optimieren wir unsere AIGC.

Inspiration: KI-Verständnis (Inhalts- und Benutzerverständnis). Kann KI uns dabei helfen, herauszufinden, welche Art von Aufforderung gut ist? Von der materiellen Einsicht zur kreativen Leitung.
- Erstellung: AIGC, wie Textgenerierung, Bildgenerierung, digitale Personen, Videogenerierung usw.
- Lieferung: KI-Optimierung. Vom empirischen Versuch und Irrtum bis zur automatischen Optimierung.
- 2. Erstellung von Marketingtexten = Business-Prompt-System + großes Wenxin-Modell
Ein gutes Business-Prompt besteht aus den folgenden Elementen:

Wissensdiagramm, z. B. Verkauf von Autos, Autos Welche kommerziellen Elemente Auch die Marke allein reicht nicht aus.
- Stil, wie der aktuelle „Literaturstil“, muss tatsächlich in einige Tags abstrahiert werden Bestimmen Sie, um welche Art von Marketingtitel oder Marketingbeschreibung es sich handelt.
- Verkaufsargument, Verkaufsargument ist eigentlich ein Merkmal von Produktattributen, das den stärksten Grund für den Konsum darstellt.
- Benutzerporträts werden basierend auf den Unterschieden in den Verhaltensansichten des Ziels in verschiedene Typen unterteilt, schnell zusammengestellt und dann werden die neu abgeleiteten Typen verfeinert, um einen Typ von Benutzerporträt zu bilden.
- 3. Zusammengesetzte modale Vermarktung digitaler menschlicher Videos, Schaffung eines digitalen Menschen in 3 Minuten
Die Videogenerierung ist mittlerweile relativ ausgereift. Aber es gibt tatsächlich immer noch einige Probleme:
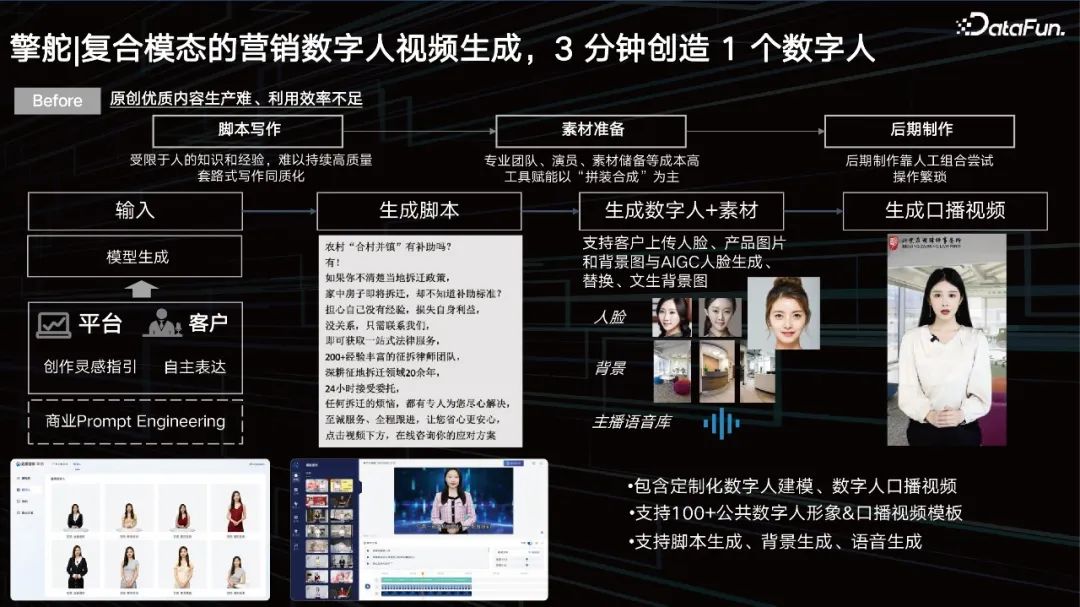
Drehbuchschreiben: Aufgrund des menschlichen Wissens und der Erfahrung ist es schwierig, qualitativ hochwertiges Schreiben aufrechtzuerhalten, und Homogenität ist ein ernstes Problem.
- Materialvorbereitung: Professionelle Teams, Akteure, Materialreserven und andere kostenintensive Werkzeuge werden befähigt, wobei der Schwerpunkt auf „Montage und Synthese“ liegt.
- Postproduktion: Die Postproduktion basiert auf manuellem Ausprobieren und der Vorgang ist umständlich.
- In der Anfangsphase geben wir durch Eingabeaufforderungen ein, welche Art von Video wir erstellen möchten, welche Art von Person wir auswählen möchten und was er sagen soll Steuern Sie unser Video nach Ihren Anforderungen. Große Modelle, um entsprechende Skripte zu generieren.
