
 Technologie-Peripheriegeräte
KI
Salesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen
Technologie-Peripheriegeräte
KI
Salesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen
Salesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen

Die automatische Zusammenfassungstechnologie hat in den letzten Jahren erhebliche Fortschritte gemacht, hauptsächlich aufgrund von Paradigmenwechseln. In der Vergangenheit stützte sich diese Technologie hauptsächlich auf die überwachte Feinabstimmung annotierter Datensätze, nutzt heute jedoch große Sprachmodelle (LLM) für Zero-Shot-Prompts, wie z. B. GPT-4. Durch sorgfältige Eingabeaufforderungseinstellungen kann eine genaue Kontrolle der Zusammenfassungslänge, des Themas, des Stils und anderer Funktionen ohne zusätzliche Schulung erreicht werden. Ein Aspekt wird jedoch häufig übersehen: die Informationsdichte der Zusammenfassung. Theoretisch sollte eine Zusammenfassung als Komprimierung eines anderen Textes dichter sein, also mehr Informationen enthalten als die Quelldatei. Angesichts der hohen Latenz der LLM-Dekodierung ist es wichtig, mehr Informationen mit weniger Wörtern abzudecken, insbesondere für Echtzeitanwendungen.
Die Informationsdichte ist jedoch eine offene Frage: Wenn die Zusammenfassung nicht genügend Details enthält, ist sie gleichbedeutend mit keiner Information; wenn sie zu viele Informationen enthält, ohne die Gesamtlänge zu erhöhen, wird sie schwer zu verstehen. Um innerhalb eines festen Token-Budgets mehr Informationen zu übermitteln, ist es notwendig, Abstraktion, Komprimierung und Fusion zu kombinieren.
In einer aktuellen Forschung haben Forscher von Salesforce, MIT und anderen versucht, die Grenzen der zunehmenden Dichte zu bestimmen, indem sie menschliche Präferenzen für eine Reihe von Zusammenfassungen erfragten, die von GPT-4 generiert wurden. Diese Methode bietet viele Inspirationen zur Verbesserung der „Ausdrucksfähigkeit“ großer Sprachmodelle wie GPT-4. /huggingface.co/datasets/griffin/chain_of_density
Konkret erstellten die Forscher eine erste Zusammenfassung mit geringer Entitätsdichte, indem sie die durchschnittliche Anzahl von Entitäten pro Token als Proxy für die Dichte verwendeten. Anschließend identifizieren und fusionieren sie iterativ die 1–3 Entitäten, die in der vorherigen Zusammenfassung fehlten, ohne die Gesamtlänge zu erhöhen (das Fünffache der Gesamtlänge). Jeder Digest hat ein höheres Entitäts-Token-Verhältnis als der vorherige Digest. Basierend auf menschlichen Präferenzdaten stellten die Autoren letztendlich fest, dass Menschen Zusammenfassungen bevorzugen, die fast so dicht sind wie von Menschen geschriebene Zusammenfassungen und dichter als Zusammenfassungen, die durch gewöhnliche GPT-4-Hinweise generiert werden. Der Gesamtbeitrag der Studie kann wie folgt zusammengefasst werden:

- Was bedeutet CoD?
Der Autor hat eine einzelne Chain of Density (CoD)-Eingabeaufforderung formuliert, die eine erste Zusammenfassung generiert und die Entitätsdichte kontinuierlich erhöht. Insbesondere wird innerhalb einer festgelegten Anzahl von Interaktionen ein eindeutiger Satz hervorstechender Entitäten im Quelltext identifiziert und in die vorherige Zusammenfassung eingefügt, ohne die Länge zu erhöhen.
Beispiele für Eingabeaufforderungen und Ausgaben sind in Abbildung 2 dargestellt. Der Autor gibt die Art der Entität nicht explizit an, definiert die fehlende Entität jedoch als:
Spezifisch: prägnant und auf den Punkt gebracht (5 Wörter oder weniger); Einzigartig: In der vorherigen Zusammenfassung nicht erwähnt;
- Getreu: im Artikel vorhanden; Irgendwo: irgendwo im Artikel enthalten.
