

SurroundOcc: Surround 3D-Belegungsraster, neues SOTA!

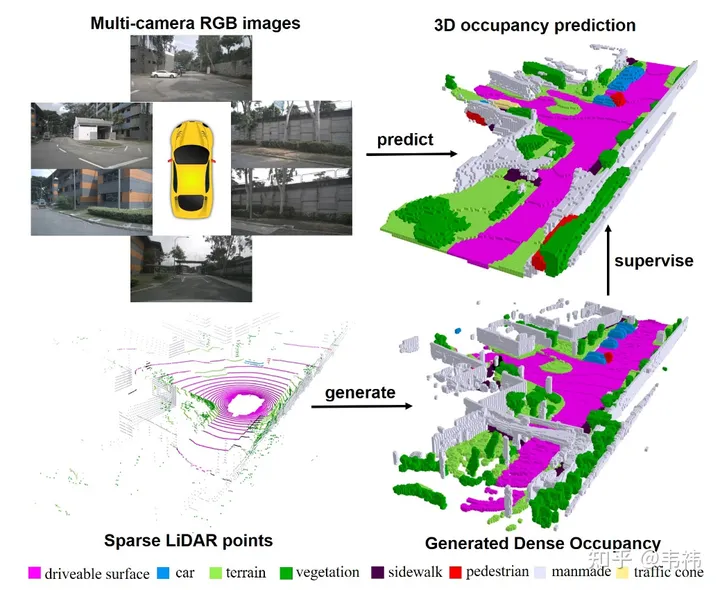
In dieser Arbeit haben wir einen dichten Belegungs-Rasterdatensatz aus Punktwolken mit mehreren Frames erstellt und ein dreidimensionales Belegungs-Rasternetzwerk basierend auf der transformatorbasierten 2D-3D-Unet-Struktur entworfen. Wir fühlen uns geehrt, dass unser Artikel in ICCV 2023 aufgenommen wurde. Der Projektcode ist jetzt Open Source und jeder ist herzlich eingeladen, ihn auszuprobieren.