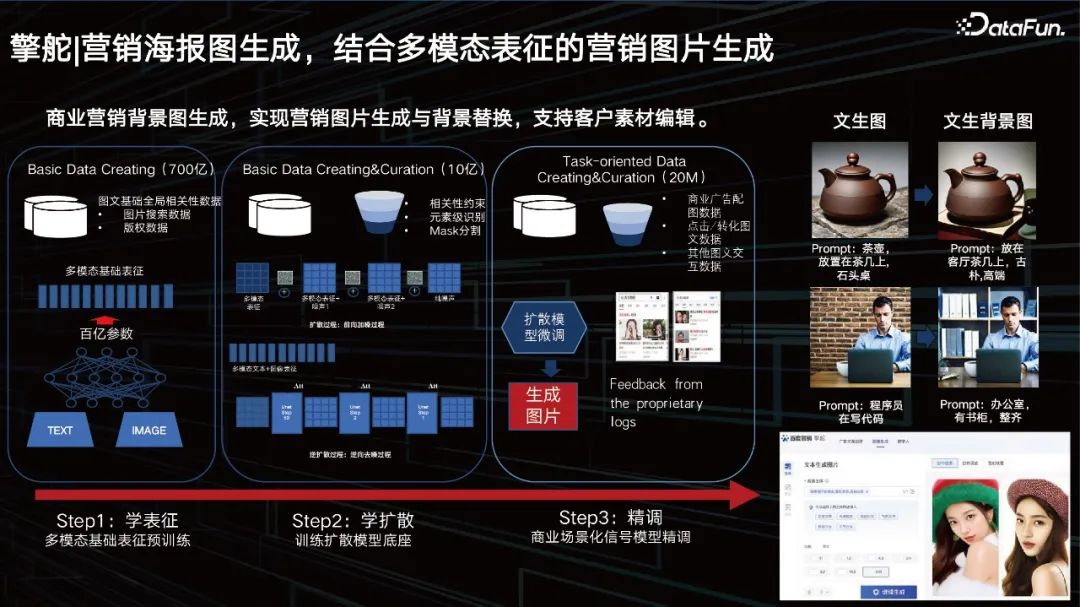
Das große Modell kann Unternehmen auch dabei helfen, Marketingplakate zu erstellen und Produkthintergründe zu ersetzen. Wir haben bereits Dutzende Milliarden multimodaler Darstellungen, die wir auf der Grundlage guter dynamischer Darstellungen gelernt haben. Nach dem Training mit Big Data möchten die Kunden auch etwas besonders Personalisiertes, daher müssen wir auch einige Methoden zur Feinabstimmung hinzufügen. Wir bieten eine Lösung, die Kunden bei der Feinabstimmung unterstützt, eine Lösung zum dynamischen Laden kleiner Parameter für große Modelle, die auch in der Branche eine gängige Lösung ist. Zunächst bieten wir Kunden die Möglichkeit, Bilder zu erstellen. Kunden können den Hintergrund hinter dem Bild durch Bearbeitung oder Aufforderung ändern. 4. Generierung von Marketingplakatbildern, Marketingbildgenerierung kombiniert mit multimodaler Darstellung
Das obige ist der detaillierte Inhalt vonBaidu-Business-Multimodal-Verständnis und AIGC-Innovationspraxis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 Das Videogenerierungsartefakt PixVerse, das Charaktere vereint und Szenen verändert, wurde von Internetnutzern gespielt und seine überragende Konsistenz ist zu einem „Killerzug' geworden.
Apr 01, 2024 pm 02:11 PM
Das Videogenerierungsartefakt PixVerse, das Charaktere vereint und Szenen verändert, wurde von Internetnutzern gespielt und seine überragende Konsistenz ist zu einem „Killerzug' geworden.