-
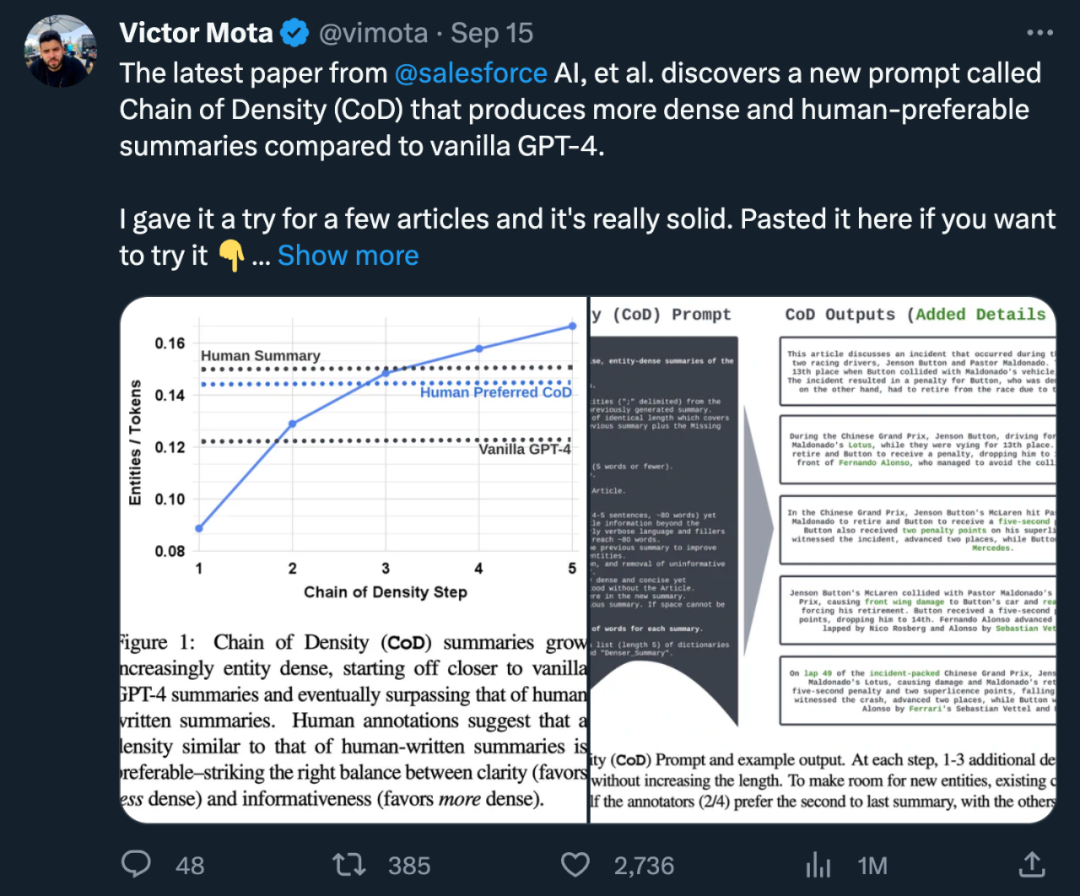
Der Autor wählte zufällig 100 Artikel aus dem CNN/DailyMail-Zusammenfassungstestsatz aus, um CoD-Zusammenfassungen für sie zu erstellen. Um die Referenz zu erleichtern, verglichen sie die CoD-Zusammenfassungsstatistiken mit von Menschen verfassten Referenzzusammenfassungen mit Stichpunkten und Zusammenfassungen, die von GPT-4 unter der normalen Aufforderung generiert wurden: „Schreiben Sie eine sehr kurze Zusammenfassung des Artikels. Nicht mehr als 70 Wörter.“
Statistische Situation -
In der Studie fasste der Autor zwei Aspekte zusammen: direkte Statistik und indirekte Statistik. Direkte Statistiken (Tokens, Entitäten, Entitätsdichte) werden direkt von CoD gesteuert, während indirekte Statistiken ein erwartetes Nebenprodukt der Verdichtung sind.