arXiv: https://arxiv.org/pdf/2303.09551.pdf
Code: https://github.com/weiyithu/SurroundOcc
Homepage-Link: https://weiyithu.github.io/ SurroundOcc/
Ich war in letzter Zeit wie verrückt auf der Suche nach einem Job und hatte keine Zeit zum Schreiben. Als ich meine Arbeit beendet hatte, dachte ich, es wäre besser, einen zu schreiben Zhihu-Zusammenfassung. Tatsächlich ist die Einleitung des Artikels bereits von verschiedenen öffentlichen Stellen gut geschrieben, und dank ihrer Publizität können Sie sich direkt auf das Herzstück des autonomen Fahrens beziehen: nuScenes SOTA! SurroundOcc: Rein visuelles 3D-Belegungsvorhersagenetzwerk für autonomes Fahren (Tsinghua & Tianda). Im Allgemeinen gliedert sich der Beitrag in zwei Teile. Ein Teil befasst sich mit der Verwendung von LIDAR-Punktwolken mit mehreren Frames zum Aufbau eines dichten Belegungsdatensatzes und der andere Teil befasst sich mit dem Entwurf eines Netzwerks für die Belegungsvorhersage. Tatsächlich ist der Inhalt beider Teile relativ einfach und leicht zu verstehen. Wenn Sie etwas nicht verstehen, können Sie mich jederzeit fragen. In diesem Artikel möchte ich also über etwas anderes als die These sprechen. Zum einen geht es darum, die aktuelle Lösung zu verbessern, um sie einfacher bereitzustellen, und zum anderen geht es um die zukünftige Entwicklungsrichtung.
Bereitstellung
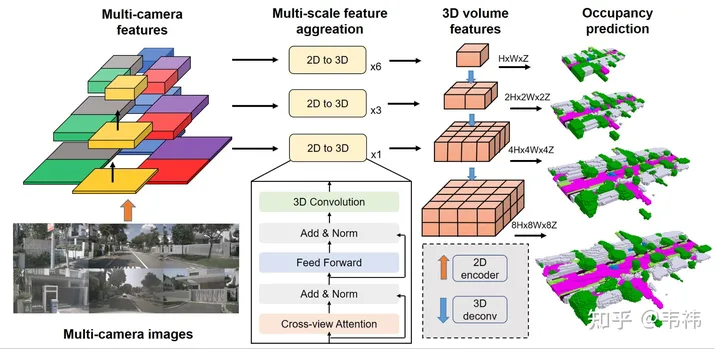
Ob ein Netzwerk einfach bereitzustellen ist, hängt hauptsächlich davon ab, ob es Operatoren gibt, die auf der Platinenseite schwer zu implementieren sind. Die beiden schwierigeren Operatoren in der SurroundOcc-Methode sind der Transformator Schicht und 3D-Faltung.
Die Hauptfunktion des Transformators besteht darin, 2D-Features in 3D-Raum umzuwandeln. Tatsächlich kann dieser Teil auch mit LSS, Homography oder sogar mlp implementiert werden, sodass dieser Teil des Netzwerks entsprechend der implementierten Lösung geändert werden kann. Aber meines Wissens ist die Transformatorlösung nicht kalibrierungsempfindlich und weist im Vergleich zu anderen Lösungen eine bessere Leistung auf. Es wird empfohlen, dass diejenigen, die in der Lage sind, den Transformatoreinsatz zu implementieren, die Originallösung verwenden.
Für die 3D-Faltung können Sie sie durch eine 2D-Faltung ersetzen. Hier müssen Sie das ursprüngliche 3D-Feature von (C, H, W, Z) in das 2D-Feature von (C* Z, H, W) umformen und dann Sie können die 2D-Faltung zur Merkmalsextraktion verwenden. Im letzten Schritt der Belegungsvorhersage können Sie sie wieder in (C, H, W, Z) umformen und eine Überwachung durchführen. Andererseits verbraucht die Skip-Verbindung aufgrund ihrer höheren Auflösung mehr Videospeicher. Während der Bereitstellung kann sie entfernt werden und es bleibt nur die Ebene mit der minimalen Auflösung übrig. Unser Experiment hat ergeben, dass diese beiden Vorgänge in der 3D-Faltung einige Drop-Punkte bei Nuscenes haben, aber der Umfang des Datensatzes der Branche ist viel größer als bei Nuscenes, und manchmal ändern sich einige Schlussfolgerungen, und die Drop-Punkte sollten kleiner oder gar nicht sein.
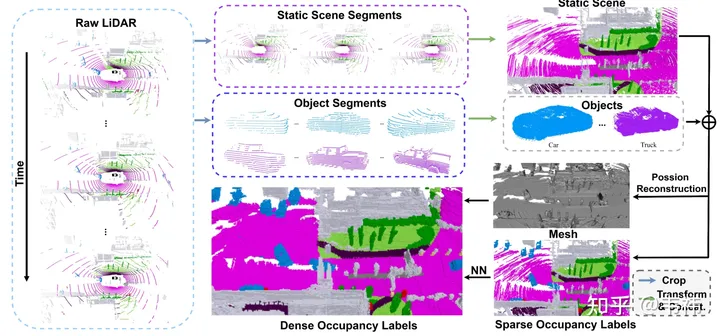
In Bezug auf die Datensatzkonstruktion ist die Poisson-Rekonstruktion der zeitaufwändigste Schritt. Wir verwenden den Nuscenes-Datensatz, der zur Erfassung 32-Zeilen-Lidar verwendet. Selbst bei Verwendung der Multi-Frame-Stitching-Technologie haben wir festgestellt, dass die genähte Punktwolke immer noch viele Löcher aufweist. Deshalb haben wir die Poisson-Rekonstruktion eingesetzt, um diese Löcher zu füllen. Allerdings sind viele derzeit in der Branche verwendete Lidar-Punktwolken relativ dicht, wie z. B. M1, RS128 usw. Daher kann in diesem Fall der Poisson-Rekonstruktionsschritt weggelassen werden, um die Erstellung des Datensatzes zu beschleunigen
Andererseits verwendet SurroundOcc den in Nuscenes mit Anmerkungen versehenen dreidimensionalen Zielerkennungsrahmen, um statische Szenen und dynamische Objekte zu trennen. In der tatsächlichen Anwendung kann jedoch Autolabel, ein großes dreidimensionales Zielerkennungs- und -verfolgungsmodell, verwendet werden, um den Erkennungsrahmen jedes Objekts in der gesamten Sequenz zu erhalten. Im Vergleich zu manuell annotierten Beschriftungen weisen die mit großen Modellen erzielten Ergebnisse definitiv einige Fehler auf. Die offensichtlichste Manifestation ist das Phänomen der Geisterbilder nach dem Zusammenfügen mehrerer Objektrahmen. Tatsächlich stellt die Besetzung jedoch keine so hohen Anforderungen an die Form von Objekten. Solange die Position des Erkennungsrahmens relativ genau ist, kann er die Anforderungen erfüllen.
Zukünftige Wegbeschreibungen
Die aktuelle Methode basiert immer noch auf Lidar, um Belegungsüberwachungssignale bereitzustellen, aber viele Autos, insbesondere einige Autos mit Fahrassistenz auf niedrigem Niveau, verfügen nicht über Lidar. Diese Autos können eine große Menge an RGB-Daten zurückübertragen Schattenmodus, dann ist eine zukünftige Richtung, ob wir RGB nur für selbstüberwachtes Lernen verwenden können. Eine natürliche Lösung besteht darin, NeRF zur Überwachung zu verwenden. Insbesondere bleibt der vordere Backbone-Teil unverändert, um eine Belegungsvorhersage zu erhalten, und dann wird Voxel-Rendering verwendet, um das RGB aus jeder Kameraperspektive zu erhalten, und der Verlust erfolgt mit dem wahren RGB-Wert Erstellen Sie ein Überwachungssignal. Es ist jedoch schade, dass diese einfache Methode nicht sehr gut funktioniert hat, als wir sie ausprobiert haben. Der mögliche Grund dafür ist, dass die Reichweite der Outdoor-Szene zu groß ist und der Nerf sie möglicherweise nicht halten kann, aber es ist auch möglich dass wir es nicht richtig eingestellt haben. Sie können es noch einmal versuchen.
Die andere Richtung ist Timing & Besetzungsfluss. Tatsächlich ist der Belegungsfluss für nachgelagerte Aufgaben weitaus nützlicher als die Einzelbildbesetzung. Während des ICCV hatten wir keine Zeit, den Datensatz zum Beschäftigungsfluss zusammenzustellen, und als wir das Papier veröffentlichten, mussten wir viele Basislinien für den Beschäftigungsfluss vergleichen, sodass wir zu diesem Zeitpunkt nicht daran gearbeitet haben. Für Timing-Netzwerke können Sie auf die Lösungen von BEVFormer und BEVDet4D zurückgreifen, die relativ einfach und effektiv sind. Der schwierige Teil ist immer noch der Flussdatensatz. Allgemeine Objekte können mithilfe des dreidimensionalen Zielerkennungsrahmens der Sequenz berechnet werden, aber speziell geformte Objekte wie kleine Tierplastiktüten müssen möglicherweise mithilfe der Szenenflussmethode annotiert werden.

Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
Das obige ist der detaillierte Inhalt vonSurroundOcc: Surround 3D-Belegungsraster, neues SOTA!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