Apr 01, 2024 pm 02:11 PM
Ein weiterer Doppelklick ist das Debüt einer neuen Funktion. Wollten Sie schon immer den Hintergrund einer Figur in einem Bild ändern, aber die KI erzeugt immer den Effekt „Das Objekt ist weder die Person noch das Objekt“. Selbst in ausgereiften Generierungstools wie Midjourney und DALL・E sind einige Prompt-Fähigkeiten erforderlich, um die Charakterkonsistenz aufrechtzuerhalten. Andernfalls ändern sich die Charaktere und Sie erzielen nicht die gewünschten Ergebnisse. Diesmal ist es jedoch Ihre Chance. Die neue „Character-Video“-Funktion des AIGC-Tools PixVerse kann Ihnen dabei helfen. Darüber hinaus können dynamische Videos generiert werden, um Ihre Charaktere lebendiger zu machen. Geben Sie ein Bild ein und Sie erhalten die entsprechenden dynamischen Videoergebnisse. Auf der Grundlage der Beibehaltung der Konsistenz der Charaktere ermöglichen die reichhaltigen Hintergrundelemente und die Charakterdynamik die generierten Ergebnisse
 Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Produktpositionierung von TensorRT-LLM TensorRT-LLM ist eine von NVIDIA entwickelte skalierbare Inferenzlösung für große Sprachmodelle (LLM). Es erstellt, kompiliert und führt Berechnungsdiagramme auf der Grundlage des TensorRT-Deep-Learning-Kompilierungsframeworks aus und stützt sich auf die effiziente Kernels-Implementierung in FastTransformer. Darüber hinaus nutzt es NCCL für die Kommunikation zwischen Geräten. Entwickler können Betreiber entsprechend der Technologieentwicklung und Nachfrageunterschieden an spezifische Anforderungen anpassen, beispielsweise durch die Entwicklung maßgeschneiderter GEMM auf Basis von Entermessern. TensorRT-LLM ist die offizielle Inferenzlösung von NVIDIA, die sich der Bereitstellung hoher Leistung und der kontinuierlichen Verbesserung ihrer Praktikabilität verschrieben hat. TensorRT-LL
 Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Laut Nachrichten vom 4. April hat die Cyberspace Administration of China kürzlich eine Liste registrierter großer Modelle veröffentlicht, in der das „Jiutian Natural Language Interaction Large Model“ von China Mobile enthalten ist, was darauf hinweist, dass das große Jiutian AI-Modell von China Mobile offiziell generative künstliche Intelligenz bereitstellen kann Geheimdienste nach außen. China Mobile gab an, dass dies das erste groß angelegte Modell sei, das von einem zentralen Unternehmen entwickelt wurde und sowohl die nationale Doppelregistrierung „Generative Artificial Intelligence Service Registration“ als auch die „Domestic Deep Synthetic Service Algorithm Registration“ bestanden habe. Berichten zufolge zeichnet sich Jiutians großes Modell für die Interaktion mit natürlicher Sprache durch verbesserte Branchenfähigkeiten, Sicherheit und Glaubwürdigkeit aus und unterstützt die vollständige Lokalisierung. Es hat mehrere Parameterversionen wie 9 Milliarden, 13,9 Milliarden, 57 Milliarden und 100 Milliarden gebildet. und kann flexibel in der Cloud eingesetzt werden, Edge und End sind unterschiedliche Situationen
 Xiaomi Photo Album AIGC-Bearbeitungsfunktion offiziell eingeführt: Unterstützt intelligente Bilderweiterung und magische Eliminierung Pro
Mar 14, 2024 pm 10:22 PM
Xiaomi Photo Album AIGC-Bearbeitungsfunktion offiziell eingeführt: Unterstützt intelligente Bilderweiterung und magische Eliminierung Pro
Mar 14, 2024 pm 10:22 PM
Laut Nachrichten vom 14. März gab Xiaomi heute offiziell bekannt, dass die AIGC-Bearbeitungsfunktion von Xiaomi Photo Album offiziell auf den Mobiltelefonen Xiaomi 14 Ultra eingeführt wird und in diesem Rahmen vollständig auf Mobiltelefonen der Serien Xiaomi 14, Xiaomi 14 Pro und Redmi K70 eingeführt wird Monat. Das AI-Großmodell bringt zwei neue Funktionen in das Xiaomi Photo Album: Intelligent Image Expansion und Magic Elimination Pro. Die AI-Smart-Bilderweiterung unterstützt die Erweiterung und automatische Komposition schlecht komponierter Bilder. Die Bedienungsmethode ist: Öffnen Sie das Fotoalbum zum Bearbeiten – geben Sie Zuschneiden und Drehen ein – klicken Sie auf Smart-Bilderweiterung. Magic Elimination Pro kann Passanten auf Touristenfotos nahtlos eliminieren. Die Verwendungsmethode ist: Öffnen Sie das Fotoalbum zum Bearbeiten – geben Sie Magic Elimination ein – klicken Sie oben rechts auf Pro. Derzeit verfügt das Gerät Xiaomi 14Ultra über intelligente Bilderweiterungs- und Magic-Eliminierungs-Pro-Funktionen.
 Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Wenn die Testfragen zu einfach sind, können sowohl Spitzenschüler als auch schlechte Schüler 90 Punkte erreichen, und der Abstand kann nicht vergrößert werden ... Mit der Veröffentlichung stärkerer Modelle wie Claude3, Llama3 und später sogar GPT-5 ist die Branche in Bewegung Dringender Bedarf an einem schwierigeren und differenzierteren Benchmark-Modell. LMSYS, die Organisation hinter der großen Modellarena, brachte den Benchmark der nächsten Generation, Arena-Hard, auf den Markt, der große Aufmerksamkeit erregte. Es gibt auch die neueste Referenz zur Stärke der beiden fein abgestimmten Versionen der Llama3-Anweisungen. Im Vergleich zu MTBench, das zuvor ähnliche Ergebnisse erzielte, stieg die Arena-Hard-Diskriminierung von 22,6 % auf 87,4 %, was auf den ersten Blick stärker und schwächer ist. Arena-Hard basiert auf menschlichen Echtzeitdaten aus der Arena und seine Übereinstimmungsrate mit menschlichen Vorlieben liegt bei bis zu 89,1 %.
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