Direkte Statistiken. Wie in Tabelle 1 gezeigt, reduzierte der zweite Schritt die Länge um durchschnittlich 5 Token (von 72 auf 67), da unnötige Wörter aus der anfänglich langen Zusammenfassung entfernt wurden. Die Entitätsdichte beginnt bei 0,089 und ist zunächst niedriger als bei menschlichem und Vanille-GPT-4 (0,151 und 0,122) und steigt schließlich nach 5 Verdichtungsschritten auf 0,167 an.
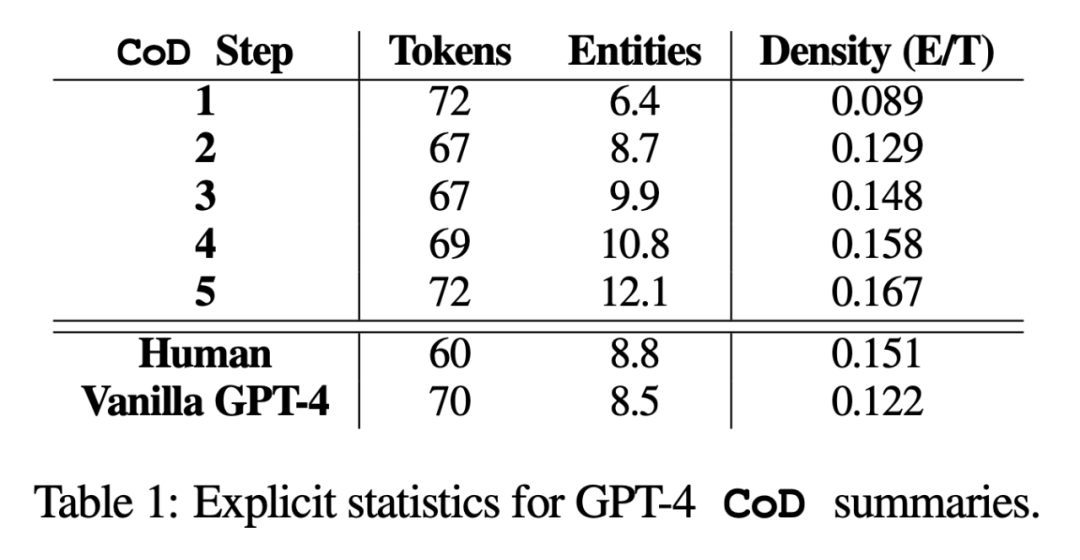
 Indirekte Statistiken. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt.
Indirekte Statistiken. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt. Konkret gehen die Autoren davon aus, dass CoD-Abstracts zunächst einen starken „Lead Bias“ (Lead Bias) aufweisen, dann aber nach und nach beginnen, Entitäten ab der Mitte und am Ende des Artikels einzuführen. Um dies zu messen, verwendeten sie Alignment in Fusion, um Inhalte auf Chinesisch umzuschreiben, ohne dass der ursprüngliche Satz erschien, und maßen den durchschnittlichen Satzrang über alle ausgerichteten Quellsätze hinweg.
Abbildung 3 bestätigt diese Hypothesen: Mit zunehmender Anzahl der Umschreibeschritte nimmt die Abstraktion zu (das linke Bild zeigt eine geringere Extraktionsdichte), die Fusionsrate steigt (das mittlere Bild zeigt) und die Zusammenfassung beginnt, Inhalte aus der Mitte einzubeziehen und Ende des Artikels (rechts abgebildet). Interessanterweise sind alle CoD-Zusammenfassungen im Vergleich zu von Menschen verfassten Zusammenfassungen und Basiszusammenfassungen abstrakter Um den Kompromiss zwischen CoD-Zusammenfassungen zu verstehen, führten die Autoren eine präferenzbasierte Humanstudie durch und führten eine bewertungsbasierte Bewertung mit GPT-4 durch.
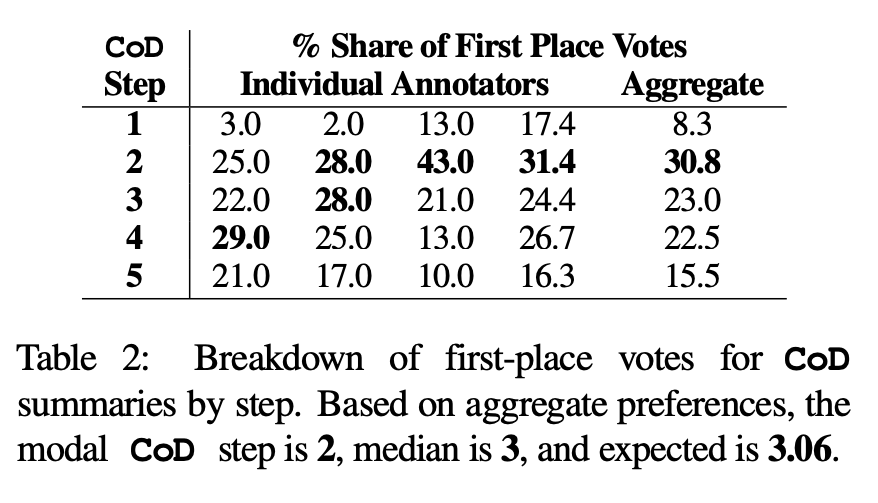
Menschliche Vorlieben. Konkret zeigte der Autor für dieselben 100 Artikel (5 Schritte * 100 = insgesamt 500 Abstracts) die „neu erstellten“ CoD-Abstracts und Artikel nach dem Zufallsprinzip den ersten vier Autoren des Papiers. Jeder Kommentator gab seine Lieblingszusammenfassung basierend auf der Definition einer „guten Zusammenfassung“ von Stiennon et al. (2020) ab. In Tabelle 2 sind die Erstplatzierungen jedes Annotators in der CoD-Phase sowie die Zusammenfassung jedes Annotators aufgeführt. Insgesamt umfassten 61 % der Abstracts mit dem ersten Platz (23,0+22,5+15,5) ≥3 Verdichtungsschritte. Die mittlere Anzahl der bevorzugten CoD-Schritte liegt im Mittelfeld (3), mit einer erwarteten Schrittzahl von 3,06.
Basierend auf der durchschnittlichen Dichte im dritten Schritt beträgt die bevorzugte Entitätsdichte aller CoD-Kandidaten ungefähr 0,15. Wie aus Tabelle 1 ersichtlich ist, stimmt diese Dichte mit von Menschen verfassten Zusammenfassungen (0,151) überein, ist jedoch deutlich höher als mit Zusammenfassungen, die mit der einfachen GPT-4-Eingabeaufforderung (0,122) geschrieben wurden –
automatische Metrik. Als Ergänzung zur menschlichen Bewertung (unten) verwendeten die Autoren GPT-4, um CoD-Zusammenfassungen (1–5 Punkte) in fünf Dimensionen zu bewerten: Informativität, Qualität, Kohärenz, Zuordenbarkeit und Gesamtheit. Wie in Tabelle 3 gezeigt, korreliert die Dichte mit der Aussagekraft, allerdings bis zu einem gewissen Grad, wobei die Punktzahl bei Stufe 4 (4,74) ihren Höhepunkt erreicht.
Aus den Durchschnittswerten jeder Dimension weisen die erste und letzte Stufe von CoD die niedrigsten Werte auf, während die mittleren drei Stufen nahe beieinander liegende Werte aufweisen (4,78, 4,77 bzw. 4,76). Qualitative Analyse. Es gibt einen klaren Kompromiss zwischen abstrakter Kohärenz/Lesbarkeit und Informationsgehalt. In Abbildung 4 sind zwei CoD-Schritte dargestellt: Die Zusammenfassung eines Schritts wird durch mehr Details verbessert, während die Zusammenfassung des anderen Schritts beeinträchtigt wird. Im Durchschnitt erreichen CoD-Zwischenzusammenfassungen dieses Gleichgewicht am besten, dieser Kompromiss muss jedoch in zukünftigen Arbeiten noch genau definiert und quantifiziert werden.
Weitere Einzelheiten zum Papier finden Sie im Originalpapier.
 Indirekte Statistiken. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt.
Indirekte Statistiken. Der Abstraktionsgrad sollte mit jedem CoD-Schritt steigen, da die Zusammenfassung immer wieder neu geschrieben wird, um Platz für jede zusätzliche Entität zu schaffen. Die Autoren messen die Abstraktion anhand der Extraktionsdichte: der durchschnittlichen Quadratlänge extrahierter Fragmente (Grusky et al., 2018). Ebenso sollte die Konzeptfusion monoton zunehmen, wenn Entitäten zu einer Zusammenfassung fester Länge hinzugefügt werden. Die Autoren drückten den Grad der Integration durch die durchschnittliche Anzahl der Quellsätze aus, die mit jedem zusammenfassenden Satz abgeglichen wurden. Zur Ausrichtung verwenden die Autoren die Methode der relativen ROUGE-Verstärkung (Zhou et al., 2018), die den Quellsatz so lange am Zielsatz ausrichtet, bis die relative ROUGE-Verstärkung der zusätzlichen Sätze nicht mehr positiv ist. Sie erwarteten auch Änderungen in der Inhaltsverteilung oder der Position innerhalb des Artikels, aus dem der zusammenfassende Inhalt stammt. 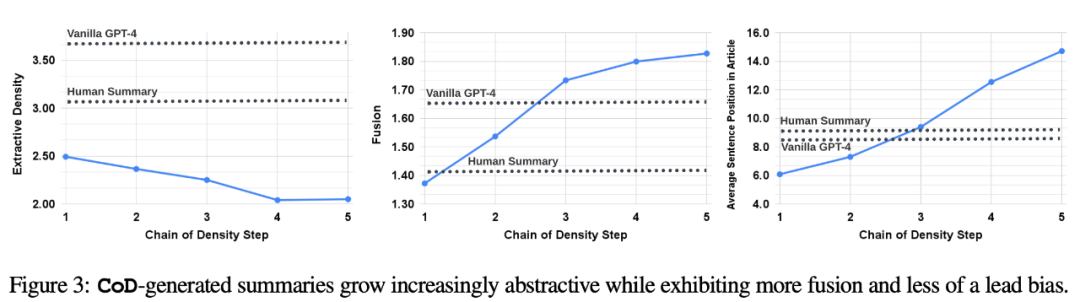
 Aus den Durchschnittswerten jeder Dimension weisen die erste und letzte Stufe von CoD die niedrigsten Werte auf, während die mittleren drei Stufen nahe beieinander liegende Werte aufweisen (4,78, 4,77 bzw. 4,76).
Aus den Durchschnittswerten jeder Dimension weisen die erste und letzte Stufe von CoD die niedrigsten Werte auf, während die mittleren drei Stufen nahe beieinander liegende Werte aufweisen (4,78, 4,77 bzw. 4,76). Das obige ist der detaillierte Inhalt vonSalesforce arbeitet mit MIT-Forschern zusammen, um GPT-4-Revisions-Tutorials als Open-Source-Tutorials zu erstellen, um mehr Informationen mit weniger Worten bereitzustellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
